A replicação do MariaDB é uma das soluções de alta disponibilidade mais populares para o MariaDB e amplamente utilizada por grandes empresas como Booking.com e Google. É muito fácil de configurar, com algumas compensações na manutenção contínua, como atualizações de software, alterações de esquema, alterações de topologia, failover e recuperação, que sempre foram complicadas. No entanto, com o conjunto de ferramentas certo, você poderá lidar com a topologia com facilidade. Nesta postagem do blog, veremos algumas dicas para monitorar a replicação do MariaDB com eficiência usando o ClusterControl.
Usando o visualizador de topologia
Uma configuração de replicação consiste em várias funções. Um nó em uma configuração de replicação pode ser:
- Mestre - O principal escritor/leitor.
- Backup master - Um slave somente leitura com replicação semi-síncrona, exclusivamente para redundância do master.
- Mestre intermediário - Replica a partir de um mestre, enquanto outros escravos replicam a partir deste nó.
- Servidor de log binário - apenas colete/armazene logs binários sem fornecer dados.
- Escravo - Replicar de um mestre e geralmente definido como somente leitura.
- Escravo de várias origens - Replicar de vários mestres.
Cada função tem sua própria responsabilidade e limitação e é preciso entender a topologia correta ao lidar com os nós do banco de dados. Isso também é verdade para o aplicativo, onde o aplicativo precisa gravar apenas no nó mestre em um determinado momento. Assim, é importante ter uma visão geral de qual nó está mantendo qual função, para não estragarmos nosso banco de dados.
No ClusterControl, o Topology Viewer pode fornecer uma visão geral da topologia de replicação e seu estado, conforme mostrado na captura de tela a seguir:
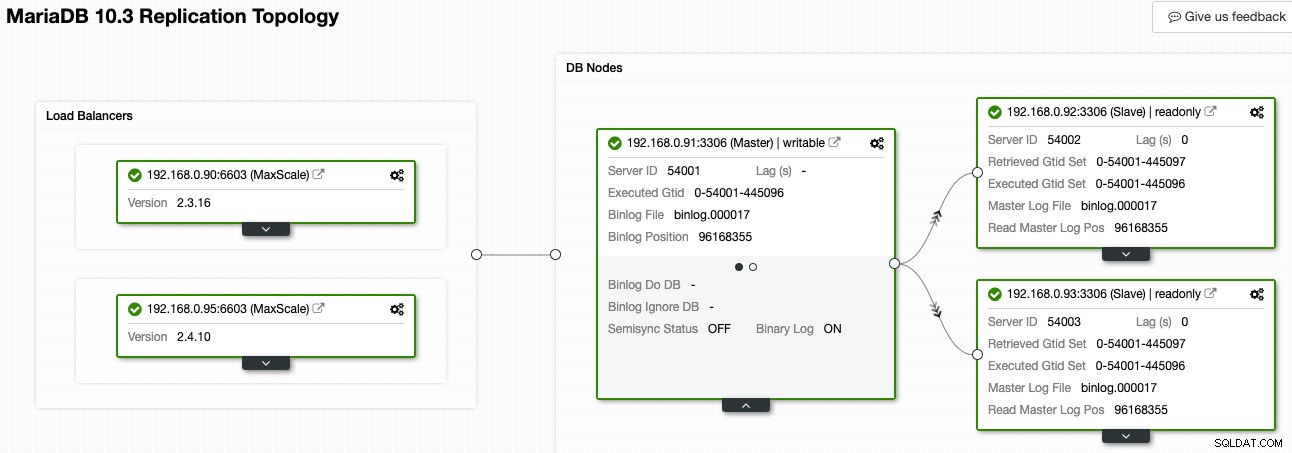
O ClusterControl entende a replicação do MariaDB e é capaz de visualizar a topologia com o fluxo de dados de replicação correto, conforme representado pelas setas apontadas para os nós escravos. Podemos distinguir facilmente qual nó é o mestre, escravos e balanceadores de carga (MaxScale) em nossa configuração de replicação. A caixa verde indica que todos os serviços importantes estão sendo executados conforme o esperado com a função atribuída.
Considere a captura de tela a seguir em que vários de nossos nós estão com problemas:
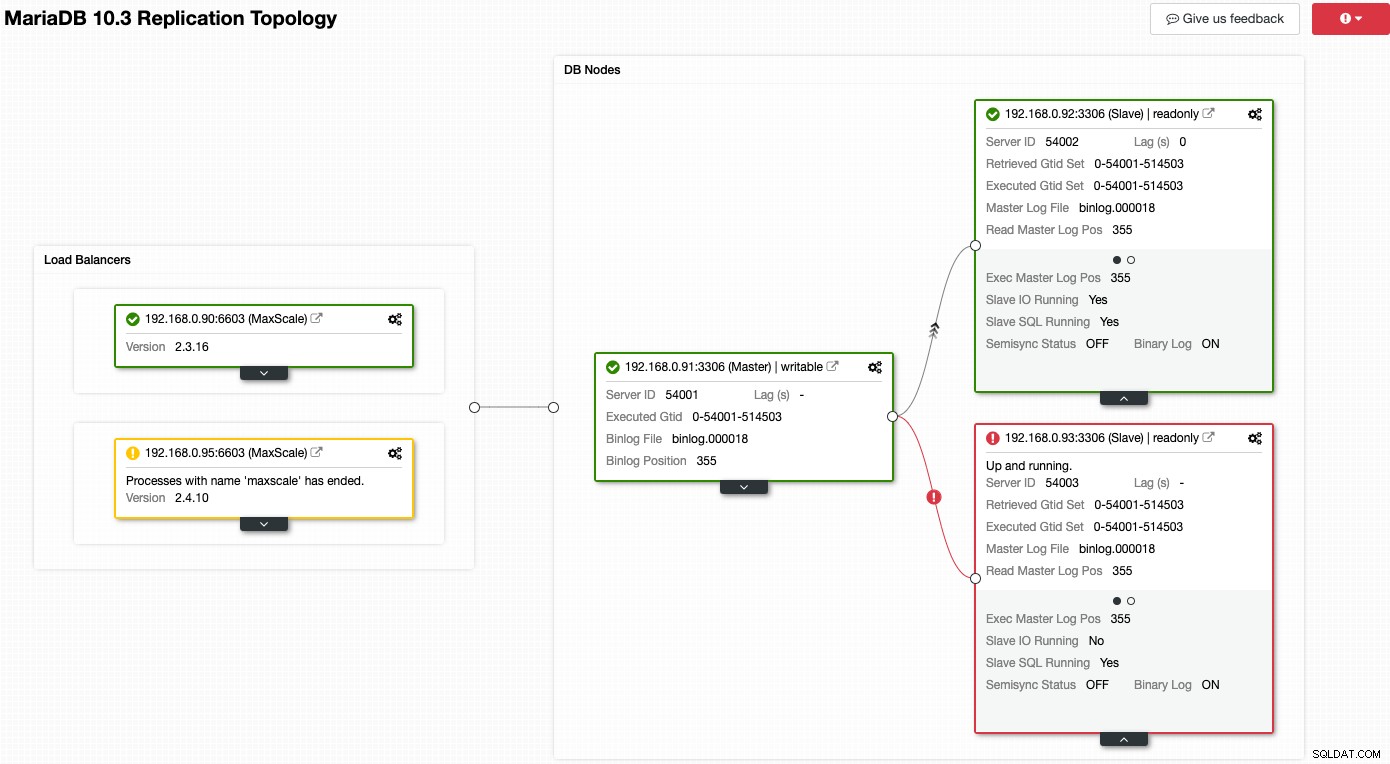
O ClusterControl informará imediatamente o que há de errado com a topologia atual. Um dos escravos (caixa vermelha) está mostrando "Slave IO Running" como Não, para indicar algum problema de conectividade para replicar do mestre. Enquanto a caixa amarela mostra que nosso serviço MaxScale não está em execução. Também podemos dizer que as versões MaxScale não são idênticas para ambos os nós. Você também pode executar tarefas de gerenciamento clicando no ícone de engrenagem (canto superior direito em cada caixa) diretamente, o que reduz os riscos de pegar um nó errado.
Atraso de replicação
Esta é a coisa mais importante se você confiar na consistência da replicação de dados. O atraso de replicação ocorre quando os escravos não conseguem acompanhar as atualizações que acontecem no mestre. As alterações não aplicadas se acumulam nos registros de retransmissão dos escravos e a versão do banco de dados nos escravos se torna cada vez mais diferente da do mestre.
No ClusterControl, você pode encontrar o histograma de atraso de replicação em Visão geral -> Lag de replicação, onde o ClusterControl amostra constantemente o valor Seconds_Behind_Master da saída "SHOW SLAVE STATUS":
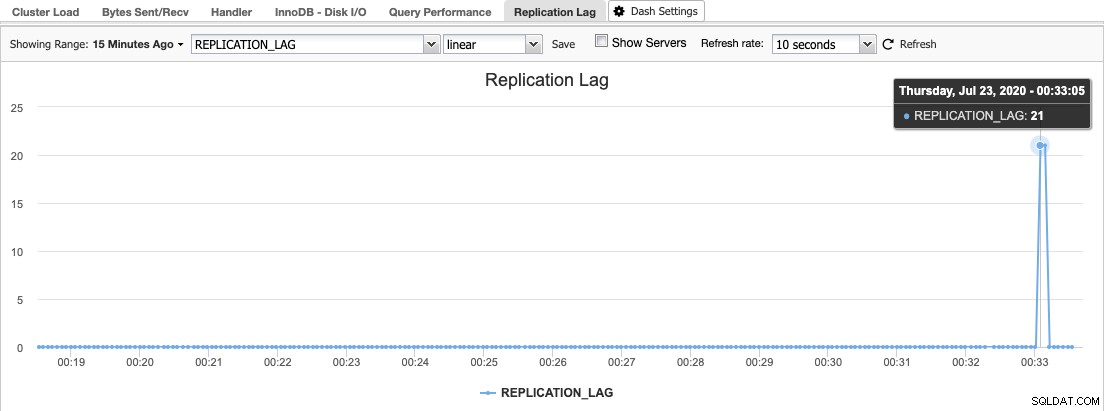
O atraso de replicação ocorre quando o Thread de E/S ou o Thread SQL não consegue lidar com as demandas impostas a ele. Se o Thread de E/S estiver sofrendo, isso significa que a conexão de rede entre o mestre e seus escravos está lenta ou com problemas. Você pode querer considerar habilitar o slave_compressed_protocol para compactar o tráfego de rede ou reportar ao seu administrador de rede.
Se for o thread SQL, o problema provavelmente se deve a consultas mal otimizadas que estão demorando muito para o escravo ser aplicado. Pode haver transações de longa duração ou muita atividade de E/S. Não ter chave primária nas tabelas escravas ao usar o formato de replicação ROW ou MIXED também é uma causa comum de atraso nesse encadeamento. Verifique se as versões master e slave das tabelas possuem uma chave primária.
Mais algumas dicas e truques são abordados nesta postagem do blog, Como reduzir o atraso de replicação em implantações de várias nuvens.
Tamanho do log binário/relê
É importante monitorar o tamanho do disco de logs binários e de retransmissão, pois isso pode consumir uma quantidade considerável de armazenamento em cada nó em um cluster de replicação. Normalmente, pode-se definir a variável de sistema expire_logs_days para expirar arquivos de log binários automaticamente após um determinado número de dias, por exemplo, expire_logs_days=7. O tamanho dos logs binários é totalmente dependente do número de eventos binários criados (gravações de entrada) e pouco sabemos quanto espaço em disco consumiria antes que os logs fossem expirados pelo MariaDB. Tenha em mente que se você habilitar log_slave_updates nos escravos, o tamanho dos logs será quase o dobro devido à existência de logs binários e de retransmissão no mesmo servidor.
Para ClusterControl, podemos definir um limite de utilização de espaço em disco em ClusterControl -> Configurações -> Limites para obter um aviso e notificações críticas conforme abaixo:
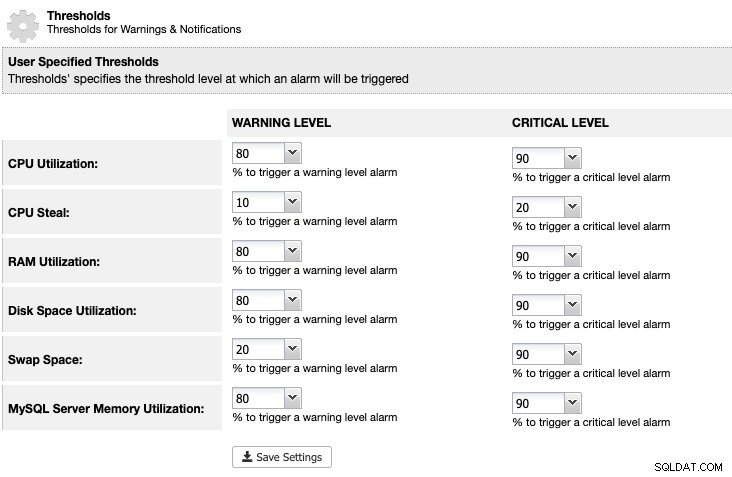
ClusterControl monitora todo o espaço em disco relacionado aos serviços do MariaDB, como a localização dos dados do MariaDB diretório, o diretório de logs binários e também a partição raiz. Se você atingiu o limite, considere limpar os logs binários manualmente usando o comando PURGE BINARY LOGS, conforme explicado e discutido neste artigo.
Ativar painéis de monitoramento
O ClusterControl fornece duas opções de monitoramento para amostrar os nós do banco de dados - sem agente ou com base em agente. O padrão é sem agente onde a amostragem acontece via SSH em um mecanismo somente pull. O monitoramento baseado em agente requer que um servidor Prometheus esteja em execução e que todos os nós monitorados sejam configurados com pelo menos três exportadores:
- Exportador de processo (porta 9011)
- Exportador de métricas de nó/sistema (porta 9100)
- Exportador MySQL/MariaDB (porta 9104)
Para habilitar o painel de monitoramento baseado em agente, deve-se ir para ClusterControl -> Dashboards -> Enable Agent Based Monitoring. Uma vez ativado, você verá um conjunto de painéis configurados para nossa replicação MariaDB, o que nos dá uma visão muito melhor sobre nossa configuração de replicação. A captura de tela a seguir mostra o que você veria para o nó mestre:
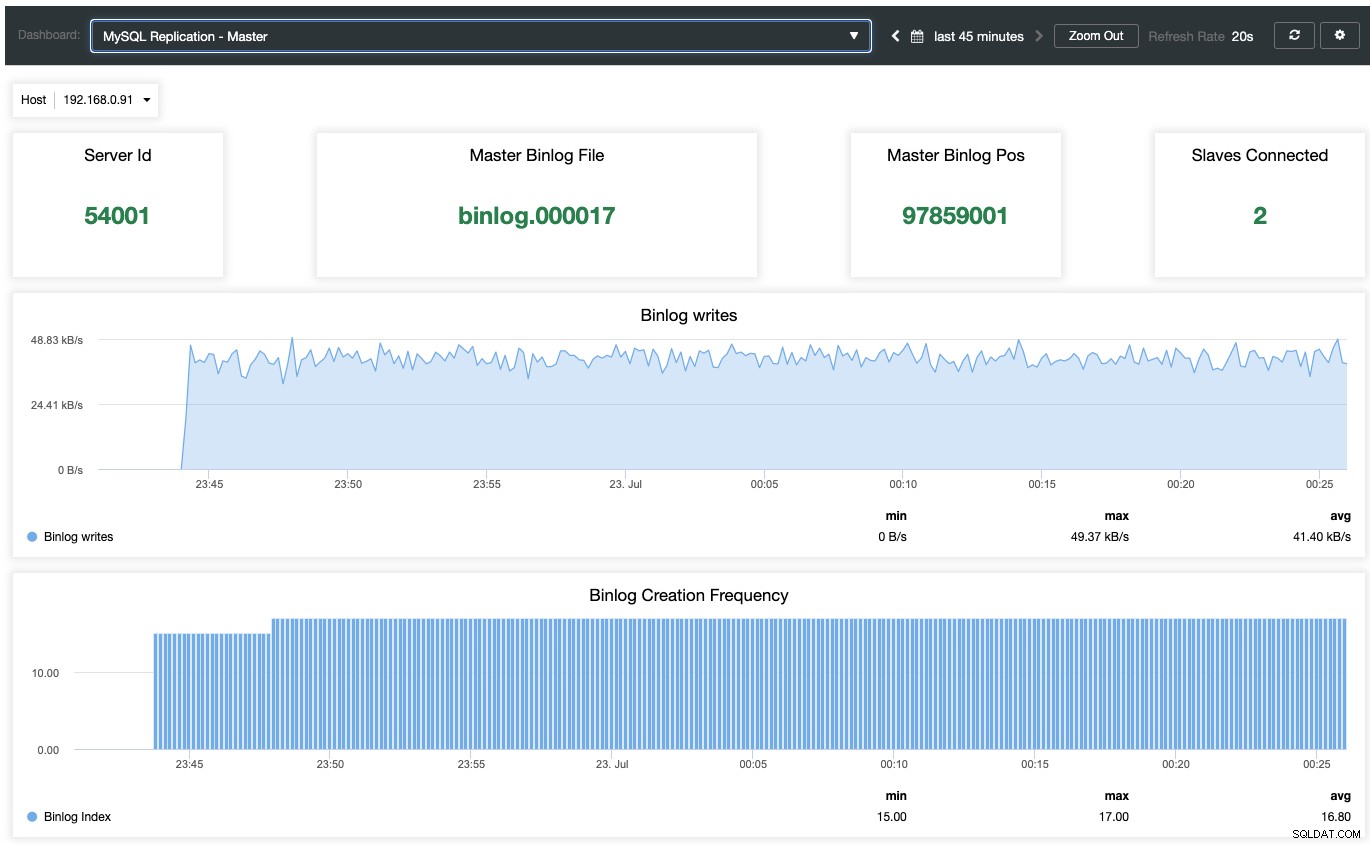
Além dos painéis de monitoramento padrão do MariaDB, como geral, caches e métricas do InnoDB, você será apresentado com um painel de replicação. Para o nó mestre, podemos obter muitas informações úteis sobre o estado do mestre, a taxa de transferência de gravação e a frequência de criação de log binário.
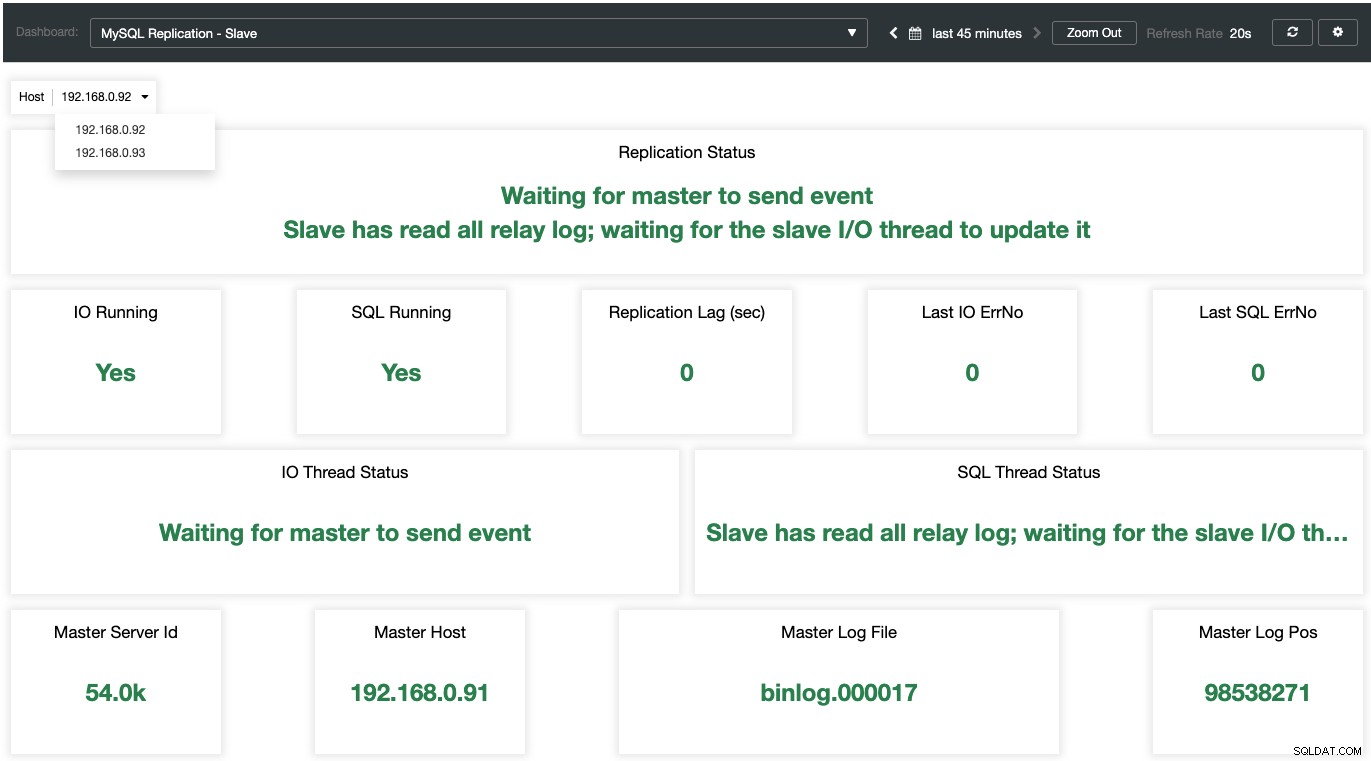
Enquanto para os escravos, todos os estados importantes são amostrados e resumidos na captura de tela a seguir. se tudo estiver verde, você está em boas mãos:
Compreendendo o log de erros do MariaDB
MariaDB registra seus eventos importantes dentro do log de erros, o que é útil para entender o que estava acontecendo com o servidor, principalmente antes, durante e depois de uma mudança de topologia. O ClusterControl fornece uma visão centralizada dos logs de erros em ClusterControl -> Logs -> System Logs, puxando-os de cada nó do banco de dados. Você clica em "Atualizar logs" para acionar um trabalho para extrair os logs mais recentes do servidor.
Os arquivos coletados são representados em uma estrutura de árvore de navegação e uma área de texto com destaque de sintaxe para melhor legibilidade:
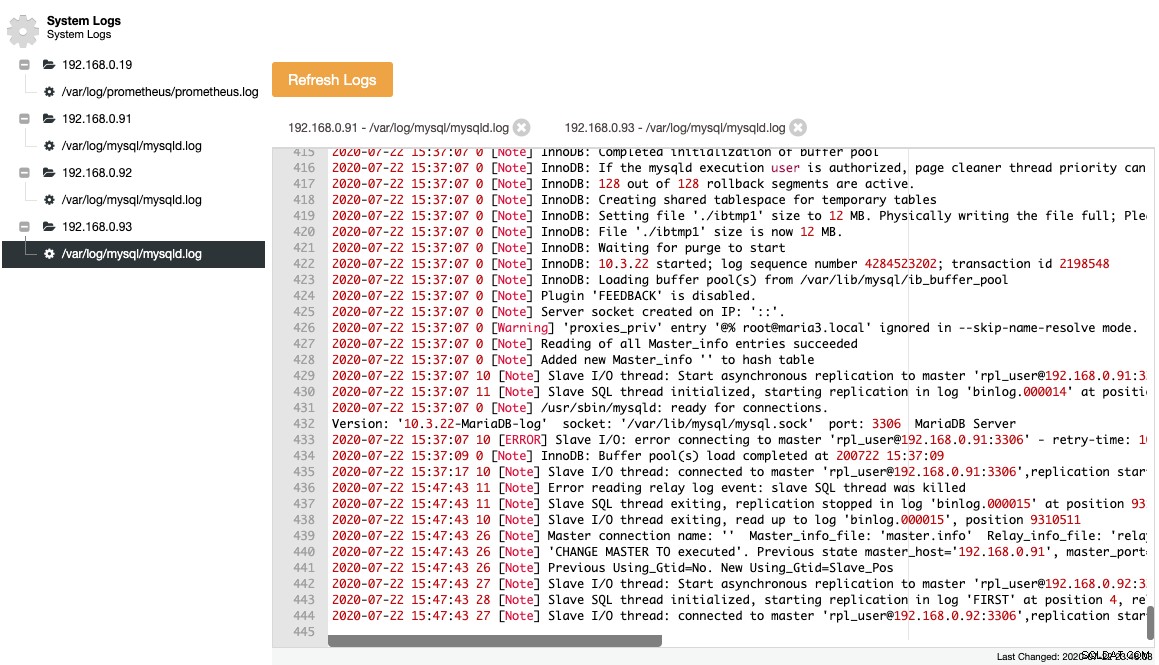
A partir da captura de tela acima, podemos entender a sequência de eventos e o que aconteceu com esse nó durante um evento de alteração de topologia. Das últimas 12 linhas do log de erros acima, o escravo teve um erro ao se conectar ao mestre e o último arquivo de log binário e a posição foram registrados no log antes de parar. Em seguida, um comando CHANGE MASTER mais recente foi executado com informações do GTID, conforme mostrado na linha "Anterior Using_Gtid=No. New Using_Gtid=Slave_Pos" e então a replicação continua conforme queríamos.
Alerta e notificações do MariaDB
O monitoramento está incompleto sem alertas e notificações. Todos os eventos e alarmes gerados pelo ClusterControl podem ser enviados para o e-mail ou qualquer outra ferramenta de terceiros suportada. Para notificações por e-mail, pode-se configurar se o tipo de evento será entregue imediatamente, ignorado ou digerido (um relatório resumido diário):

Para todos os eventos de gravidade crítica, é recomendável definir tudo como "Entregar" para que você receba as notificações o mais rápido possível. Defina "Digest" para eventos de aviso para que você esteja bem ciente da integridade e do estado do cluster.
Você pode integrar suas ferramentas de comunicação e mensagens preferidas com o ClusterControl usando o recurso Gerenciamento de Notificações em ClusterControl -> Integrações -> Notificações de terceiros. O ClusterControl pode enviar alarmes e eventos para PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow ou qualquer webhooks registrado pelo usuário.
A captura de tela a seguir mostra que todos os eventos críticos serão enviados para o canal de telegrama configurado para nosso cluster de replicação MariaDB 10.3:

O ClusterControl também oferece suporte à integração de chatbot, onde você pode interagir com o serviço do controlador via cliente s9s diretamente de sua ferramenta de mensagens, conforme mostrado nesta postagem do blog, Automatize seu banco de dados com CCBot:ClusterControl Hubot Integration.
Conclusão
O ClusterControl oferece um conjunto completo de ferramentas de monitoramento proativo para seus clusters de banco de dados. Use o ClusterControl para monitorar sua configuração de replicação MariaDB porque a maioria dos recursos de monitoramento está disponível gratuitamente na edição da comunidade. Não perca aqueles!