ATUALIZAÇÃO:2 de setembro de 2021 (Publicado originalmente em 26 de julho de 2012.)
Muitas coisas mudam ao longo de algumas versões principais de nossa plataforma de banco de dados favorita. O SQL Server 2016 nos trouxe STRING_SPLIT, uma função nativa que elimina a necessidade de muitas das soluções personalizadas que precisávamos antes. Também é rápido, mas não é perfeito. Por exemplo, ele suporta apenas um delimitador de caractere único e não retorna nada para indicar a ordem dos elementos de entrada. Já escrevi vários artigos sobre essa função (e STRING_AGG, que chegou no SQL Server 2017) desde que este post foi escrito:
- Surpresas e suposições de desempenho :STRING_SPLIT()
- STRING_SPLIT() no SQL Server 2016:acompanhamento nº 1
- STRING_SPLIT() no SQL Server 2016:acompanhamento nº 2
- Código de substituição de string dividida do SQL Server com STRING_SPLIT
- Comparando métodos de divisão/concatenação de strings
- Resolva problemas antigos com as novas funções STRING_AGG e STRING_SPLIT do SQL Server
- Como lidar com o delimitador de caractere único na função STRING_SPLIT do SQL Server
- Ajude com STRING_SPLIT melhorias
- Uma maneira de melhorar o STRING_SPLIT no SQL Server – e você pode ajudar
Vou deixar o conteúdo abaixo aqui para a posteridade e relevância histórica, e também porque parte da metodologia de teste é relevante para outros problemas além da divisão de strings, mas veja algumas das referências acima para obter informações sobre como você deve dividir strings em versões modernas e suportadas do SQL Server – assim como este post, que explica por que dividir strings talvez não seja um problema que você deseja que o banco de dados resolva em primeiro lugar, nova função ou não.
- Divisão de strings:agora com menos T-SQL
Eu sei que muitas pessoas estão entediadas com o problema de "sequências divididas", mas ainda parece surgir quase diariamente em fóruns e sites de perguntas e respostas como o Stack Overflow. Este é o problema onde as pessoas querem passar uma string como esta:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Dentro do procedimento, eles querem fazer algo assim:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Isso não funciona porque @FavoriteTeams é uma única string e o acima se traduz em:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); O SQL Server vai tentar encontrar uma equipe chamada Patriots,Red Sox,Bruins , e eu estou supondo que não existe tal equipe. O que eles realmente querem aqui é o equivalente a:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Mas como não há um tipo de array no SQL Server, não é assim que a variável é interpretada – ainda é uma string simples e única que contém algumas vírgulas. Deixando de lado o design de esquema questionável, nesse caso a lista separada por vírgulas precisa ser "dividida" em valores individuais - e essa é a pergunta que frequentemente estimula muitos "novos" debates e comentários sobre a melhor solução para conseguir exatamente isso.
A resposta parece ser, quase invariavelmente, que você deve usar o CLR. Se você não pode usar o CLR – e eu sei que muitos de vocês não podem, devido à política corporativa, ao chefe de cabelos pontudos ou à teimosia – então você usa uma das muitas soluções alternativas que existem. E existem muitas soluções alternativas.
Mas qual você deve usar?
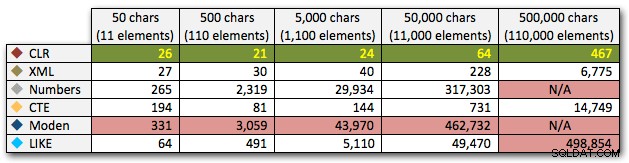
Vou comparar o desempenho de algumas soluções – e focar na pergunta que todo mundo sempre faz:"Qual é a mais rápida?" Não vou me alongar na discussão sobre *todos* os métodos potenciais, porque vários já foram eliminados devido ao fato de que eles simplesmente não escalam. E posso revisitar isso no futuro para examinar o impacto em outras métricas, mas por enquanto vou me concentrar apenas na duração. Aqui estão os concorrentes que vou comparar (usando SQL Server 2012, 11.00.2316, em uma VM Windows 7 com 4 CPUs e 8 GB de RAM):
CLR
Se você deseja usar o CLR, você deve definitivamente pegar emprestado o código do colega MVP Adam Machanic antes de pensar em escrever o seu próprio (eu já escrevi antes sobre reinventar a roda, e também se aplica a trechos de código gratuitos como este). Ele passou muito tempo ajustando essa função CLR para analisar eficientemente uma string. Se você está usando uma função CLR e não é isso, eu recomendo fortemente que você a implante e compare – eu testei contra uma rotina CLR muito mais simples, baseada em VB que era funcionalmente equivalente, mas a abordagem VB teve um desempenho cerca de três vezes pior que o de Adão.
Então, peguei a função de Adam, compilei o código em uma DLL (usando csc) e implantei apenas esse arquivo no servidor. Em seguida, adicionei o seguinte assembly e função ao meu banco de dados:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Essa é a função típica que uso para cenários únicos em que sei que a entrada é "segura", mas não é uma que eu recomendo para ambientes de produção (mais sobre isso abaixo).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Uma advertência muito forte deve acompanhar a abordagem XML:ela só pode ser usada se você puder garantir que sua string de entrada não contenha nenhum caractere XML ilegal. Um nome com <,> ou &e a função explodirá. Portanto, independentemente do desempenho, se você for usar essa abordagem, esteja ciente das limitações – ela não deve ser considerada uma opção viável para um divisor de string genérico. Estou incluindo isso neste resumo porque você pode ter um caso em que pode confie na entrada – por exemplo, é possível usar para listas de inteiros ou GUIDs separadas por vírgulas.
Tabela de números
Esta solução usa uma tabela do Numbers, que você mesmo deve construir e preencher. (Estamos solicitando uma versão integrada há muito tempo.) A tabela Numbers deve conter linhas suficientes para exceder o comprimento da string mais longa que você dividirá. Nesse caso, usaremos 1.000.000 de linhas:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (O uso da compactação de dados reduzirá drasticamente o número de páginas necessárias, mas obviamente você só deve usar essa opção se estiver executando o Enterprise Edition. Nesse caso, os dados compactados requerem 1.360 páginas, versus 2.102 páginas sem compactação – cerca de 35% de economia. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO Expressão de tabela comum
Esta solução usa um CTE recursivo para extrair cada parte da string do "restante" da parte anterior. Como um CTE recursivo com variáveis locais, você notará que isso tinha que ser uma função com valor de tabela de várias instruções, diferente das outras que são todas inline.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO Divisor de Jeff Moden Uma função baseada no divisor de Jeff Moden com pequenas alterações para suportar strings mais longas
No SQLServerCentral, Jeff Moden apresentou uma função de divisão que rivalizava com o desempenho do CLR, então achei justo incluir uma variação usando uma abordagem semelhante neste resumo. Eu tive que fazer algumas pequenas alterações em sua função para lidar com nossa string mais longa (500.000 caracteres) e também fiz as convenções de nomenclatura semelhantes:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Como um aparte, para aqueles que usam a solução de Jeff Moden, você pode considerar usar uma tabela Numbers como acima e experimentar uma pequena variação na função de Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Isso trocará leituras um pouco mais altas por CPU um pouco mais baixa, portanto, pode ser melhor dependendo se o seu sistema já está vinculado à CPU ou E/S.)
Verificação de integridade
Apenas para ter certeza de que estamos no caminho certo, podemos verificar se todas as cinco funções retornam os resultados esperados:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
E, de fato, esses são os resultados que vemos em todos os cinco casos…

Os dados de teste
Agora que sabemos que as funções se comportam conforme o esperado, podemos chegar à parte divertida:testar o desempenho em relação a vários números de strings que variam em tamanho. Mas primeiro precisamos de uma mesa. Eu criei o seguinte objeto simples:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Eu preenchi esta tabela com um conjunto de strings de comprimentos variados, certificando-me de que aproximadamente o mesmo conjunto de dados seria usado para cada teste – primeiro 10.000 linhas onde a string tem 50 caracteres, depois 1.000 linhas onde a string tem 500 caracteres , 100 linhas onde a string tem 5.000 caracteres, 10 linhas onde a string tem 50.000 caracteres e assim por diante até 1 linha de 500.000 caracteres. Fiz isso para comparar a mesma quantidade de dados gerais sendo processados pelas funções, bem como para tentar manter meus tempos de teste um pouco previsíveis.
Eu uso uma tabela #temp para que eu possa simplesmente usar GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Criar e preencher esta tabela levou cerca de 20 segundos na minha máquina, e a tabela representa cerca de 6 MB de dados (cerca de 500.000 caracteres vezes 2 bytes, ou 1 MB por string_type, além de sobrecarga de linha e índice). Não é uma tabela enorme, mas deve ser grande o suficiente para destacar quaisquer diferenças de desempenho entre as funções.
Os testes
Com as funções no lugar e a tabela devidamente preenchida com grandes strings para mastigar, podemos finalmente executar alguns testes reais para ver como as diferentes funções se comportam em relação aos dados reais. Para medir o desempenho sem considerar a sobrecarga da rede, usei o SQL Sentry Plan Explorer, executando cada conjunto de testes 10 vezes, coletando as métricas de duração e calculando a média.
O primeiro teste simplesmente puxou os itens de cada string como um conjunto:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Os resultados mostram que à medida que as cordas ficam maiores, a vantagem do CLR realmente brilha. Na extremidade inferior, os resultados foram misturados, mas novamente o método XML deve ter um asterisco próximo a ele, já que seu uso depende de contar com entrada segura para XML. Para este caso de uso específico, a tabela Numbers teve o pior desempenho consistente:
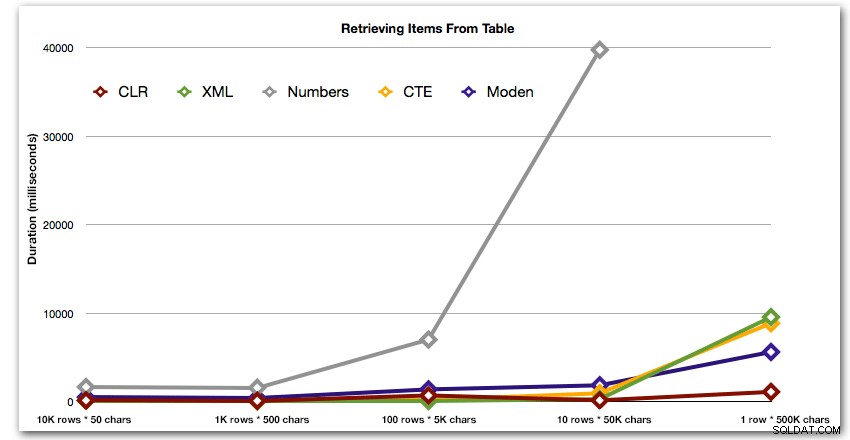
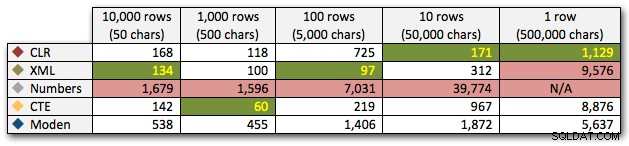
Duração, em milissegundos
Após o desempenho hiperbólico de 40 segundos para a tabela de números em 10 linhas de 50.000 caracteres, eu a retirei da execução para o último teste. Para mostrar melhor o desempenho relativo dos quatro melhores métodos neste teste, excluí completamente os resultados do Numbers do gráfico:
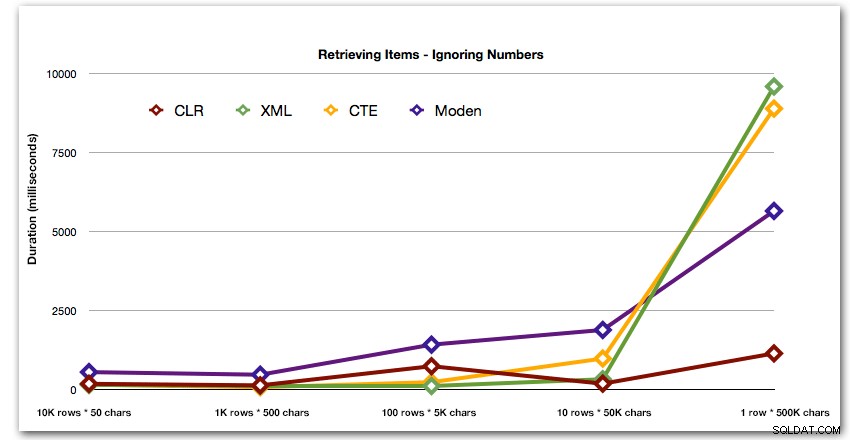
Em seguida, vamos comparar quando realizamos uma pesquisa com o valor separado por vírgulas (por exemplo, retornar as linhas em que uma das strings é 'foo'). Novamente, usaremos as cinco funções acima, mas também compararemos o resultado com uma pesquisa realizada em tempo de execução usando LIKE em vez de se preocupar com a divisão.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Esses resultados mostram que, para strings pequenas, o CLR foi realmente o mais lento e que a melhor solução será executar uma varredura usando LIKE, sem se preocupar em dividir os dados. Mais uma vez, abandonei a solução da tabela Numbers da 5ª abordagem, quando ficou claro que sua duração aumentaria exponencialmente à medida que o tamanho da string aumentasse:
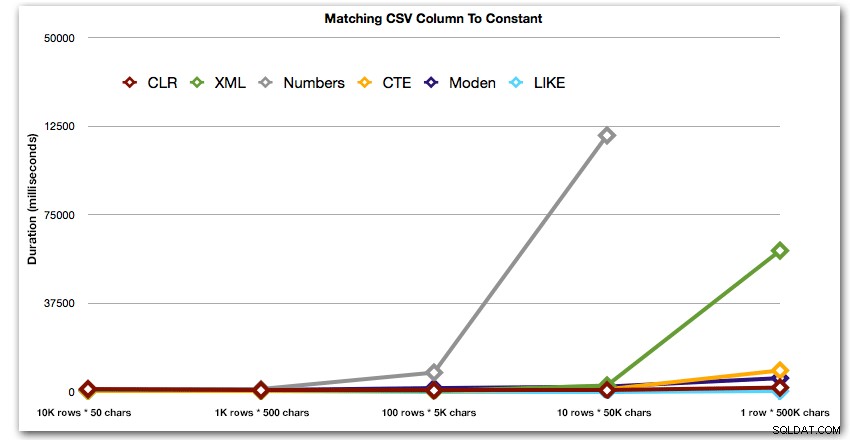
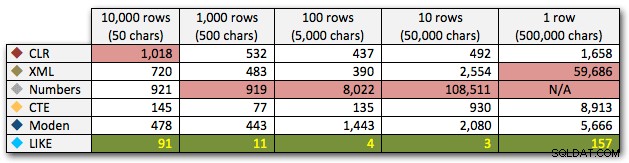
Duração, em milissegundos
E para melhor demonstrar os padrões dos 4 principais resultados, eliminei as soluções Numbers e XML do gráfico:
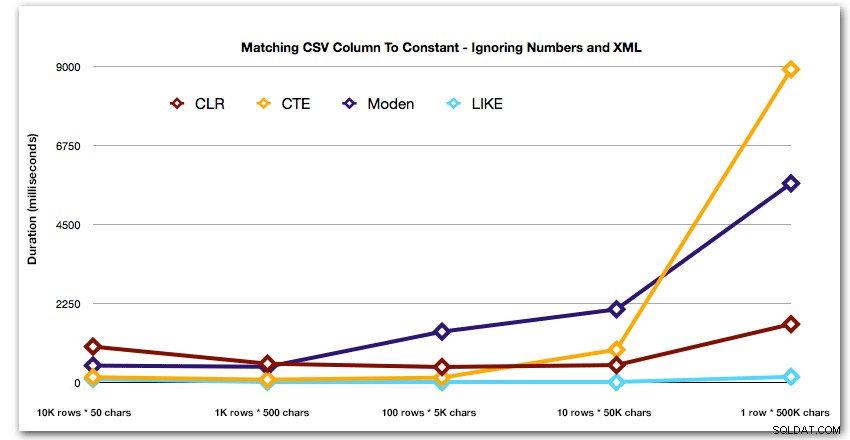
Em seguida, vamos ver como replicar o caso de uso do início deste post, onde estamos tentando encontrar todas as linhas em uma tabela que existem na lista que está sendo passada. Assim como os dados na tabela que criamos acima, nós vamos criar strings de comprimento variando de 50 a 500.000 caracteres, armazená-los em uma variável e, em seguida, verificar se existe uma exibição de catálogo comum na lista.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Esses resultados mostram que, para esse padrão, vários métodos veem sua duração aumentar exponencialmente à medida que o tamanho da string aumenta. Na extremidade inferior, o XML mantém um bom ritmo com o CLR, mas isso também se deteriora rapidamente. O CLR é consistentemente o vencedor claro aqui:
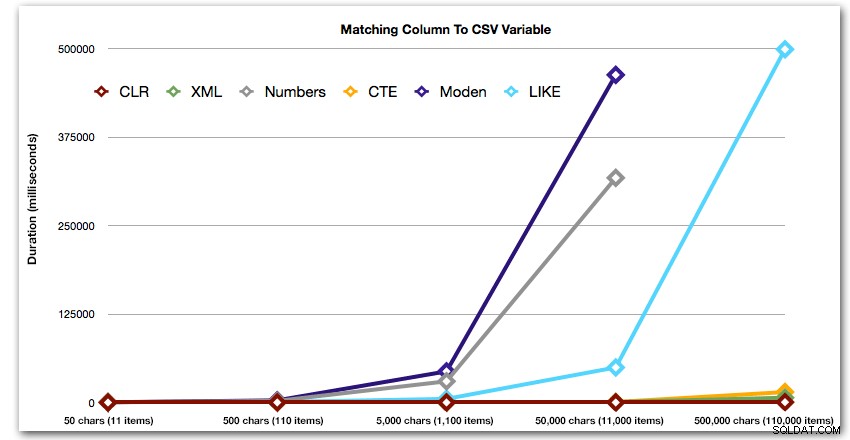
Duração, em milissegundos
E novamente sem os métodos que explodem para cima em termos de duração:
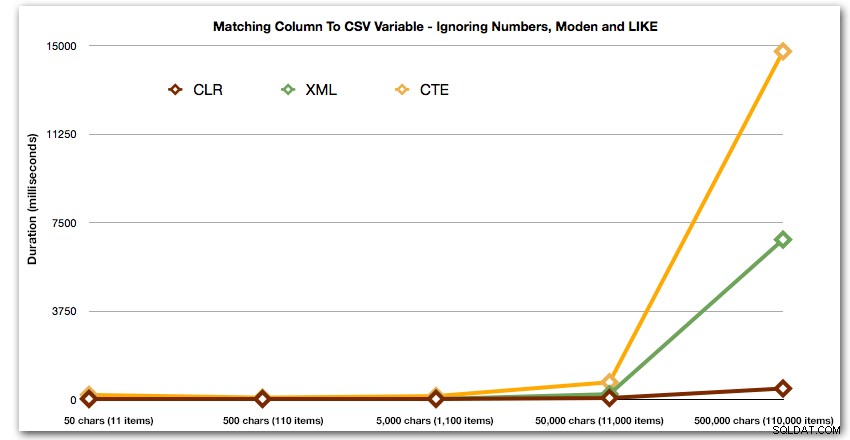
Por fim, vamos comparar o custo de recuperar os dados de uma única variável de comprimento variável, ignorando o custo de ler os dados de uma tabela. Novamente, geraremos strings de comprimento variável, de 50 a 500.000 caracteres, e então retornaremos os valores como um conjunto:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Esses resultados também mostram que o CLR é bastante linear em termos de duração, até 110.000 itens no conjunto, enquanto os outros métodos mantêm um ritmo decente até algum tempo depois de 11.000 itens:
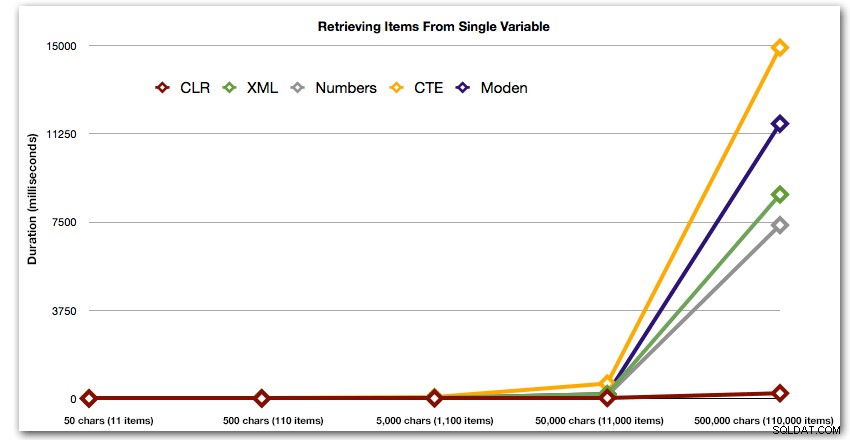
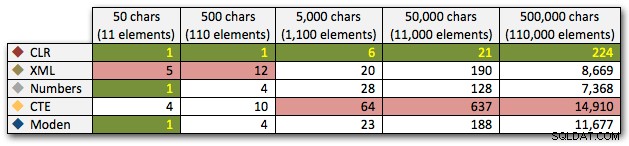
Duração, em milissegundos
Conclusão
Em quase todos os casos, a solução CLR supera claramente as outras abordagens – em alguns casos é uma vitória esmagadora, especialmente à medida que o tamanho das cordas aumenta; em alguns outros, é um acabamento fotográfico que pode cair de qualquer maneira. No primeiro teste, vimos que XML e CTE superaram o CLR na extremidade inferior, portanto, se esse for um caso de uso típico *e* você tiver certeza de que suas strings estão no intervalo de 1 a 10.000 caracteres, uma dessas abordagens pode ser uma opção melhor. Se os tamanhos das cordas forem menos previsíveis do que isso, o CLR provavelmente ainda é sua melhor aposta no geral – você perde alguns milissegundos na extremidade baixa, mas ganha muito na extremidade alta. Aqui estão as escolhas que eu faria, dependendo da tarefa, com o segundo lugar destacado para os casos em que o CLR não é uma opção. Observe que XML é meu método preferido somente se eu souber que a entrada é segura para XML; essas podem não ser necessariamente suas melhores alternativas se você tiver menos fé em sua opinião.
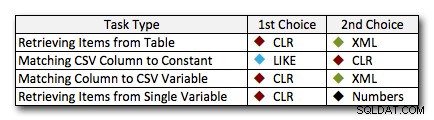
A única exceção real em que o CLR não é minha escolha geral é o caso em que você está realmente armazenando listas separadas por vírgulas em uma tabela e, em seguida, encontrando linhas em que uma entidade definida está nessa lista. Nesse caso específico, eu provavelmente recomendaria primeiro reprojetar e normalizar adequadamente o esquema, para que esses valores sejam armazenados separadamente, em vez de usá-lo como desculpa para não usar o CLR para divisão.
Se você não pode usar o CLR por outros motivos, não há um "segundo lugar" claro revelado por esses testes; minhas respostas acima foram baseadas na escala geral e não em qualquer tamanho de string específico. Cada solução aqui foi vice-campeã em pelo menos um cenário - portanto, embora o CLR seja claramente a escolha quando você pode usá-lo, o que você deve usar quando não pode é mais uma resposta "depende" - você precisará julgar com base em seu(s) caso(s) de uso e os testes acima (ou construindo seus próprios testes) qual alternativa é melhor para você.
Adendo :Uma alternativa à divisão em primeiro lugar
As abordagens acima não exigem alterações em seus aplicativos existentes, supondo que eles já estejam montando uma string separada por vírgulas e jogando-a no banco de dados para lidar com ela. Uma opção que você deve considerar, se o CLR não for uma opção e/ou você puder modificar o(s) aplicativo(s), é usar parâmetros com valor de tabela (TVPs). Aqui está um exemplo rápido de como utilizar um TVP no contexto acima. Primeiro, crie um tipo de tabela com uma única coluna de string:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Em seguida, o procedimento armazenado pode receber esse TVP como entrada e ingressar no conteúdo (ou usá-lo de outras maneiras - este é apenas um exemplo):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Agora, em seu código C#, por exemplo, em vez de criar uma string separada por vírgulas, preencha um DataTable (ou use qualquer coleção compatível que já contenha seu conjunto de valores):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Você pode considerar isso como uma prequela de um post de acompanhamento.
Claro que isso não funciona bem com JSON e outras APIs – muitas vezes o motivo pelo qual uma string separada por vírgulas está sendo passada para o SQL Server em primeiro lugar.