Em qualquer um dos mecanismos de banco de dados relacional, é necessário gerar o melhor plano possível que corresponda à execução da consulta com o menor tempo e recursos. Geralmente, todos os bancos de dados geram planos em formato de estrutura de árvore, onde o nó folha de cada árvore de plano é chamado de nó de varredura de tabela. Este nó específico do plano corresponde ao algoritmo a ser usado para buscar dados da tabela base.
Por exemplo, considere um exemplo de consulta simples como SELECT * FROM TBL1, TBL2 onde TBL2.ID>1000; e suponha que o plano gerado seja o seguinte:
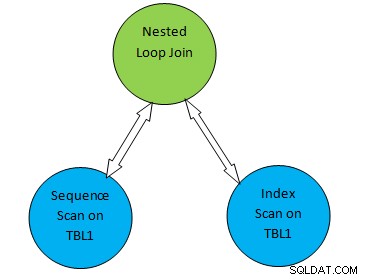
Assim, na árvore de planos acima, “Verificação Sequencial em TBL1” e “ Index Scan on TBL2” corresponde ao método de varredura de tabela na tabela TBL1 e TBL2, respectivamente. Portanto, de acordo com este plano, o TBL1 será buscado sequencialmente nas páginas correspondentes e o TBL2 pode ser acessado usando o INDEX Scan.
A escolha do método de verificação correto como parte do plano é muito importante em termos de desempenho geral da consulta.
Antes de entrar em todos os tipos de métodos de varredura suportados pelo PostgreSQL, vamos revisar alguns dos principais pontos-chave que serão usados com frequência ao longo do blog.
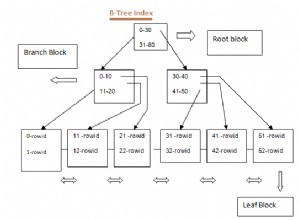
- HEAP: Área de armazenamento para armazenar toda a linha da tabela. Isso é dividido em várias páginas (como mostrado na imagem acima) e cada tamanho de página é, por padrão, 8 KB. Dentro de cada página, cada ponteiro de item (por exemplo, 1, 2, ….) aponta para dados dentro da página.
- Armazenamento de índice: Este armazenamento armazena apenas valores de chave, ou seja, valor de colunas contido por índice. Isso também é dividido em várias páginas e cada tamanho de página é, por padrão, 8 KB.
- Identificador de Tupla (TID): TID é um número de 6 bytes que consiste em duas partes. A primeira parte é o número da página de 4 bytes e o índice de tupla restante de 2 bytes dentro da página. A combinação desses dois números aponta exclusivamente para o local de armazenamento de uma tupla específica.
Atualmente, o PostgreSQL suporta os métodos de varredura abaixo pelos quais todos os dados necessários podem ser lidos da tabela:
- Verificação sequencial
- Verificação de índice
- Verificação somente de índice
- Verificação de bitmap
- TID Scan
Cada um desses métodos de varredura é igualmente útil dependendo da consulta e de outros parâmetros, por exemplo, cardinalidade da tabela, seletividade da tabela, custo de E/S de disco, custo de E/S aleatório, custo de E/S de sequência, etc. Vamos criar uma tabela pré-configurada e preencher com alguns dados, que serão usados com frequência para explicar melhor esses métodos de varredura .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEEntão, neste exemplo, um milhão de registros são inseridos e então a tabela é analisada para que todas as estatísticas estejam atualizadas.
Verificação Sequencial
Como o nome sugere, uma varredura sequencial de uma tabela é feita pela varredura sequencial de todos os ponteiros de item de todas as páginas das tabelas correspondentes. Portanto, se houver 100 páginas para uma tabela específica e, em seguida, houver 1.000 registros em cada página, como parte da varredura sequencial, ele buscará 100*1.000 registros e verificará se corresponde de acordo com o nível de isolamento e também de acordo com a cláusula de predicado. Portanto, mesmo que apenas 1 registro seja selecionado como parte de toda a varredura da tabela, ele terá que varrer 100 mil registros para encontrar um registro qualificado de acordo com a condição.
De acordo com a tabela e os dados acima, a consulta a seguir resultará em uma varredura sequencial, pois a maioria dos dados está sendo selecionada.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)NOTA
Embora sem calcular e comparar o custo do plano, é quase impossível dizer que tipo de varredura será usada. Mas, para que a varredura sequencial seja usada, pelo menos os critérios abaixo devem corresponder:
- Nenhum índice disponível na chave, que faz parte do predicado.
- A maioria das linhas está sendo buscada como parte da consulta SQL.
DICAS
Caso apenas % de linhas sejam buscadas e o predicado esteja em uma (ou mais) coluna, tente avaliar o desempenho com ou sem índice.
Verificação de índice
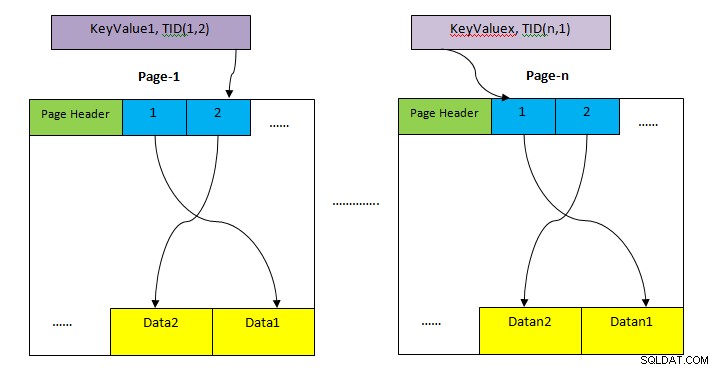
Ao contrário da Varredura Sequencial, a Varredura de Índice não busca todos os registros sequencialmente. Em vez disso, ele usa uma estrutura de dados diferente (dependendo do tipo de índice) correspondente ao índice envolvido na consulta e localiza a cláusula de dados necessários (conforme o predicado) com varreduras mínimas. Em seguida, a entrada encontrada usando a varredura de índice aponta diretamente para os dados na área de heap (como mostrado na figura acima), que é buscada para verificar a visibilidade de acordo com o nível de isolamento. Portanto, há duas etapas para a verificação de índice:
- Busca dados da estrutura de dados relacionada ao índice. Ele retorna o TID dos dados correspondentes no heap.
- Em seguida, a página de heap correspondente é acessada diretamente para obter dados completos. Esta etapa adicional é necessária pelos motivos abaixo:
- A consulta pode ter solicitado a busca de colunas mais do que o disponível no índice correspondente.
- As informações de visibilidade não são mantidas junto com os dados de índice. Portanto, para verificar a visibilidade dos dados de acordo com o nível de isolamento, ele precisa acessar os dados de heap.
Agora podemos nos perguntar por que nem sempre usar o Index Scan se ele é tão eficiente. Então, como sabemos, tudo vem com algum custo. Aqui o custo envolvido está relacionado ao tipo de E/S que estamos fazendo. No caso do Index Scan, Random I/O está envolvido, pois para cada registro encontrado no armazenamento de índice, ele deve buscar os dados correspondentes do armazenamento HEAP, enquanto no caso do Sequential Scan, o Sequence I/O está envolvido, o que leva aproximadamente apenas 25% de temporização de E/S aleatória.
Assim, a varredura de índice deve ser escolhida apenas se o ganho geral superar a sobrecarga incorrida devido ao custo de E/S aleatória.
De acordo com a tabela e os dados acima, a consulta a seguir resultará em uma verificação de índice, pois apenas um registro está sendo selecionado. Assim, a E/S aleatória é menor, assim como a busca do registro correspondente é rápida.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Verificação somente de índice
A varredura somente de índice é semelhante à varredura de índice, exceto pela segunda etapa, ou seja, como o nome indica, ela verifica apenas a estrutura de dados do índice. Há duas pré-condições adicionais para escolher Index Only Scan comparar com Index Scan:
- A consulta deve buscar apenas colunas-chave que fazem parte do índice.
- Todas as tuplas (registros) na página de heap selecionada devem estar visíveis. Conforme discutido na seção anterior, a estrutura de dados do índice não mantém as informações de visibilidade, portanto, para selecionar dados apenas do índice, devemos evitar verificar a visibilidade e isso pode acontecer se todos os dados dessa página forem considerados visíveis.
A consulta a seguir resultará em uma verificação apenas de índice. Mesmo que essa consulta seja quase semelhante em termos de seleção do número de registros, mas como apenas o campo-chave (ou seja, “num”) está sendo selecionado, ela escolherá Index Only Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Verificação de bitmap
A varredura de bitmap é uma mistura de varredura de índice e varredura seqüencial. Ele tenta resolver a desvantagem da varredura de índice, mas ainda mantém toda a sua vantagem. Conforme discutido acima, para cada dado encontrado na estrutura de dados do índice, ele precisa encontrar os dados correspondentes na página de heap. Então, alternativamente, ele precisa buscar a página de índice uma vez e depois seguida pela página de heap, o que causa muita E/S aleatória. Portanto, o método de varredura de bitmap aproveita o benefício da varredura de índice sem E/S aleatória. Isso funciona em dois níveis como abaixo:
- Varredura de índice de bitmap:primeiro ele busca todos os dados de índice da estrutura de dados de índice e cria um mapa de bits de todos os TIDs. Para uma compreensão simples, você pode considerar que este bitmap contém um hash de todas as páginas (com hash com base no número da página) e cada entrada de página contém uma matriz de todos os deslocamentos dessa página.
- Varredura de heap de bitmap:Como o nome indica, ele lê o bitmap de páginas e, em seguida, varre os dados do heap correspondente à página armazenada e ao deslocamento. No final, ele verifica a visibilidade e o predicado etc. e retorna a tupla com base no resultado de todas essas verificações.
A consulta abaixo resultará em varredura de bitmap, pois não está selecionando muito poucos registros (ou seja, muito para varredura de índice) e ao mesmo tempo não seleciona um grande número de registros (ou seja, muito pouco para uma varredura sequencial Varredura).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Agora considere a consulta abaixo, que seleciona o mesmo número de registros, mas apenas campos-chave (ou seja, apenas colunas de índice). Como ele seleciona apenas a chave, ele não precisa consultar páginas de heap para outras partes de dados e, portanto, não há E/S aleatória envolvida. Portanto, esta consulta irá escolher Index Only Scan em vez de Bitmap Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Verificação TID
TID, como mencionado acima, é um número de 6 bytes que consiste em um número de página de 4 bytes e um índice de tupla de 2 bytes restantes dentro da página. A varredura TID é um tipo muito específico de varredura no PostgreSQL e é selecionada apenas se houver TID no predicado da consulta. Considere a consulta abaixo demonstrando o TID Scan:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Então aqui no predicado, em vez de fornecer um valor exato da coluna como condição, o TID é fornecido. Isso é algo semelhante à pesquisa baseada em ROWID no Oracle.
Bônus
Todos os métodos de varredura são amplamente utilizados e famosos. Além disso, esses métodos de varredura estão disponíveis em quase todos os bancos de dados relacionais. Mas há outro método de varredura recentemente em discussão na comunidade PostgreSQL e também recentemente adicionado em outros bancos de dados relacionais. É chamado de “Loose IndexScan” no MySQL, “Index Skip Scan” no Oracle e “Jump Scan” no DB2.
Este método de varredura é usado para um cenário específico em que um valor distinto da coluna de chave principal do índice B-Tree é selecionado. Como parte dessa verificação, ele evita percorrer todos os valores de colunas de chave iguais, em vez de apenas percorrer o primeiro valor exclusivo e, em seguida, pular para o próximo grande.
Este trabalho ainda está em andamento no PostgreSQL com o nome provisório de “Index Skip Scan” e podemos esperar ver isso em uma versão futura.