As exibições indexadas podem ser criadas em qualquer edição do SQL Server, mas há vários comportamentos a serem observados se você quiser aproveitá-los ao máximo.
Estatísticas automáticas requerem uma dica NOEXPAND
O SQL Server pode criar estatísticas automaticamente para auxiliar na estimativa de cardinalidade e na tomada de decisões com base em custos durante a otimização de consultas. Esse recurso funciona com exibições indexadas e também com tabelas base, mas somente se a exibição for nomeada explicitamente na consulta e o
NOEXPAND dica é especificada. (Sempre há um objeto de estatística associado a cada índice em uma visão, é a geração e manutenção automática de estatísticas não associadas a um índice que estamos falando aqui.) Se você está acostumado a trabalhar com edições não Enterprise do SQL Server, talvez nunca tenha notado esse comportamento antes. Edições inferiores do SQL Server requerem o
NOEXPAND dica para produzir um plano de consulta que acessa uma exibição indexada. Quando NOEXPAND for especificado, as estatísticas automáticas são criadas nas visualizações indexadas exatamente como acontece com as tabelas comuns. Exemplo – Edição Standard com NOEXPAND
Usando o SQL Server 2012 Standard Edition e o banco de dados de exemplo Adventure Works, primeiro criamos uma exibição que une duas tabelas de vendas e calcula a quantidade total do pedido por cliente e produto:
CREATE VIEW dbo.CustomerOrders
WITH SCHEMABINDING AS
SELECT
SOH.CustomerID,
SOD.ProductID,
OrderQty = SUM(SOD.OrderQty),
NumRows = COUNT_BIG(*)
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY
SOH.CustomerID,
SOD.ProductID; Para que essa visualização suporte estatísticas, precisamos materializá-la adicionando um índice clusterizado exclusivo. A combinação de ID do cliente e do produto é garantida como exclusiva na visualização (por definição), portanto, usaremos isso como a chave. Poderíamos especificar as duas colunas de qualquer maneira no índice, mas supondo que esperamos que mais consultas sejam filtradas por produto, tornamos o ID do produto a coluna principal. Essa ação também cria estatísticas de índice, com um histograma criado a partir de valores de ID do produto.
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
Agora somos solicitados a escrever uma consulta que mostre a quantidade total de pedidos por cliente, para uma determinada gama de produtos. Esperamos que um plano de execução usando a visualização indexada seja uma estratégia eficaz, pois evitará uma junção e operará em dados que já estão parcialmente agregados. Como estamos usando o SQL Server Standard Edition, devemos especificar a exibição explicitamente e usar um
NOEXPAND dica para produzir um plano de consulta que acesse a exibição indexada:SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID; O plano de execução produzido mostra uma busca na visão indexada para encontrar linhas para os produtos de interesse seguido de uma agregação para calcular a quantidade total por cliente:
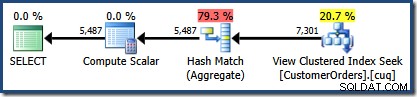
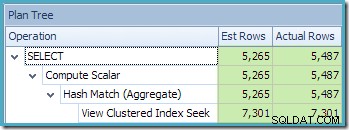
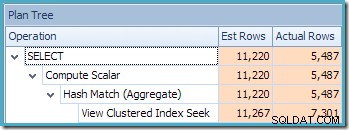
A visualização Plan Tree do SQL Sentry Plan Explorer mostra que a estimativa de cardinalidade está exatamente correta para a busca de visualização indexada e muito boa para o resultado da agregação:
Como parte do processo de compilação e otimização dessa consulta, o SQL Server criou um objeto de estatísticas adicional na coluna ID do cliente da exibição indexada. Essa estatística é criada porque o número esperado e a distribuição de IDs de clientes podem ser importantes, por exemplo, na escolha de uma estratégia de agregação. Podemos ver a nova estatística usando o Management Studio Object Explorer:
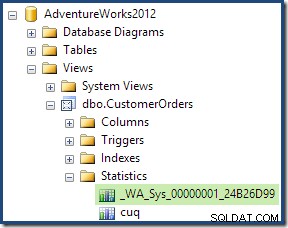
Clicar duas vezes no objeto de estatísticas confirma que ele foi criado a partir da coluna ID do cliente na visualização (não em uma tabela base):
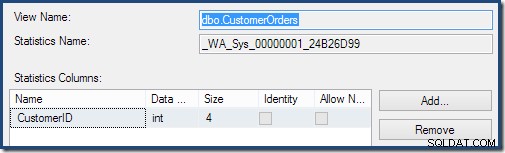
As visualizações indexadas podem melhorar a estimativa de cardinalidade
Ainda usando o Standard Edition, agora descartamos e recriamos a visualização indexada (que também descarta as estatísticas da visualização) e executamos a consulta novamente, desta vez com o
NOEXPAND dica comentou:SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID; Como esperado ao usar o Standard Edition sem
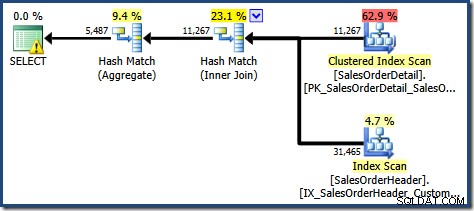
NOEXPAND , o plano de consulta resultante opera nas tabelas base em vez da exibição diretamente:
O triângulo de aviso no operador raiz no plano acima está nos alertando para um índice potencialmente útil na tabela Detalhes do pedido de vendas, que não é importante para nossos propósitos atuais. Essa compilação não cria estatísticas na exibição indexada. A única estatística na exibição após a compilação da consulta é aquela associada ao índice clusterizado:
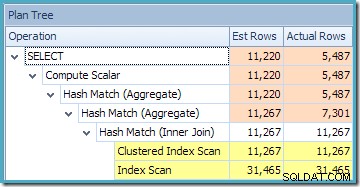
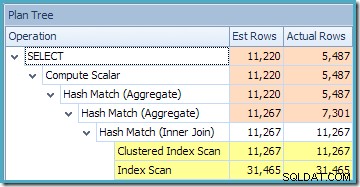
A visualização Plan Tree para a consulta mostra que a estimativa de cardinalidade está correta para as duas varreduras de tabela e a junção, mas um pouco pior para os outros operadores de plano:
Usando a visualização indexada com um
NOEXPAND hint resultou em estimativas mais precisas para nossa consulta de teste porque informações de melhor qualidade estavam disponíveis nas estatísticas da exibição – em particular, as estatísticas associadas ao índice de exibição. Como regra geral, a precisão das informações estatísticas diminui rapidamente à medida que elas passam e são modificadas pelos operadores do plano de consulta. As junções simples geralmente não são tão ruins a esse respeito, mas as informações sobre o resultado de uma agregação geralmente não são melhores do que um palpite. Fornecer ao otimizador de consulta informações mais precisas usando estatísticas em exibições indexadas pode ser uma técnica útil para aumentar a qualidade e a robustez do plano.
Uma visualização sem NOEXPAND pode produzir um plano inferior
O plano de consulta mostrado acima (Standard Edition, sem
NOEXPAND ) é realmente menos ideal do que se tivéssemos escrito a consulta nas tabelas base, em vez de permitir que o otimizador de consulta expandisse a exibição. A consulta abaixo expressa o mesmo requisito lógico, mas não faz referência à visualização:SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID; Essa consulta produz o seguinte plano de execução:
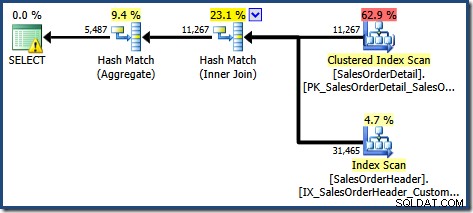
Este plano apresenta uma operação de agregação a menos do que antes. Quando a expansão de visualização foi usada, o otimizador de consulta infelizmente não conseguiu remover uma operação de agregação redundante, resultando em um plano de execução menos eficiente. A estimativa de cardinalidade final para a nova consulta também é um pouco melhor do que quando a visualização indexada foi referenciada sem
NOEXPAND :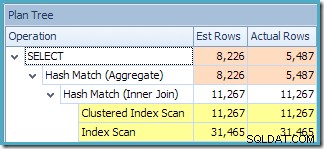
No entanto, as melhores estimativas ainda são aquelas produzidas ao referenciar a visualização indexada com
NOEXPAND (repetido abaixo por conveniência):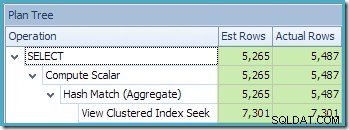
Edição Enterprise e correspondência de visualização
Em uma instância do Enterprise Edition, o otimizador de consulta pode usar uma exibição indexada mesmo que a consulta não mencione a exibição explicitamente. Se o otimizador puder corresponder parte da árvore de consulta a uma exibição indexada, ele poderá optar por fazê-lo, com base em sua estimativa dos custos de usar ou não a exibição. A lógica de correspondência de visualização é razoavelmente inteligente, mas tem limites que são muito fáceis de atingir na prática. Mesmo onde a correspondência de visualização é bem-sucedida, o otimizador ainda pode ser enganado por estimativas de custo imprecisas.
A dica de consulta EXPAND VIEWS
Começando com a mais rara das possibilidades, pode haver ocasiões em que uma consulta referencia uma visão indexada, mas um plano melhor seria obtido acessando as tabelas base. Nessas circunstâncias, a dica de consulta
EXPAND VIEWS pode ser usado:SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID
OPTION (EXPAND VIEWS); Na Enterprise Edition, essa consulta produz o mesmo plano visto na Standard Edition quando o
NOEXPAND dica foi omitida (incluindo a operação de agregação redundante):
Como um aparte, o
EXPAND VIEWS dica é mal nomeado, na minha opinião. O SQL Server sempre expande as definições de exibição em uma consulta, a menos que o NOEXPAND dica é especificada. As EXPAND VIEWS A dica desativa as regras no otimizador que podem corresponder partes da árvore expandida de volta às exibições indexadas. Na ausência de qualquer dica, o SQL Server primeiro expande uma exibição para sua definição de tabela base e, posteriormente, considera a correspondência de volta às exibições indexadas. Um nome melhor para as EXPAND VIEWS dica pode ter sido DISABLE INDEXED VIEW MATCHING , porque é isso que ele faz. As
EXPAND VIEWS A dica é provavelmente usada com mais frequência para evitar que uma consulta nas tabelas base corresponda a uma exibição indexada:SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID
OPTION (EXPAND VIEWS); A dica de consulta resulta no mesmo plano de execução e estimativas vistas quando estávamos usando o Standard Edition e a mesma consulta somente de tabela base:
Correspondência e estatísticas do Enterprise View
Mesmo na Enterprise Edition, as estatísticas de exibição não indexadas ainda são criadas apenas se o
NOEXPAND dica é usada. Para ser absolutamente claro sobre isso, o recurso de correspondência de exibição somente para empresas nunca resulta na criação ou atualização de estatísticas de exibição. Vale a pena explorar um pouco esse comportamento pouco intuitivo, pois pode ter efeitos colaterais surpreendentes. Agora executamos nossa consulta básica na visualização em uma instância do Enterprise Edition, sem nenhuma dica:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID; 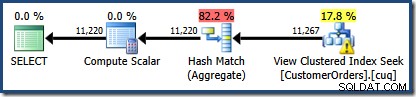
Uma coisa nova é o triângulo de aviso no View Clustered Index Seek. A dica de ferramenta mostra os detalhes:
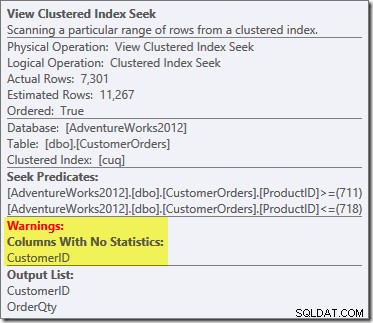
Não usamos um
NOEXPAND dica, portanto, as estatísticas na coluna ID do cliente da exibição indexada não foram criadas automaticamente. As estatísticas sobre o ID do cliente não são muito importantes neste exemplo simplificado, mas nem sempre será o caso. Estimativas curiosas de cardinalidade
A segunda coisa interessante é que as estimativas de cardinalidade parecem ser piores do que qualquer caso que encontramos até agora, incluindo os exemplos da Standard Edition.
Inicialmente, é difícil ver de onde veio a estimativa de cardinalidade para o View Clustered Index Seek (11.267). Esperamos que a estimativa seja baseada nas informações do histograma do ID do produto das estatísticas associadas ao índice clusterizado de visualização. A parte relevante deste histograma é mostrada abaixo:
DBCC SHOW_STATISTICS
('dbo.CustomerOrders', 'cuq')
WITH HISTOGRAM; 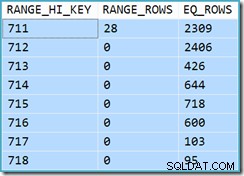
Dado que a tabela não foi modificada desde que as estatísticas foram criadas, esperamos que a estimativa seja uma simples soma de RANGE_ROWS e EQ_ROWS para valores de ID do produto entre 711 e 718 (observe que a estimativa deve excluir os 28 RANGE_ROWS mostrados em relação à entrada 711 já que essas linhas existem abaixo do valor da chave 711). A soma do EQ_ROWS mostrado é 7.301. Este é exatamente o número de linhas realmente retornado pela exibição - então, de onde veio a estimativa de 11.267?
A resposta está na maneira como a correspondência de visualizações funciona atualmente. Nossa consulta não especificou o
NOEXPAND dica, portanto, as estimativas de cardinalidade iniciais são baseadas na árvore de consulta expandida de exibição. Isso é mais fácil de ver olhando novamente para o plano estimado para a mesma consulta com EXPAND VIEWS Especificadas: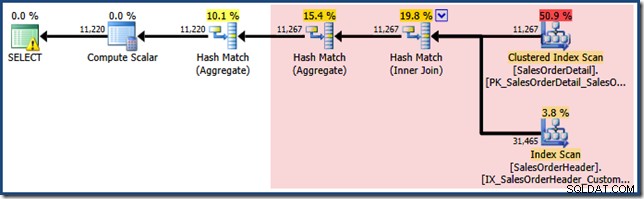
A área sombreada em vermelho representa a parte da árvore que é substituída pela atividade de correspondência de visualização. A cardinalidade de saída desta área é 11.267. A parte não sombreada com a estimativa de 11.220 não é afetada pela correspondência de visualização. Estas são exatamente as estimativas que estávamos procurando explicar:
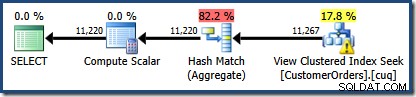
A correspondência de exibição simplesmente substituiu a área sombreada em vermelho por uma busca logicamente equivalente na exibição indexada. Ele não usou informações estatísticas da exibição para recalcular a estimativa de cardinalidade.
Até certo ponto, você provavelmente pode entender por que isso pode funcionar dessa maneira:em geral, há poucas razões para esperar que uma estimativa calculada a partir de um conjunto de informações estatísticas seja melhor do que outra. Pode-se argumentar que as estatísticas de visualizações indexadas são mais prováveis de serem precisas aqui, em comparação com as estatísticas derivadas pós-junção na área sombreada em vermelho, mas pode ser complicado generalizar isso ou explicar corretamente a rapidez com que várias fontes de as informações estatísticas podem ficar desatualizadas à medida que os dados subjacentes mudam.
Pode-se também argumentar que, se tivéssemos tanta certeza de que as informações da visualização indexada eram melhores, teríamos usado um
NOEXPAND dica. Estimativas de cardinalidade ainda mais curiosas
Uma situação ainda mais interessante surge com a Enterprise Edition se escrevermos a consulta nas tabelas base e contarmos com a correspondência automatizada de visualizações:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID; 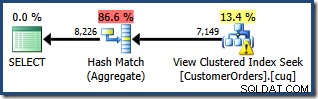
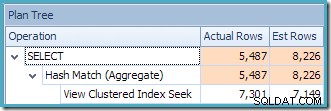
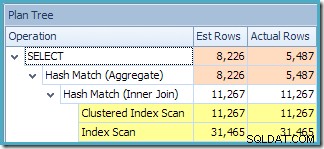
O aviso de estatísticas ausentes é o mesmo de antes e tem a mesma explicação. O recurso mais interessante é que agora temos uma estimativa menor para o número de linhas produzidas pelo View Clustered Index Seek (7.149) e uma estimativa aumentada para o número de linhas retornadas da agregação (8.226).
Para enfatizar o ponto, esse plano de consulta parece ser baseado na ideia de que 7.149 linhas de origem podem ser agregadas para produzir 8.226 linhas!
Parte da explicação é a mesma de antes. As
EXPAND VIEWS plano de consulta, mostrando a região vermelha que será substituída pela correspondência de exibição é mostrada abaixo: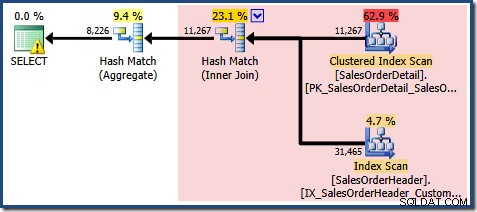
Isso explica de onde vem a estimativa final de 8.226, mas e a estimativa de 7.149 linhas? Seguindo a lógica vista anteriormente, parece que a exibição deveria mostrar uma estimativa de 11.267 linhas?
A resposta é que a estimativa de 7.149 é um palpite. Sim, realmente. A exibição indexada contém 79.433 linhas no total. A porcentagem de estimativa mágica para o predicado Product ID BETWEEN é de 9% – fornecendo 0,09 * 79433 =7148,97 linhas. O plano de consulta do SSMS mostra que esse cálculo está exatamente correto, mesmo antes do arredondamento:
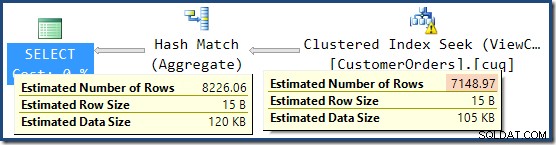
Nessa situação, o otimizador do SQL Server parece ter preferido uma estimativa com base na cardinalidade de exibição indexada sobre a estimativa de cardinalidade pós-junção da subárvore substituída. Curioso.
Resumo
Usando o
NOEXPAND A dica garante que uma exibição indexada será usada no plano de consulta final e permite que estatísticas não indexadas sejam criadas, mantidas e usadas automaticamente pelo otimizador de consulta. Usando NOEXPAND também garante que as estimativas de cardinalidade inicial sejam baseadas em informações de exibição indexadas em vez de serem derivadas de tabelas base. Se
NOEXPAND não for especificado, as referências de exibição são sempre substituídas por suas definições de tabela base antes do início da compilação da consulta (e, portanto, antes da estimativa inicial de cardinalidade). Somente em SKUs Corporativos, as exibições indexadas podem ser substituídas novamente na árvore de consulta posteriormente no processo de otimização. As
EXPAND VIEWS a dica de consulta impede que o otimizador execute a correspondência de exibição indexada do Enterprise Edition. Isso se aplica se a consulta fez referência originalmente a uma exibição indexada ou não. Quando a correspondência de visualização é executada, uma estimativa de cardinalidade existente pode ser substituída por uma estimativa em algumas circunstâncias. As estatísticas mostradas como ausentes em uma exibição indexada podem ser criadas manualmente, mas o otimizador geralmente não as usará para consultas que não usam um
NOEXPAND dica. O uso de exibições indexadas pode melhorar a estimativa de cardinalidade, principalmente se a exibição contiver junções ou agregações. As consultas têm a melhor chance de se beneficiar de estatísticas de visualização mais precisas se
NOEXPAND é especificado.