Um modelo de dados de folha de pagamento permite calcular facilmente o salário de seus funcionários. Como esse modelo funciona?
Não importa se você está administrando uma empresa pequena ou grande, você precisa de algum tipo de solução de folha de pagamento. É aí que um aplicativo de folha de pagamento é útil. Além disso, quanto maior a empresa, mais difícil fica lidar com os cálculos salariais dos funcionários; aqui, um aplicativo de folha de pagamento torna-se uma necessidade. Para ajudá-lo a entender todos os dados necessários para esse aplicativo, orientaremos você em um modelo de dados relacionado.
Vamos ver como funciona nosso modelo de dados de folha de pagamento!
Modelo de dados
Com a criação desse modelo de dados, tentei criar um modelo que seja geralmente aplicável a todos os negócios. É claro que sempre haverá diferenças nos regulamentos, políticas da empresa, etc., que exigirão que o modelo seja personalizado para cobrir as necessidades de uma folha de pagamento específica. No entanto, os princípios estabelecidos neste modelo devem ser relevantes para a maioria das organizações.
É de notar que este modelo foi criado com vários pressupostos:
- Os salários acordados no contrato de trabalho são anuais.
- Os salários líquidos (ou seja, com determinados valores deduzidos de impostos etc.) são pagos aos funcionários.
- Os salários são pagos mensalmente.
O modelo de dados é composto por catorze tabelas e está dividido em duas áreas temáticas:
EmployeesSalaries
Para entender melhor o modelo, é necessário percorrer cada área de assunto minuciosamente.
Funcionários
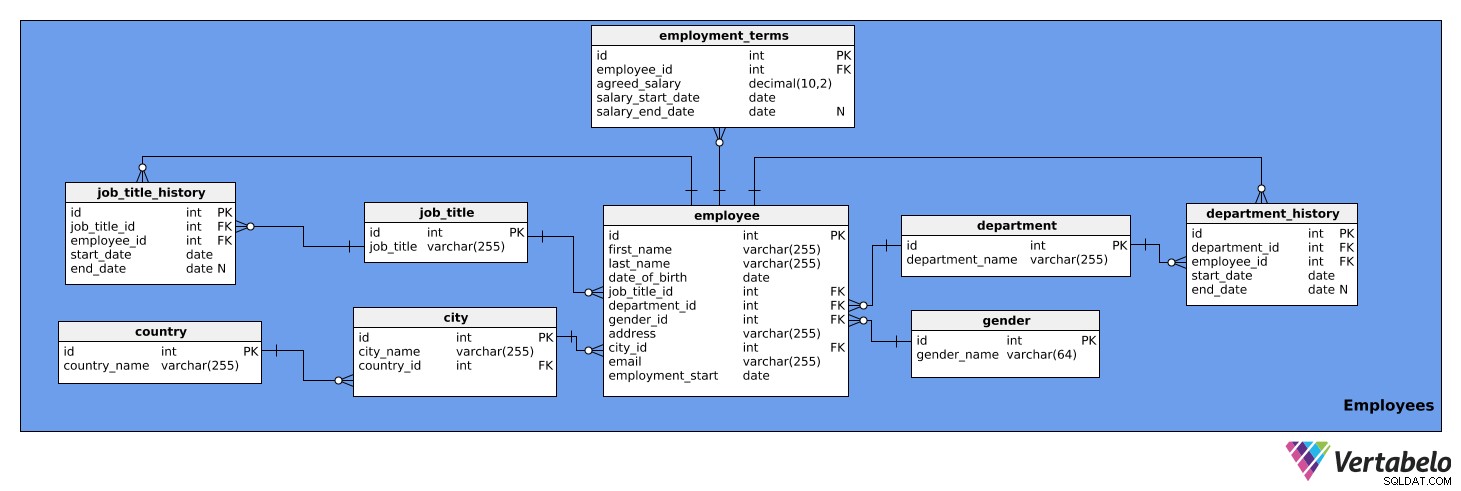
Esta área de assunto contém informações detalhadas sobre os funcionários. É composto por nove tabelas:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
A primeira tabela que veremos é a
employee tabela. Ele contém uma lista de todos os funcionários e seus detalhes relevantes. Os atributos da tabela são:id– Um ID exclusivo para cada funcionário.first_name– O primeiro nome do funcionário.last_name– O sobrenome do funcionário.job_title_id– Referencia ojob_titletabela.department_id– Refere-se aodepartmenttabela.gender_id– Faz referência aogendertabela.address– O endereço do funcionário.city_id– Referencia acitytabela.email– O e-mail do funcionário.employment_start– A data em que o emprego dessa pessoa começou.
Observe que as colunas
job_title_id e department_id são redundantes, pois as informações sobre cargos e departamentos atuais podem ser acessadas no job_title_history e department_history mesas. No entanto, manteremos essas duas colunas nesta tabela para acesso mais rápido às informações. A seguir estão os
employment_terms tabela. Ele armazena dados sobre o salário de cada funcionário, conforme acordado no contrato de trabalho, e como ele mudou ao longo do tempo. Os atributos da tabela são:id– Um ID exclusivo para cada conjunto de termos de emprego.employee_id– Refere-se aoemployeetabela.agreed_salary– O salário estabelecido no contrato de trabalho.salary_start_date– A data de início do salário acordado.salary_end_date– A data final do salário acordado. Isso pode ser NULL porque um salário pode não ter nenhuma mudança planejada.
O
job_title table é uma lista dos cargos que podem ser atribuídos a vários funcionários da empresa, por exemplo, analista, motorista, secretário, diretor, etc. A tabela possui os seguintes atributos:id– Um ID exclusivo para cada cargo.job_title– O nome do cargo. Esta é a chave alternativa.
Também precisamos de uma tabela para armazenar o histórico de cargos de cada funcionário. Precisamos disso porque os funcionários podem ser promovidos, rebaixados ou realocados dentro da empresa. O
job_title_history table gerenciará essas informações e consistirá nos seguintes atributos:id– Um ID exclusivo para a entrada histórica do cargo.job_title_id– Referencia ojob_titletabela.employee_id– Refere-se aoemployeetabela.start_date– A data em que o funcionário ocupou esse cargo pela primeira vez.end_date– Quando o funcionário deixou de ter esse cargo. Isso pode ser NULL porque o funcionário pode ter esse cargo no momento.
A combinação de
job_title_id , employee_id e start_date é a chave alternativa para a tabela acima. Um funcionário pode ter apenas um cargo atribuído em uma determinada data. A próxima tabela é o
department tabela. Isso simplesmente listará todos os departamentos da empresa, como TI, Contabilidade, Jurídico, etc. Ele contém dois atributos:id– Um ID exclusivo para cada departamento.department_name– O nome de cada departamento. Esta é a chave alternativa.
Os funcionários também podem mudar de departamento dentro da empresa. Portanto, precisamos ter um
department_history tabela. Esta tabela irá armazenar o seguinte:id– Um ID exclusivo para essa entrada histórica do departamento.department_id– Refere-se aodepartmenttabela.employee_id– Refere-se aoemployeetabela.start_date– A data em que um funcionário começou a trabalhar em um departamento.end_date- A data em que um funcionário deixou de trabalhar nesse departamento. Isso pode ser NULL porque o funcionário ainda pode trabalhar lá.
A combinação de
department_id , employee_id e start_date é a chave alternativa. Um funcionário pode trabalhar em apenas um departamento por vez. A próxima tabela sobre a qual falaremos é a
city tabela. Esta é uma lista de todas as cidades relevantes. Possui os seguintes atributos:id– Um ID exclusivo para cada cidade.city_name– O nome da cidade.country_id– Refere-se aocountrytabela.
O
country tabela é a próxima em nosso modelo. É simplesmente uma lista de países e contém as seguintes informações:id– Um ID exclusivo para cada país.country_name– O nome do país. Esta é a chave alternativa.
A última tabela nesta área de assunto é o
gender tabela. Esta tabela lista todos os gêneros. Ele contém os seguintes atributos:id– Um ID exclusivo para cada sexo.gender_name– O nome do gênero.
Vamos agora analisar a segunda área de assunto.
Salários
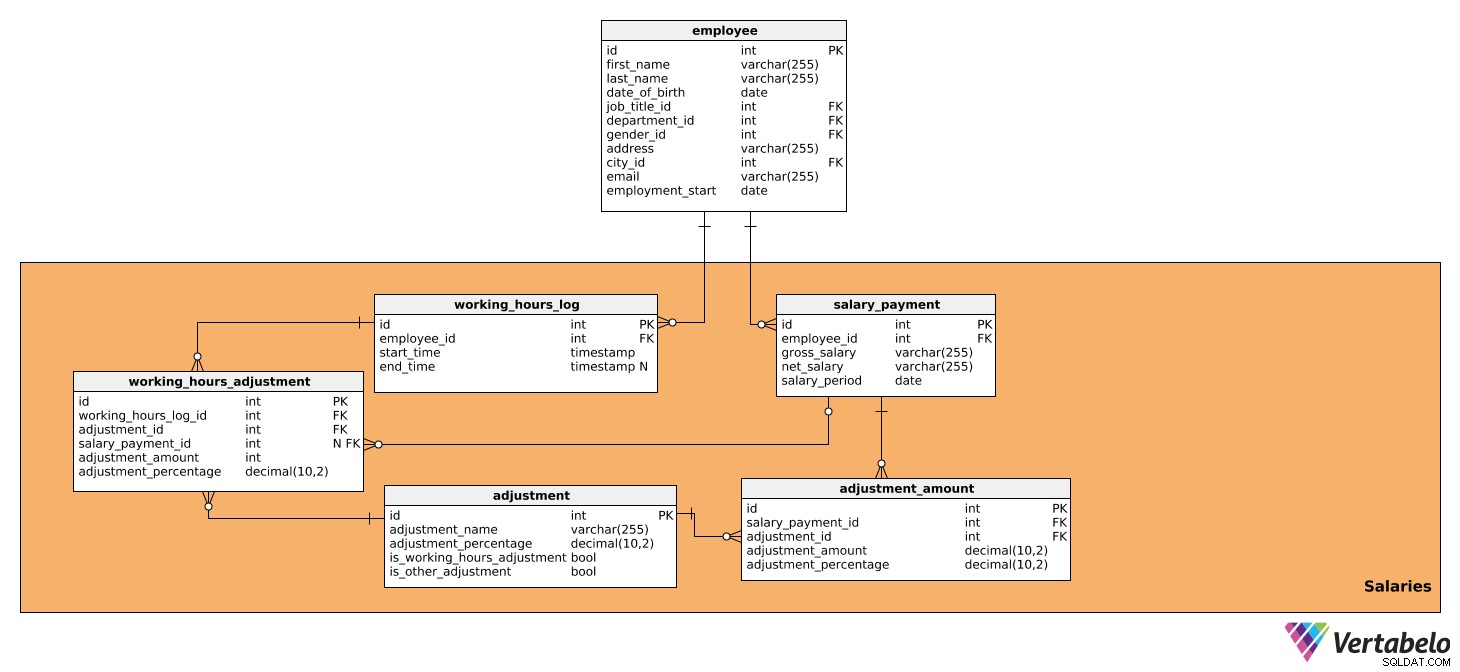
Esta área de assunto é composta por tabelas que contêm todos os dados que influenciam diretamente os cálculos salariais de cada período, bem como o valor a ser pago. É composto por cinco tabelas:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Agora vamos analisar cada tabela.
A primeira tabela é
salary_payment . Ele contém todos os detalhes relevantes sobre o salário pago a cada funcionário e possui os seguintes atributos:id– Um ID exclusivo para cada salário.employee_id– Refere-se aoemployeetabela.gross_salary– O salário bruto, que servirá de base para novos ajustes.net_salary– O salário líquido (ou seja, o valor recebido pelo funcionário após várias deduções).salary_period– O período para o qual o salário está sendo calculado e pago.
O segundo é o
working_hours_log tabela. Ele contém dados sobre o número de horas trabalhadas por cada funcionário, o que pode influenciar determinados reajustes salariais. Esta tabela tem os seguintes atributos:id– Um ID exclusivo para cada entrada de registro.employee_id– Refere-se aoemployeetabela.start_time– A hora em que o funcionário fez login, ou seja, iniciou o trabalho do dia.end_time– Quando o funcionário fez logout. Pode ser NULL porque não saberemos a hora exata até que o funcionário faça logout.
A próxima tabela que analisaremos é
working_hours_adjustment . Esta tabela só será utilizada no cálculo dos ajustes com base nas horas trabalhadas, ou seja, aquelas que possuem valor TRUE em is_working_hours_adjustment no adjustment tabela. Os atributos são os seguintes:id– Um ID exclusivo para cada ajuste.working_hours_log_id– Refere-se aoworking_hours_logtabela.adjustment_id- Referencia oadjustmenttabela.salary_payment_id– Refere-se aosalary_paymenttabela. Este valor pode ser NULL porquesalary_payment_idserá usado apenas uma vez por mês, quando iniciarmos o cálculo do salário.adjustment_amount– O valor do ajuste.adjustment_percentage– O valor percentual do ajuste. Isso será usado para fins históricos, pois a porcentagem pode mudar ao longo do tempo.
A próxima tabela sobre a qual falaremos é o
adjustment tabela. Contém informações sobre todos os reajustes utilizados para cálculo do salário, ou seja, todos os impostos e contribuições que impactam no valor do salário. Além disso, conterá todos os ajustes que dependem das horas trabalhadas e não trabalhadas, como bônus, horas extras, licença médica e licença maternidade/paternidade. Para isso, precisamos dos seguintes dados:id– Um ID exclusivo para cada ajuste.adjustment_name– Um nome que descreve esse ajuste.adjustment_percentage– O valor percentual do ajuste específico.is_working_hours_adjustment– Esta é uma marcação de bandeira se um ajuste depender diretamente das horas de trabalho, por exemplo, horas extras, licença médica, etc.is_other_adjustment– Este é um ajuste de marcação de bandeira que não dependem diretamente das horas trabalhadas, como deduções fiscais, contribuições previdenciárias, contribuições patronais, etc.
Depois disso, precisamos do
adjustment_amount tabela. Ele será usado para calcular todos os ajustes salariais, exceto aqueles que já estão no working_hours_adjustment , ou seja, aqueles que têm um valor TRUE em is_other_adjustment no adjustment tabela. A tabela contém os seguintes atributos:id– Um ID exclusivo para cada entrada de valor de ajuste.salary_payment_id– Refere-se aosalary_paymenttabela.adjustment_id– Refere-se aoadjustmenttabela.adjustment_amount– O valor de cada ajuste calculado.adjustment_percentage- O valor percentual do ajuste. Ele será usado para fins históricos, pois a porcentagem pode mudar ao longo do tempo.
Deixe-me dar um exemplo de como as tabelas
working_hours_log , working_hours_adjustment , adjustment e adjustment_amount trabalham juntos para calcular um salário. Todos os dias, o funcionário registra quando chega ao trabalho e quando sai. Esses dados podem ser vistos no working_hours_log tabela. Digamos que nosso funcionário tenha trabalhado 10 horas extras durante um mês e, de acordo com a política da empresa, ele receberá 20% a mais por hora a cada hora extra. Fazendo referência ao adjustment tabela, poderemos encontrar o ajuste necessário, ou seja, horas extras, que terão um determinado valor percentual (20%). Também teremos is_working_hours_adjustment definido como VERDADEIRO. Usando os dados dessas duas tabelas, poderemos calcular o ajuste e armazená-lo no working_hours_adjustment tabela. Agora podemos calcular todos os outros ajustes que não dependem das horas trabalhadas. Isso será feito no
adjustment_amount tabela. Assim como fizemos acima, faremos referência ao adjustment tabela e encontrar os ajustes de que precisamos - por exemplo, dedução fiscal, contribuição previdenciária ou contribuição patronal – e seus respectivos percentuais. O is_other_adjustment sinalizador no adjustment tabela será definida como TRUE para esses ajustes. Com base nesses cálculos, podemos armazenar dados de salário bruto e salário líquido no arquivo
salary_payment tabela. Ao analisar este exemplo, cobrimos tudo em nosso modelo de dados!
Você gostou do modelo de dados da folha de pagamento?
Tentei criar um modelo que pudesse ser usado em quase todas as situações. No entanto, é impossível incluir todos os parâmetros específicos que influenciam o cálculo do salário em um artigo dessa extensão. Ao cobrir princípios gerais, tentei tornar este modelo útil como uma base sólida para seu modelo de dados de folha de pagamento.
O que você acha do modelo de dados da folha de pagamento? É aplicável como uma solução para suas necessidades de folha de pagamento? Você veio com algo diferente? Existem problemas específicos que você encontrou que mudariam significativamente o modelo de dados? Dê sua opinião na seção de comentários.