Usando IN:
SELECT p.*
FROM POSTS p
WHERE p.id IN (SELECT tg.post_id
FROM TAGGINGS tg
JOIN TAGS t ON t.id = tg.tag_id
WHERE t.name IN ('Cheese','Wine','Paris','Frace','City','Scenic','Art')
GROUP BY tg.post_id
HAVING COUNT(DISTINCT t.name) = 7)
Usando um JOIN
SELECT p.*
FROM POSTS p
JOIN (SELECT tg.post_id
FROM TAGGINGS tg
JOIN TAGS t ON t.id = tg.tag_id
WHERE t.name IN ('Cheese','Wine','Paris','Frace','City','Scenic','Art')
GROUP BY tg.post_id
HAVING COUNT(DISTINCT t.name) = 7) x ON x.post_id = p.id
Usando EXISTS
SELECT p.*
FROM POSTS p
WHERE EXISTS (SELECT NULL
FROM TAGGINGS tg
JOIN TAGS t ON t.id = tg.tag_id
WHERE t.name IN ('Cheese','Wine','Paris','Frace','City','Scenic','Art')
AND tg.post_id = p.id
GROUP BY tg.post_id
HAVING COUNT(DISTINCT t.name) = 7)
Explicação
O cerne das coisas é que o
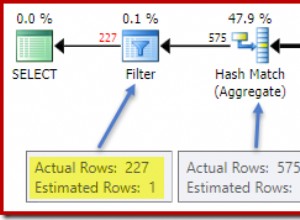
COUNT(DISTINCT t.name) precisa corresponder ao número de nomes de tags para garantir que todas essas tags estejam relacionadas à postagem. Sem o DISTINCT, existe o risco de que duplicatas de um dos nomes retornem uma contagem de 7, então você teria um falso positivo. Desempenho
A maioria dirá que o JOIN é ideal, mas os JOINs também correm o risco de duplicar linhas no conjunto de resultados. EXISTS seria minha próxima escolha - sem risco duplicado e execução geralmente mais rápida, mas verificar o plano de explicação acabará dizendo o que é melhor com base em sua configuração e dados.