A execução de bancos de dados na infraestrutura de nuvem está se tornando cada vez mais popular nos dias de hoje. Embora uma VM em nuvem possa não ser tão confiável quanto um servidor de nível empresarial, os principais provedores de nuvem oferecem uma variedade de ferramentas para aumentar a disponibilidade do serviço. Nesta postagem do blog, mostraremos como arquitetar seu banco de dados MySQL ou MariaDB para alta disponibilidade, na nuvem. Analisaremos especificamente o Amazon Web Services e o Google Cloud Platform, mas a maioria das dicas também pode ser usada com outros provedores de nuvem.
Tanto a AWS quanto o Google oferecem serviços de banco de dados em suas nuvens, e esses serviços podem ser configurados para alta disponibilidade. É possível ter cópias em diferentes zonas de disponibilidade (ou zonas no GCP), para aumentar suas chances de sobreviver a falhas parciais de serviços em uma região. Embora um serviço hospedado seja uma maneira muito conveniente de executar um banco de dados, observe que o serviço foi projetado para se comportar de uma maneira específica e pode ou não atender às suas necessidades. Por exemplo, o AWS RDS for MySQL tem uma lista bastante limitada de opções quando se trata de tratamento de failover. As implantações Multi-AZ vêm com tempo de failover de 60 a 120 segundos, conforme a documentação. Na verdade, considerando que a instância “sombra” do MySQL deve iniciar a partir de um conjunto de dados “corrompido”, isso pode demorar ainda mais, pois mais trabalho pode ser necessário na aplicação ou reversão de transações de logs de redo do InnoDB. Existe uma opção para promover um escravo a mestre, mas não é viável, pois você não pode rescravizar escravos existentes do novo mestre. No caso de um serviço gerenciado, também é intrinsecamente mais complexo e mais difícil rastrear problemas de desempenho. Mais informações sobre o RDS for MySQL e suas limitações nesta postagem do blog.
Por outro lado, se você decidir gerenciar os bancos de dados, estará em um mundo diferente de possibilidades. Várias coisas que você pode fazer em bare metal também são possíveis em instâncias do EC2 ou do Compute Engine. Você não tem a sobrecarga de gerenciar o hardware subjacente e ainda mantém o controle sobre como arquitetar o sistema. Existem duas opções principais ao projetar para disponibilidade do MySQL - replicação do MySQL e Galera Cluster. Vamos discuti-los.
Replicação MySQL
A replicação do MySQL é uma maneira comum de dimensionar o MySQL com várias cópias dos dados. Assíncrono ou semi-síncrono, permite propagar as alterações executadas em um único gravador, o mestre, para réplicas/escravos - cada um dos quais conteria o conjunto de dados completo e pode ser promovido para se tornar o novo mestre. A replicação também pode ser usada para dimensionar leituras, direcionando o tráfego de leitura para réplicas e descarregando o mestre dessa maneira. A principal vantagem da replicação é a facilidade de uso - ela é tão conhecida e popular (também é fácil de configurar) que existem inúmeros recursos e ferramentas para ajudá-lo a gerenciá-la e configurá-la. Nosso próprio ClusterControl é um deles - você pode usá-lo para implantar facilmente uma configuração de replicação MySQL com balanceadores de carga integrados, gerenciar alterações de topologia, failover/recuperação e assim por diante.
Um grande problema com a replicação do MySQL é que ela não foi projetada para lidar com divisões de rede ou falha do mestre. Se um mestre cair, você deve promover uma das réplicas. Este é um processo manual, embora possa ser automatizado com ferramentas externas (por exemplo, ClusterControl). Também não há mecanismo de quorum e não há suporte para fence de instâncias master com falha na replicação do MySQL. Infelizmente, isso pode levar a sérios problemas em ambientes distribuídos - se você promoveu um novo mestre enquanto o antigo volta a ficar online, pode acabar gravando em dois nós, criando desvio de dados e causando sérios problemas de consistência de dados.
Veremos alguns exemplos mais adiante neste post, que mostram como detectar divisões de rede e implementar STONITH ou algum outro mecanismo de fencing para sua configuração de replicação MySQL.
Conjunto Galera
Vimos na seção anterior que a replicação do MySQL não tem suporte para fencing e quorum - é aqui que o Galera Cluster brilha. Ele possui um suporte de quorum embutido, também possui um mecanismo de fencing que impede que nós particionados aceitem gravações. Isso torna o Galera Cluster mais adequado do que a replicação em configurações de vários datacenters. O Galera Cluster também oferece suporte a vários gravadores e é capaz de resolver conflitos de gravação. Portanto, você não está limitado a um único gravador em uma configuração de vários datacenters, é possível ter um gravador em cada datacenter, o que reduz a latência entre o aplicativo e a camada do banco de dados. Ele não acelera as gravações, pois cada gravação ainda precisa ser enviada para cada nó Galera para certificação, mas ainda é mais fácil do que enviar gravações de todos os servidores de aplicativos pela WAN para um único mestre remoto.
Por melhor que o Galera seja, nem sempre é a melhor escolha para todas as cargas de trabalho. Galera não é um substituto para MySQL/InnoDB. Ele compartilha recursos comuns com o MySQL "normal" - ele usa o InnoDB como mecanismo de armazenamento, contém todo o conjunto de dados em cada nó, o que torna os JOINs viáveis. Ainda assim, algumas das características de desempenho do Galera (como o desempenho das gravações que são afetadas pela latência da rede) diferem do que você esperaria das configurações de replicação. A manutenção também parece diferente:o tratamento de alterações de esquema funciona um pouco diferente. Alguns designs de esquema não são ideais:se você tiver pontos de acesso em suas tabelas, como contadores atualizados com frequência, isso pode levar a problemas de desempenho. Há também uma diferença nas práticas recomendadas relacionadas ao processamento em lote - em vez de executar consultas em grandes transações, você deseja que suas transações sejam pequenas.
Nível de proxy
É muito difícil e complicado construir uma configuração altamente disponível sem proxies. Claro, você pode escrever código em seu aplicativo para acompanhar instâncias de banco de dados, colocar na lista negra as não íntegras, acompanhar o(s) mestre(s) gravável(is) e assim por diante. Mas isso é muito mais complexo do que apenas enviar tráfego para um único endpoint - que é onde entra um proxy. O ClusterControl permite que você implante ProxySQL, HAProxy e MaxScale. Daremos alguns exemplos usando ProxySQL, pois nos dá uma boa flexibilidade no controle do tráfego do banco de dados.
O ProxySQL pode ser implantado de duas maneiras. Para iniciantes, ele pode ser implantado em hosts separados e o Keepalived pode ser usado para fornecer IP virtual. O IP virtual será movido caso uma das instâncias do ProxySQL falhe. Na nuvem, essa configuração pode ser problemática, pois adicionar um IP à interface geralmente não é suficiente. Você teria que modificar a configuração e os scripts do Keepalived para trabalhar com IP elástico (ou estático - no entanto, pode ser chamado pelo seu provedor de nuvem). Em seguida, usaria a API ou CLI na nuvem para realocar esse endereço IP para outro host. Por esse motivo, sugerimos colocar o ProxySQL com o aplicativo. Cada servidor de aplicação seria configurado para se conectar ao ProxySQL local, usando soquetes Unix. Como o ProxySQL usa um processo anjo, as falhas do ProxySQL podem ser detectadas/reiniciadas em um segundo. Em caso de falha de hardware, esse servidor de aplicativos específico ficará inativo junto com o ProxySQL. Os servidores de aplicativos restantes ainda podem acessar suas respectivas instâncias locais do ProxySQL. Essa configuração específica possui recursos adicionais. Segurança - ProxySQL, a partir da versão 1.4.8, não tem suporte para SSL do lado do cliente. Ele só pode configurar a conexão SSL entre o ProxySQL e o back-end. Colocar o ProxySQL no host do aplicativo e usar soquetes Unix é uma boa solução alternativa. O ProxySQL também tem a capacidade de armazenar consultas em cache e, se você for usar esse recurso, faz sentido mantê-lo o mais próximo possível do aplicativo para reduzir a latência. Sugerimos usar esse padrão para implantar o ProxySQL.
Configurações típicas
Vamos dar uma olhada em exemplos de configurações altamente disponíveis.
Datacenter único, replicação MySQL
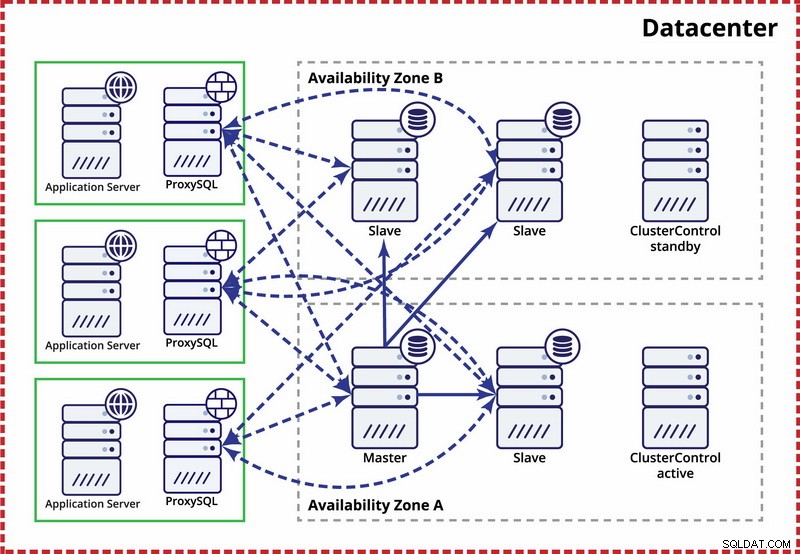
A suposição aqui é que existem duas zonas separadas dentro do datacenter. Cada zona tem energia, rede e conectividade redundantes e separadas para reduzir a probabilidade de duas zonas falharem simultaneamente. É possível configurar uma topologia de replicação abrangendo ambas as zonas.
Aqui usamos o ClusterControl para gerenciar o failover. Para resolver o cenário de cérebro dividido entre zonas de disponibilidade, colocamos o ClusterControl ativo com o mestre. Também colocamos escravos na outra zona de disponibilidade para garantir que o failover automatizado não resultará na disponibilidade de dois mestres.
Vários datacenters, replicação MySQL
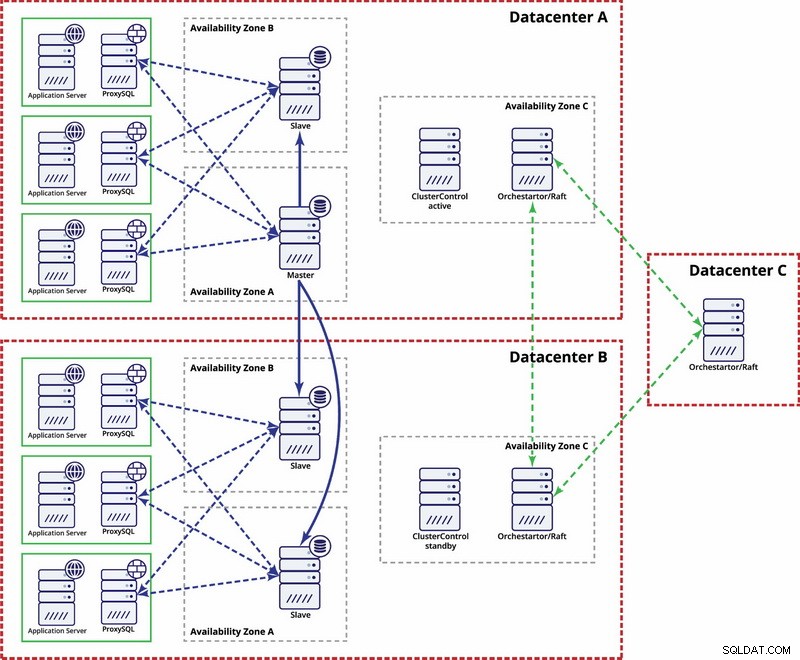
Neste exemplo, usamos três datacenters e Orchestrator/Raft para cálculo de quorum. Você pode ter que escrever seus próprios scripts para implementar STONITH se o master estiver no segmento particionado da infraestrutura. ClusterControl é usado para funções de gerenciamento e recuperação de nós.
Vários datacenters, Galera Cluster
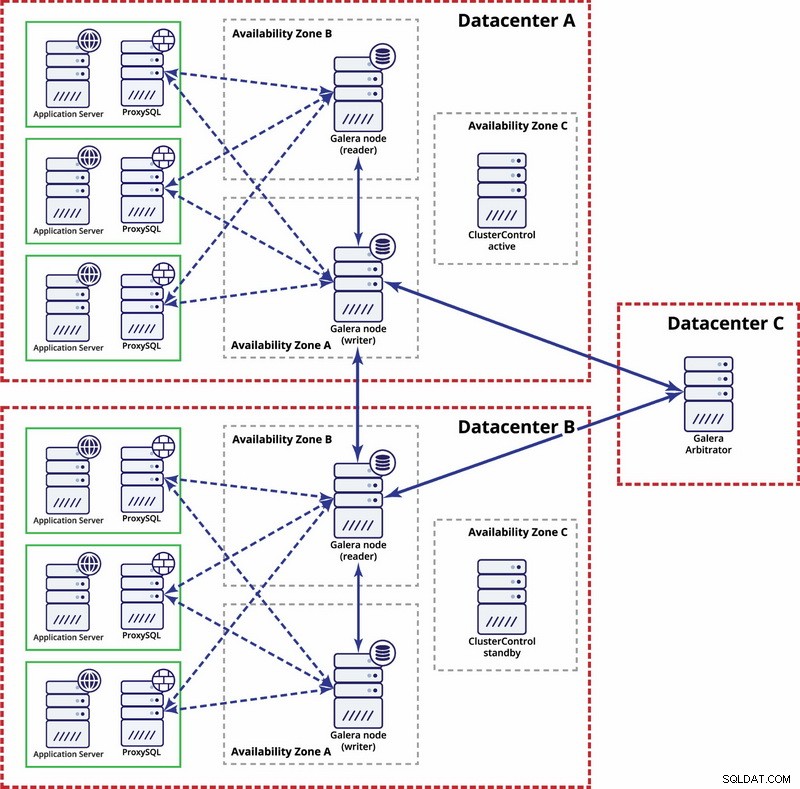
Nesse caso, usamos três datacenters com um árbitro Galera no terceiro - isso possibilita lidar com falhas de todo o datacenter e reduz o risco de particionamento de rede, pois o terceiro datacenter pode ser usado como retransmissão.
Para ler mais, dê uma olhada no whitepaper “Como projetar ambientes de banco de dados de código aberto altamente disponíveis” e assista à repetição do webinar “Projetando bancos de dados de código aberto para alta disponibilidade”.