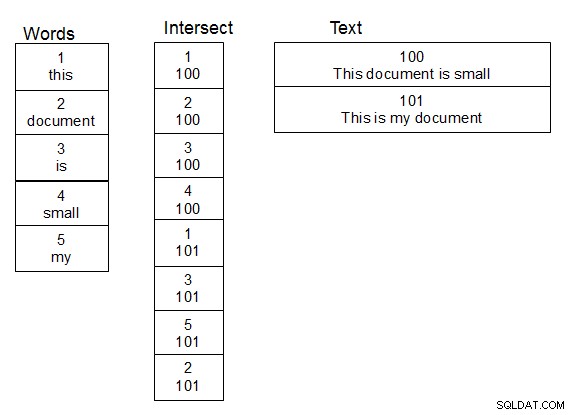
Ao trabalhar com nomes de pessoas e fazer pesquisas difusas sobre eles, o que funcionou para mim foi criar uma segunda tabela de palavras. Crie também uma terceira tabela que seja uma tabela de interseção para o relacionamento muitos para muitos entre a tabela que contém o texto e a tabela de palavras. Quando uma linha é adicionada à tabela de texto, você divide o texto em palavras e preenche a tabela de interseção apropriadamente, adicionando novas palavras à tabela de palavras quando necessário. Uma vez que esta estrutura esteja no lugar, você pode fazer pesquisas um pouco mais rápido, porque você só precisa executar sua função damlev sobre a tabela de palavras únicas. Uma junção simples fornece o texto que contém as palavras correspondentes.
Uma consulta para uma correspondência de uma única palavra seria algo assim:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
e duas palavras ficariam assim (em cima da minha cabeça, então pode não estar exatamente correta):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
As vantagens aqui, ao custo de algum espaço de banco de dados, é que você só precisa aplicar a função damlev demorada às palavras únicas, que provavelmente serão numeradas apenas na casa dos 10 de milhares, independentemente do tamanho da sua tabela de texto. Isso importa, porque a UDF damlev não usará índices - ela varrerá toda a tabela na qual é aplicada para calcular um valor para cada linha. Digitalizar apenas as palavras únicas deve ser muito mais rápido. A outra vantagem é que o damlev é aplicado no nível da palavra, que parece ser o que você está pedindo. Outra vantagem é que você pode expandir a consulta para oferecer suporte à pesquisa em várias palavras e classificar os resultados agrupando as linhas de interseção correspondentes no TextId e classificando a contagem de correspondências.