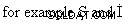Boa pergunta.
Os índices funcionam da esquerda para a direita, então seu
WHERE critérios usariam o índice. A classificação também utilizaria o índice neste caso (plano de execução abaixo). Do manual :
Se você tivesse um índice de coluna única (
accountid ), um filesort seria usado em seu lugar. Portanto, sua consulta se beneficia desse índice. Índice de duas colunas
create table t1 (
accountid tinyint,
logindate date);
create index idx on t1 (accountid, logindate);
insert into t1 values (1, '2012-09-05'), (2, '2012-09-09'), (3, '2012-09-04'),
(1, '2012-09-01'), (1, '2012-09-26'), (2, '2012-05-16'),
(1, '2012-09-01'), (3, '2012-10-19'), (1, '2012-03-01')
Plano de execução
ID SELECT_TYPE TABLE TYPE POSSIBLE_KEYS KEY KEY_LEN REF ROWS FILTERED EXTRA 1 SIMPLE t1 ref idx idx 2 const 5 100 Using where; Using index
Índice de coluna única
create table t1 (
accountid tinyint,
logindate date);
create index idx on t1 (accountid);
insert into t1 values (1, '2012-09-05'), (2, '2012-09-09'), (3, '2012-09-04'),
(1, '2012-09-01'), (1, '2012-09-26'), (2, '2012-05-16'), (1, '2012-09-01'),
(3, '2012-10-19'), (1, '2012-03-01')
Plano de execução
ID SELECT_TYPE TABLE TYPE POSSIBLE_KEYS KEY KEY_LEN REF ROWS FILTERED EXTRA 1 SIMPLE t1 range idx idx 2 5 100 Using where; Using filesort