Introdução
Ao executar o Galera Cluster, é uma prática comum adicionar um ou mais escravos assíncronos no mesmo datacenter ou em um datacenter diferente. Isso nos proporciona um plano de contingência com baixo RTO e baixo custo operacional. No caso de um problema irrecuperável em nosso cluster, podemos fazer failover rapidamente para ele para que os aplicativos continuem a ter acesso aos dados.
Ao usar esse tipo de configuração, não podemos reconstruir nosso cluster a partir de um backup anterior. Como o escravo assíncrono agora é a nova fonte de verdade, precisamos reconstruir o cluster a partir dele.
Isso não significa que temos apenas uma maneira de fazer isso, talvez haja uma maneira melhor! Sinta-se à vontade para nos dar suas sugestões na seção de comentários no final deste post.
Topologia
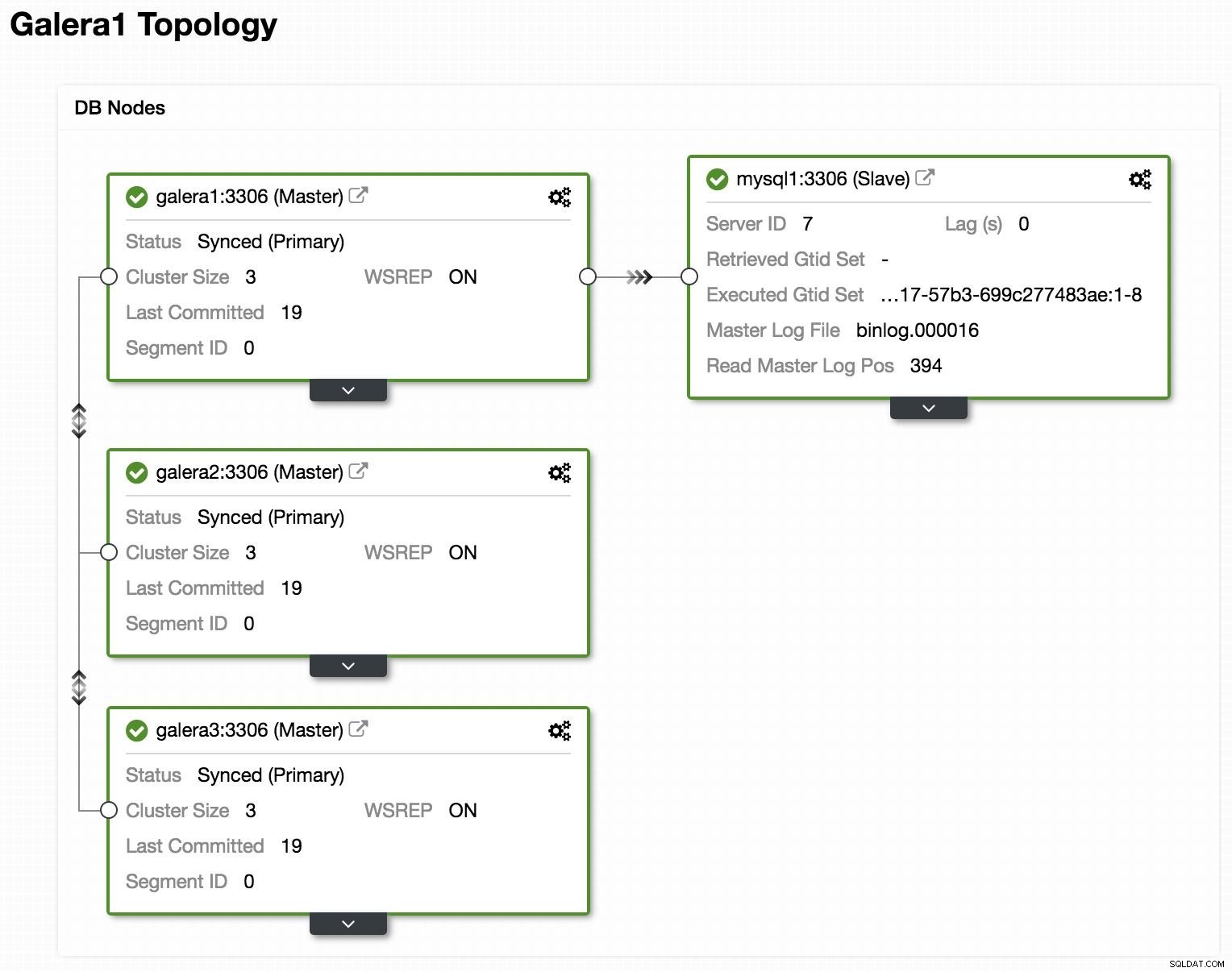 Visualização on-line da topologia do ClusterControl
Visualização on-line da topologia do ClusterControl Acima, podemos ver um exemplo de topologia com Galera Cluster e uma réplica/escravo assíncrona.
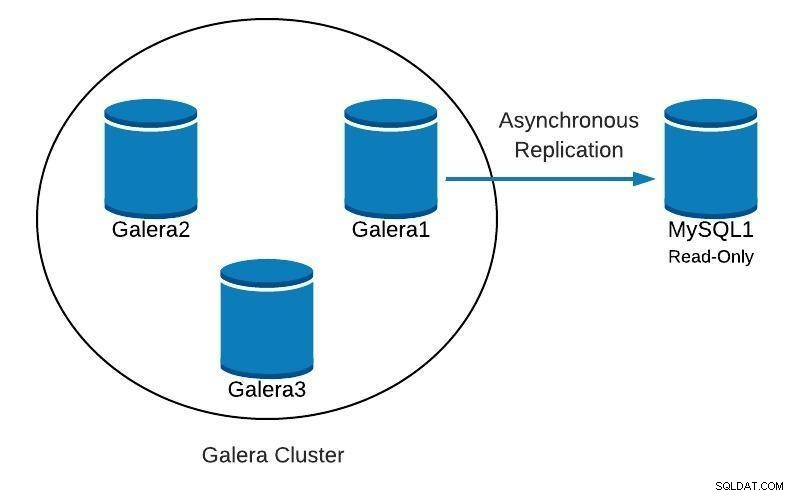 Diagrama de banco de dados 1
Diagrama de banco de dados 1 A seguir veremos como podemos recriar nosso cluster, a partir do slave, caso encontremos algo assim:
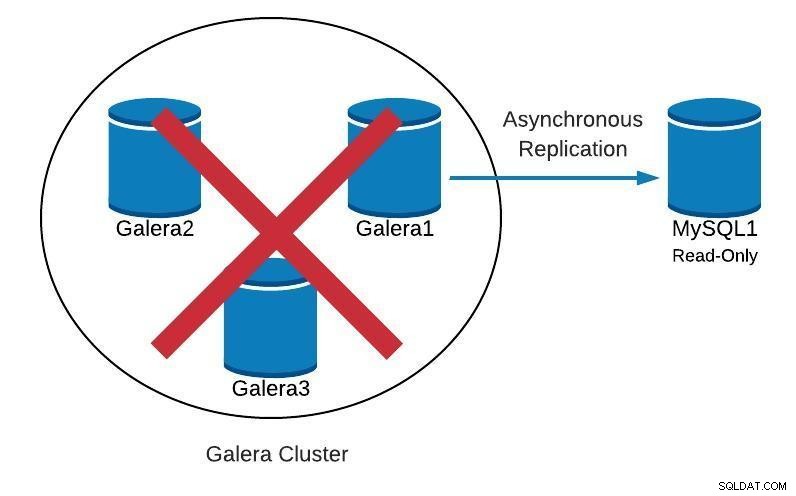 Diagrama de banco de dados 2
Diagrama de banco de dados 2 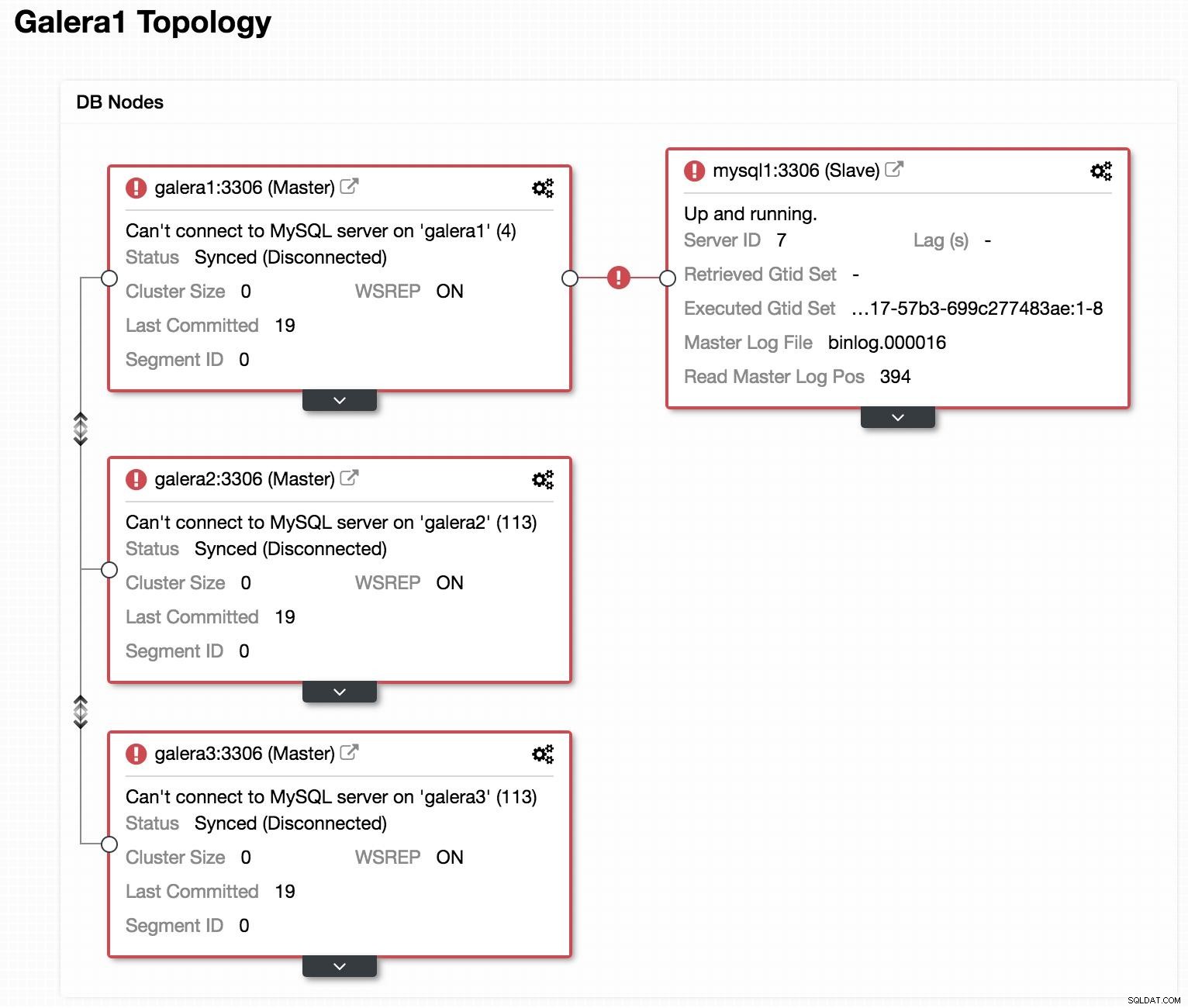 Visualização off-line da topologia do ClusterControl
Visualização off-line da topologia do ClusterControl Se olharmos para a imagem anterior, podemos ver que nossos 3 nós Galera estão inativos. Nosso slave não consegue se conectar ao Galera master, mas está no estado "Up and running".
Promover escravo
Como nosso slave está funcionando corretamente, podemos promovê-lo para master e apontar nossas aplicações para ele. Para isso, devemos desabilitar o parâmetro read-only em nosso slave e resetar a configuração do slave.
Em nosso escravo (mysql1):
mysql> SET GLOBAL read_only=0;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> RESET SLAVE;
Query OK, 0 rows affected (0.18 sec)Criar novo cluster
Em seguida, para iniciar a recuperação do nosso cluster com falha, criaremos um novo Galera Cluster. Isso pode ser feito facilmente através do ClusterControl ClusterControl, role mais para baixo neste blog para ver como.
Depois de implantar nosso novo cluster Galera, teríamos algo como o seguinte:
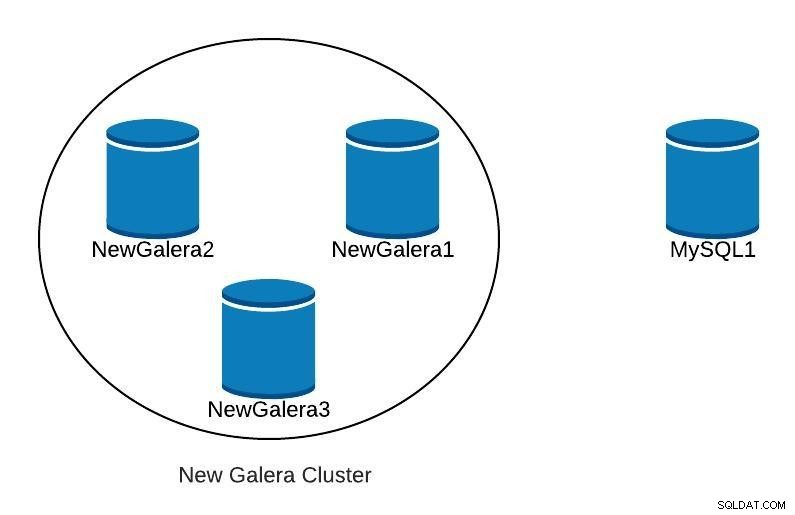 Diagrama de banco de dados 3
Diagrama de banco de dados 3 Replicação
Devemos garantir que temos os parâmetros de replicação configurados.
Para nós Galera (galera1, galera2, galera3):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-bin
expire_logs_days = 7Para o nó mestre (mysql1):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
sync_binlog=1
report_host=<HOSTNAME or IP> # Local serverPara que nosso novo slave (galera1) se conecte com nosso novo master (mysql1), devemos criar um usuário com permissões de replicação em nosso master.
Em nosso novo mestre (mysql1):
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'slave_password';Obs:Podemos substituir o "%" pelo IP do nó Galera Cluster que será nosso slave, em nosso exemplo, galera1.
Backup
Caso não tenhamos, devemos criar um backup consistente do nosso master (mysql1) e carregá-lo em nosso novo Galera Cluster. Para isso, podemos usar a ferramenta XtraBackup ou mysqldump. Vamos ver as duas opções.
Em nosso exemplo usamos o banco de dados sakila disponível para teste.
Ferramenta XtraBackup
Geramos o backup no novo mestre (mysql1). No nosso caso, enviamos para o diretório local /root/backup:
$ innobackupex /root/backup/Devemos receber a mensagem:
180705 22:08:14 completed OK!Compactamos o backup e enviamos para o nó que será nosso escravo (galera1):
$ cd /root/backup
$ tar zcvf 2018-07-05_22-08-07.tar.gz 2018-07-05_22-08-07
$ scp /root/backup/2018-07-05_22-08-07.tar.gz galera1:/root/backup/Na galera1, extraia o backup:
$ tar zxvf /root/backup/2018-07-05_22-08-07.tar.gzParamos o cluster (se for iniciado). Para isso paramos os serviços mysql dos 3 nós:
$ service mysql stopNa galera1, renomeamos o diretório de dados do mysql e carregamos o backup:
$ mv /var/lib/mysql /var/lib/mysql.bak
$ innobackupex --copy-back /root/backup/2018-07-05_22-08-07Devemos receber a mensagem:
180705 23:00:01 completed OK!Atribuímos as permissões corretas no diretório de dados:
$ chown -R mysql.mysql /var/lib/mysqlEntão devemos inicializar o cluster.
Uma vez inicializado o primeiro nó, devemos iniciar o serviço MySQL para os demais nós, eliminando qualquer cópia anterior do arquivo grastate.dat, e então verificar se nossos dados estão atualizados.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startObservação:verifique se o usuário usado pelo XtraBackup foi criado em nosso nó inicializado e é o mesmo em cada nó.
mysqldump
Em geral, não recomendamos fazê-lo com mysqldump, pois pode ser bastante lento com um grande volume de dados. Mas é uma alternativa para realizar a tarefa.
Geramos o backup no novo mestre (mysql1):
$ mysqldump -uroot -p --single-transaction --skip-add-locks --triggers --routines --events --databases sakila > /root/backup/sakila_dump.sqlNós o compactamos e enviamos para nosso nó escravo (galera1):
$ gzip /root/backup/sakila_dump.sql
$ scp /root/backup/sakila_dump.sql.gz galera1:/root/backup/Carregamos o dump na galera1.
$ gunzip /root/backup/sakila_dump.sql.gz
$ mysql -p < /root/backup/sakila_dump.sqlQuando o dump é carregado no galera1, devemos reiniciar o serviço MySQL nos nós restantes, removendo o arquivo grastate.dat, e verificar se temos nossos dados atualizados.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startIniciar Escravo de Replicação
Independente de qual opção escolhermos, XtraBackup ou mysqldump, se tudo deu certo, nesta etapa já podemos ativar a replicação no nó que será nosso slave (galera1).
$ mysql> CHANGE MASTER TO MASTER_HOST = 'mysql1', MASTER_PORT = 3306, MASTER_USER = 'slave_user', MASTER_PASSWORD = 'slave_password', MASTER_AUTO_POSITION = 1;
$ mysql> START SLAVE;Verificamos se o escravo está funcionando:
mysql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: YesNeste ponto, temos algo como o seguinte:
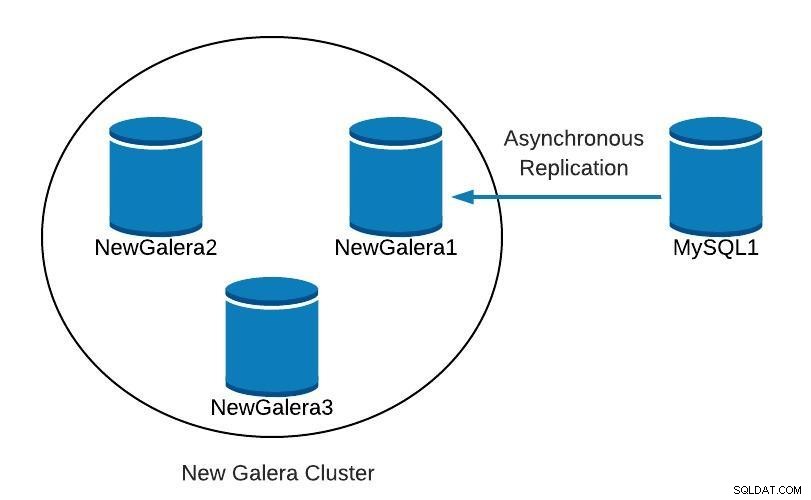 Diagrama de banco de dados 4
Diagrama de banco de dados 4 Depois que o NewGalera1 estiver atualizado, podemos redirecionar o aplicativo para nosso novo cluster galera e reconfigurar a replicação assíncrona.
Controle de cluster
Como mencionamos anteriormente, com o ClusterControl podemos realizar várias das tarefas mencionadas acima em apenas alguns cliques. Ele também possui opções de recuperação automática, tanto para os nós quanto para o cluster. Vamos ver algumas tarefas que ele pode ajudar.
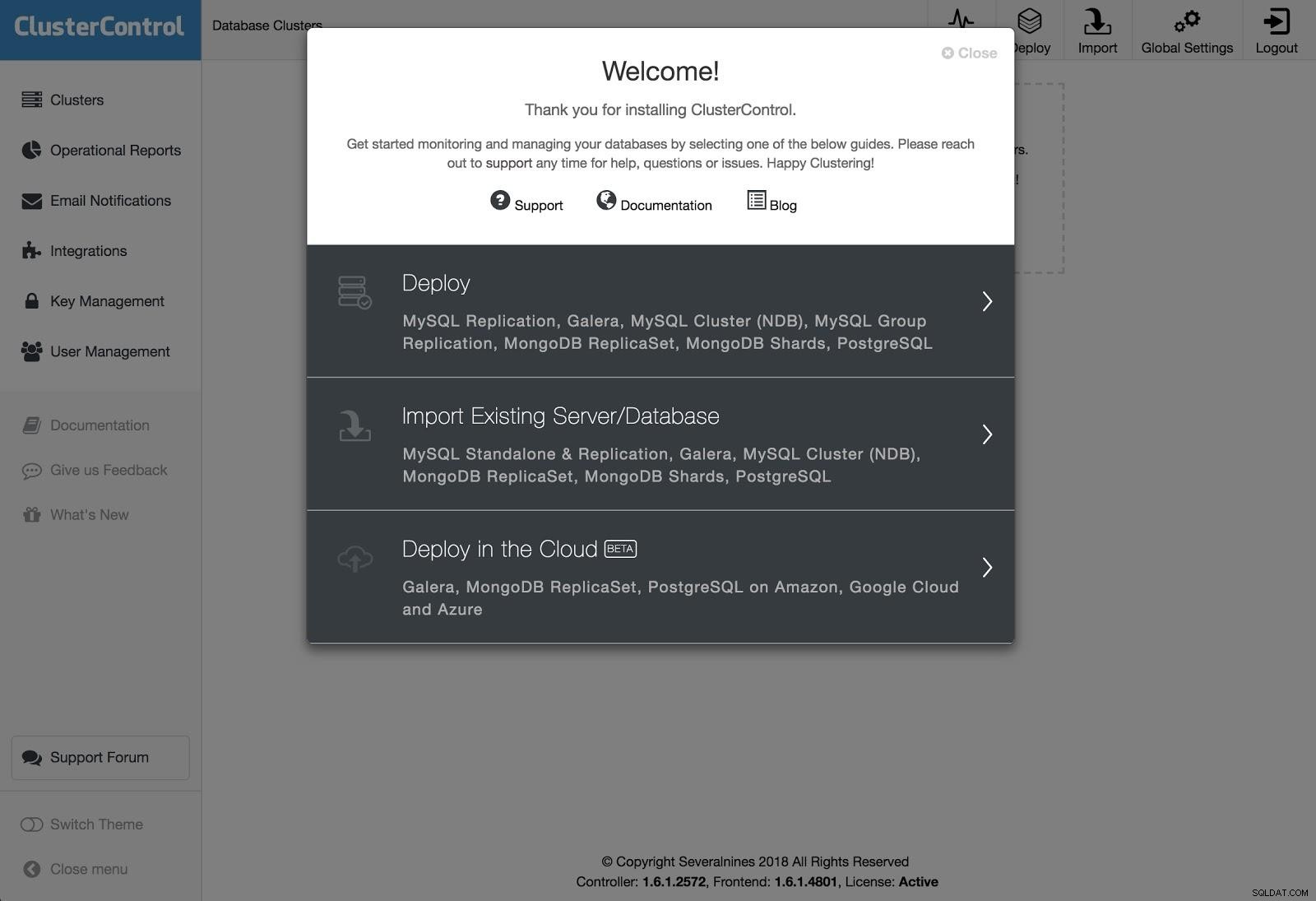 ClusterControl Deployment 1
ClusterControl Deployment 1 Para realizar uma implantação, basta selecionar a opção “Deploy Database Cluster” e seguir as instruções que aparecem.
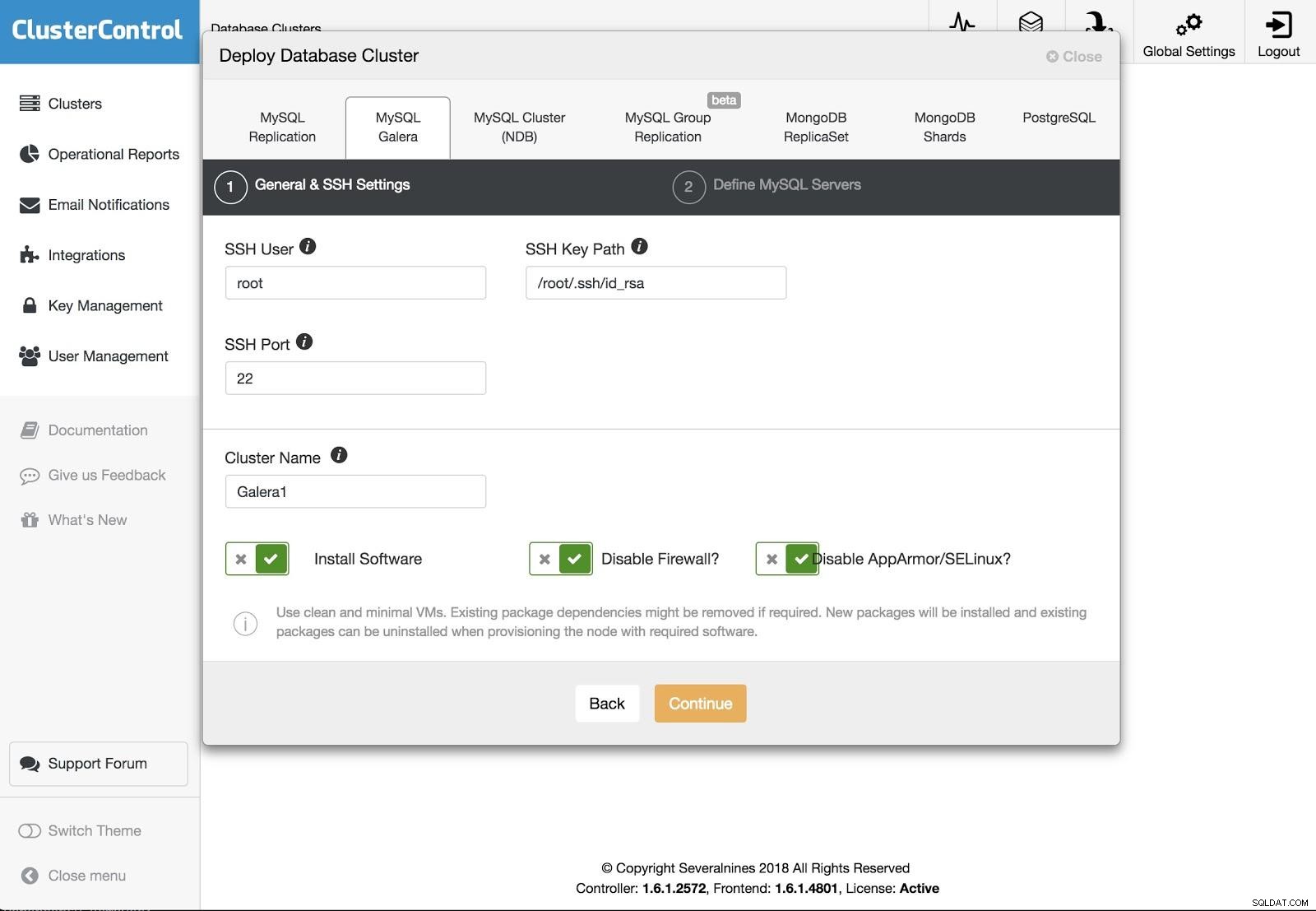 ClusterControl Deployment 2
ClusterControl Deployment 2 Podemos escolher entre diferentes tipos de tecnologias e fornecedores. Devemos especificar Usuário, Chave ou Senha e porta para conectar por SSH aos nossos servidores. Também precisamos do nome do nosso novo cluster e se queremos que o ClusterControl instale o software e as configurações correspondentes para nós.
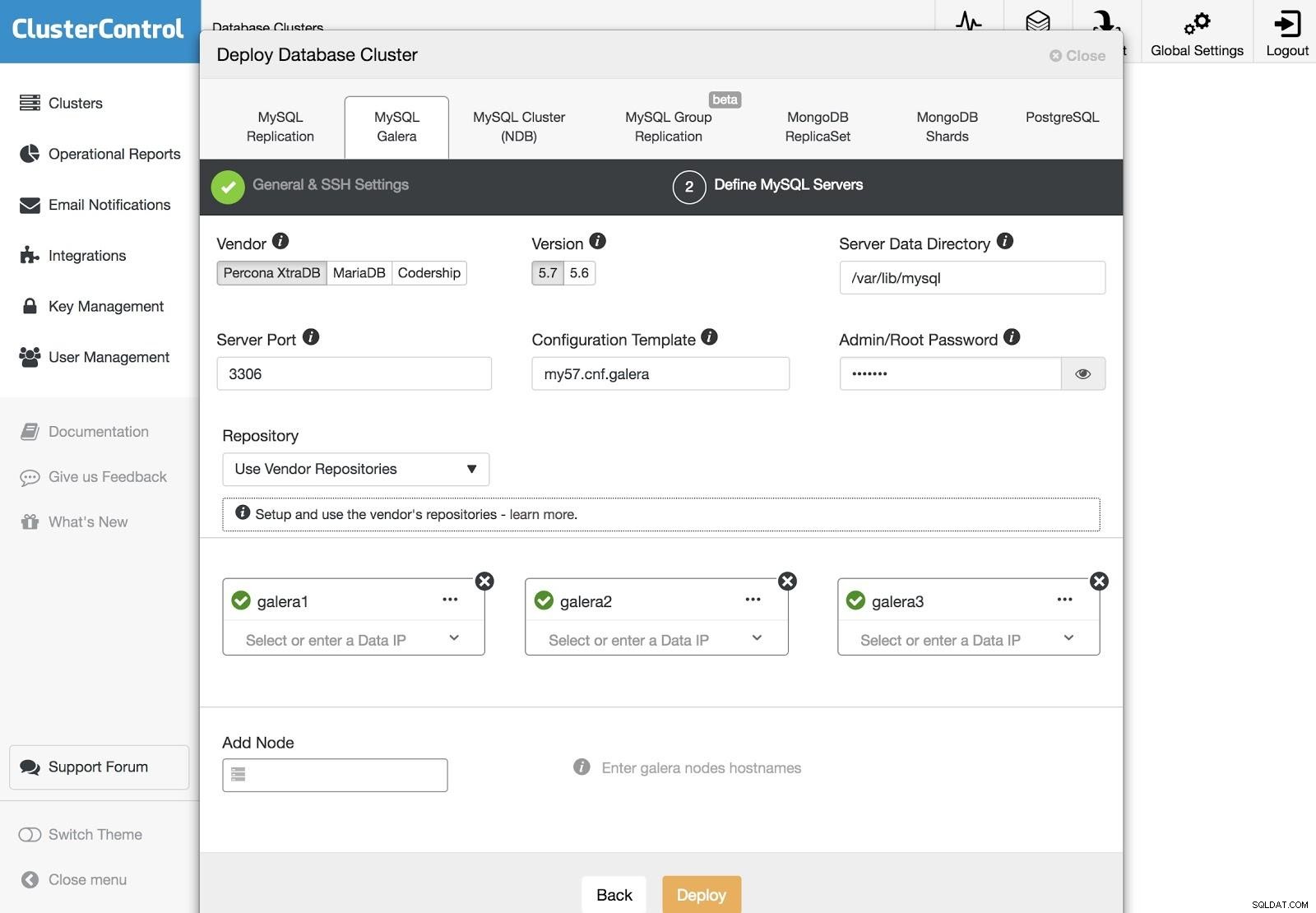 ClusterControl Deployment 3
ClusterControl Deployment 3 Após configurar as informações de acesso SSH, devemos definir os nós em nosso cluster. Também podemos especificar qual repositório usar. Precisamos adicionar nossos servidores ao cluster que vamos criar.
Podemos monitorar o status da criação do nosso novo cluster a partir do monitor de atividades do ClusterControl.
Além disso, podemos fazer uma importação do nosso cluster ou banco de dados atual seguindo as mesmas etapas. Nesse caso, o ClusterControl não instalará o software de banco de dados, pois já existe um banco de dados em execução.
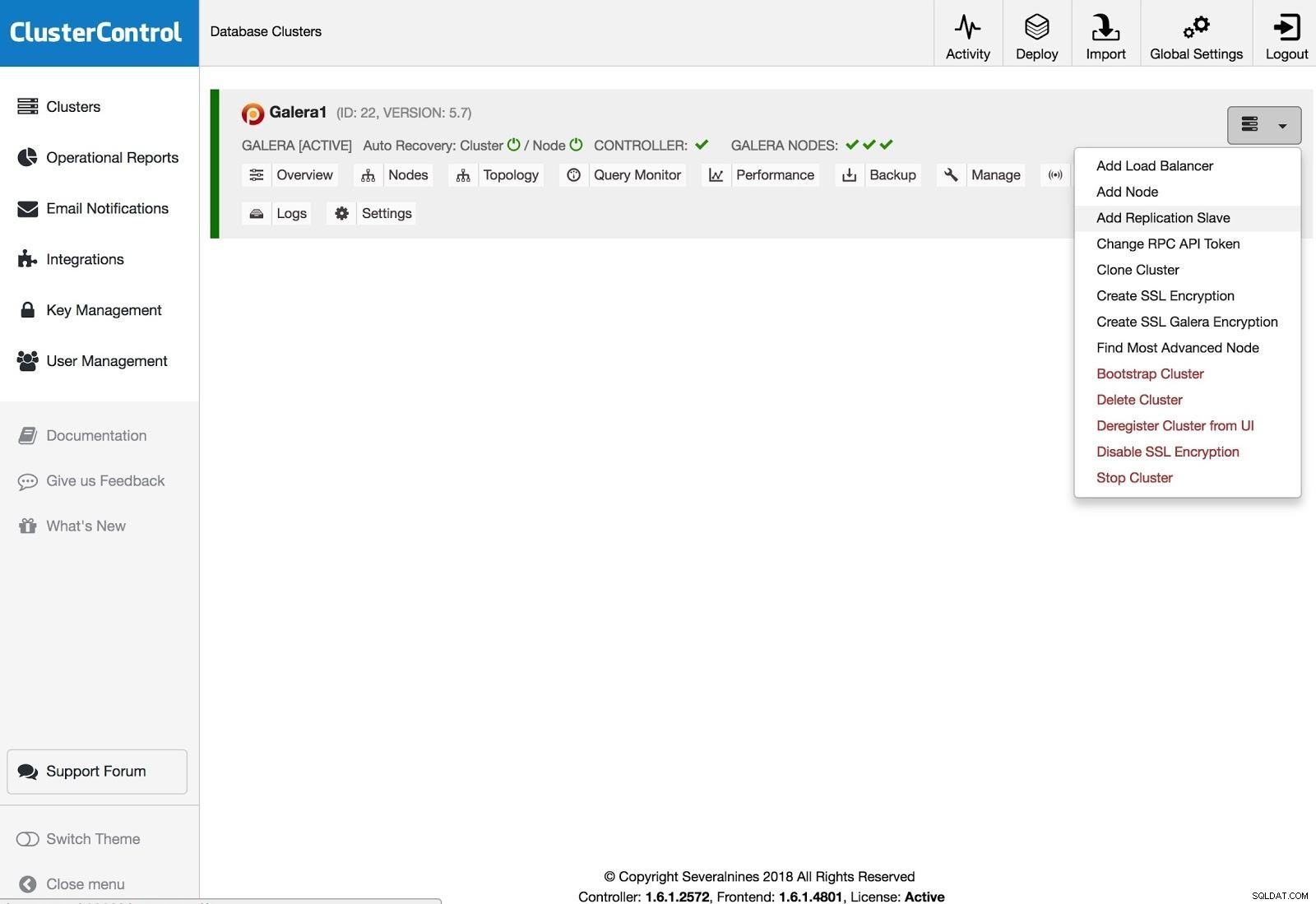 ClusterControl Adicionar salvamento de replicação
ClusterControl Adicionar salvamento de replicação Para adicionar um slave de replicação, você precisa clicar em Cluster Actions, selecionar Add Replication Slave e adicionar as informações de acesso SSH do novo servidor. O ClusterControl se conectará ao servidor para fazer as configurações necessárias para esta ação.
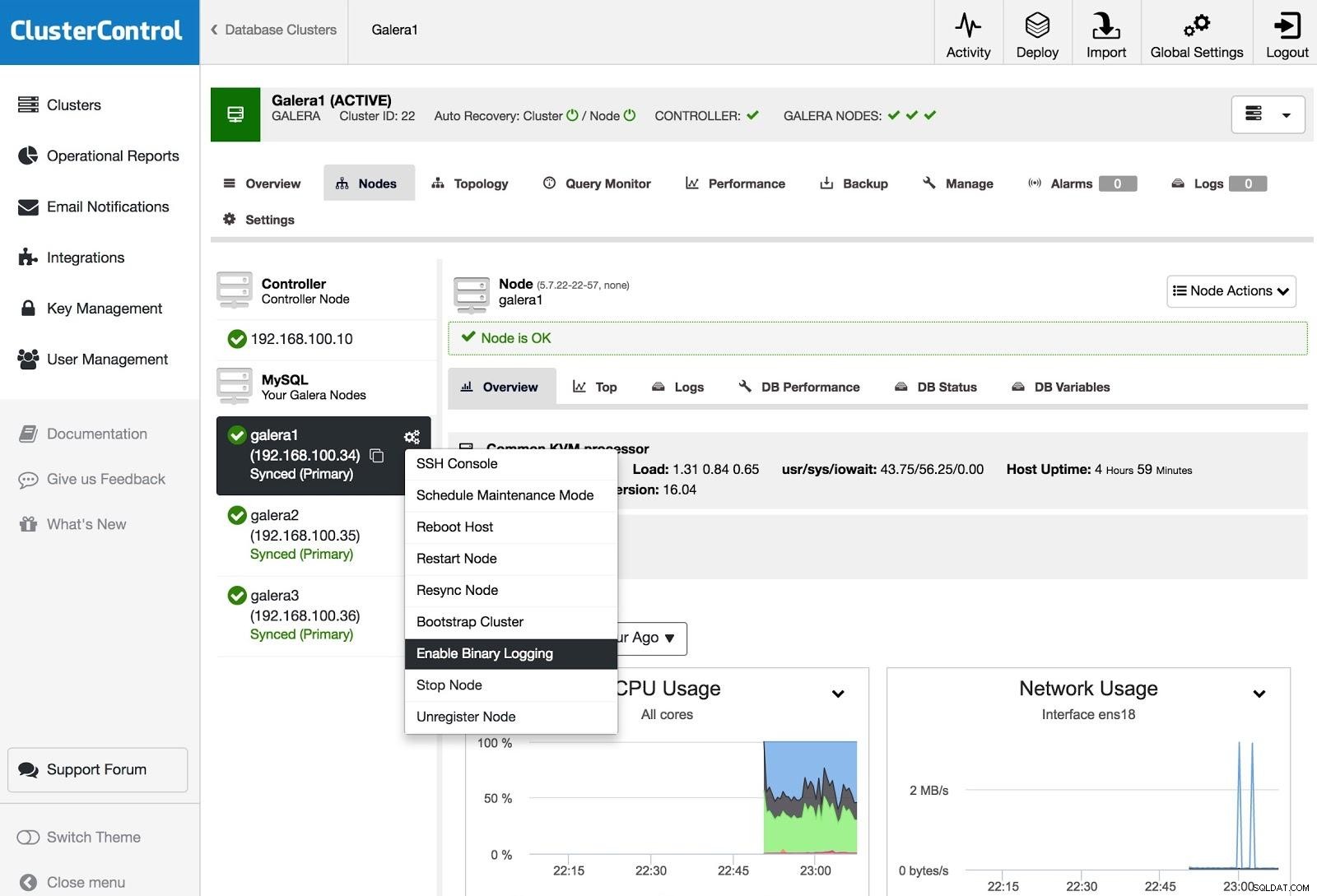 ClusterControl Habilitar log binário
ClusterControl Habilitar log binário Para transformar um ou mais nós Galera em servidores mestres (como no sentido de produzir logs binários), você pode ir para Ações do nó e selecionar Habilitar log binário.
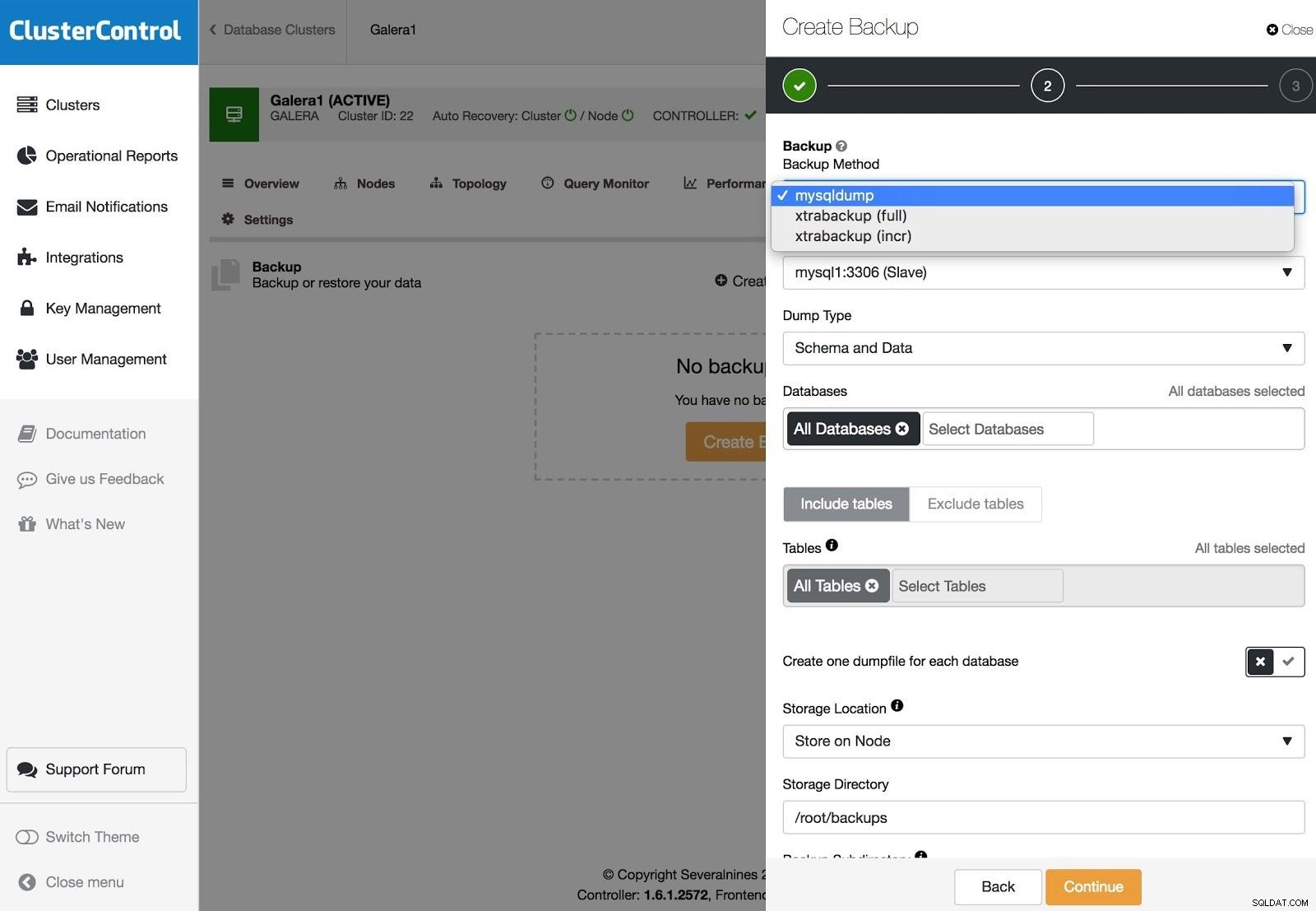 Backups do ClusterControl
Backups do ClusterControl Os backups podem ser configurados com XtraBackup (completo ou incremental) e mysqldump, e você tem outras opções como upload do backup para a nuvem, criptografia, compactação, agendamento e muito mais.
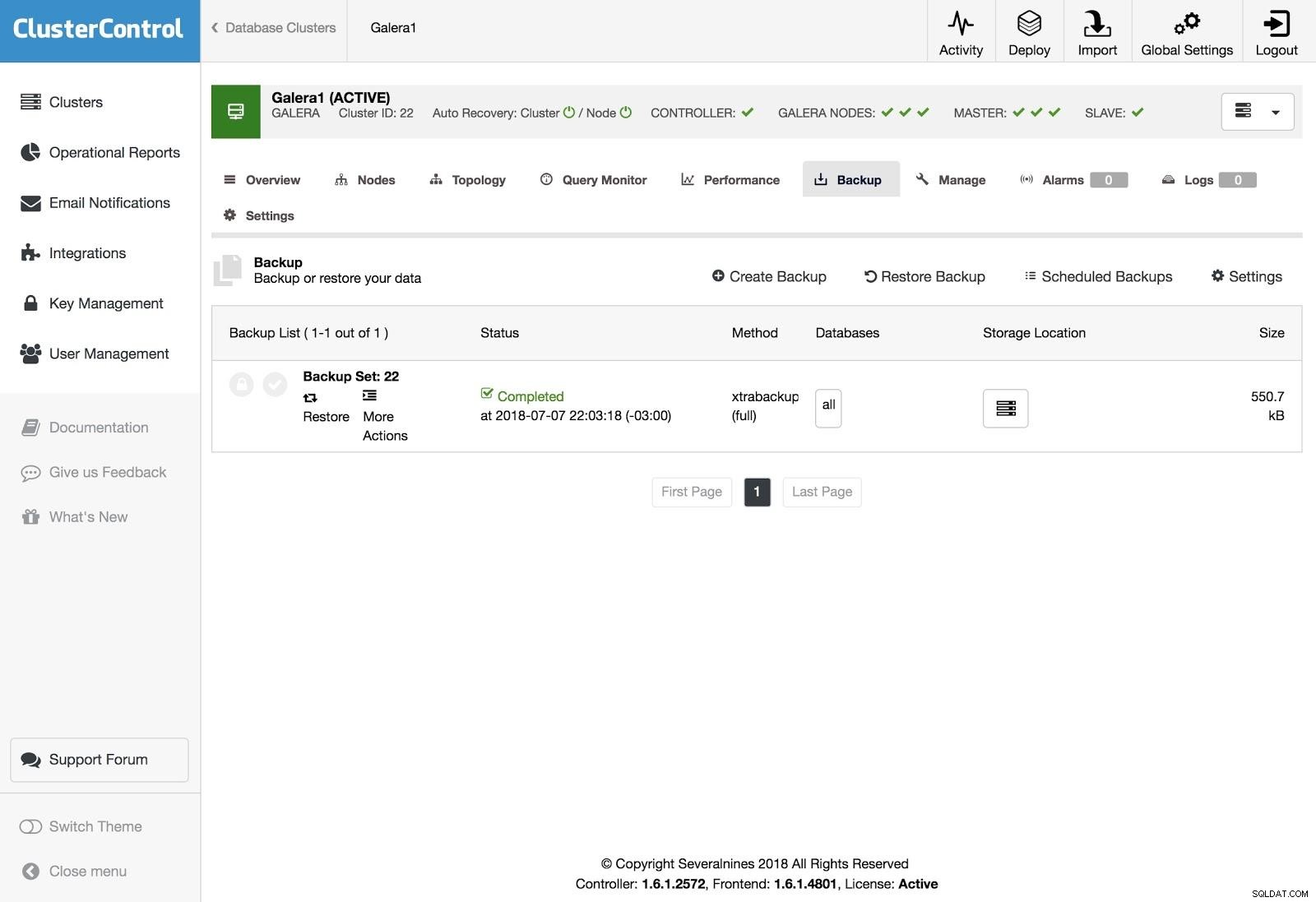 Restauração de controle de cluster
Restauração de controle de cluster Para restaurar o backup, vá para a guia Backup e escolha a opção Restaurar, depois selecione em qual servidor deseja restaurar.
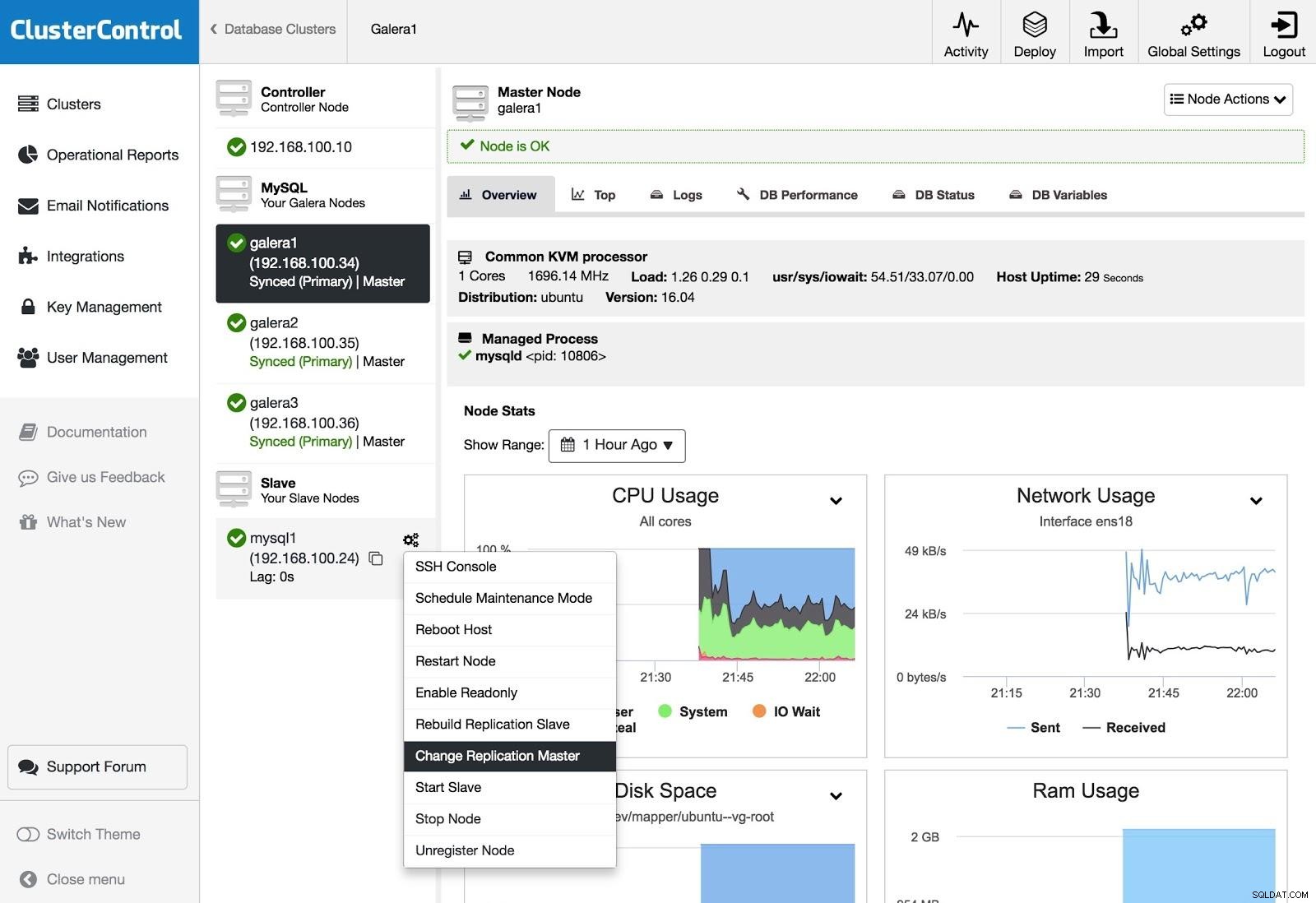 Mestre de replicação de alteração de ClusterControl
Mestre de replicação de alteração de ClusterControl Se você possui um escravo e deseja alterar o mestre ou reconstruir a replicação, pode acessar as Ações do nó e selecionar a opção.
Conclusão
Como pudemos ver, temos várias maneiras de atingir nosso objetivo, algumas mais complexas, outras mais amigáveis, mas com qualquer uma delas você pode recriar um cluster a partir de um escravo assíncrono. O Xtrabackup restauraria mais rapidamente para volumes de dados maiores. Para se proteger contra erros do operador (por exemplo, um DROP TABLE errôneo), você também pode usar um escravo atrasado para que tenha tempo de impedir a propagação da instrução.
Esperamos que esta informação seja útil e que você nunca precise usá-la em produção;)