Felizmente, isso geralmente não significa isso.
A variável ausente em sua equação é como seu banco de dados e seu servidor de aplicativos e qualquer outra coisa em sua pilha lida com simultaneidade .
Para ilustrar isso estritamente da perspectiva do MySQL, escrevi um programa cliente de teste que estabelece um número fixo de conexões com o servidor MySQL, cada uma em seu próprio thread (e, portanto, capaz de emitir uma consulta ao servidor aproximadamente ao mesmo tempo) .
Uma vez que todos os threads tenham sinalizado de volta que estão conectados, uma mensagem é enviada a todos eles ao mesmo tempo, para enviar sua consulta.
Quando cada thread recebe o sinal "go", ele verifica a hora atual do sistema e envia a consulta ao servidor. Quando obtém a resposta, ele verifica a hora do sistema novamente e envia todas as informações de volta ao thread principal, que compara os horários e gera a saída abaixo.
O programa é escrito de forma que não conte o tempo necessário para estabelecer as conexões com o servidor, pois em uma aplicação bem comportada as conexões seriam reutilizáveis.
A consulta foi
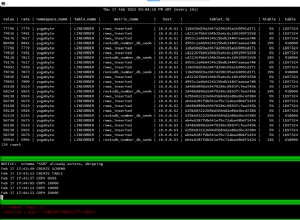
SELECT SQL_NO_CACHE COUNT(1) FROM ... (uma tabela InnoDB com cerca de 500 linhas). threads 1 min 0.001089 max 0.001089 avg 0.001089 total runtime 0.001089
threads 2 min 0.001200 max 0.002951 avg 0.002076 total runtime 0.003106
threads 4 min 0.000987 max 0.001432 avg 0.001176 total runtime 0.001677
threads 8 min 0.001110 max 0.002789 avg 0.001894 total runtime 0.003796
threads 16 min 0.001222 max 0.005142 avg 0.002707 total runtime 0.005591
threads 32 min 0.001187 max 0.010924 avg 0.003786 total runtime 0.014812
threads 64 min 0.001209 max 0.014941 avg 0.005586 total runtime 0.019841
Os tempos estão em segundos. O min/max/avg são os melhores/piores/médios tempos observados executando a mesma consulta. Em uma simultaneidade de 64, você percebe que o melhor caso não era tão diferente do melhor caso com apenas 1 consulta. Mas a maior vantagem aqui é a coluna de tempo de execução total. Esse valor é a diferença de tempo de quando o primeiro thread enviou sua consulta (todos enviam sua consulta essencialmente ao mesmo tempo, mas "precisamente" ao mesmo tempo é impossível, pois não tenho uma máquina de 64 núcleos para executar o test script on) até quando o último thread recebeu sua resposta.
Observações:a boa notícia é que as 64 consultas com uma média de 0,005586 segundos definitivamente não precisaram de 64 * 0,005586 segundos =0,357504 segundos para serem executadas... dessas consultas foram iniciadas e concluídas em 0,019841 segundos... ou apenas cerca de 28,5% do tempo que teoricamente levaria para serem executadas uma após a outra.
A má notícia, é claro, é que o tempo médio de execução dessa consulta em uma simultaneidade de 64 é mais de 5 vezes maior do que o tempo em que ela é executada apenas uma vez... e o pior caso é quase 14 vezes maior. Mas isso ainda é muito melhor do que uma extrapolação linear do tempo de execução de consulta única sugeriria.
As coisas não escalam indefinidamente, no entanto. Como você pode ver, o desempenho se deteriora com a simultaneidade e, em algum momento, cairia - provavelmente rapidamente - quando atingimos o gargalo que ocorresse primeiro. O número de tabelas, a natureza das consultas, qualquer bloqueio encontrado, tudo contribui para o desempenho do servidor sob cargas simultâneas, assim como o desempenho do armazenamento, o tamanho, o desempenho e a arquitetura da memória do sistema e os internos do MySQL -- alguns dos quais podem ser ajustados e outros não.
Mas é claro que o banco de dados não é o único fator. A maneira como o servidor de aplicativos lida com solicitações simultâneas pode ser outra grande parte de seu desempenho sob carga, às vezes em maior extensão do que o banco de dados e às vezes menos.
Uma grande incógnita de seus benchmarks é quanto desse tempo é gasto pelo banco de dados respondendo às consultas, quanto tempo é gasto pelo servidor de aplicativos executando o negócio lógico e quanto tempo é gasto pelo código que é renderizando os resultados da página em HTML.