A necessidade mais comum de retirar o tempo de um valor datetime é obter todas as linhas que representam pedidos (ou visitas ou acidentes) que ocorreram em um determinado dia. No entanto, nem todas as técnicas utilizadas para isso são eficientes ou mesmo seguras.
TL;versão DR
Se você deseja uma consulta de intervalo seguro com bom desempenho, use um intervalo aberto ou, para consultas de um dia no SQL Server 2008 e superior, use
CONVERT(DATE) :DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Algumas ressalvas:
- Tenha cuidado com o
DATEDIFFabordagem, pois existem algumas anomalias de estimativa de cardinalidade que podem ocorrer (consulte esta postagem do blog e a pergunta do Stack Overflow que o estimulou para obter mais informações). - Embora o último ainda use potencialmente uma busca de índice (diferente de todas as outras expressões não sargáveis que já encontrei), você precisa ter cuidado ao converter a coluna em uma data antes de comparar. Essa abordagem também pode gerar estimativas de cardinalidade fundamentalmente erradas. Veja esta resposta de Martin Smith para mais detalhes.
De qualquer forma, continue lendo para entender por que essas são as duas únicas abordagens que eu recomendo.
Nem todas as abordagens são seguras
Como um exemplo inseguro, vejo este muito usado:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Existem alguns problemas com essa abordagem, mas o mais notável é o cálculo do "fim" de hoje - se o tipo de dados subjacente for
SMALLDATETIME , esse intervalo final será arredondado para cima; se for DATETIME2 , teoricamente você pode perder dados no final do dia. Se você escolher minutos ou nanossegundos ou qualquer outro intervalo para acomodar o tipo de dados atual, sua consulta começará a ter um comportamento estranho caso o tipo de dados mude mais tarde (e vamos ser honestos, se alguém alterar o tipo dessa coluna para ser mais ou menos granular, eles não estão correndo por aí verificando todas as consultas que o acessam). Ter que codificar dessa maneira, dependendo do tipo de dados de data/hora na coluna subjacente, é fragmentado e propenso a erros. É muito melhor usar intervalos de datas abertos para isso:Eu falo muito mais sobre isso em alguns posts antigos do blog:
- O que BETWEEN e o diabo têm em comum?
- Maus hábitos a serem eliminados:tratamento incorreto de consultas de data/intervalo
Mas eu queria comparar o desempenho de algumas das abordagens mais comuns que vejo por aí. Sempre usei intervalos abertos e, desde o SQL Server 2008, podemos usar
CONVERT(DATE) e ainda utilizar um índice nessa coluna, que é bastante poderoso. SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Um teste de desempenho simples
Para realizar um teste de desempenho inicial muito simples, fiz o seguinte para cada uma das declarações acima, definindo uma variável para a saída do cálculo 100.000 vezes:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Eu fiz isso três vezes para cada método, e todos eles rodaram no intervalo de 34 a 38 segundos. Então, estritamente falando, existem diferenças muito insignificantes nesses métodos ao realizar as operações na memória:
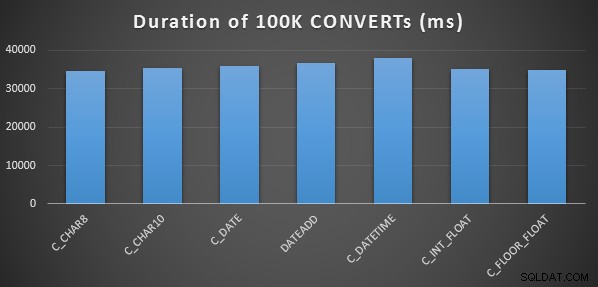
Um teste de desempenho mais elaborado
Eu também queria comparar esses métodos com diferentes tipos de dados (
DATETIME , SMALLDATETIME e DATETIME2 ), contra um índice clusterizado e um heap, e com e sem compactação de dados. Então, primeiro eu criei um banco de dados simples. Por meio de experimentação, determinei que o tamanho ideal para lidar com 120 milhões de linhas e toda a atividade de log que poderia ocorrer (e para evitar que eventos de crescimento automático interferissem no teste) era um arquivo de dados de 20 GB e um log de 3 GB:CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Em seguida, criei 12 tabelas:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Em seguida, repita novamente para DATETIME e DATETIME2.]
Em seguida, inseri 10.000.000 de linhas em cada tabela. Eu fiz isso criando uma visão que geraria as mesmas 10.000.000 datas de cada vez:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Isso me permitiu preencher as tabelas desta forma:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Em seguida, repita novamente para os heaps e o índice clusterizado não compactado. Coloquei um
CHECKPOINT entre cada inserção para garantir a reutilização do log (o modelo de recuperação é simples).] INSERIR Tempos e Espaço Usado
Aqui estão os horários para cada inserção (conforme capturado com o Plan Explorer):
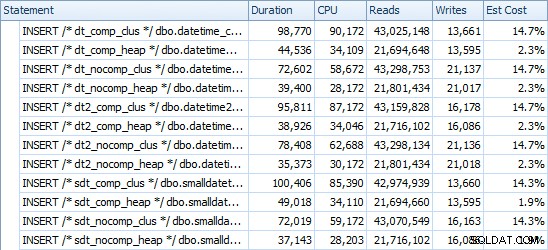
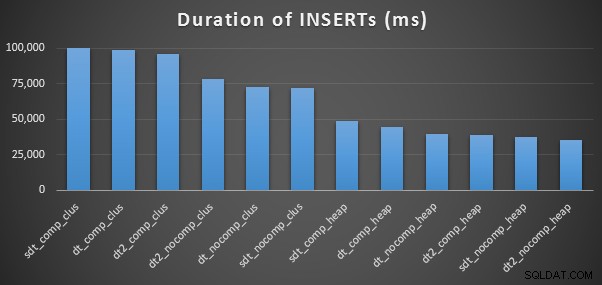
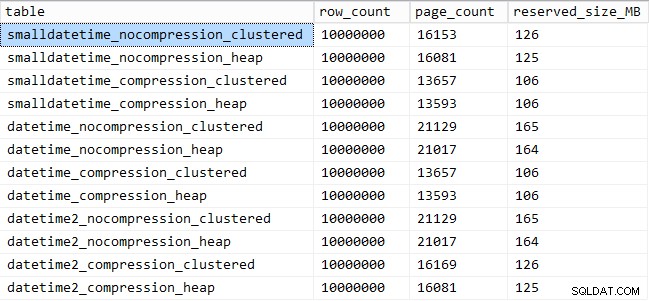
E aqui está a quantidade de espaço ocupado por cada mesa:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Desempenho do padrão de consulta
Em seguida, comecei a testar dois padrões de consulta diferentes para desempenho:
- Contando as linhas de um dia específico, usando as sete abordagens acima, bem como o período em aberto
- Converter todas as 10.000.000 linhas usando as sete abordagens acima, bem como apenas retornar os dados brutos (já que a formatação no lado do cliente pode ser melhor)
[Com exceção do
FLOAT métodos e o DATETIME2 coluna, já que esta conversão não é legal.] Para a primeira pergunta, as consultas ficam assim (repetidas para cada tipo de tabela):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Os resultados em relação a um índice clusterizado são assim (clique para ampliar):
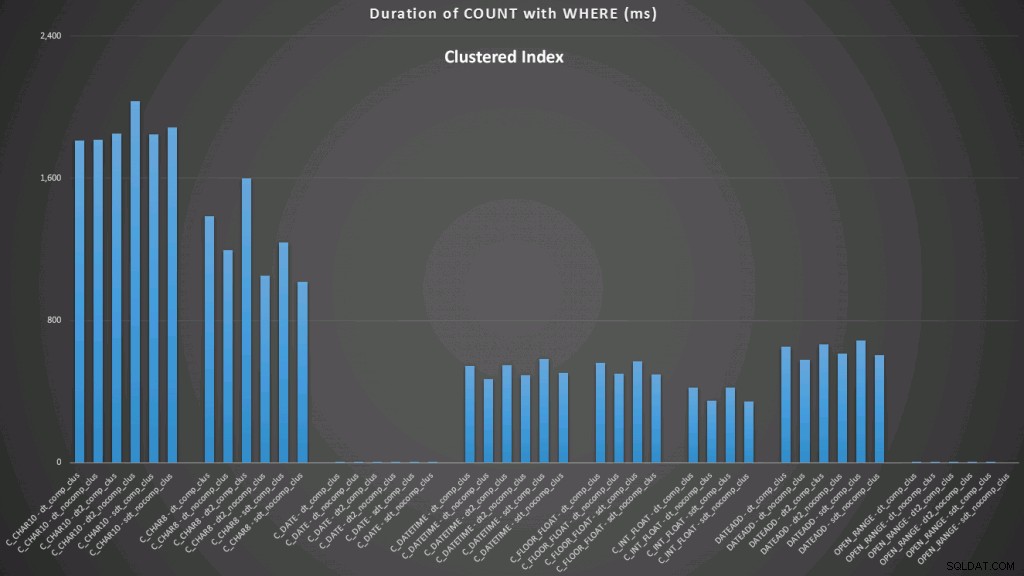
Aqui vemos que a conversão para data e o intervalo aberto usando um índice têm os melhores desempenhos. No entanto, em relação a um heap, a conversão para data na verdade leva algum tempo, tornando o intervalo aberto a escolha ideal (clique para ampliar):
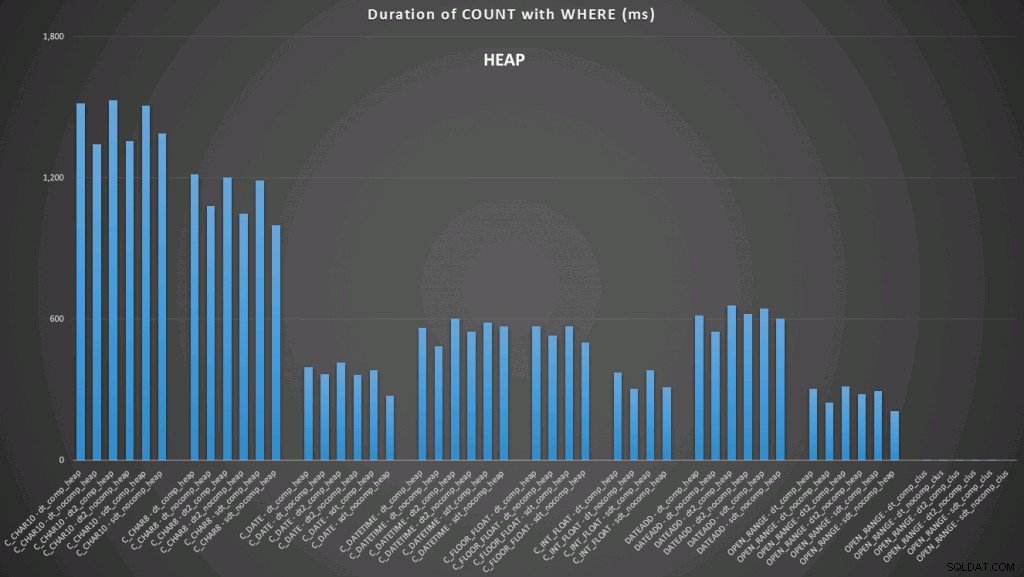
E aqui está o segundo conjunto de consultas (novamente, repetindo para cada tipo de tabela):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Focando nos resultados para tabelas com um índice clusterizado, fica claro que o convert to date teve um desempenho muito próximo de apenas selecionar os dados brutos (clique para ampliar):
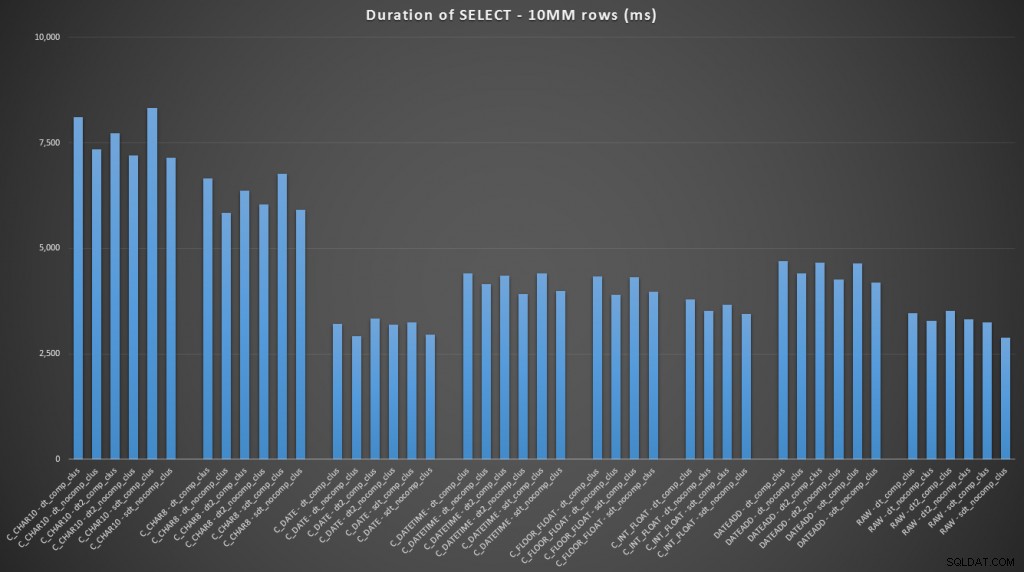
(Para este conjunto de consultas, o heap mostrou resultados muito semelhantes – praticamente indistinguíveis.)
Conclusão
Caso você queira pular para a conclusão, esses resultados mostram que as conversões na memória não são importantes, mas se você estiver convertendo dados ao sair de uma tabela (ou como parte de um predicado de pesquisa), o método escolhido pode ter um impacto dramático no desempenho. Convertendo para um
DATE (para um único dia) ou usar um intervalo de datas aberto em qualquer caso produzirá o melhor desempenho, enquanto o método mais popular disponível – converter para uma string – é absolutamente péssimo. Também vemos que a compactação pode ter um efeito decente no espaço de armazenamento, com um impacto muito pequeno no desempenho da consulta. O efeito sobre o desempenho da inserção parece ser tão dependente se a tabela tem ou não um índice clusterizado, em vez de se a compactação está ou não habilitada. No entanto, com um índice clusterizado, houve um aumento notável na duração necessária para inserir 10 milhões de linhas. Algo para manter em mente e equilibrar com a economia de espaço em disco.
Claramente, poderia haver muito mais testes envolvidos, com cargas de trabalho mais substanciais e variadas, que posso explorar mais em um post futuro.