Em minha última postagem, demonstrei que em pequenos volumes, um TVP com otimização de memória pode oferecer benefícios substanciais de desempenho para padrões de consulta típicos.
Para testar em uma escala um pouco maior, fiz uma cópia do
SalesOrderDetailEnlarged table, que eu havia expandido para aproximadamente 5.000.000 de linhas graças a este script de Jonathan Kehayias (blog | @SQLPoolBoy)). DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Também criei três versões na memória dessa tabela, cada uma com uma contagem de baldes diferente (pescando um "ponto ideal") - 16.384, 131.072 e 1.048.576. (Você pode usar números arredondados, mas eles são arredondados para a próxima potência de 2 de qualquer maneira.) Exemplo:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Observe que alterei o tamanho do bucket do exemplo anterior (256). Ao construir a tabela, você deseja escolher o "ponto ideal" para o tamanho do bucket – você deseja otimizar o índice de hash para pesquisas de ponto, o que significa que deseja o maior número possível de buckets com o menor número possível de linhas em cada bucket. É claro que se você criar ~5 milhões de buckets (já que nesse caso, talvez não seja um exemplo muito bom, existem ~5 milhões de combinações únicas de valores), você terá algumas trocas de utilização de memória e coleta de lixo para lidar. No entanto, se você tentar colocar cerca de 5 milhões de valores exclusivos em 256 buckets, também terá alguns problemas. De qualquer forma, essa discussão vai muito além do escopo dos meus testes para este post.
Para testar em relação à tabela padrão, fiz procedimentos armazenados semelhantes aos dos testes anteriores:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Então, primeiro, veja os planos para, digamos, 1.000 linhas sendo inseridas nas variáveis da tabela e, em seguida, execute os procedimentos:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Desta vez, vemos que em ambos os casos, o otimizador escolheu uma busca de índice clusterizado contra a tabela base e uma junção de loops aninhados contra o TVP. Algumas métricas de custo são diferentes, mas os planos são bastante semelhantes:
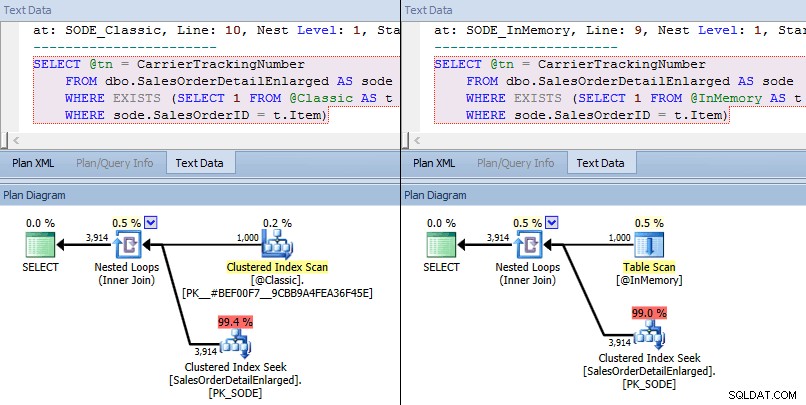 Planos semelhantes para TVP na memória x TVP clássica em maior escala
Planos semelhantes para TVP na memória x TVP clássica em maior escala 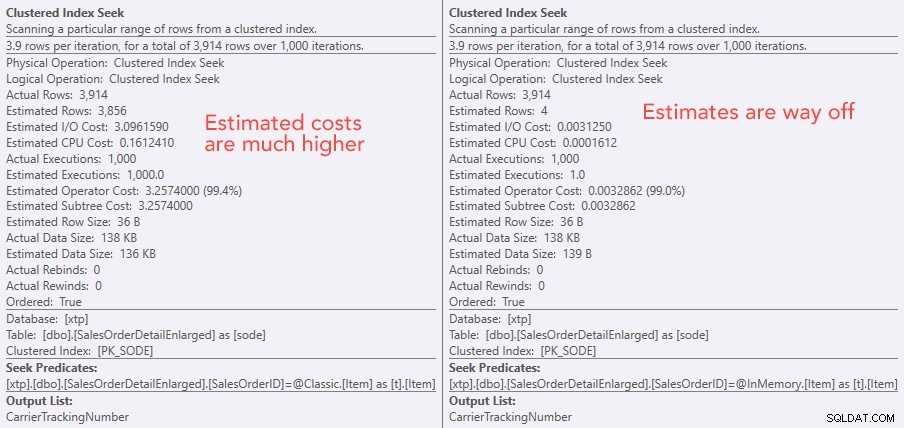 Comparando os custos do operador de busca – Clássico à esquerda, In-Memory à direita
Comparando os custos do operador de busca – Clássico à esquerda, In-Memory à direita O valor absoluto dos custos faz parecer que o TVP clássico seria muito menos eficiente que o TVP In-Memory. Mas eu me perguntava se isso seria verdade na prática (especialmente porque o número estimado de execuções à direita parecia suspeito), então, é claro, fiz alguns testes. Resolvi comparar 100, 1.000 e 2.000 valores a serem enviados para o procedimento.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Os resultados de desempenho mostram que, em um número maior de pesquisas de ponto, o uso de um In-Memory TVP leva a retornos ligeiramente decrescentes, sendo um pouco mais lento a cada vez:
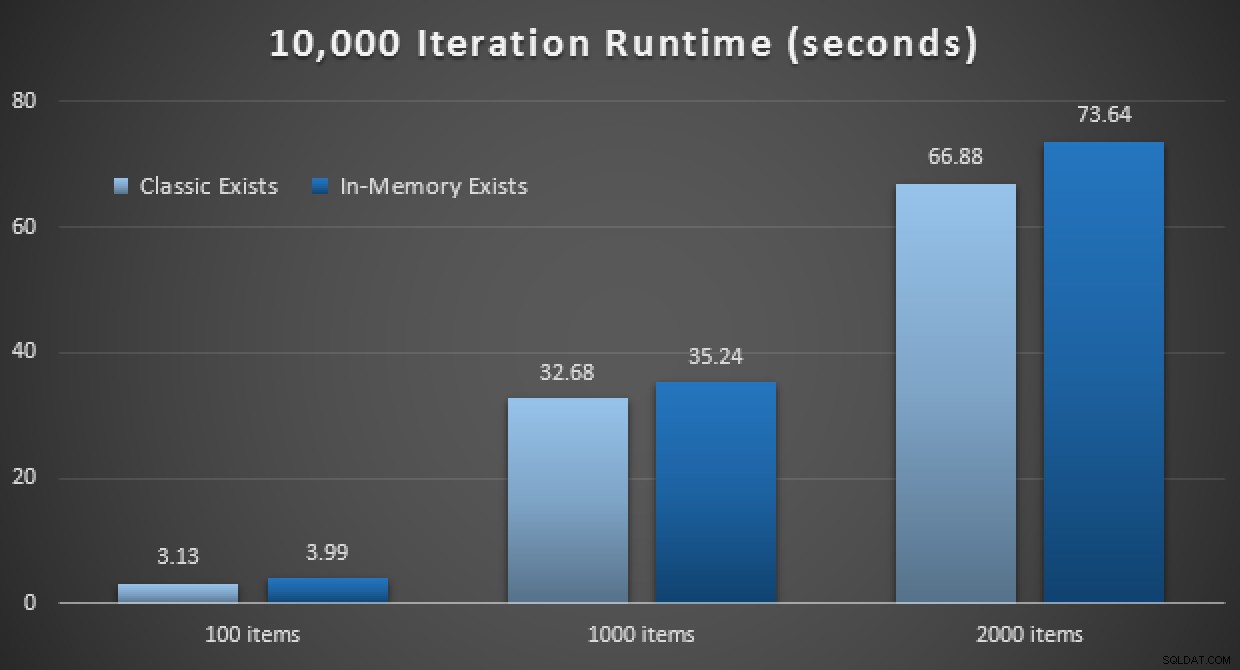
Resultados de 10.000 execuções usando TVPs clássico e in-memory
Portanto, ao contrário da impressão que você pode ter tirado do meu post anterior, usar um TVP na memória não é necessariamente benéfico em todos os casos.
Anteriormente, também examinei procedimentos armazenados compilados nativamente e tabelas na memória, em combinação com TVPs na memória. Isso pode fazer a diferença aqui? Spoiler:absolutamente não. Eu criei três procedimentos assim:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Outro spoiler:não consegui executar esses 9 testes com uma contagem de iteração de 10.000 – demorou muito. Em vez disso, fiz um loop e executei cada procedimento 10 vezes, executei esse conjunto de testes 10 vezes e tirei a média. Aqui estão os resultados:
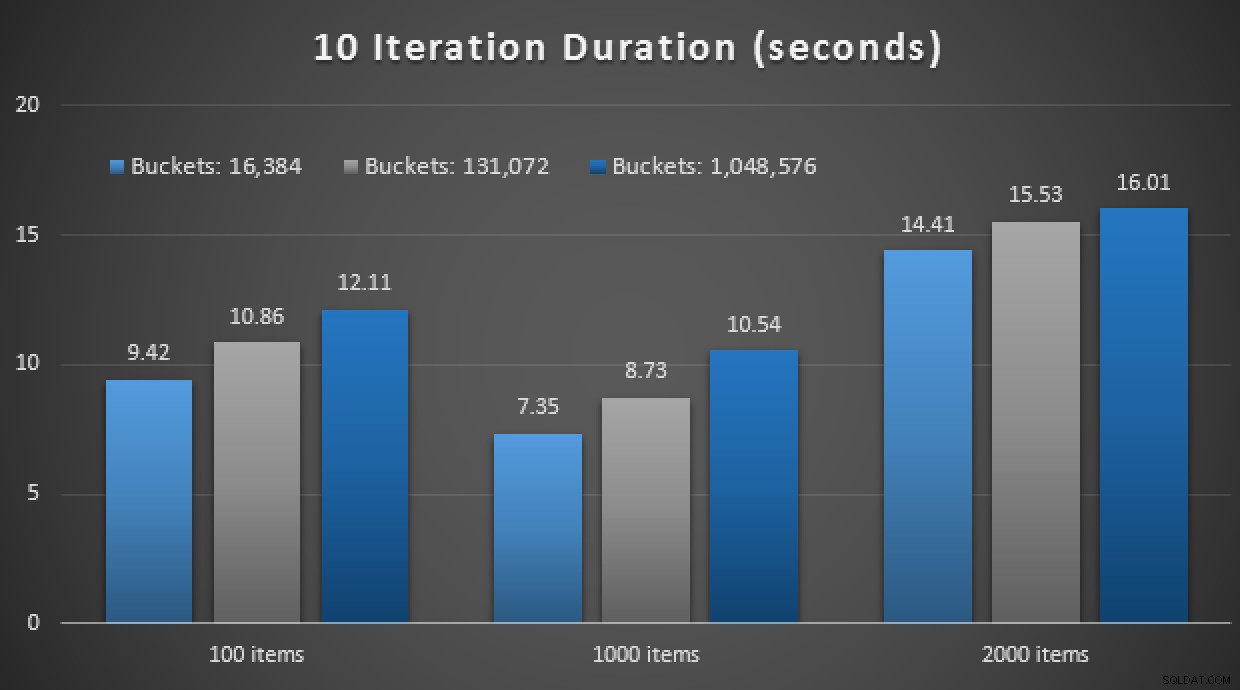
Resultados de 10 execuções usando TVPs na memória e compilados nativamente armazenados procedimentos
No geral, este experimento foi bastante decepcionante. Apenas olhando para a magnitude da diferença, com uma tabela em disco, a chamada média de procedimento armazenado foi concluída em uma média de 0,0036 segundos. No entanto, quando tudo estava usando tecnologias na memória, a chamada média de procedimento armazenado foi de 1,1662 segundos. Ai . É altamente provável que eu tenha escolhido um caso de uso ruim para demonstração geral, mas na época parecia ser uma "primeira tentativa" intuitiva.
Conclusão
Há muito mais para testar em torno deste cenário, e tenho mais posts para seguir. Ainda não identifiquei o caso de uso ideal para TVPs na memória em uma escala maior, mas espero que este post sirva como um lembrete de que, embora uma solução pareça ótima em um caso, nunca é seguro supor que seja igualmente aplicável a diferentes cenários. É exatamente assim que o OLTP In-Memory deve ser abordado:como uma solução com um conjunto restrito de casos de uso que absolutamente devem ser validados antes de serem implementados em produção.