O que a indexação faz?
A indexação é a maneira de obter uma tabela não ordenada em uma ordem que maximizará a eficiência da consulta durante a pesquisa.
Quando uma tabela não é indexada, a ordem das linhas provavelmente não será discernível pela consulta como otimizada de forma alguma e, portanto, sua consulta terá que pesquisar as linhas linearmente. Em outras palavras, as consultas terão que pesquisar em todas as linhas para encontrar as linhas que correspondem às condições. Como você pode imaginar, isso pode levar muito tempo. Olhar através de cada linha não é muito eficiente.
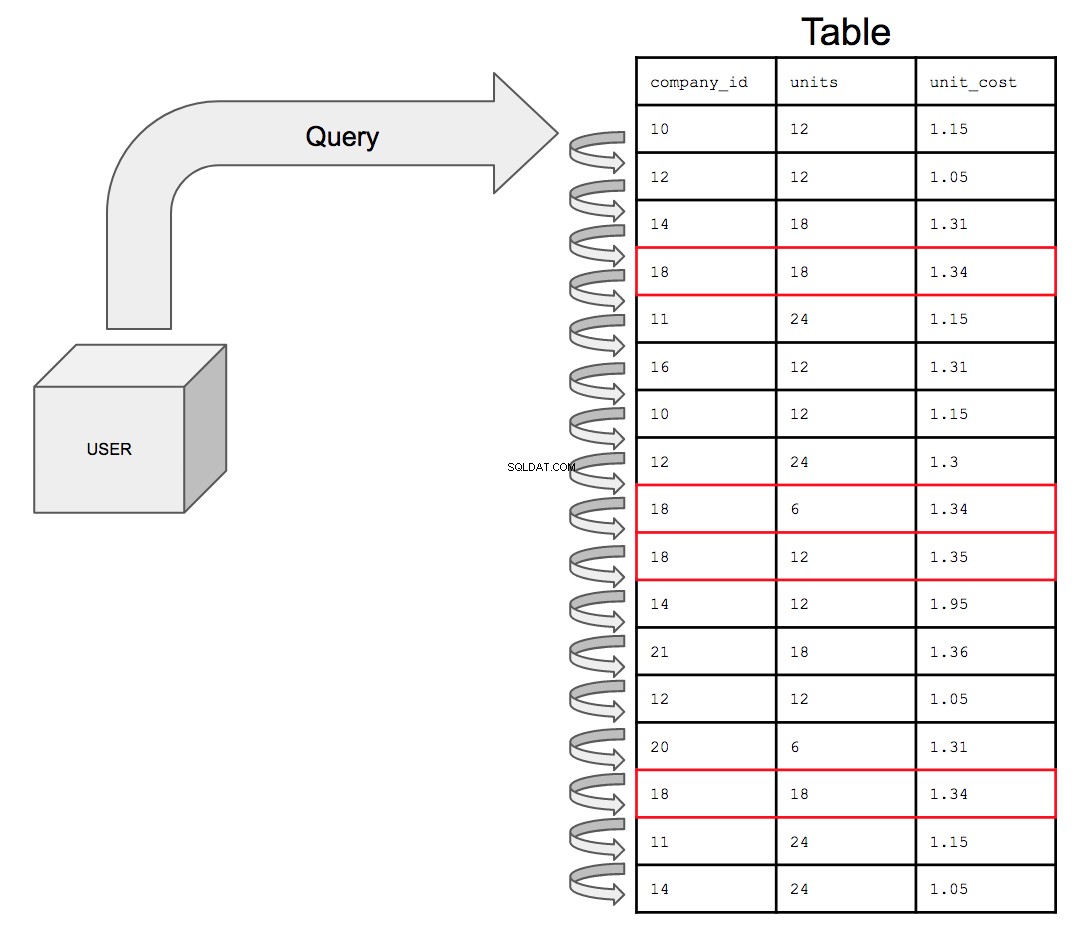
Por exemplo, a tabela abaixo representa uma tabela em uma fonte de dados fictícia, que é completamente desordenada.
| company_id | unidade | custo_unidade |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Se fôssemos executar a seguinte consulta:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
O banco de dados teria que pesquisar todas as 17 linhas na ordem em que aparecem na tabela, de cima para baixo, uma de cada vez. Portanto, para pesquisar todas as possíveis instâncias do
company_id número 18, o banco de dados deve procurar em toda a tabela todas as aparências de 18 no company_id coluna. Isso só consumirá cada vez mais tempo à medida que o tamanho da tabela aumentar. À medida que a sofisticação dos dados aumenta, o que pode eventualmente acontecer é que uma tabela com um bilhão de linhas seja unida a outra tabela com um bilhão de linhas; a consulta agora precisa pesquisar o dobro da quantidade de linhas, custando o dobro do tempo.
Você pode ver como isso se torna problemático em nosso mundo sempre saturado de dados. As tabelas aumentam de tamanho e a pesquisa aumenta o tempo de execução.
Consultar uma tabela não indexada, se apresentada visualmente, ficaria assim:
O que a indexação faz é configurar a coluna em que as condições de pesquisa estão em uma ordem de classificação para ajudar a otimizar o desempenho da consulta.
Com um índice no
company_id coluna, a tabela seria, essencialmente, “se parecer” com isto:| company_id | unidade | custo_unidade |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Agora, o banco de dados pode pesquisar por
company_id número 18 e retornar todas as colunas solicitadas para essa linha, em seguida, passe para a próxima linha. Se o comapny_id da próxima linha número também for 18, então ele retornará todas as colunas solicitadas na consulta. Se o company_id da próxima linha for 20, a consulta sabe que deve parar de pesquisar e a consulta terminará. Como funciona a indexação?
Na realidade, a tabela de banco de dados não se reordena toda vez que as condições de consulta mudam para otimizar o desempenho da consulta:isso seria irreal. Na verdade, o que acontece é que o índice faz com que o banco de dados crie uma estrutura de dados. O tipo de estrutura de dados é muito provavelmente uma B-Tree. Embora as vantagens do B-Tree sejam numerosas, a principal vantagem para nossos propósitos é que ele é classificável. Quando a estrutura de dados é classificada em ordem, torna nossa busca mais eficiente pelas razões óbvias que apontamos acima.
Quando o índice cria uma estrutura de dados em uma coluna específica, é importante observar que nenhuma outra coluna é armazenada na estrutura de dados. Nossa estrutura de dados para a tabela acima conterá apenas o
company_id números. Unidades e unit_cost não será mantido na estrutura de dados. Como o banco de dados sabe quais outros campos da tabela devem ser retornados?
Os índices de banco de dados também armazenam ponteiros que são simplesmente informações de referência para a localização das informações adicionais na memória. Basicamente, o índice contém o
company_id e o endereço residencial dessa linha específica no disco de memória. Na verdade, o índice ficará assim:| company_id | ponteiro |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Com esse índice, a consulta pode pesquisar apenas as linhas no
company_id coluna que tem 18 e, em seguida, usando o ponteiro, pode entrar na tabela para encontrar a linha específica onde esse ponteiro reside. A consulta pode então entrar na tabela para recuperar os campos das colunas solicitadas para as linhas que atendem às condições. Se a pesquisa fosse apresentada visualmente, ficaria assim:
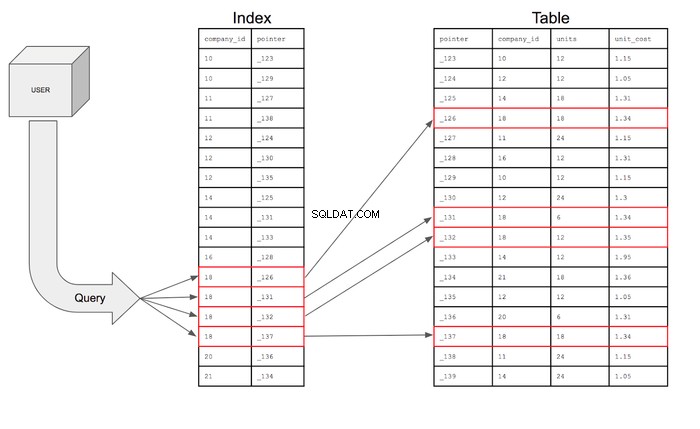
Recapitulação
- A indexação adiciona uma estrutura de dados com colunas para as condições de pesquisa e um ponteiro
- O ponteiro é o endereço no disco de memória da linha com o restante das informações
- A estrutura de dados do índice é classificada para otimizar a eficiência da consulta
- A consulta procura a linha específica no índice; o índice se refere ao ponteiro que encontrará o restante das informações.
- O índice reduz o número de linhas que a consulta precisa pesquisar de 17 para 4.