Para implementar suporte multilíngue em seu modelo de dados, você não precisa reinventar a roda. Este artigo mostrará as diferentes maneiras de fazer isso e ajudará você a escolher a que funciona melhor para você.
O conceito de localização é vital para o desenvolvimento de um aplicativo de software, principalmente quando o escopo desse aplicativo é global. O suporte para vários idiomas é o principal aspecto a ser considerado; um design de banco de dados que suporta um aplicativo multilíngue permite diversificar seus mercados-alvo e, assim, alcançar muito mais clientes. Além disso, esse design de banco de dados pode fazer parte de sua estratégia de longo prazo para projetar sistemas prontos para localização.
A chave para incorporar suporte multilíngue em seu aplicativo é fazê-lo de uma forma que não aumente drasticamente os custos de desenvolvimento ou manutenção. Como a modelagem de banco de dados é uma parte inseparável do processo de desenvolvimento de software, você precisa pensar na melhor estratégia de design de modelo de dados para fornecer suporte multilíngue ao seu aplicativo.
Um modelo de dados adequado deve permitir que você modifique o aplicativo ou adicione novas funcionalidades, mantendo o suporte a vários idiomas – sem adicionar esforço ou custo extra. Também deve permitir que você incorpore novos idiomas sem tocar no aplicativo; você só precisa adicionar os dados de tradução correspondentes ao banco de dados.
Implementação simples versus flexibilidade e funcionalidade
Existem diferentes abordagens para criar um design de banco de dados para aplicativos multilíngues. Cada um tem suas vantagens e desvantagens. Aqueles que são mais fáceis de implementar oferecem menos flexibilidade e menos funcionalidade; aqueles que oferecem mais flexibilidade e funcionalidade têm implementações mais complexas.
Meu conselho aqui é sempre escolher os que oferecem mais funcionalidade e flexibilidade , mesmo que sejam mais caros de implementar. Às vezes cometemos o erro de pensar que um aplicativo é muito pequeno, que não vale a pena implementar esquemas complexos para resolver coisas como suporte a vários idiomas. Mas, eventualmente, esse aplicativo crescerá e nos arrependeremos de optar pela abordagem “rápida e suja” que parecia mais simples e menos cara.
O ideal para implementar a funcionalidade acessória em um aplicativo – seja suporte multilíngue, log de alterações, autenticação de usuário ou qualquer outra coisa – é que essa funcionalidade tenha seu próprio subesquema e sua lógica encapsulada em componentes reutilizáveis. Desta forma, tanto a funcionalidade do acessório quanto seu subesquema podem ser incorporados em qualquer nova aplicação com o mínimo esforço.
Uma ferramenta inteligente de design de banco de dados e modelagem de dados como o Vertabelo é uma grande ajuda para o gerenciamento eficiente de seus esquemas e subesquemas. Além disso, confira essas dicas para um melhor design de banco de dados e certifique-se de seguir todas elas. Antes de começar a desenhar seu diagrama ER, sugiro que você considere esta série essencial de dicas de modelagem de banco de dados.
Algumas soluções atraentes (mas desaconselháveis) de design de banco de dados em vários idiomas
Mais fácil – mas menos recomendado
Vamos começar com a maneira menos recomendada, mas mais fácil, de implementar um banco de dados de aplicativos multilíngue. Ele permite que você resolva rapidamente a necessidade de suporte a um aplicativo multilíngue, mas trará problemas quando o aplicativo crescer em funcionalidade ou em cobertura geográfica.
Essa estratégia simples consiste em adicionar uma coluna adicional para cada coluna de texto que precisa ser traduzida e para cada idioma para o qual os textos devem ser traduzidos.
Por exemplo, em
Movies tabela abaixo, há um OriginalTitle campo. Uma coluna de título adicional é adicionada para cada idioma a ser traduzido:| MovieId | Título Original | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Duro de morrer | Duro de matar | Trappola de cristal | Peça de cristal |
| 2 | De volta para o futuro | Voltar ao futuro | Rito no futuro | Retornar para o futuro |
| 3 | Jurassic Park | Parque jurásico | Giurassico parque | Parc jurassique |
A aplicação deve obter os dados descritivos da coluna correspondente ao idioma selecionado pelo usuário. Quando você precisa adicionar um novo idioma, você deve adicionar uma coluna adicional à tabela para conter os textos traduzidos para o novo idioma. Você também deve adaptar o aplicativo para reconhecer o idioma e as colunas adicionados.
Esta solução não requer JOINs complicados para obter os textos traduzidos, nem requer registros duplicados – apenas a replicação de colunas de conteúdo de texto. Mas sua aplicabilidade é limitada a situações em que apenas algumas tabelas precisam ser traduzidas.
Por exemplo, suponha que você tenha um
Products tabela e um Processes tabela. Cada um deles possui um campo Descrição que precisa ser traduzido; parece fácil o suficiente, certo? Mas se todo o aplicativo (incluindo todas as opções de menu, mensagens de erro, etc.) precisar ser multilíngue, essa solução não será aplicável. Mais versátil, mas também não aconselhável
Continuando com a ideia de manter as traduções dentro da mesma tabela, uma alternativa à opção anterior é ampliar os campos de texto. Isso nos permitiria armazenar todas as traduções no mesmo campo, organizando-as em uma estrutura de dados (por exemplo, um documento XML ou um objeto JSON). Abaixo temos um exemplo:
| MovieId | Título Original | Traduções |
| 1 | Duro de Matar | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | De volta para o Futuro | [ {"language":"sp", "title":"Voltar ao futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Parque jurassico | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Esta opção não requer colunas adicionais, mas adiciona complexidade. As consultas de dados agora devem ser capazes de processar e interpretar corretamente a estrutura de dados usada para suporte a vários idiomas. Por exemplo, se JSON ou XML for usado para armazenar traduções, as consultas SQL deverão usar uma versão SQL que suporte o tipo de dados escolhido.
O comando SQL a seguir usa o MS SQL Server
OPENJSON() função para usar o conteúdo do Translations campo como uma tabela subordinada:SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Como não há funções ou operadores para manipular dados formatados em JSON ou XML no SQL padrão, você é forçado a escrever suas consultas para um RDBMS específico se quiser usar essa técnica para armazenar textos traduzidos. Por exemplo, a consulta anterior não é suportada pelo MySQL. Se você precisar ler os dados JSON em
Movies table com MySQL, você escreveria esta consulta:SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Armazenamento de texto traduzido em diferentes registros
Você também pode optar por usar registros diferentes para cada idioma. No entanto, você deve se resignar a perder a normalização:os mesmos dados se repetem em vários registros, nos quais varia apenas a tradução.
| MovieId | LanguageId | Título |
|---|---|---|
| 1 | pt | Duro de morrer |
| 1 | sp | Duro de matar |
| 1 | ele | Trappola de cristal |
| 1 | fr | Peça de cristal |
| 2 | pt | De volta para o futuro |
| 2 | sp | Voltar ao futuro |
| 2 | ele | Rito no futuro |
Com esta opção, você pode criar visualizações de cada tabela que retornam apenas as linhas em um determinado idioma:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Então, para consultar a tabela, você pode usar uma visualização diferente de acordo com o idioma de tradução de destino. Mas a normalização do modelo é perdida e a manutenção da tabela é desnecessariamente complexa.
Armazenamento de texto traduzido em tabelas separadas
Uma forma de armazenar os textos traduzidos sem quebrar o modelo relacional é ter uma tabela de detalhes para cada tabela contendo os textos a serem traduzidos. A tabela subordinada que contém as traduções deve ter os mesmos campos-chave da tabela mãe, além de um campo indicando o idioma da tradução.
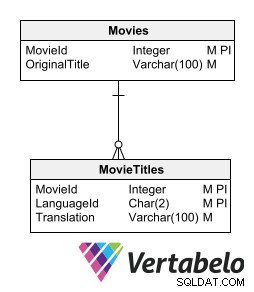
Uma tabela subordinada com traduções deve ter os mesmos campos-chave da tabela mãe, além de um campo indicando o idioma da tradução.
Esta opção permite incorporar novos idiomas sem alterar a estrutura da tabela. Não requer gerar informações redundantes ou quebrar a normalização do modelo.
A desvantagem desta opção é que ela requer a criação de uma tabela subordinada para cada tabela que armazena dados textuais que requerem tradução. No entanto, a ideia de armazenar traduções em tabelas relacionadas nos aproxima da maneira mais aconselhável de projetar um banco de dados multilíngue.
A solução universal:um subesquema de tradução
Para que um aplicativo e seu banco de dados sejam verdadeiramente multilíngues, todos os textos devem ter uma tradução em cada idioma suportado – não apenas os dados de texto em uma tabela específica. Isso é conseguido com um subesquema de tradução onde são armazenados todos os dados com conteúdo textual que podem chegar aos olhos do usuário.
Em aplicativos da Web destinados ao uso em diferentes idiomas, um subesquema de tradução é uma necessidade, não uma opção. Qualquer outra coisa levará a complexidades que impossibilitarão a manutenção adequada do aplicativo.
A chave para manter as traduções em um esquema separado é manter um catálogo indexado com todos os textos que precisam de tradução, sejam descrições de entidades, mensagens de erro ou opções de menu. A ideia é que nenhum texto que possa alcançar os olhos do usuário seja armazenado em qualquer tabela fora deste subesquema.
Uma maneira de organizar o catálogo de traduções é usar três tabelas:
- Uma tabela mestra de idiomas.
- Uma tabela de textos no idioma original.
- Uma tabela de textos traduzidos.
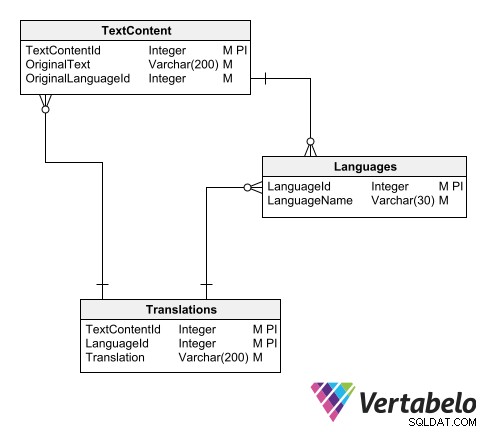
Esquema para um catálogo de tradução universal.
Na tabela mestre de idiomas, basta inserir um registro para cada idioma suportado pelo modelo de dados. Cada um tem um código de identificação e um nome:
| LanguageId | LanguageName |
|---|---|
| pt | Inglês |
| sp | Espanhol |
| isso | italiano |
| fr | Francês |
A tabela de texto registra todos os textos que requerem tradução. Cada registro tem um ID arbitrário, o texto original e o ID do idioma original.
No
TextContent tabela, o texto original e o ID do idioma original não são estritamente necessários. Mas eles simplificam as consultas que não requerem tradução. Por exemplo, ao fazer análises estatísticas ou consultas de controle de gerenciamento (que geralmente estão disponíveis apenas para usuários que entendem o idioma original), as consultas podem ser simplificadas usando os textos padrão (não traduzidos). Os textos originais também são úteis para quem precisa preencher a tabela de textos traduzidos. A entrada de dados de tradução pode ser feita por meio de um miniaplicativo que mostra o texto original e as traduções em todos os idiomas disponíveis. Também é possível gerar informações para o subesquema de tradução por meio de um processo automático usando uma API de tradução.
Vinculação com o esquema principal
No esquema principal do aplicativo, as colunas com valores de texto que precisam ser traduzidas são substituídas por IDs que apontam para a tabela de textos traduzidos:
O esquema principal está vinculado ao esquema de tradução por meio de tabelas com textos que precisam de tradução.
Você pode deixar o campo de texto original em algumas das principais tabelas de esquema para facilitar as consultas onde a tradução não é necessária, mesmo que isso gere informações redundantes. Por exemplo, podemos manter o
ProductDescription campo em Products tabela para facilitar consultas estatísticas ou para preencher as dimensões de um data warehouse, deixando de lado o subesquema de tradução quando não for necessário. - Design de banco de dados multilíngue:faça uma vez e faça certo
Vimos várias alternativas para criar um design de banco de dados multilíngue. Alguns são mais fáceis e rápidos de implementar. A última solução é um pouco mais complexa, mas oferece muito mais flexibilidade. Também evitará problemas quando chegar a hora de manter o aplicativo e o banco de dados. Assim, a longo prazo, será muito mais barato.
Às vezes, o caminho mais curto no design de banco de dados o leva a acreditar que economizará tempo e esforço. Mas quando você o escolhe, está ignorando o fato de que provavelmente terá que descer várias vezes. Se você ignorar as práticas recomendadas para design de banco de dados multilíngue, provavelmente acabará fazendo o mesmo trabalho repetidamente.