Você pode pensar que a manutenção do banco de dados não é da sua conta. Mas se você projetar seus modelos de forma proativa, obterá bancos de dados que facilitam a vida de quem precisa mantê-los.
Um bom desenho de banco de dados requer proatividade, qualidade reconhecida em qualquer ambiente de trabalho. Caso você não esteja familiarizado com o termo, proatividade é a capacidade de antecipar problemas e ter soluções prontas quando os problemas ocorrerem – ou melhor ainda, planejar e agir para que os problemas não ocorram em primeiro lugar.
Os empregadores entendem que a proatividade de seus funcionários ou contratados equivale a economia de custos. É por isso que eles valorizam e incentivam as pessoas a praticá-lo.
Em sua função de modelador de dados, a melhor maneira de demonstrar proatividade é projetar modelos que antecipem e evitem problemas que rotineiramente afligem a manutenção do banco de dados. Ou, pelo menos, que simplifiquem substancialmente a solução desses problemas.
Mesmo que você não seja responsável pela manutenção do banco de dados, a modelagem para facilitar a manutenção do banco de dados traz muitos benefícios. Por exemplo, ele evita que você seja chamado a qualquer momento para resolver emergências de dados que tiram um tempo valioso que você poderia gastar em tarefas de design ou modelagem que você tanto gosta!
Facilitando a vida do pessoal de TI
Ao projetar nossos bancos de dados, precisamos pensar além da entrega de um DER e da geração de scripts de atualização. Depois que um banco de dados entra em produção, os engenheiros de manutenção precisam lidar com todos os tipos de problemas em potencial, e parte de nossa tarefa como modeladores de banco de dados é minimizar as chances de que esses problemas ocorram.
Vamos começar analisando o que significa criar um bom design de banco de dados e como essa atividade se relaciona com as tarefas regulares de manutenção do banco de dados.
O que é modelagem de dados?
A modelagem de dados é a tarefa de criar uma representação abstrata, geralmente gráfica, de um repositório de informações. O objetivo da modelagem de dados é expor os atributos e os relacionamentos entre as entidades cujos dados são armazenados no repositório.
Os modelos de dados são construídos em torno das necessidades de um problema de negócios. Regras e requisitos são definidos antecipadamente por meio de informações de especialistas de negócios para que possam ser incorporados ao projeto de um novo repositório de dados ou adaptados na iteração de um existente.
Idealmente, os modelos de dados são documentos vivos que evoluem com as necessidades de negócios em constante mudança. Eles desempenham um papel importante no suporte às decisões de negócios e no planejamento da arquitetura e estratégia de sistemas. Os modelos de dados devem ser mantidos em sincronia com os bancos de dados que representam para que sejam úteis às rotinas de manutenção desses bancos de dados.
Desafios comuns de manutenção do banco de dados
A manutenção de um banco de dados requer monitoramento constante, automatizado ou não, para garantir que ele não perca suas virtudes. As práticas recomendadas de manutenção de banco de dados garantem que os bancos de dados sempre mantenham:
- Integridade e qualidade das informações
- Desempenho
- Disponibilidade
- Escalabilidade
- Adaptabilidade a mudanças
- Rastreabilidade
- Segurança
Muitas dicas de modelagem de dados estão disponíveis para ajudá-lo a criar sempre um bom design de banco de dados. Os discutidos abaixo visam especificamente garantir ou facilitar a manutenção das qualidades do banco de dados mencionadas acima.
Integridade e qualidade da informação
Um objetivo fundamental das práticas recomendadas de manutenção de banco de dados é garantir que as informações no banco de dados mantenham sua integridade. Isso é fundamental para que os usuários mantenham sua fé nas informações.
Existem dois tipos de integridade:integridade física e integridade lógica .
Integridade Física
A manutenção da integridade física de um banco de dados é feita protegendo as informações de fatores externos, como falhas de hardware ou energia. A abordagem mais comum e amplamente aceita é por meio de uma estratégia de backup adequada que permita a recuperação de um banco de dados em um tempo razoável caso uma catástrofe o destrua.
Para DBAs e administradores de servidor que gerenciam o armazenamento de banco de dados, é útil saber se os bancos de dados podem ser particionados em seções com diferentes frequências de atualização. Isso permite que eles otimizem o uso do armazenamento e os planos de backup.
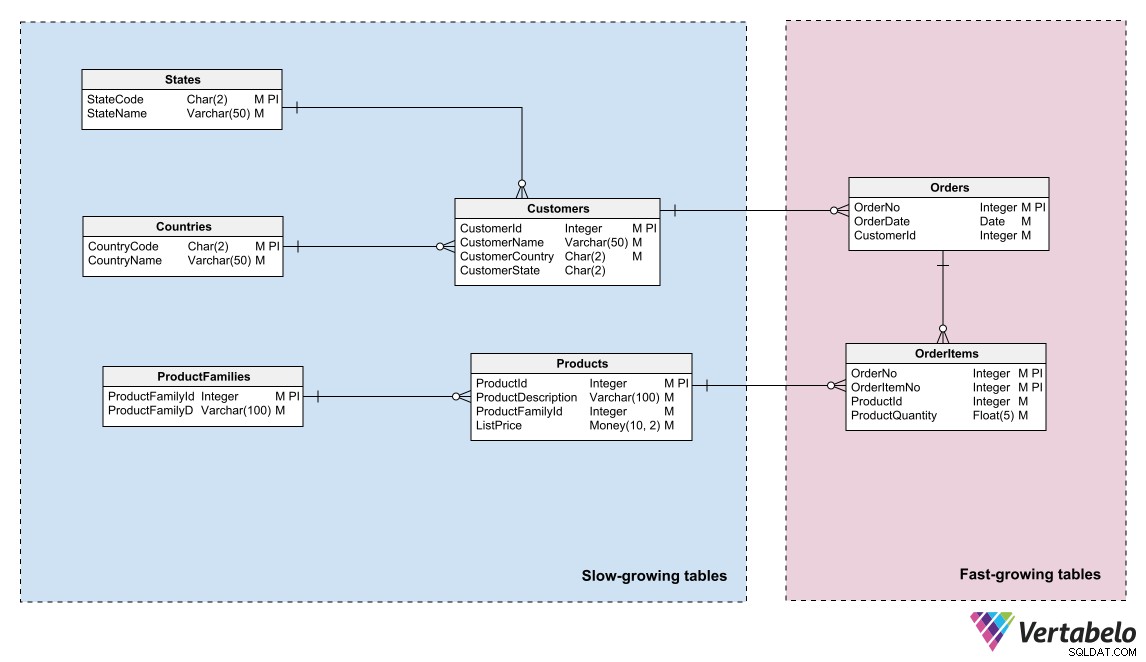
Os modelos de dados podem refletir esse particionamento identificando áreas de diferentes “temperaturas” de dados e agrupando entidades nessas áreas. “Temperatura” refere-se à frequência com que as tabelas recebem novas informações. As tabelas que são atualizadas com muita frequência são as “mais quentes”; aqueles que nunca ou raramente são atualizados são os “mais frios”.

Modelo de dados de um sistema de comércio eletrônico diferenciando dados quentes, quentes e frios.
Um DBA ou administrador de sistema pode usar esse agrupamento lógico para particionar os arquivos de banco de dados e criar planos de backup diferentes para cada partição.
Integridade lógica
Manter a integridade lógica de um banco de dados é essencial para a confiabilidade e utilidade das informações que ele fornece. Se um banco de dados não tiver integridade lógica, os aplicativos que o utilizam revelarão inconsistências nos dados mais cedo ou mais tarde. Diante dessas inconsistências, os usuários desconfiam das informações e simplesmente buscam fontes de dados mais confiáveis.
Dentre as tarefas de manutenção do banco de dados, manter a integridade lógica das informações é uma extensão da tarefa de modelagem do banco de dados, só que começa após o banco de dados ser colocado em produção e continua por toda a sua vida útil. A parte mais crítica desta área de manutenção é a adaptação às mudanças.
Gerenciamento de Mudanças
Mudanças nas regras ou requisitos de negócios são uma ameaça constante à integridade lógica dos bancos de dados. Você pode se sentir feliz com o modelo de dados que construiu, sabendo que ele está perfeitamente adaptado ao negócio, que responde com as informações corretas a qualquer consulta e que deixa de fora qualquer anomalia de inserção, atualização ou exclusão. Aproveite este momento de satisfação, pois é de curta duração!
A manutenção de um banco de dados envolve enfrentar a necessidade de fazer alterações no modelo diariamente. Ele força você a adicionar novos objetos ou alterar os existentes, modificar a cardinalidade dos relacionamentos, redefinir chaves primárias, alterar tipos de dados e fazer outras coisas que fazem nós modeladores estremecer.
Mudanças acontecem o tempo todo. Pode ser que algum requisito tenha sido explicado errado desde o início, novos requisitos tenham surgido ou você tenha introduzido involuntariamente alguma falha em seu modelo (afinal, nós, modeladores de dados, somos apenas humanos).
Seus modelos devem ser fáceis de modificar quando surgir a necessidade de alterações. É fundamental usar uma ferramenta de design de banco de dados para modelagem que permita a versão de seus modelos, gere scripts para migrar um banco de dados de uma versão para outra e documente adequadamente todas as decisões de design.
Sem essas ferramentas, cada mudança que você faz em seu projeto cria riscos de integridade que vêm à tona nos momentos mais inoportunos. O Vertabelo te dá toda essa funcionalidade e cuida de manter o histórico de versões de um modelo sem você nem pensar nisso.
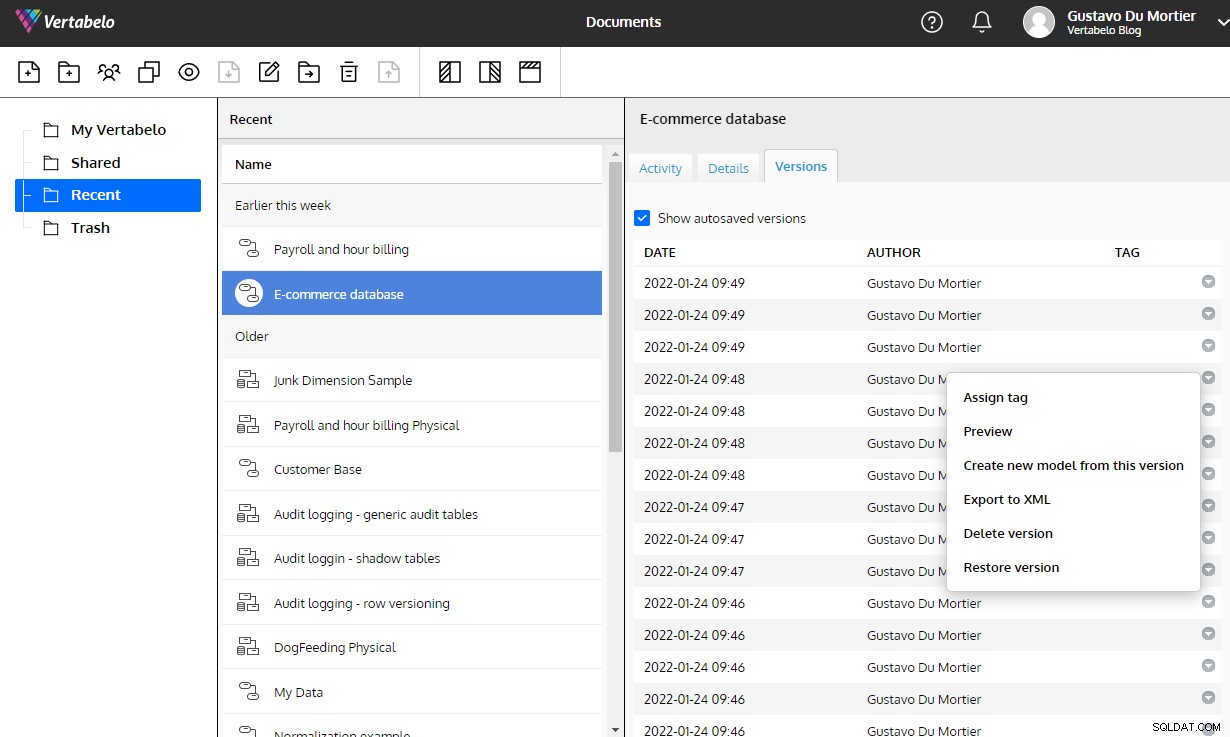
O controle de versão automático integrado ao Vertabelo é uma tremenda ajuda na manutenção de alterações em um modelo de dados.
O gerenciamento de mudanças e o controle de versão também são fatores cruciais na incorporação de atividades de modelagem de dados no ciclo de vida de desenvolvimento de software.
Refactoring
Ao aplicar alterações em um banco de dados em uso, você precisa ter 100% de certeza de que nenhuma informação será perdida e que sua integridade não será afetada como consequência das alterações. Para fazer isso, você pode usar técnicas de refatoração. Eles são normalmente aplicados quando você deseja melhorar um projeto sem afetar sua semântica, mas também podem ser usados para corrigir erros de projeto ou adaptar um modelo a novos requisitos.
Há um grande número de técnicas de refatoração. Geralmente são empregados para dar nova vida aos bancos de dados legados, e existem procedimentos de livros didáticos que garantem que as alterações não prejudiquem as informações existentes. Livros inteiros foram escritos sobre isso; Eu recomendo que você os leia.
Mas, para resumir, podemos agrupar as técnicas de refatoração nas seguintes categorias:
- Qualidade dos dados: Fazer alterações que garantam a consistência e a coerência dos dados. Os exemplos incluem adicionar uma tabela de pesquisa e migrar para ela dados repetidos em outra tabela e adicionar uma restrição em uma coluna.
- Estrutural: Fazendo alterações nas estruturas da tabela que não alteram a semântica do modelo. Os exemplos incluem combinar duas colunas em uma, adicionar uma chave substituta e dividir uma coluna em duas.
- Integridade referencial: Aplicando alterações para garantir que uma linha referenciada exista em uma tabela relacionada ou que uma linha não referenciada possa ser excluída. Os exemplos incluem adicionar uma restrição de chave estrangeira em uma coluna e adicionar uma restrição de valor não nulo a uma tabela.
- Arquitetura: Realização de alterações visando melhorar a interação dos aplicativos com o banco de dados. Os exemplos incluem criar um índice, tornar uma tabela somente leitura e encapsular uma ou mais tabelas em uma visualização.
Técnicas que modificam a semântica do modelo, bem como aquelas que não alteram o modelo de dados de forma alguma, não são consideradas técnicas de refatoração. Isso inclui inserir linhas em uma tabela, adicionar uma nova coluna, criar uma nova tabela ou exibição e atualizar os dados em uma tabela.
Manter a qualidade das informações
A qualidade da informação em um banco de dados é o grau em que os dados atendem às expectativas da organização quanto à precisão, validade, integridade e consistência. Manter a qualidade dos dados ao longo do ciclo de vida de um banco de dados é vital para que seus usuários tomem decisões corretas e informadas usando os dados nele contidos.
Sua responsabilidade como modelador de dados é garantir que seus modelos mantenham a qualidade das informações no mais alto nível possível. Para fazer isso:
- O design deve seguir pelo menos a 3ª forma normal para que não ocorram anomalias de inserção, atualização ou exclusão. Essa consideração se aplica principalmente a bancos de dados para uso transacional, onde os dados são adicionados, atualizados e excluídos regularmente. Ele não se aplica estritamente em bancos de dados para uso analítico (ou seja, data warehouses), uma vez que a atualização e a exclusão de dados raramente são realizadas, ou nunca.
- Os tipos de dados de cada campo em cada tabela devem ser adequados ao atributo que representam no modelo lógico. Isso vai além de definir corretamente se um campo é do tipo de dados numérico, de data ou alfanumérico. Também é importante definir corretamente o intervalo e a precisão dos valores suportados por cada campo. Um exemplo:um atributo do tipo Data implementado em um banco de dados como campo Data/Hora pode causar problemas nas consultas, pois um valor armazenado com sua parte de tempo diferente de zero pode ficar fora do escopo de uma consulta que utiliza um intervalo de datas.
- As dimensões e os fatos que definem a estrutura de um data warehouse devem estar alinhados às necessidades do negócio. Ao projetar um data warehouse, as dimensões e os fatos do modelo devem ser definidos corretamente desde o início. Fazer modificações assim que o banco de dados estiver operacional tem um custo de manutenção muito alto.
Gerenciando o crescimento
Outro grande desafio na manutenção de um banco de dados é impedir que seu crescimento atinja o limite de capacidade de armazenamento inesperadamente. Para ajudar no gerenciamento do espaço de armazenamento, você pode aplicar o mesmo princípio usado nos procedimentos de backup:agrupe as tabelas em seu modelo de acordo com a taxa de crescimento.
Uma divisão em duas áreas geralmente é suficiente. Coloque as tabelas com adições freqüentes de linhas em uma área, aquelas nas quais as linhas raramente são inseridas em outra. Ter o modelo setorizado dessa forma permite que os administradores de armazenamento particionem os arquivos do banco de dados de acordo com a taxa de crescimento de cada área. Eles podem distribuir as partições entre diferentes mídias de armazenamento com diferentes capacidades ou possibilidades de crescimento.
Um agrupamento de tabelas por sua taxa de crescimento ajuda a determinar os requisitos de armazenamento e gerenciar seu crescimento.
Registro
Criamos um modelo de dados esperando que ele forneça as informações como estão no momento da consulta. No entanto, tendemos a ignorar a necessidade de um banco de dados lembrar tudo o que aconteceu no passado, a menos que os usuários o exijam especificamente.
Parte da manutenção de um banco de dados é saber como, quando, por que e por quem um determinado dado foi alterado. Isso pode ser feito para descobrir quando o preço de um produto mudou ou revisar as alterações no prontuário médico de um paciente em um hospital. O registro pode ser usado até mesmo para corrigir erros do usuário ou do aplicativo, pois permite reverter o estado das informações para um ponto no passado sem a necessidade de recorrer a procedimentos complicados de restauração de backup.
Novamente, mesmo que os usuários não precisem explicitamente, considerar a necessidade de registro proativo é um meio muito valioso de facilitar a manutenção do banco de dados e demonstrar sua capacidade de antecipar problemas. Ter dados de registro permite respostas imediatas quando alguém precisa revisar informações históricas.
Existem diferentes estratégias para um modelo de banco de dados oferecer suporte ao registro, todas as quais adicionam complexidade ao modelo. Uma abordagem é chamada de log in-loco, que adiciona colunas a cada tabela para registrar informações de versão. Esta é uma opção simples que não envolve a criação de esquemas separados ou tabelas específicas de log. No entanto, isso afeta o design do modelo porque as chaves primárias originais das tabelas não são mais válidas como chaves primárias – seus valores são repetidos em linhas que representam diferentes versões dos mesmos dados.
Outra opção para manter as informações de log é usar tabelas de sombra. As tabelas de sombra são réplicas das tabelas de modelo com a adição de colunas para registrar os dados da trilha de log. Essa estratégia não requer a modificação das tabelas no modelo original, mas você precisa se lembrar de atualizar as tabelas de sombra correspondentes ao alterar seu modelo de dados.
Ainda outra estratégia é empregar um subesquema de tabelas genéricas que registram cada inserção, exclusão ou modificação em qualquer outra tabela.
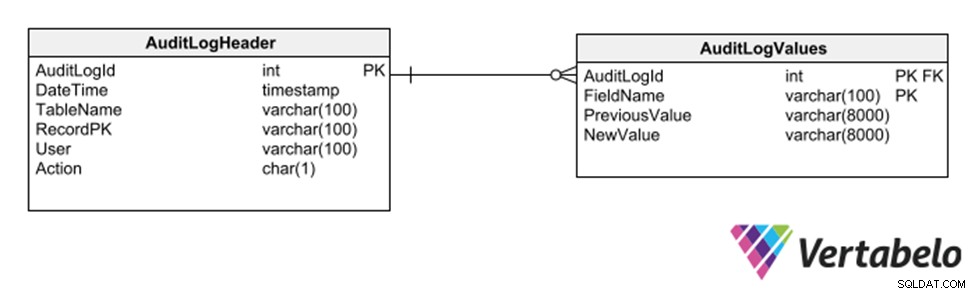
Tabelas genéricas para manter uma trilha de auditoria de um banco de dados.
Essa estratégia tem a vantagem de não exigir modificações no modelo para registro de uma trilha de auditoria. No entanto, por usar colunas genéricas do tipo varchar, limita os tipos de dados que podem ser registrados na trilha de log.
Manutenção de desempenho e criação de índice
Praticamente qualquer banco de dados tem um bom desempenho quando está começando a ser usado e suas tabelas contêm apenas algumas linhas. Mas assim que os aplicativos começarem a preenchê-lo com dados, o desempenho pode diminuir muito rapidamente se as precauções não forem tomadas ao projetar o modelo. Quando isso acontece, DBAs e administradores de sistema chamam você para ajudá-los a resolver problemas de desempenho.
A criação/sugestão automática de índices em bancos de dados de produção é uma ferramenta útil para resolver problemas de desempenho “no calor do momento”. Os mecanismos de banco de dados podem analisar as atividades do banco de dados para ver quais operações demoram mais e onde há oportunidades de acelerar criando índices.
No entanto, é muito melhor ser proativo e antecipar a situação definindo índices como parte do modelo de dados. Isso reduz bastante os esforços de manutenção para melhorar o desempenho do banco de dados. Se você não estiver familiarizado com os benefícios dos índices de banco de dados, sugiro ler tudo sobre índices, começando pelo básico.
Existem regras práticas que fornecem orientação suficiente para criar os índices mais importantes para consultas eficientes. A primeira é gerar índices para a chave primária de cada tabela. Praticamente todo RDBMS gera um índice para cada chave primária automaticamente, então você pode esquecer essa regra.
Outra regra é gerar índices para chaves alternativas de uma tabela, principalmente em tabelas para as quais uma chave substituta é criada. Se uma tabela tiver uma chave natural que não é usada como chave primária, as consultas para unir essa tabela a outras provavelmente o farão com a chave natural, não com a substituta. Essas consultas não funcionam bem, a menos que você crie um índice na chave natural.
A próxima regra prática para índices é gerá-los para todos os campos que são chaves estrangeiras. Esses campos são ótimos candidatos para estabelecer junções com outras tabelas. Se eles estiverem incluídos em índices, eles serão usados por analisadores de consulta para acelerar a execução e melhorar o desempenho do banco de dados.
Por fim, é uma boa ideia usar uma ferramenta de criação de perfil em um banco de dados de teste ou controle de qualidade durante os testes de desempenho para detectar oportunidades de criação de índice que não sejam óbvias. A incorporação dos índices sugeridos pelas ferramentas de criação de perfil no modelo de dados é extremamente útil para alcançar e manter o desempenho do banco de dados quando estiver em produção.
Segurança
Em sua função como modelador de dados, você pode ajudar a manter a segurança do banco de dados fornecendo uma base sólida e segura para armazenar dados para autenticação do usuário. Lembre-se de que essas informações são altamente confidenciais e não devem ser expostas a ataques cibernéticos.
Para que seu projeto simplifique a manutenção da segurança do banco de dados, siga as melhores práticas de armazenamento de dados de autenticação, a principal delas é não armazenar senhas no banco de dados mesmo de forma criptografada. Armazenar apenas seu hash em vez da senha de cada usuário permite que um aplicativo autentique um login de usuário sem criar nenhum risco de exposição de senha.
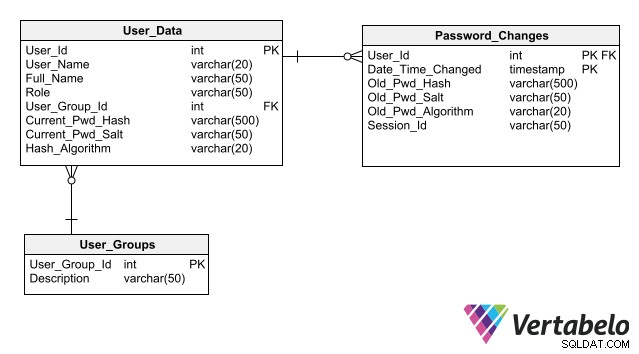
Um esquema completo para autenticação de usuário que inclui colunas para armazenar hashes de senha.
Visão para o Futuro
Portanto, crie seus modelos para facilitar a manutenção do banco de dados com bons designs de banco de dados, levando em consideração as dicas fornecidas acima. Com modelos de dados mais sustentáveis, seu trabalho fica melhor e você ganha a apreciação de DBAs, engenheiros de manutenção e administradores de sistema.
Você também investe em tranquilidade. Criar bancos de dados de fácil manutenção significa que você pode gastar suas horas de trabalho projetando novos modelos de dados, em vez de executar patches em bancos de dados que não fornecem informações corretas no prazo.