No artigo anterior, expliquei como poderíamos instalar o Ubuntu 18.04 e o SQL Server 2019 nas máquinas virtuais. Agora, antes de prosseguirmos, vamos passar pela configuração.
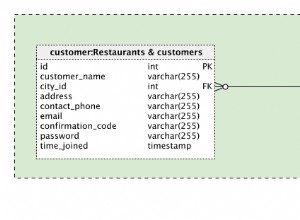
Criamos três máquinas virtuais e os detalhes são os seguintes:
| Nome do host | Endereço IP | Função |
| LinuxSQL01 | 192.168.0.140 | Réplica primária |
| LinuxSQL02 | 192.168.0.141 | Réplica secundária síncrona |
| LinuxSQL03 | 192.168.0.142 | Réplica secundária assíncrona |
Atualize o arquivo host.
Na configuração, não estamos usando um servidor de domínio. Portanto, para resolver o nome do host, devemos adicionar uma entrada no arquivo do host.
O arquivo host está localizado em /etc diretório. Execute o comando abaixo para editar o arquivo:
example@sqldat.com:/# vim /etc/hostsNo arquivo de host, insira os nomes de host e os endereços IP de todas as máquinas virtuais:
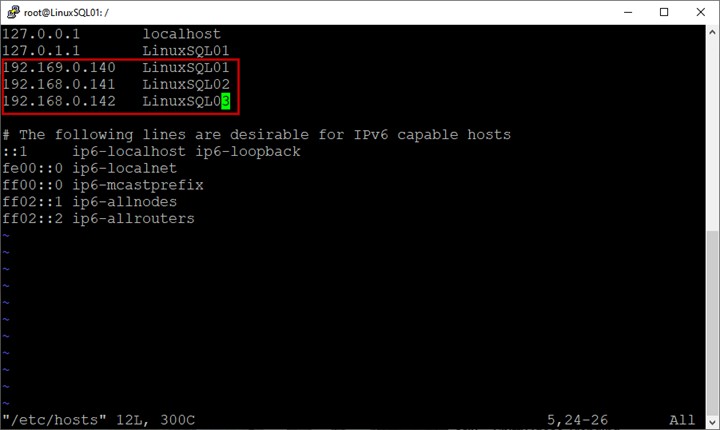
Salve o arquivo hospedeiro.
Execute as mesmas etapas em todas as máquinas virtuais.
Ativar grupos de disponibilidade AlwaysOn do SQL Server
Antes de implantar o AlwaysOn, devemos habilitar o recurso de alta disponibilidade no SQL Server.
No Windows Server 2016, essa opção pode ser habilitada a partir do gerenciador de configuração do SQL Server, mas na plataforma Linux devemos fazê-lo com um comando bash.
Conecte-se ao LinuxSQL01 usando o Putty e execute o seguinte comando:
example@sqldat.com:~# sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Reinicie os serviços do SQL Server:
example@sqldat.com:~# service mssql-server restartExecute as etapas acima em todas as máquinas virtuais.
Crie os certificados para autenticação
Ao contrário do AlwaysOn no servidor Windows, a implantação do Linux não requer um controlador de domínio. Para autenticação e comunicação entre réplicas primárias e secundárias, ele usa o certificado.
O script a seguir cria um certificado e uma chave mestra. Em seguida, ele faz backup do certificado e o protege com uma senha.
Conecte-se ao LinuxSQL01 e execute o seguinte script:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE AG_Auth_Cert
TO FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.pvk',
ENCRYPTION BY PASSWORD = 'abcd!1234'
);
Assim que obtivermos o certificado e a chave mestra criados, nós os copiamos para réplicas secundárias (LinuxSQL02 e LinuxSQL03) executando o comando abaixo.
Certifique-se de que a localização da chave mestra e do certificado seja a mesma em todas as réplicas e tenha permissão de leitura/gravação.
/*Copy certificate and the key to LinuxSQL02*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
/*Copy certificate and the key to LinuxSQL03*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
Execute o seguinte comando em nós secundários para conceder permissão de leitura e gravação no certificado e na chave privada:
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
Uma vez que a permissão é atribuída, criamos o certificado e a chave mestra usando o backup do certificado e da chave mestra criados no LinuxSQL01.
Para fazer isso, execute o seguinte comando em ambas as réplicas secundárias:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert
FROM FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.pvk',
DECRYPTION BY PASSWORD = 'abcd!1234'
);
Depois de criar o certificado e a chave mestra, configuraremos os pontos de espelhamento do banco de dados.
Crie os endpoints de espelhamento
Para se comunicar entre as réplicas primárias e secundárias, o SQL Server usa pontos de extremidade de espelhamento.
Um endpoint de espelhamento usa o protocolo TCP/IP para enviar e receber mensagens de réplicas primárias e secundárias e atende em uma porta TCP/IP exclusiva.
Execute o script a seguir para criar um endpoint nos nós primário e secundário:
/*Run this script on LinuxSQL01*/
CREATE ENDPOINT [AG_LinuxSQL01]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL01] STATE = STARTED;
/*Run this script on LinuxSQL02*/
CREATE ENDPOINT [AG_LinuxSQL02]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL02] STATE = STARTED;
/*Run this script on LinuxSQL03*/
CREATE ENDPOINT [AG_LinuxSQL03]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL03] STATE = STARTED;
Depois que os pontos de espelhamento forem criados, vamos criar um grupo de disponibilidade.
Criar grupo de disponibilidade
Vamos configurar o AlwaysON usando o SQL Server Management Studio.
Primeiro, inicie-o e conecte-se à instância LinuxSQL01 usando sa credenciais. Uma vez conectado à instância do SQL Server, clique com o botão direito do mouse em Always On High Availability e selecione o Assistente de Novo Grupo de Disponibilidade .
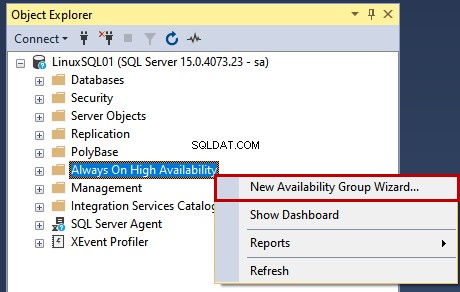
O assistente de grupo de disponibilidade começa.
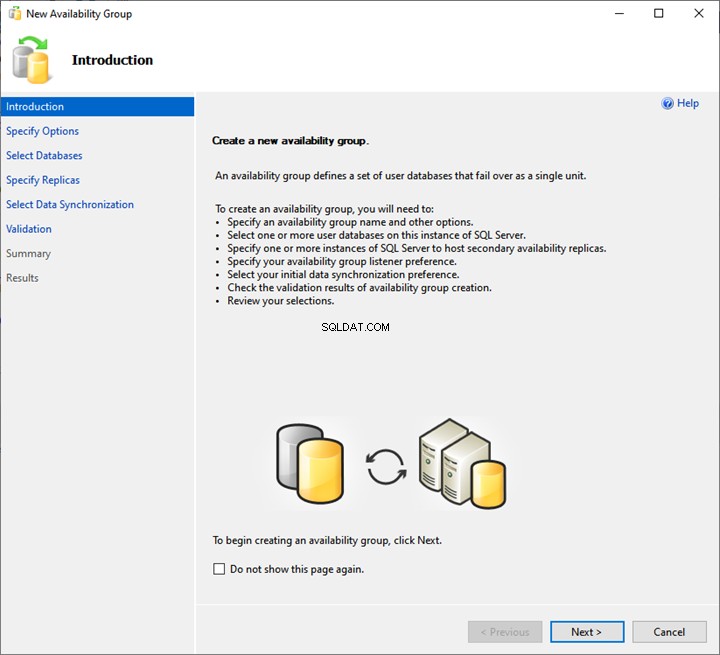
1. Introdução
Em uma Introdução tela, veja a lista de tarefas que serão executadas pelo assistente do grupo de disponibilidade. Clique em Avançar.
2. Especificar a opção do grupo de disponibilidade
Na tela Especificar opção de grupo de disponibilidade, forneça o nome do grupo de disponibilidade desejado e escolha EXTERNAL do tipo de cluster menu suspenso.
Além disso, marque a Detecção de integridade no nível do banco de dados caixa de seleção. Ele habilita a sessão de evento estendida para a disponibilidade da integridade do grupo.
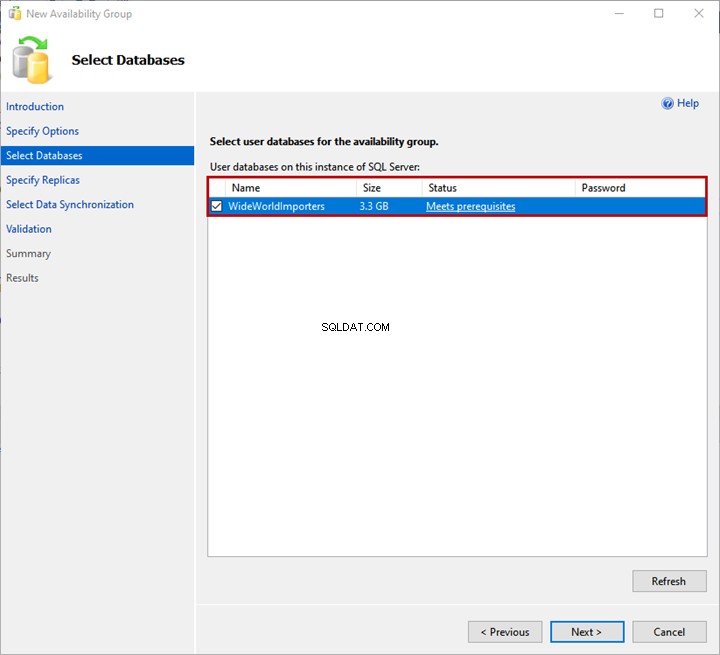
3. Selecionar bancos de dados
Você pode escolher o banco de dados para adicionar ao grupo de disponibilidade em Selecionar bancos de dados tela. Nota:O banco de dados deve atender aos seguintes pré-requisitos:
- O banco de dados deve estar no modelo de recuperação COMPLETO.
- Um backup COMPLETO do banco de dados deve ser criado.
Eu restaurei um backup dos WideWorldImportors banco de dados na réplica primária. O banco de dados está em FULL modelo de recuperação e um backup completo foi gerado.
Selecione os WideWorldImporters banco de dados da lista e clique em Avançar .
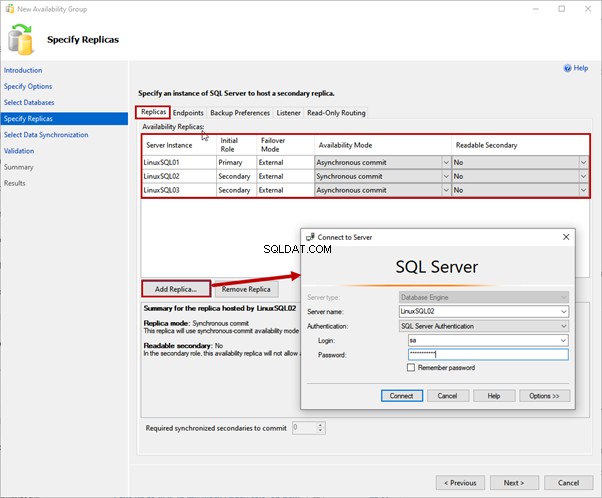
4. Especificar réplicas
Na página Especificar réplicas tela, temos várias abas para configurar diferentes opções. Vamos revisá-los todos.
guia Réplicas
Aqui, especificamos as réplicas primárias e secundárias, o modo de disponibilidade e os modos de failover.
Usamos LinuxSQL01 como uma réplica primária. LinuxSQL02 e LinuxSQL03 são uma réplica secundária.
O modo de disponibilidade para LinuxSQL02 será Commit síncrono , e para LinuxSQL03 será commit assíncrono .
Para adicionar a réplica, clique em Adicionar réplica . Em seguida, em Conectar ao servidor caixa de diálogo, especifique o nome do servidor e os detalhes de login do SQL para se conectar à instância:
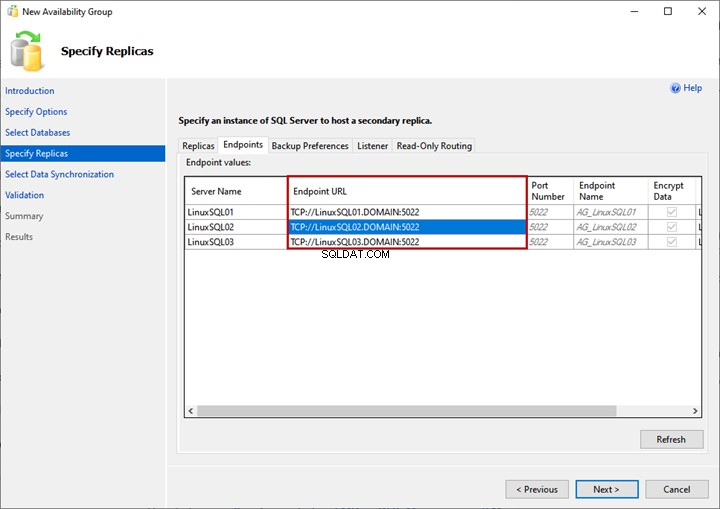
Guia Pontos de extremidade
Aqui, podemos ver a lista de réplicas e seus endpoints de espelhamento com os números e nomes das portas correspondentes:
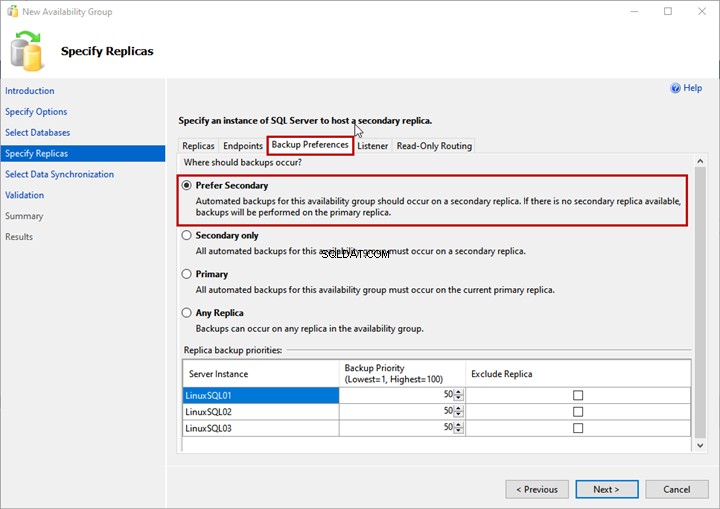
Preferências de backup
Aqui, você especifica a réplica que deseja usar para gerar o backup. Essa opção é útil quando você deseja descarregar o processo de backup do banco de dados SQL no grupo de disponibilidade.
Você pode escolher qualquer uma das seguintes opções:
- Preferir secundário:o backup será gerado na réplica secundária. Se a réplica secundária não estiver disponível, o backup será gerado na réplica primária.
- Somente secundário:todos os backups serão gerados na réplica secundária.
- Primário:os backups serão gerados na réplica primária.
- Qualquer réplica:o backup será gerado a partir de qualquer uma das réplicas.
Usaremos o Prefer Secondary opção:
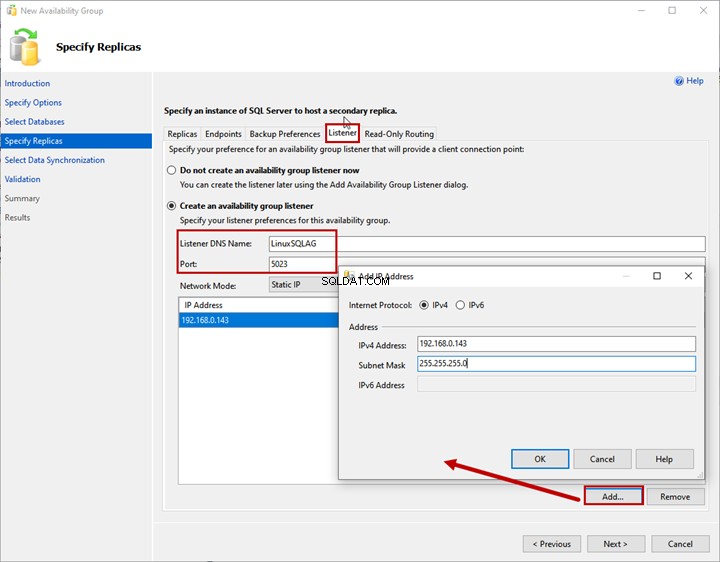
Ouvinte
O ouvinte do grupo de disponibilidade é um nome virtual usado por um aplicativo para conectar os bancos de dados do grupo de disponibilidade. Especifique o nome DNS do ouvinte e sua porta em Nome DNS do ouvinte e Porta caixas de texto.
Selecione IP estático do Modo de Rede menu suspenso.
Para adicionar o endereço IP para o ouvinte do grupo de disponibilidade, clique em Adicionar >Digite Endereço IP e Máscara de sub-rede .
Roteamento somente leitura
Aqui, você pode fornecer o URL de roteamento somente leitura e Lista de roteamento somente leitura para réplicas primárias e secundárias.
Não configuraremos o roteamento somente leitura em nossa demonstração. Portanto, clique em Avançar. Para saber mais sobre o roteamento somente leitura, você pode consultar Roteamento somente leitura para um Always On.
Agora, vamos voltar ao processo principal em que trabalhamos.
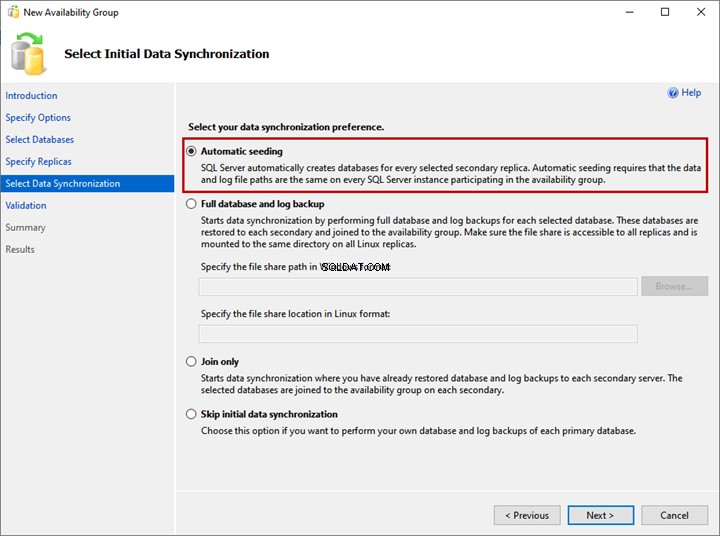
5. Selecione a sincronização de dados inicial
Em Selecionar sincronização de dados inicial tela, defina suas preferências para a sincronização de dados inicial. Os detalhes de cada opção são fornecidos na tela do assistente e você pode escolher qualquer uma delas:
- Semeadura automática.
- Banco de dados completo e backup de log.
- Somente para participar.
- Ignore a sincronização de dados inicial.
Eu não criei os WideWorldImporters banco de dados na réplica LinuxSQL02 e LinuxSQL03, selecionando a Semeadura automática opção. Ele criará o banco de dados em ambas as réplicas e iniciará a sincronização de dados. Clique em Avançar.
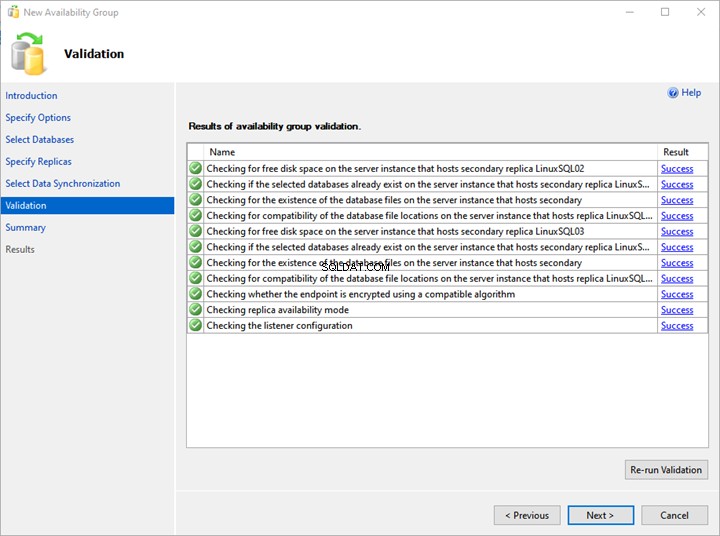
6. Validação e Resumo
Na Validação tela, o assistente valida todas as configurações.
Para implantar o grupo de disponibilidade Always On com êxito, você precisa de todas as validações bem-sucedidas. Se houver algum erro, você deve resolvê-lo.
No Resumo tela, você pode ver a lista de configurações escolhidas para implantar o grupo de disponibilidade.
Revise os detalhes mais uma vez e clique em Concluir – inicia o processo de implantação.
Se você deseja gerar o script do processo de implantação, clique em Script .
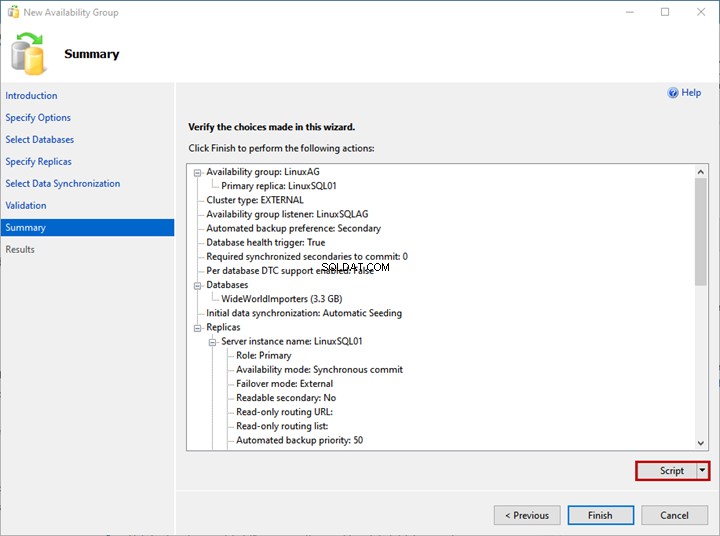
Como vemos, o processo de implantação AlwaysOn é iniciado. Depois de concluído com êxito, clique em Fechar para sair do assistente.
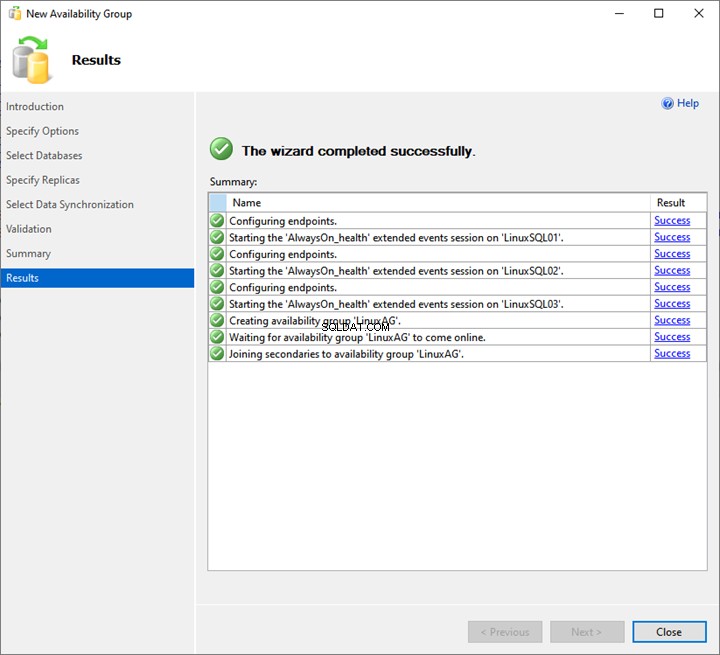
Assim, a implantação do grupo de disponibilidade AlwaysOn no SQL Server 2019 está concluída.
Resumo
Este artigo nos ajuda a entender o processo de implantação passo a passo do grupo de disponibilidade AlwaysOn do SQL Server no Linux.
O próximo artigo explicará como podemos configurar o ouvinte do grupo de disponibilidade e realizar o failover manual usando o SQL Server Management Studio. Fique atento!