O MySQL tem problemas conhecidos com a otimização de consultas envolvendo subconsultas correlacionadas ou subseleções. Até a versão 5.6.5 não materializa subconsultas, porém materializará uma tabela derivada utilizada em uma junção.
Em essência, isso significa que, quando você usa uma junção, na primeira vez que a subconsulta é encontrada, o MySQL executará o seguinte:
SELECT code1 FROM myTable GROUP BY code1 HAVING COUNT(code1) > 1
E mantenha os resultados em uma tabela temporária (que é hash para tornar as pesquisas mais rápidas) e, em seguida, para cada valor em
myTable ele pesquisará na tabela temporária para ver se o código está lá. No entanto, desde quando você usa
IN a subconsulta não é materializada e é reescrita como:SELECT t1.code1, t1.code2
FROM myTable t1
WHERE EXISTS
( SELECT t2.code1
FROM myTable t2
WHERE t2.Code1 = t1.Code1
GROUP BY t2.code1
HAVING COUNT(t2.code1) > 1
)
O que significa que para cada
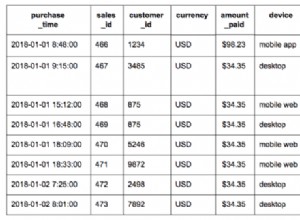
code em myTable , ele executa a subconsulta novamente. O que quando sua consulta externa é muito estreita é bom, pois é mais eficiente executar apenas a subconsulta algumas vezes, do que executá-la para todos os valores e armazenar os resultados em uma tabela temporária, no entanto, quando sua consulta externa é ampla, resulta na consulta interna executando muitas vezes, e é aí que a diferença de desempenho entra em ação. Portanto, para sua contagem de linhas, em vez de executar a subconsulta ~ 30.000 vezes, você a executa uma vez e, em seguida, pesquisa ~ 30.000 linhas em uma tabela temporária com hash com apenas 400 linhas. Isso explicaria uma diferença de desempenho tão drástica.
Este artigo nos documentos on-line explica a otimização de subconsultas com muito mais profundidade.