Houve muitas discussões sobre o OLTP na memória (o recurso anteriormente conhecido como "Hekaton") e como ele pode ajudar cargas de trabalho muito específicas e de alto volume. No meio de uma conversa diferente, notei algo no
CREATE TYPE documentação do SQL Server 2014 que me fez pensar que pode haver um caso de uso mais geral:
Adições relativamente silenciosas e não anunciadas à documentação CREATE TYPE
Com base no diagrama de sintaxe, parece que os parâmetros com valor de tabela (TVPs) podem ser otimizados para memória, assim como as tabelas permanentes. E com isso, as rodas imediatamente começaram a girar.
Uma coisa para a qual usei TVPs é ajudar os clientes a eliminar métodos caros de divisão de strings em T-SQL ou CLR (consulte o histórico em postagens anteriores aqui, aqui e aqui). Em meus testes, usar um TVP regular superou padrões equivalentes usando funções de divisão CLR ou T-SQL por uma margem significativa (25-50%). Eu logicamente me perguntei:haveria algum ganho de desempenho de um TVP com otimização de memória?
Tem havido alguma apreensão sobre o OLTP na memória em geral, porque há muitas limitações e lacunas de recursos, você precisa de um grupo de arquivos separado para dados com otimização de memória, você precisa mover tabelas inteiras para otimização de memória e o melhor benefício é normalmente alcançado criando também procedimentos armazenados compilados nativamente (que têm seu próprio conjunto de limitações). Como demonstrarei, supondo que seu tipo de tabela contenha estruturas de dados simples (por exemplo, representando um conjunto de inteiros ou strings), usar essa tecnologia apenas para TVPs elimina algumas dessas questões.
O Teste
Você ainda precisará de um grupo de arquivos com otimização de memória, mesmo se não for criar tabelas permanentes com otimização de memória. Então, vamos criar um novo banco de dados com a estrutura apropriada:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Agora, podemos criar um tipo de tabela regular, como faríamos hoje, e um tipo de tabela com otimização de memória com um índice de hash não clusterizado e uma contagem de buckets que tirei do ar (mais informações sobre cálculo de requisitos de memória e contagem de buckets em o mundo real aqui):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Se você tentar isso em um banco de dados que não possui um grupo de arquivos com otimização de memória, receberá esta mensagem de erro, assim como faria se tentasse criar uma tabela normal com otimização de memória:
Msg 41337, Level 16, State 0, Line 9
O grupo de arquivos MEMORY_OPTIMIZED_DATA não existe ou está vazio. As tabelas com otimização de memória não podem ser criadas para um banco de dados até que ele tenha um grupo de arquivos MEMORY_OPTIMIZED_DATA que não esteja vazio.
Para testar uma consulta em uma tabela normal, sem otimização de memória, simplesmente puxei alguns dados para uma nova tabela do banco de dados de exemplo AdventureWorks2012, usando
SELECT INTO ignorar todas essas restrições, índices e propriedades estendidas irritantes e, em seguida, criei um índice clusterizado na coluna que eu sabia que estaria pesquisando (ProductID ):SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Em seguida, criei quatro procedimentos armazenados:dois para cada tipo de tabela; cada um usando
EXISTS e JOIN abordagens (normalmente gosto de examinar ambas, embora prefira EXISTS; mais tarde você verá por que eu não quis restringir meus testes a apenas EXISTS ). Nesse caso, apenas atribuo uma linha arbitrária a uma variável, para que eu possa observar altas contagens de execução sem lidar com conjuntos de resultados e outras saídas e sobrecarga:-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Em seguida, eu precisava simular o tipo de consulta que normalmente ocorre nesse tipo de tabela e requer um TVP ou padrão semelhante em primeiro lugar. Imagine um formulário com um drop-down ou um conjunto de checkboxes contendo uma lista de produtos, e o usuário pode selecionar os 20 ou 50 ou 200 que deseja comparar, listar, o que tiver. Os valores não estarão em um bom conjunto contíguo; eles normalmente estarão espalhados por todo o lugar (se fosse um intervalo contíguo previsível, a consulta seria muito mais simples:valores inicial e final). Então, eu apenas peguei 20 valores arbitrários da tabela (tentando ficar abaixo, digamos, 5% do tamanho da tabela), ordenados aleatoriamente. Uma maneira fácil de criar um
VALUES reutilizável cláusula como esta é a seguinte:DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Os resultados (o seu quase certamente irá variar):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
Ao contrário de um
INSERT...SELECT direto , isso torna bastante fácil manipular essa saída em uma instrução reutilizável para preencher nossos TVPs repetidamente com os mesmos valores e em várias iterações de teste:SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Se executarmos este lote usando o SQL Sentry Plan Explorer, os planos resultantes mostrarão uma grande diferença:o TVP na memória é capaz de usar uma junção de loops aninhados e 20 buscas de índice clusterizado de linha única, versus uma junção de mesclagem alimentada por 502 linhas por uma varredura de índice clusterizado para o TVP clássico. E neste caso, EXISTS e JOIN produziram planos idênticos. Isso pode indicar um número muito maior de valores, mas vamos continuar com a suposição de que o número de valores será menor que 5% do tamanho da tabela:
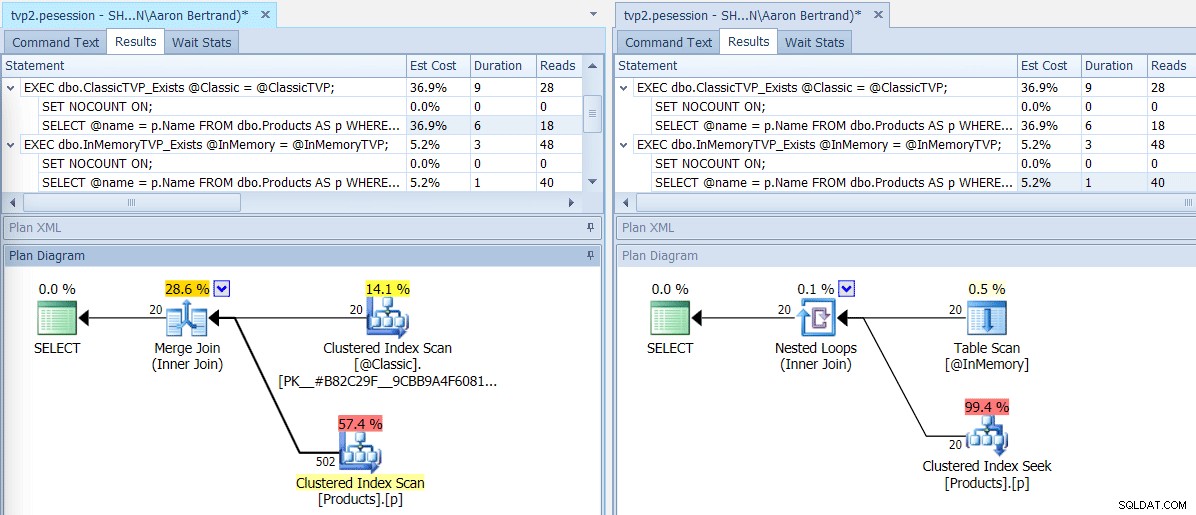 Planos para TVPs clássicas e in-memory
Planos para TVPs clássicas e in-memory 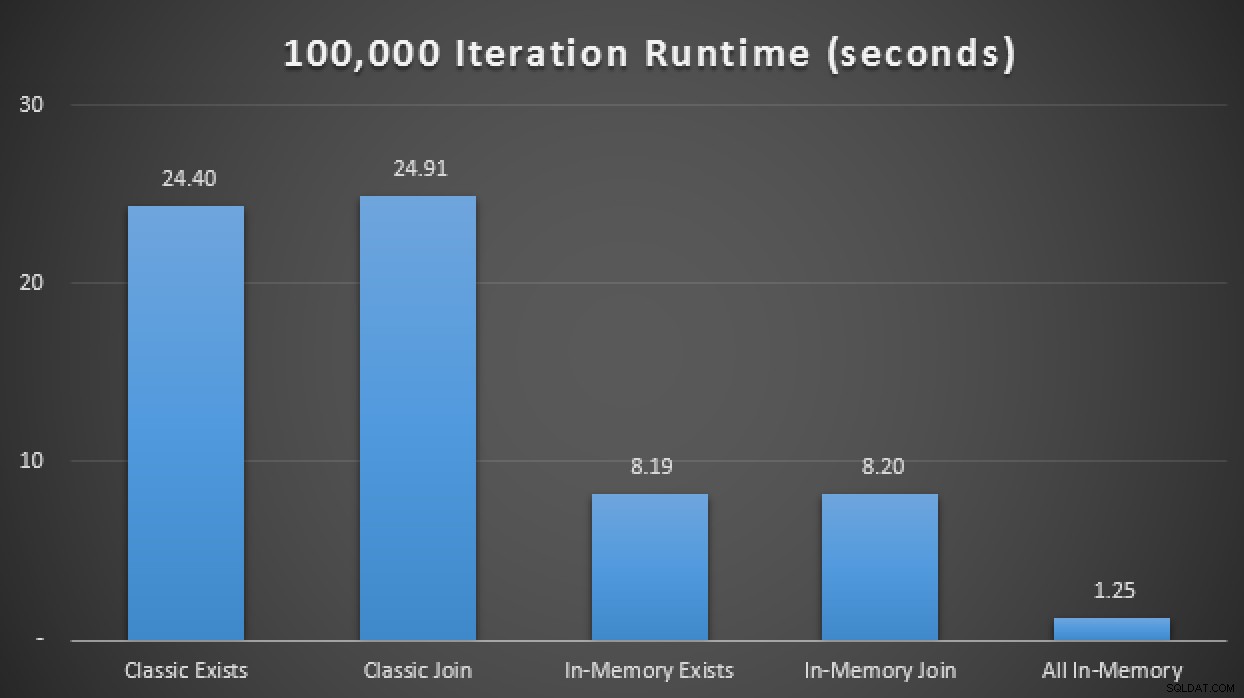 Dicas de ferramentas para operadores de varredura/busca, destacando as principais diferenças – Clássico à esquerda, In- Memória à direita
Dicas de ferramentas para operadores de varredura/busca, destacando as principais diferenças – Clássico à esquerda, In- Memória à direita Agora, o que isso significa em escala? Vamos desativar qualquer coleção de showplan e alterar um pouco o script de teste para executar cada procedimento 100.000 vezes, capturando o tempo de execução cumulativo manualmente:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
SELECT SYSDATETIME(); Nos resultados, com média de 10 execuções, vemos que, neste caso de teste limitado, pelo menos, o uso de um tipo de tabela com otimização de memória rendeu uma melhoria de aproximadamente 3 vezes na métrica de desempenho mais crítica em OLTP (duração do tempo de execução):
Resultados de tempo de execução mostrando uma melhoria de 3X com TVPs na memória em>
In-Memory + In-Memory + In-Memory :In-Memory Inception
Agora que vimos o que podemos fazer simplesmente alterando nosso tipo de tabela regular para um tipo de tabela com otimização de memória, vamos ver se podemos extrair mais desempenho desse mesmo padrão de consulta quando aplicamos a tríplice:um in-memory table, usando um procedimento armazenado com otimização de memória compilado nativamente, que aceita uma tabela de tabela na memória como um parâmetro com valor de tabela.
Primeiro, precisamos criar uma nova cópia da tabela e preenchê-la a partir da tabela local que já criamos:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Em seguida, criamos um procedimento armazenado compilado nativamente que usa nosso tipo de tabela com otimização de memória existente como um TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Algumas advertências. Não podemos usar um tipo de tabela regular e não otimizado para memória como um parâmetro para um procedimento armazenado compilado nativamente. Se tentarmos, teremos:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedure
O tipo de tabela 'dbo.ClassicTVP' não é um tipo de tabela com otimização de memória e não pode ser usado em um procedimento armazenado compilado nativamente.
Além disso, não podemos usar o
EXISTS padrão aqui também; quando tentamos, obtemos:Msg 12311, Level 16, State 37, Procedure NativeCompiled_Exists
Subconsultas (consultas aninhadas dentro de outra consulta) não são suportadas com procedimentos armazenados compilados nativamente.
Existem muitas outras advertências e limitações com o OLTP na memória e procedimentos armazenados compilados nativamente, eu só queria compartilhar algumas coisas que podem parecer estar obviamente ausentes dos testes.
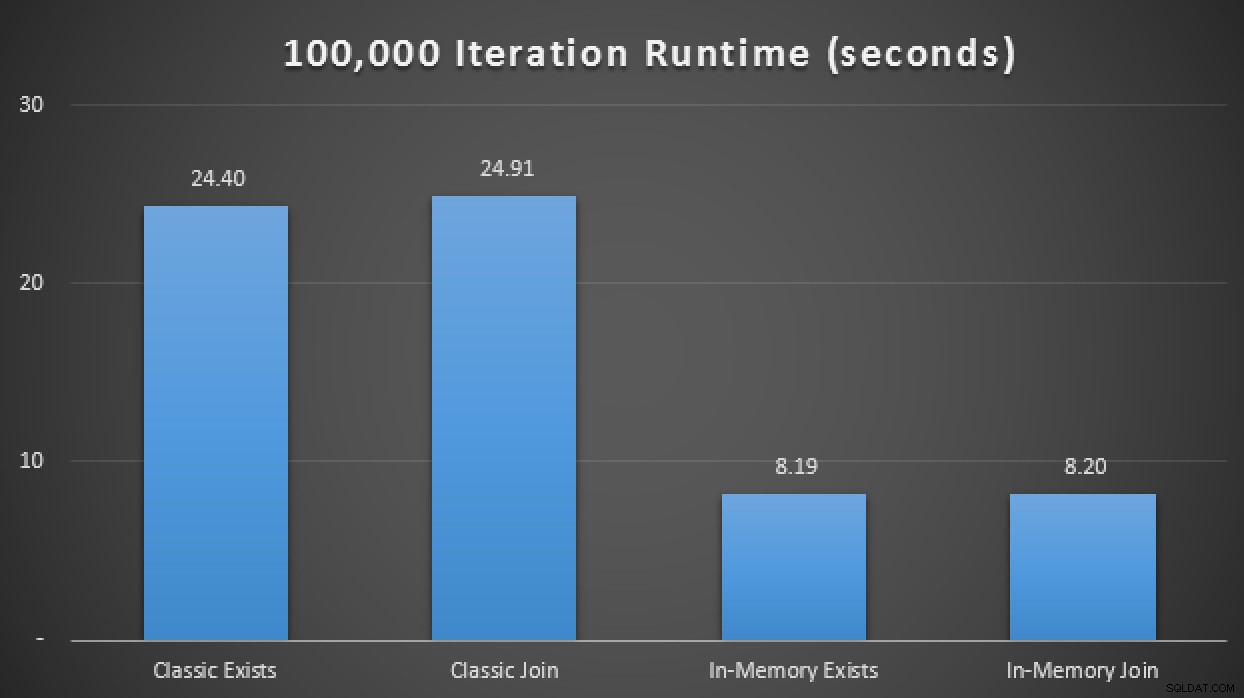
Então, adicionando esse novo procedimento armazenado compilado nativamente à matriz de teste acima, descobri que – novamente, com média de 10 execuções – ele executou as 100.000 iterações em apenas 1,25 segundos. Isso representa aproximadamente uma melhoria de 20 vezes em relação aos TVPs regulares e uma melhoria de 6 a 7 vezes em relação aos TVPs na memória usando tabelas e procedimentos tradicionais:
Resultados de tempo de execução mostrando uma melhoria de até 20 vezes com In-Memory ao redor
Conclusão
Se você estiver usando TVPs agora ou estiver usando padrões que podem ser substituídos por TVPs, você deve considerar adicionar TVPs com otimização de memória aos seus planos de teste, mas lembre-se de que talvez não veja as mesmas melhorias em seu cenário. (E, claro, tendo em mente que os TVPs em geral têm muitas ressalvas e limitações, e também não são apropriados para todos os cenários. Erland Sommarskog tem um ótimo artigo sobre os TVPs de hoje aqui.)
Na verdade, você pode ver que na extremidade mais baixa do volume e da simultaneidade, não há diferença - mas, por favor, teste em escala realista. Este foi um teste muito simples e planejado em um laptop moderno com um único SSD, mas quando você está falando sobre volume real e/ou discos mecânicos giratórios, essas características de desempenho podem ter muito mais peso. Há um acompanhamento com algumas demonstrações sobre tamanhos de dados maiores.



