TimescaleDB é um banco de dados de código aberto inventado para tornar o SQL escalável para dados de séries temporais. É um sistema de banco de dados relativamente novo. O TimescaleDB foi introduzido no mercado há dois anos e alcançou a versão 1.0 em setembro de 2018. No entanto, ele foi desenvolvido com base em um sistema RDBMS maduro.
TimescaleDB é empacotado como uma extensão do PostgreSQL. Todo o código é licenciado sob a licença de código aberto Apache-2, com exceção de alguns códigos-fonte relacionados aos recursos corporativos de séries temporais licenciados sob a Licença de Escala de Tempo (TSL).
Como um banco de dados de série temporal, ele fornece particionamento automático entre data e valores de chave. O suporte a SQL nativo do TimescaleDB o torna uma boa opção para quem planeja armazenar dados de séries temporais e já possui um sólido conhecimento da linguagem SQL.
Se você estiver procurando por um banco de dados de série temporal que possa usar SQL avançado, HA, uma solução de backup sólida, replicação e outros recursos corporativos, este blog pode colocá-lo no caminho certo.
Quando usar TimescaleDB
Antes de começarmos com os recursos do TimescaleDB, vamos ver onde ele pode se encaixar. O TimescaleDB foi projetado para oferecer o melhor do relacional e do NoSQL, com foco em séries temporais. Mas o que são dados de séries temporais?
Dados de séries temporais estão no centro da Internet das Coisas, sistemas de monitoramento e muitas outras soluções focadas em dados em constante mudança. Como o nome “série temporal” sugere, estamos falando de dados que mudam com o tempo. As possibilidades para esse tipo de SGBD são infinitas. Você pode usá-lo em vários casos de uso de IoT industrial em manufatura, mineração, petróleo e gás, varejo, saúde, monitoramento de operações de desenvolvimento ou setor de informações financeiras. Ele também pode se encaixar muito em pipelines de aprendizado de máquina ou como fonte para operações e inteligência de negócios.
Não há dúvida de que a demanda por IoT e soluções similares crescerá. Com isso dito, também podemos esperar a necessidade de analisar e processar dados de muitas maneiras diferentes. Os dados de série temporal normalmente são apenas anexados - é bastante improvável que você esteja atualizando dados antigos. Você normalmente não exclui linhas específicas, por outro lado, você pode querer algum tipo de agregação dos dados ao longo do tempo. Não queremos apenas armazenar como nossos dados mudam com o tempo, mas também analisá-los e aprender com eles.
O problema com os novos tipos de sistemas de banco de dados é que eles geralmente usam sua própria linguagem de consulta. Leva tempo para os usuários aprenderem um novo idioma. A maior diferença entre o TimescaleDB e outros bancos de dados de séries temporais populares é o suporte para SQL. O TimescaleDB oferece suporte a toda a gama de funcionalidades do SQL, incluindo agregações baseadas em tempo, junções, subconsultas, funções de janela e índices secundários. Além disso, se seu aplicativo já estiver usando o PostgreSQL, não há necessidade de alterações no código do cliente.
Noções básicas de arquitetura
O TimescaleDB é implementado como uma extensão no PostgreSQL, o que significa que um banco de dados de escala de tempo é executado em uma instância geral do PostgreSQL. O modelo de extensão permite que o banco de dados aproveite muitos dos atributos do PostgreSQL, como confiabilidade, segurança e conectividade com uma ampla variedade de ferramentas de terceiros. Ao mesmo tempo, o TimescaleDB aproveita o alto grau de personalização disponível para extensões, adicionando ganchos ao planejador de consultas, modelo de dados e mecanismo de execução do PostgreSQL.
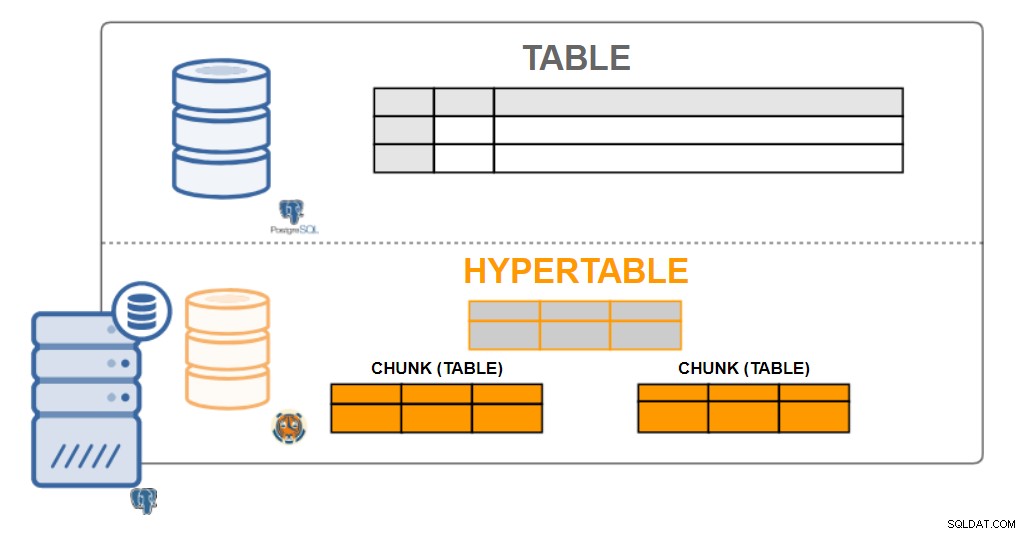 arquitetura TimescaleDB
arquitetura TimescaleDB Hipertabelas
Do ponto de vista do usuário, os dados do TimescaleDB se parecem com tabelas singulares, chamadas hipertabelas. As hipertabelas são um conceito ou uma visão implícita de muitas tabelas individuais que contêm os dados chamados pedaços. Os dados da hipertabela podem ter uma ou duas dimensões. Ele pode ser agregado por um intervalo de tempo e por um valor (opcional) de "chave de partição".
Praticamente todas as interações do usuário com o TimescaleDB são com hipertabelas. Criar tabelas, índices, alterar tabelas, selecionar dados, inserir dados... tudo deve ser executado na hipertabela.
O TimescaleDB executa esse particionamento extensivo tanto em implantações de nó único quanto em implantações em cluster (em desenvolvimento). Embora o particionamento seja tradicionalmente usado apenas para dimensionar em várias máquinas, ele também nos permite dimensionar até altas taxas de gravação (e consultas paralelizadas aprimoradas) mesmo em máquinas únicas.
Suporte a dados relacionais
Como um banco de dados relacional, possui suporte total para SQL. O TimescaleDB oferece suporte a modelos de dados flexíveis que podem ser otimizados para diferentes casos de uso. Isso torna a escala de tempo um pouco diferente da maioria dos outros bancos de dados de séries temporais. O SGBD é otimizado para ingestão rápida e consultas complexas, baseado em PostgreSQL e, quando necessário, temos acesso a processamento robusto de séries temporais.
Instalação
TimescaleDB de forma semelhante ao PostgreSQL suporta muitas formas diferentes de instalação, incluindo instalação no Ubuntu, Debian, RHEL/Centos, Windows ou plataformas em nuvem.
Uma das maneiras mais convenientes de jogar com o TimescaleDB é uma imagem docker.
O comando abaixo extrairá uma imagem do Docker do Docker Hub se ela ainda não tiver sido instalada e a executará.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPrimeiro uso
Como nossa instância está funcionando, é hora de criar nosso primeiro banco de dados timescaledb. Como você pode ver abaixo, nos conectamos por meio do console padrão do PostgreSQL, portanto, se você tiver ferramentas de cliente PostgreSQL (por exemplo, psql) instaladas localmente, poderá usá-las para acessar a instância do docker TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Operações diárias
Do ponto de vista de uso e gerenciamento, o TimescaleDB apenas se parece com o PostgreSQL e pode ser gerenciado e consultado como tal.
Os principais pontos para as operações do dia a dia são:
- Coexiste com outros bancos de dados TimescaleDBs e PostgreSQL em um servidor PostgreSQL.
- Usa SQL como linguagem de interface.
- Usa conectores comuns do PostgreSQL para ferramentas de terceiros para backups, console etc.
Configurações do TimescaleDB
As configurações prontas para uso do PostgreSQL geralmente são muito conservadoras para servidores modernos e TimescaleDB. Você deve certificar-se de que suas configurações do postgresql.conf estão ajustadas, usando timescaledb-tune ou manualmente.
$ timescaledb-tuneO script solicitará que você confirme as alterações. Essas alterações são gravadas em seu postgresql.conf e entrarão em vigor na reinicialização.
Agora, vamos dar uma olhada em algumas operações básicas do tutorial do TimescaleDB que podem lhe dar uma ideia de como trabalhar com o novo sistema de banco de dados.
Para criar uma hipertabela, você começa com uma tabela SQL normal e depois a converte em uma hipertabela por meio da função create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Convertê-lo para hipertabela é simples assim:
SELECT create_hypertable('conditions', 'time');A inserção de dados na hipertabela é feita por meio de comandos SQL normais:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Selecionando dados, é um bom SQL antigo.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Como podemos ver abaixo, podemos fazer um group by, order by e functions. Além disso, TimescaleDB inclui funções para análise de séries temporais que não estão presentes no Vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;


