As funções OVER e PARTITION BY são ambas funções usadas para porcionar um conjunto de resultados de acordo com critérios especificados.
Este artigo explica como essas duas funções podem ser usadas em conjunto para recuperar dados particionados de maneiras muito específicas.
Preparando alguns dados de amostra
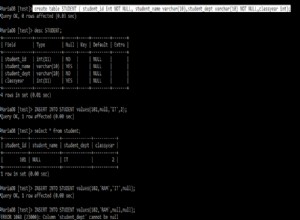
Para executar nossas consultas de exemplo, vamos primeiro criar um banco de dados chamado “studentdb”.
Execute o seguinte comando na janela de consulta:
CRIAR BANCO DE DADOS schooldb;
Em seguida, precisamos criar a tabela “student” dentro do banco de dados “studentdb”. A tabela de alunos terá cinco colunas:id, name, age, gender e total_score.
Como sempre, certifique-se de ter um backup completo antes de experimentar um novo código. Consulte este artigo sobre como fazer backup de bancos de dados do SQL Server se não tiver certeza.
Execute a consulta a seguir para criar a tabela de alunos.
USE schooldbCREATE TABLE aluno( id INT PRIMARY KEY IDENTITY, nome VARCHAR(50) NOT NULL, gênero VARCHAR(50) NOT NULL, idade INT NOT NULL, total_score INT NOT NULL, )
Finalmente, precisamos inserir alguns dados fictícios para trabalharmos no banco de dados.
USE schooldbINSERT INTO student VALUES ('Jolly', 'Female', 20, 500), ('Jon', 'Masculino', 22, 545), ('Sara', 'Female', 25, 600), ('Laura', 'Feminino', 18, 400), ('Alan', 'Masculino', 20, 500), ('Kate', 'Feminino', 22, 500), ('Joseph', 'Masculino' , 18, 643), ('Mice', 'Male', 23, 543), ('Wise', 'Male', 21, 499), ('Elis', 'Female', 27, 400);
Certo, agora estamos prontos para trabalhar em um problema e ver quem podemos usar Over e Partition By para resolvê-lo.
Problema
Temos 10 registros na tabela de alunos e queremos exibir o nome, id e sexo de todos os alunos, além disso também queremos exibir o número total de alunos que pertencem a cada sexo, a idade média do alunos de cada sexo e a soma dos valores na coluna total_score para cada sexo.
O conjunto de resultados que estamos procurando é o seguinte:
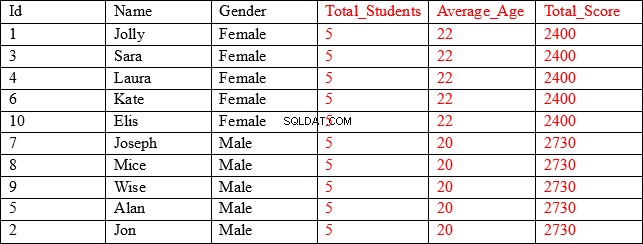
Como você pode ver, as três primeiras colunas (mostradas em preto) contêm valores individuais para cada registro, enquanto as três últimas colunas (mostradas em vermelho) contêm valores agregados agrupados pela coluna de gênero. Por exemplo, na coluna Average_Age, as primeiras cinco linhas exibem a idade média e a pontuação total de todos os registros em que o gênero é Feminino.
Nosso conjunto de resultados contém resultados agregados unidos a colunas não agregadas.
Para recuperar os resultados agregados, agrupados por uma coluna específica, podemos usar a cláusula GROUP BY como de costume.
USE schooldbSELECT sexo, contagem(gênero) AS Total_Students, AVG(idade) como Average_Age, SUM(total_score) como Total_ScoreFROM studentGROUP BY sexo
Vamos ver como podemos recuperar Total_Students, Average_Age e Total_Score dos alunos agrupados por sexo.
Você verá os seguintes resultados:

Agora vamos estender isso e adicionar 'id' e 'name' (as colunas não agregadas na instrução SELECT) e ver se podemos obter o resultado desejado.
USE schooldbSELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Ao executar a consulta acima, você verá um erro:

O erro diz que a coluna id da tabela do aluno é inválida dentro da instrução SELECT, pois estamos usando a cláusula GROUP BY na consulta.
Isso significa que teremos que aplicar uma função agregada na coluna id ou teremos que usá-la na cláusula GROUP BY. Em suma, este esquema não resolve o nosso problema.
Solução usando declaração JOIN
Uma solução para isso seria usar a instrução JOIN para unir as colunas com resultados agregados a colunas contendo resultados não agregados.
Para isso, você precisa de uma subconsulta que recupere o gênero, Total_Students, Average_Age e o Total_Score dos alunos agrupados por gênero. Esses resultados podem então ser unidos aos resultados obtidos da subconsulta com a instrução SELECT externa. Isso será aplicado à coluna de gênero da subconsulta que contém o resultado agregado e à coluna de gênero da tabela do aluno. A instrução SELECT externa incluiria colunas não agregadas, ou seja, 'id' e 'name', conforme abaixo.
USE schooldbSELECT id, nome, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_ScoreFROM studentGROUP BY gender) AS Aggregationon Aggregation.gender =student.gender
A consulta acima fornecerá o resultado desejado, mas não é a solução ideal. Tivemos que usar uma instrução JOIN e uma subconsulta que aumenta a complexidade do script. Esta não é uma solução elegante ou eficiente.
Uma abordagem melhor é usar as cláusulas OVER e PARTITION BY em conjunto.
Solução usando OVER e PARTITION BY
Para usar as cláusulas OVER e PARTITION BY, basta especificar a coluna pela qual deseja particionar seus resultados agregados. Isso é melhor explicado com o uso de um exemplo.
Vamos dar uma olhada em como alcançar nosso resultado usando OVER e PARTITION BY.
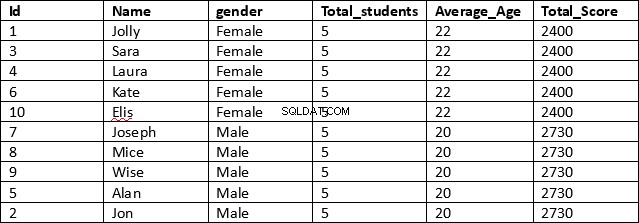
USE schooldbSELECT id, nome, sexo,COUNT(gender) OVER (PARTITION BY gender) AS Total_students,AVG(age) OVER (PARTITION BY gender) AS Average_Age,SUM(total_score) OVER (PARTITION BY gender) AS Total_ScoreFROM aluno
Este é um resultado muito mais eficiente. Na primeira linha do script, as colunas id, name e gender são recuperadas. Essas colunas não contêm resultados agregados.
Em seguida, para as colunas que contêm resultados agregados, simplesmente especificamos a função agregada, seguida da cláusula OVER e, dentro dos parênteses, especificamos a cláusula PARTITION BY seguida do nome da coluna que queremos que nossos resultados sejam particionados, conforme mostrado abaixo de.
Referências
- Microsoft – Entendendo a cláusula OVER
- Midnight DBA – Introdução a OVER e PARTITION BY
- StackOverflow – Diferença entre PARTITION BY e GROUP BY