No momento em que escrevo, o T-SQL não suporta essas opções, mas nos links a seguir você pode encontrar solicitações de melhoria de recursos solicitando sua inclusão no T-SQL no futuro e votar neles:
- Adicione suporte para a cláusula ISO/IEC SQL SEARCH para CTEs recursivos em T-SQL
- Adicione suporte para a cláusula ISO/IEC SQL CYCLE para CTEs recursivos em T-SQL
Nas seções a seguir, descreverei as duas opções padrão e também fornecerei soluções alternativas logicamente equivalentes que estão atualmente disponíveis no T-SQL.
cláusula SEARCH
A cláusula SEARCH padrão define a ordem de busca recursiva como BREADTH FIRST ou DEPTH FIRST por algumas colunas de ordenação especificadas e cria uma nova coluna de sequência com as posições ordinais dos nós visitados. Você especifica BREADTH FIRST para pesquisar primeiro em cada nível (largura) e depois nos níveis (profundidade). Você especifica DEPTH FIRST para pesquisar primeiro para baixo (profundidade) e depois transversalmente (largura).
Você especifica a cláusula SEARCH logo antes da consulta externa.
Vou começar com um exemplo de ordem de busca recursiva em largura. Apenas lembre-se de que esse recurso não está disponível no T-SQL, portanto, você não poderá executar os exemplos que usam as cláusulas padrão no SQL Server ou no Banco de Dados SQL do Azure. O código a seguir retorna a subárvore do funcionário 1, solicitando uma ordem de busca em largura por empid, criando uma coluna de sequência chamada seqbreadth com as posições ordinais dos nós visitados:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) PESQUISE LARGURA PRIMEIRO POR empid SET seqbreadth------------------------------------------------------ ---- SELECT empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Aqui está a saída desejada deste código:
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Seraph 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
Não se confunda com o fato de que os valores seqbreadth parecem ser idênticos aos valores empid. Isso é apenas por acaso, como resultado da maneira como atribuí manualmente os valores empid nos dados de amostra que criei.
A Figura 2 apresenta uma representação gráfica da hierarquia de funcionários, com uma linha pontilhada mostrando a amplitude da primeira ordem em que os nós foram pesquisados. Os valores empid aparecem logo abaixo dos nomes dos funcionários e os valores seqbreadth atribuídos aparecem no canto inferior esquerdo de cada caixa.
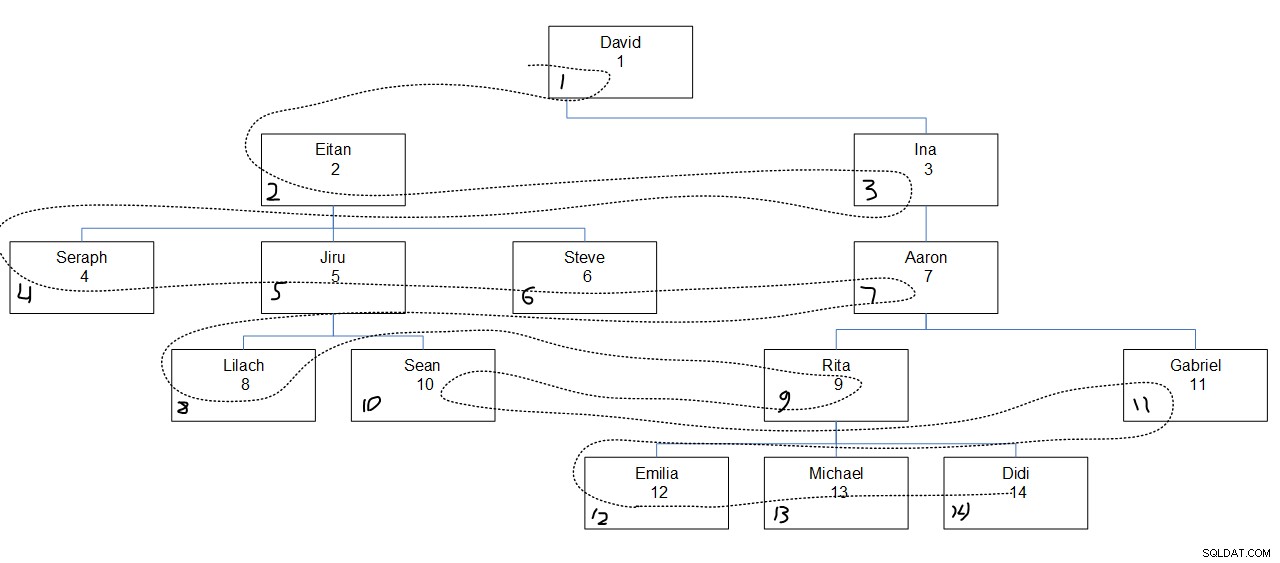 Figura 2:abrangência da pesquisa primeiro
Figura 2:abrangência da pesquisa primeiro
O que é interessante notar aqui é que dentro de cada nível, os nós são pesquisados com base na ordem de coluna especificada (empid no nosso caso), independentemente da associação pai do nó. Por exemplo, observe que no quarto nível Lilach é acessado primeiro, Rita em segundo, Sean em terceiro e Gabriel por último. Isso porque, entre todos os funcionários do quarto nível, essa é a ordem deles com base em seus valores empíricos. Não é como se Lilach e Sean fossem revistados consecutivamente porque são subordinados diretos do mesmo gerente, Jiru.
É bastante simples criar uma solução T-SQL que forneça o equivalente lógico da opção padrão SAERCH DEPTH FIRST. Você cria uma coluna chamada lvl como mostrei anteriormente para rastrear o nível do nó em relação à raiz (0 para o primeiro nível, 1 para o segundo e assim por diante). Em seguida, você calcula a coluna de sequência de resultados desejada na consulta externa usando uma função ROW_NUMBER. Conforme a ordenação da janela você especifica primeiro o lvl, e depois a coluna de ordenação desejada (empid no nosso caso). Aqui está o código da solução completa:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM CORDER BY seqbreadth;
Em seguida, vamos examinar a ordem de pesquisa DEPTH FIRST. De acordo com o padrão, o código a seguir deve retornar a subárvore do funcionário 1, solicitando uma ordem de busca em profundidade por empid, criando uma coluna de sequência chamada seqdepth com as posições ordinais dos nós pesquisados:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) PROFUNDIDADE DE PESQUISA PRIMEIRO POR empid SET seqdepth---------------------------------------- SELECT empid, mgrid, empname, seqdepthFROM CORDER BY seqdepth;
A seguir está a saída desejada deste código:
empid mgrid empname seqdepth------ ------ -------- ---------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
Observando a saída de consulta desejada, provavelmente é difícil descobrir por que os valores de sequência foram atribuídos da maneira que foram. A Figura 3 deve ajudar. Ele tem uma representação gráfica da hierarquia de funcionários, com uma linha pontilhada refletindo a primeira ordem de pesquisa em profundidade, com os valores de sequência atribuídos no canto inferior esquerdo de cada caixa.
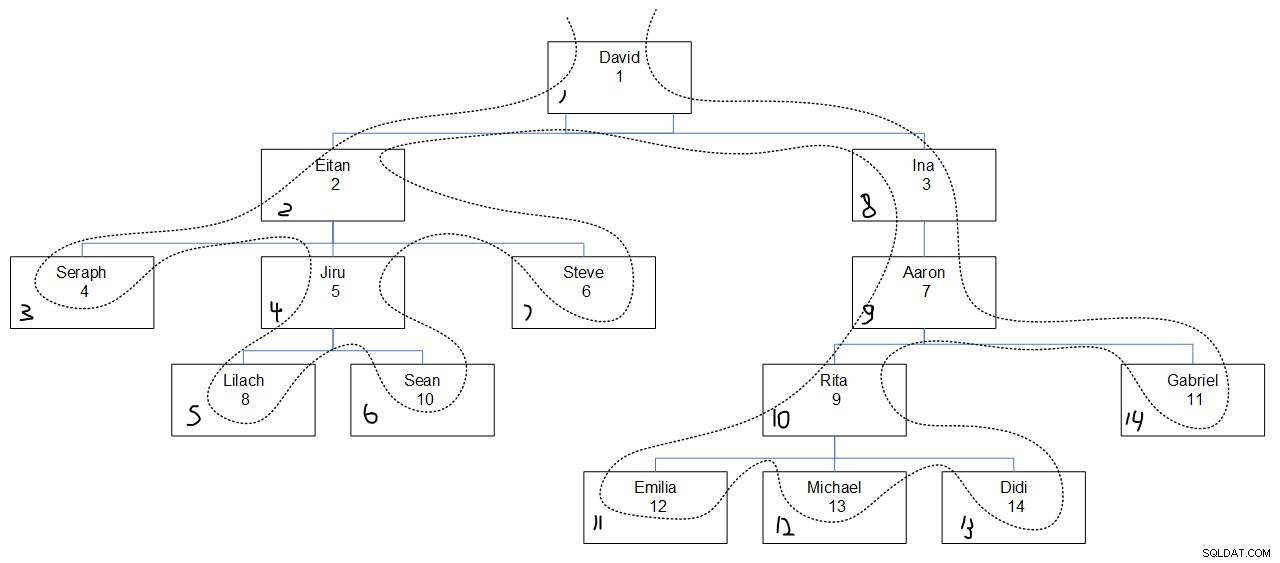 Figura 3:profundidade de pesquisa primeiro
Figura 3:profundidade de pesquisa primeiro
Criar uma solução T-SQL que forneça o equivalente lógico da opção padrão SEARCH DEPTH FIRST é um pouco complicado, mas factível. Vou descrever a solução em duas etapas.
Na Etapa 1, para cada nó você computa um caminho de classificação binário que é feito de um segmento por ancestral do nó, com cada segmento refletindo a posição de classificação do ancestral entre seus irmãos. Você constrói este caminho de forma semelhante à forma como calcula a coluna lvl. Ou seja, comece com uma string binária vazia para o nó raiz na consulta âncora. Então, na consulta recursiva, você concatena o caminho do pai com a posição de classificação do nó entre os irmãos depois de convertê-lo em um segmento binário. Você usa a função ROW_NUMBER para calcular a posição, particionada pelo pai (mgrid em nosso caso) e ordenada pela coluna de ordenação relevante (empid em nosso caso). Você converte o número da linha em um valor binário de tamanho suficiente dependendo do número máximo de filhos diretos que um pai pode ter em seu gráfico. BINARY(1) suporta até 255 filhos por pai, BINARY(2) suporta 65.535, BINARY(3):16.777.215, BINARY(4):4.294.967.295. Em uma CTE recursiva, as colunas correspondentes nas consultas âncora e recursivas devem ser do mesmo tipo e tamanho , portanto, certifique-se de converter o caminho de classificação em um valor binário do mesmo tamanho em ambos.
Aqui está o código que implementa a Etapa 1 em nossa solução (assumindo que BINARY(1) é suficiente por segmento, o que significa que você não tem mais de 255 subordinados diretos por gerente):
DECLARE @root AS INT =1; WITH C AS(SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Este código gera a seguinte saída:
empid mgrid empname sortpath------ ------ -------- -----------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 rita 0x02010111 7 Gabriel 0x02010212 9 Emilia 0x0201010113 9 Michael 0x0201010214 9 DIDI 0x02010101034 2 Seraph 0x01015 2 Jiru 0x01026 2 Steve 0x010108 5 LILLC
Observe que usei uma string binária vazia como o caminho de classificação para o nó raiz da única subárvore que estamos consultando aqui. Caso o membro âncora possa potencialmente retornar múltiplas raízes de subárvore, simplesmente comece com um segmento baseado em um cálculo ROW_NUMBER na consulta âncora, semelhante à maneira como você o calcula na consulta recursiva. Nesse caso, seu caminho de classificação terá um segmento a mais.
O que resta a fazer na Etapa 2 é criar a coluna seqdepth do resultado desejado calculando os números das linhas que são ordenados pelo caminho de classificação na consulta externa, assim
DECLARE @root AS INT =1; WITH C AS(SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY caminho de classificação) AS seqdepthFROM CORDER BY seqdepth;
Esta solução é o equivalente lógico de usar a opção padrão SEARCH DEPTH FIRST mostrada anteriormente junto com sua saída desejada.
Uma vez que você tenha uma coluna de sequência refletindo a primeira ordem de busca de profundidade (seqdepth em nosso caso), com um pouco mais de esforço você pode gerar uma representação visual muito boa da hierarquia. Você também precisará da coluna lvl acima mencionada. Você ordena a consulta externa pela coluna de sequência. Você retorna algum atributo que deseja usar para representar o nó (digamos, empname em nosso caso), prefixado por alguma string (digamos ' | ') tempos de lvl replicados. Aqui está o código completo para obter essa representação visual:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seqdepth;
Este código gera a seguinte saída:
empid seqdepth emp------ ------------- --------------------1 1 David2 2 | Eitan4 3 | | Serafim5 4 | | Jiru8 5 | | | Lilach10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aaron9 10 | | | Rita12 11 | | | | Emília13 12 | | | | Miguel14 13 | | | | Didi11 14 | | | Gabriel
Isso é bem legal!
cláusula CYCLE
Estruturas de grafos podem ter ciclos. Esses ciclos podem ser válidos ou inválidos. Um exemplo de ciclos válidos é um gráfico que representa rodovias e estradas conectando cidades e vilas. Isso é o que chamamos de gráfico cíclico . Por outro lado, um gráfico que representa uma hierarquia de funcionários, como no nosso caso, não deve ter ciclos. Isso é o que chamamos de acíclico gráfico. No entanto, suponha que devido a alguma atualização errônea, você acabe com um ciclo sem querer. Por exemplo, suponha que, por engano, você atualize o ID de gerente do CEO (funcionário 1) para o funcionário 14 executando o seguinte código:
ATUALIZAR Funcionários SET mgrid =14WHERE empid =1;
Agora você tem um ciclo inválido na hierarquia de funcionários.
Independentemente de os ciclos serem válidos ou inválidos, quando você percorre a estrutura do gráfico, certamente não deseja continuar seguindo um caminho cíclico repetidamente. Em ambos os casos, você deseja parar de seguir um caminho assim que uma não primeira ocorrência do mesmo nó for encontrada e marcar esse caminho como cíclico.
Então, o que acontece quando você consulta um gráfico que tem ciclos usando uma consulta recursiva, sem nenhum mecanismo para detectá-los? Isso depende da implementação. No SQL Server, em algum momento você atingirá o limite máximo de recursão e sua consulta será abortada. Por exemplo, supondo que você executou a atualização acima que introduziu o ciclo, tente executar a seguinte consulta recursiva para identificar a subárvore do funcionário 1:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;
Como esse código não define um limite máximo de recursão explícito, o limite padrão de 100 é assumido. O SQL Server interrompe a execução deste código antes da conclusão e gera um erro:
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aaron...
Msg 530, Level 16, State 1, Line 432
A instrução terminou. A recursão máxima 100 foi esgotada antes da conclusão da instrução.
O padrão SQL define uma cláusula chamada CYCLE para CTEs recursivos, permitindo que você lide com ciclos em seu gráfico. Você especifica essa cláusula logo antes da consulta externa. Se uma cláusula SEARCH também estiver presente, especifique-a primeiro e depois a cláusula CYCLE. Aqui está a sintaxe da cláusula CYCLE:
CYCLE
SET TO DEFAULT
USING
A detecção de um ciclo é baseada na lista de colunas de ciclo especificada . Por exemplo, em nossa hierarquia de funcionários, você provavelmente gostaria de usar a coluna empid para essa finalidade. Quando o mesmo valor empid aparece pela segunda vez, um ciclo é detectado e a consulta não busca mais esse caminho. Você especifica uma nova coluna de marca de ciclo que indicará se um ciclo foi encontrado ou não, e seus próprios valores como a marca de ciclo e marca de não ciclo valores. Por exemplo, eles podem ser 1 e 0 ou 'Sim' e 'Não', ou qualquer outro valor de sua escolha. Na cláusula USING, você especifica um novo nome de coluna de matriz que conterá o caminho dos nós encontrados até agora.
Veja como você lidaria com uma solicitação para subordinados de algum funcionário raiz de entrada, com a capacidade de detectar ciclos com base na coluna empid, indicando 1 na coluna de marca de ciclo quando um ciclo é detectado e 0 caso contrário:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) CYCLE empid SET cycle TO 1 DEFAULT 0------------------------------------ SELECT empid, mgrid, empnameFROM C;
Aqui está a saída desejada deste código:
empid mgrid empname cycle------ ------ -------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
Atualmente, o T-SQL não oferece suporte à cláusula CYCLE, mas há uma solução alternativa que fornece um equivalente lógico. Envolve três etapas. Lembre-se de que anteriormente você construiu um caminho de classificação binário para lidar com a ordem de pesquisa recursiva. De maneira semelhante, como primeira etapa da solução, você cria um caminho de ancestrais baseado em cadeia de caracteres feito dos IDs de nó (IDs de funcionários em nosso caso) dos ancestrais que levam ao nó atual, incluindo o nó atual. Você deseja separadores entre os IDs de nó, incluindo um no início e um no final.
Aqui está o código para construir esse caminho de ancestrais:
DECLARE @root AS INT =1; WITH C AS(SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpathFROM C;
Esse código gera a seguinte saída, ainda seguindo caminhos cíclicos e, portanto, abortando antes da conclusão quando o limite máximo de recursão é excedido:
empid mgrid empname ancpath------ ------ -------- -------------------1 14 David . 1.2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 9 Michael .1.3.7.9. 13.14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron .1.3.7.9.14.1.3.7. ...
Msg 530, Level 16, State 1, Line 492
A instrução terminou. A recursão máxima 100 foi esgotada antes da conclusão da instrução.
Observando a saída, você pode identificar um caminho cíclico quando o nó atual aparece no caminho pela primeira vez, como no caminho '.1.3.7.9.14.1.' .
Na segunda etapa da solução, você produz a coluna da marca do ciclo. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;
This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...
Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;
This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;
Run the recursive query and you will find that there are no cycles present.
Conclusão
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.
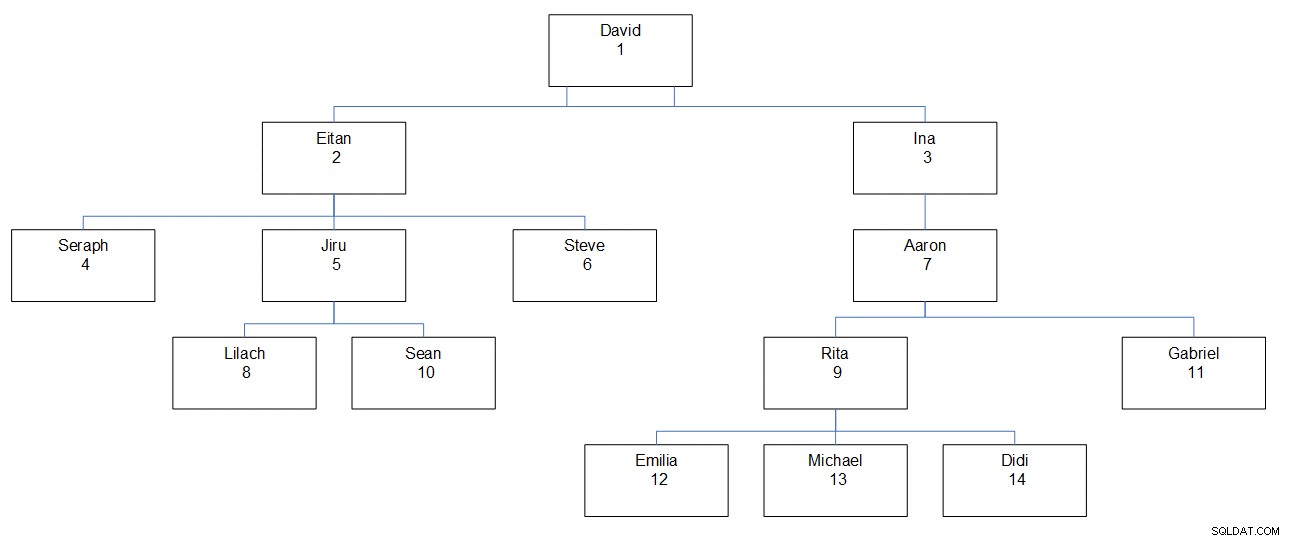 Figura 1:hierarquia de funcionários
Figura 1:hierarquia de funcionários