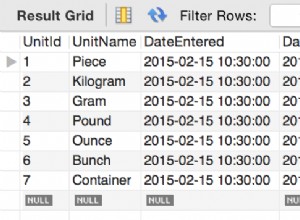
A execução da consulta pode ignorar o
ORDER BY no FROM ( SELECT ... ) . Esta provavelmente a verdadeira razão para a diferença que você está vendo. (Eu não acho que a resposta de Gordon seja relevante.) O problema é discutido aqui (4 anos atrás):https://mariadb.com/kb/en/mariadb/group-by-trick-has-been-optimized-away/ ; que tem uma solução, por meio de uma configuração.
Algumas outras soluções estão aqui:https://mysql.rjweb.org/doc.php/groupwise_max ; eles são projetados para serem eficientes.
Mais um possível solução é adicionar um falso
LIMIT com um número grande na subconsulta.