Já se passaram quase dois meses desde que lançamos o SCUMM (Severalnines ClusterControl Unified Management and Monitoring). O SCUMM utiliza o Prometheus como método subjacente para coletar dados de séries temporais de exportadores executados em instâncias de banco de dados e balanceadores de carga. Este blog mostrará como corrigir problemas quando os exportadores do Prometheus não estiverem em execução, ou se os gráficos não estiverem exibindo dados ou mostrando "Nenhum ponto de dados".
O que é Prometheus?
O Prometheus é um sistema de monitoramento de código aberto com modelo de dados dimensional, linguagem de consulta flexível, banco de dados de séries temporais eficiente e abordagem de alerta moderna. É uma plataforma de monitoramento que coleta métricas de destinos monitorados por meio de coleta de métricas de endpoints HTTP nesses destinos. Ele fornece dados dimensionais, consultas poderosas, ótima visualização, armazenamento eficiente, operação simples, alertas precisos, muitas bibliotecas de clientes e muitas integrações.
Prometheus em ação para painéis SCUMM
O Prometheus coleta dados de métricas de exportadores, com cada exportador sendo executado em um banco de dados ou host do balanceador de carga. O diagrama abaixo mostra como esses exportadores estão vinculados ao servidor que hospeda o processo do Prometheus. Ele mostra que o nó ClusterControl tem o Prometheus em execução onde também executa process_exporter e node_exporter.
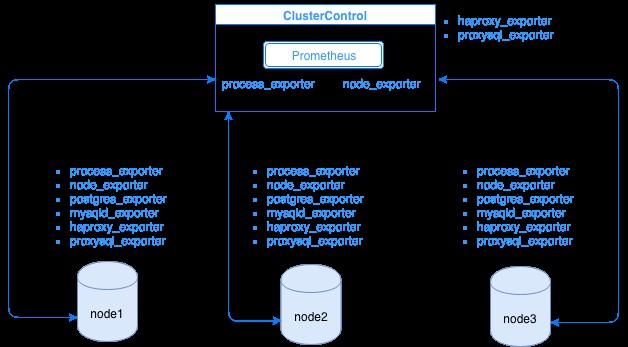
O diagrama mostra que o Prometheus está sendo executado no host ClusterControl e nos exportadores process_exporter e node_exporter estão sendo executados também para coletar métricas de seu próprio nó. Opcionalmente, você também pode tornar seu host ClusterControl o destino no qual você pode configurar HAProxy ou ProxySQL.
Para os nós de cluster acima (node1, node2 e node3), ele pode ter mysqld_exporter ou postgres_exporter em execução, que são os agentes que raspam os dados internamente nesse nó e os passam para o servidor Prometheus e os armazenam em seu próprio armazenamento de dados. Você pode localizar seus dados físicos via /var/lib/prometheus/data dentro do host onde o Prometheus está configurado.
Ao configurar o Prometheus, por exemplo, no host ClusterControl, ele deve ter as seguintes portas abertas. Ver abaixo:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusCom base na saída, tenho o ProxySQL em execução também no host testccnode no qual o ClusterControl está hospedado.
Problemas comuns com painéis SCUMM usando o Prometheus
Quando os Dashboards estiverem habilitados, o ClusterControl instalará e implantará binários e exportadores como node_exporter, process_exporter, mysqld_exporter, postgres_exporter e daemon. Esses são os conjuntos comuns de pacotes para os nós do banco de dados. Quando estes são configurados e instalados, os seguintes comandos daemon são acionados e executados como visto abaixo:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusPara um nó PostgreSQL,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterEle tem os mesmos exportadores de um nó MySQL, mas difere apenas no postgres_exporter, pois este é um nó de banco de dados PostgreSQL.
No entanto, quando um nó sofre uma interrupção de energia, uma falha do sistema ou uma reinicialização do sistema, esses exportadores param de funcionar. O Prometheus informará que um exportador está inativo. O ClusterControl faz uma amostra do próprio Prometheus e solicita os status do exportador. Portanto, ele atua sobre essas informações e reiniciará o exportador se estiver inativo.
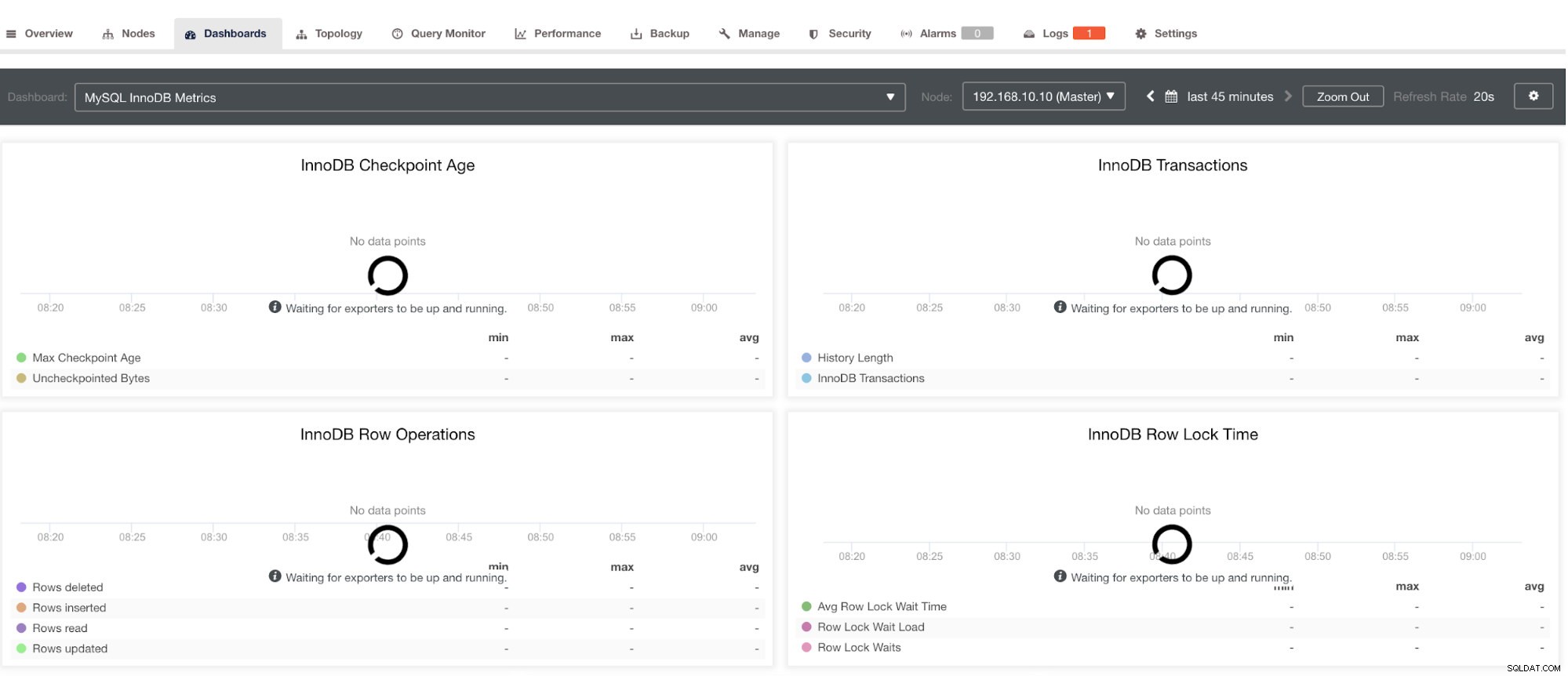
No entanto, observe que, para exportadores que não foram instalados via ClusterControl, eles não serão reiniciados após uma falha. A razão é que eles não são monitorados pelo systemd ou por um daemon que atua como um script de segurança que reiniciaria um processo em caso de falha ou desligamento anormal. Portanto, a captura de tela abaixo mostrará como fica quando os exportadores não estão em execução. Ver abaixo:
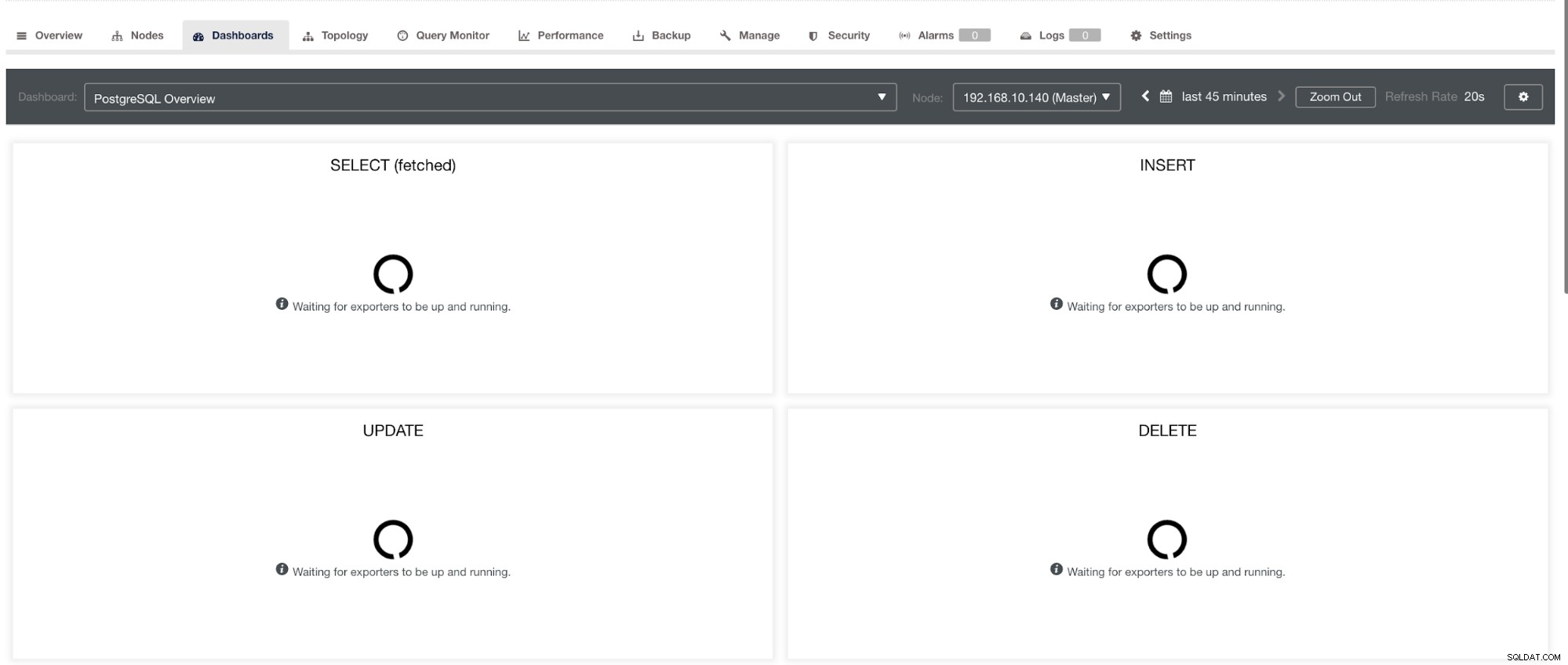
e no PostgreSQL Dashboard, terá o mesmo ícone de carregamento com o rótulo “Sem pontos de dados” no gráfico. Ver abaixo:
Portanto, eles podem ser solucionados por meio de várias técnicas que seguirão nas seções a seguir.
Solução de problemas com o Prometheus
Os agentes Prometheus, conhecidos como exportadores, estão usando as seguintes portas:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) e a própria 9090 que é de propriedade de um prometheus processo. Essas são as portas para esses agentes que são usadas pelo ClusterControl.
Para começar a solucionar os problemas do SCUMM Dashboard, você pode começar verificando as portas abertas no nó do banco de dados. Você pode seguir as listas abaixo:
-
Verifique se as portas estão abertas
por exemplo.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_expor
Pode haver a possibilidade de que as portas não estejam abertas devido a um firewall (como iptables ou firewalld) bloqueando a abertura da porta ou o próprio daemon de processo não está em execução.
-
Use curl do monitor host e verifique se a porta está acessível e aberta.
por exemplo.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0
Idealmente, eu praticamente achei essa abordagem viável para mim porque posso grep e depurar do terminal facilmente.
-
Por que não usar a interface do usuário da Web?
-
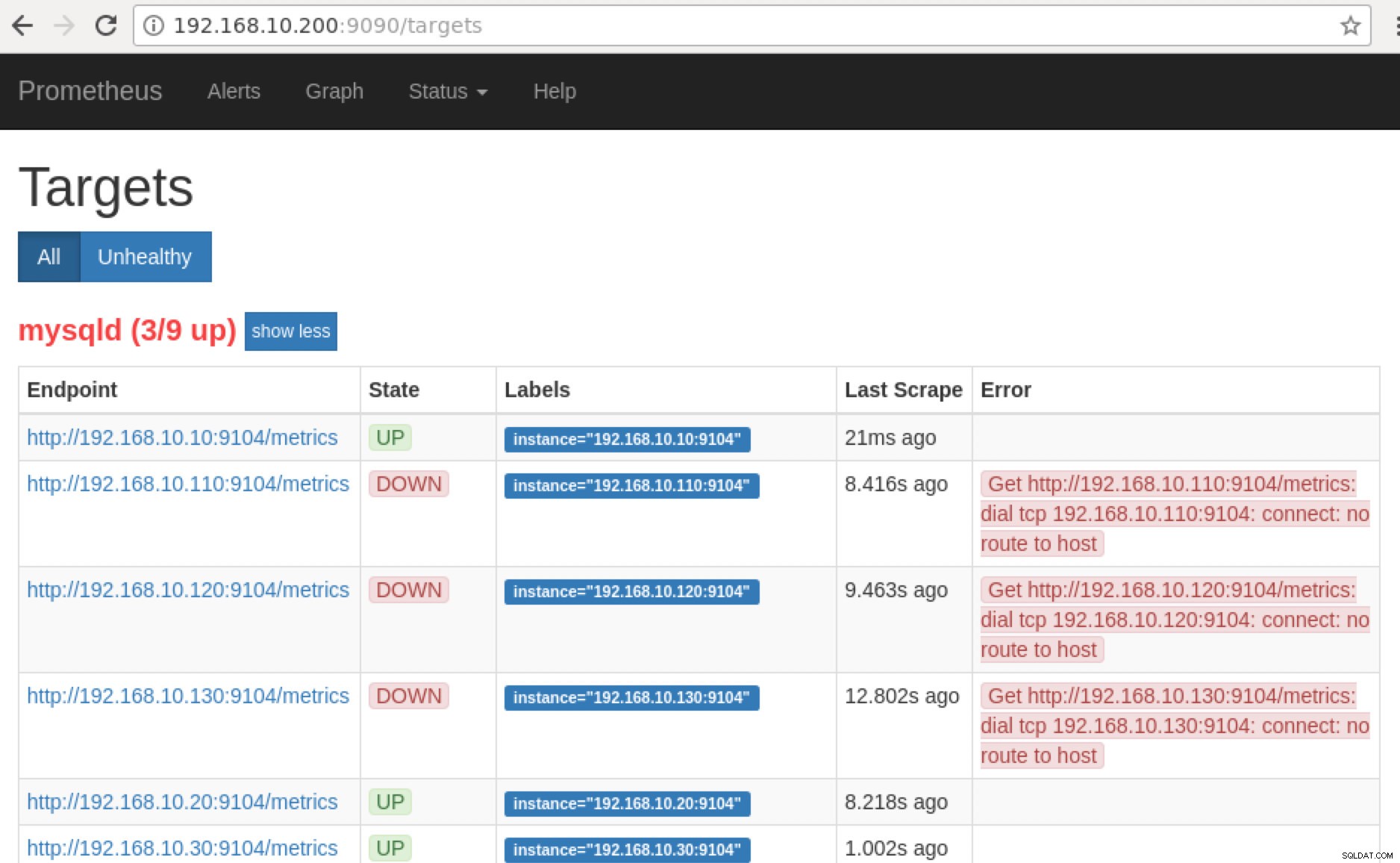
O Prometheus expõe a porta 9090 que é usada pelo ClusterControl em nossos painéis SCUMM. Além disso, as portas que os exportadores estão expondo também podem ser usadas para solucionar problemas e determinar os nomes das métricas disponíveis usando o PromQL. No servidor em que o Prometheus está sendo executado, você pode visitar https://:9090/targets . A captura de tela abaixo mostra isso em ação:
e clicando em “Endpoints”, você pode verificar as métricas assim como a imagem abaixo:
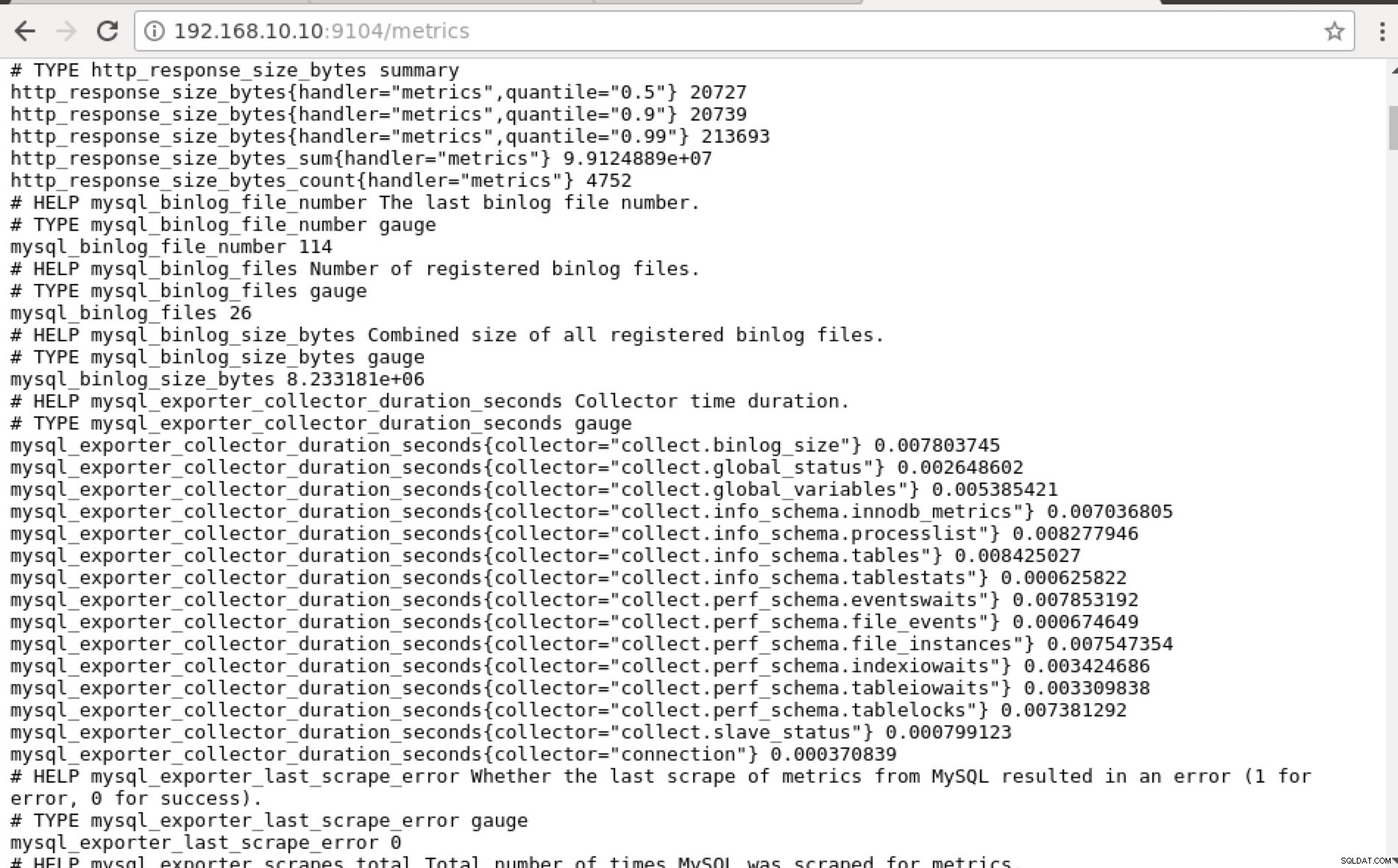
Em vez de usar o endereço IP, você também pode verificar isso localmente por meio de localhost nesse nó específico, como visitando https://localhost:9104/metrics em uma interface de UI da Web ou usando cURL.
Agora, se voltarmos aos “Destinos ” página, você pode ver a lista de nós onde pode haver um problema com a porta. Os motivos que podem causar isso estão listados abaixo:
- O servidor está inativo
- A rede está inacessível ou as portas não estão abertas devido à execução de um firewall
- O daemon não está sendo executado onde o
_exporter não está correndo. Por exemplo, mysqld_exporter não está rodando.
-
Quando esses exportadores estão em execução, você pode iniciar e executar o processo usando o daemon comando. Você pode consultar os processos em execução disponíveis que usei no exemplo acima ou mencionados na seção anterior deste blog.
E os gráficos "Sem pontos de dados" no meu painel?
Os painéis SCUMM apresentam um cenário de caso de uso geral que é comumente usado pelo MySQL. No entanto, existem algumas variáveis ao invocar tal métrica que pode não estar disponível em uma versão específica do MySQL ou em um fornecedor MySQL, como MariaDB ou Percona Server.
Deixe-me mostrar um exemplo abaixo:
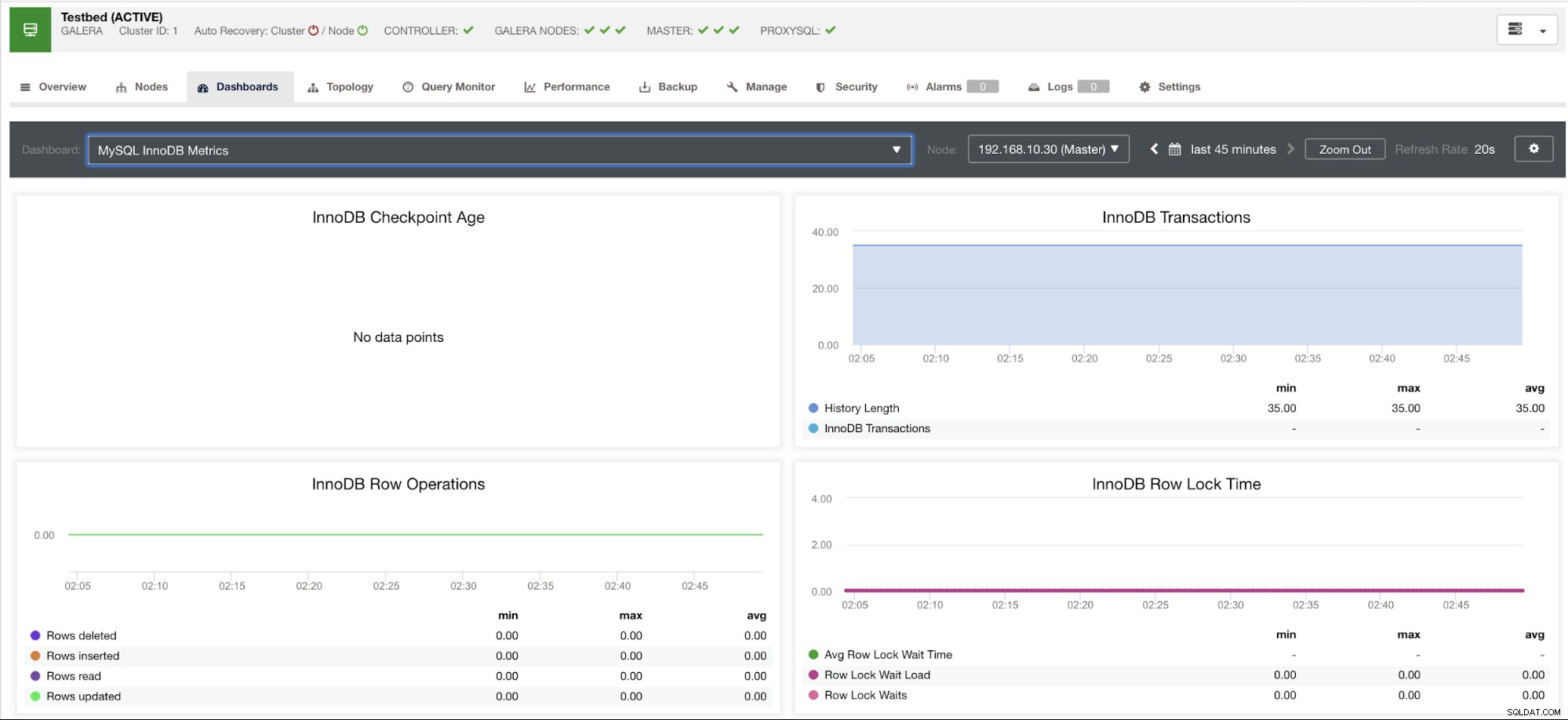
Este gráfico foi obtido em um servidor de banco de dados rodando em uma versão 10.3.9-MariaDB-log Servidor MariaDB com wsrep_patch_version da instância wsrep_25.23. Agora a pergunta é:por que não há nenhum carregamento de pontos de dados? Bem, enquanto eu consultava o nó para um status de idade do ponto de verificação, ele revela que está vazio ou nenhuma variável encontrada. Ver abaixo:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Eu não tenho ideia de por que o MariaDB não tem essa variável (por favor, deixe-nos saber na seção de comentários deste blog se você tiver a resposta). Isso contrasta com um Percona XtraDB Cluster Server onde a variável Innodb_checkpoint_max_age existe. Ver abaixo:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)O que isso significa é que pode haver gráficos que não possuem pontos de dados coletados porque não há dados sendo coletados nessa métrica específica quando uma consulta do Prometheus foi executada.
No entanto, um gráfico que não possui pontos de dados não significa que sua versão atual do MySQL ou sua variante não o suporte. Por exemplo, existem certos gráficos que requerem certas variáveis que precisam ser configuradas corretamente ou habilitadas.
A seção a seguir mostrará quais são esses gráficos.
Gráfico de pushdown de condição de índice (ICP)

Este gráfico foi mencionado no meu blog anterior. Ele se baseia em uma variável global do MySQL chamada innodb_monitor_enable. Esta variável é dinâmica, então você pode definir isso sem uma reinicialização forçada do seu banco de dados MySQL. Também requer innodb_monitor_enable =module_icp ou você pode definir essa variável global como innodb_monitor_enable =all. Normalmente, para evitar esses casos e confusões sobre o motivo pelo qual esse gráfico não mostra nenhum ponto de dados, talvez seja necessário usar todos, exceto com cuidado. Pode haver certa sobrecarga quando essa variável é ativada e definida como all.
Gráficos de esquema de desempenho do MySQL
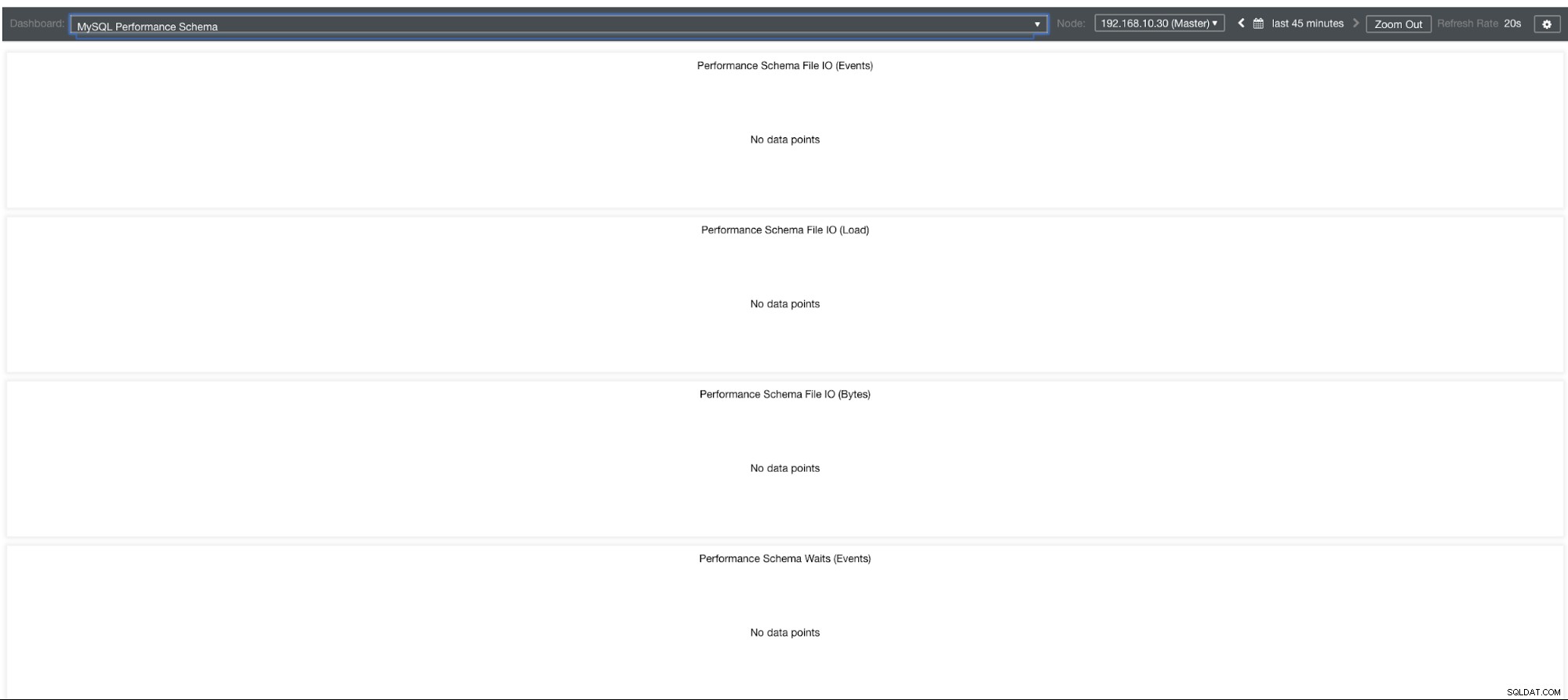
Então, por que esses gráficos estão mostrando “Nenhum ponto de dados”? Quando você cria um cluster usando o ClusterControl usando nossos templates, por padrão ele definirá as variáveis performance_schema. Por exemplo, estas variáveis abaixo são definidas:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0No entanto, se performance_schema =OFF, então essa é a razão pela qual os gráficos relacionados exibiriam “Nenhum ponto de dados”.
Mas eu tenho o performance_schema ativado, por que outros gráficos ainda são um problema?
Bem, ainda existem gráficos que exigem que várias variáveis sejam definidas. Isso já foi abordado em nosso blog anterior. Assim, você precisa definir innodb_monitor_enable =all e userstat =1. O resultado ficaria assim:
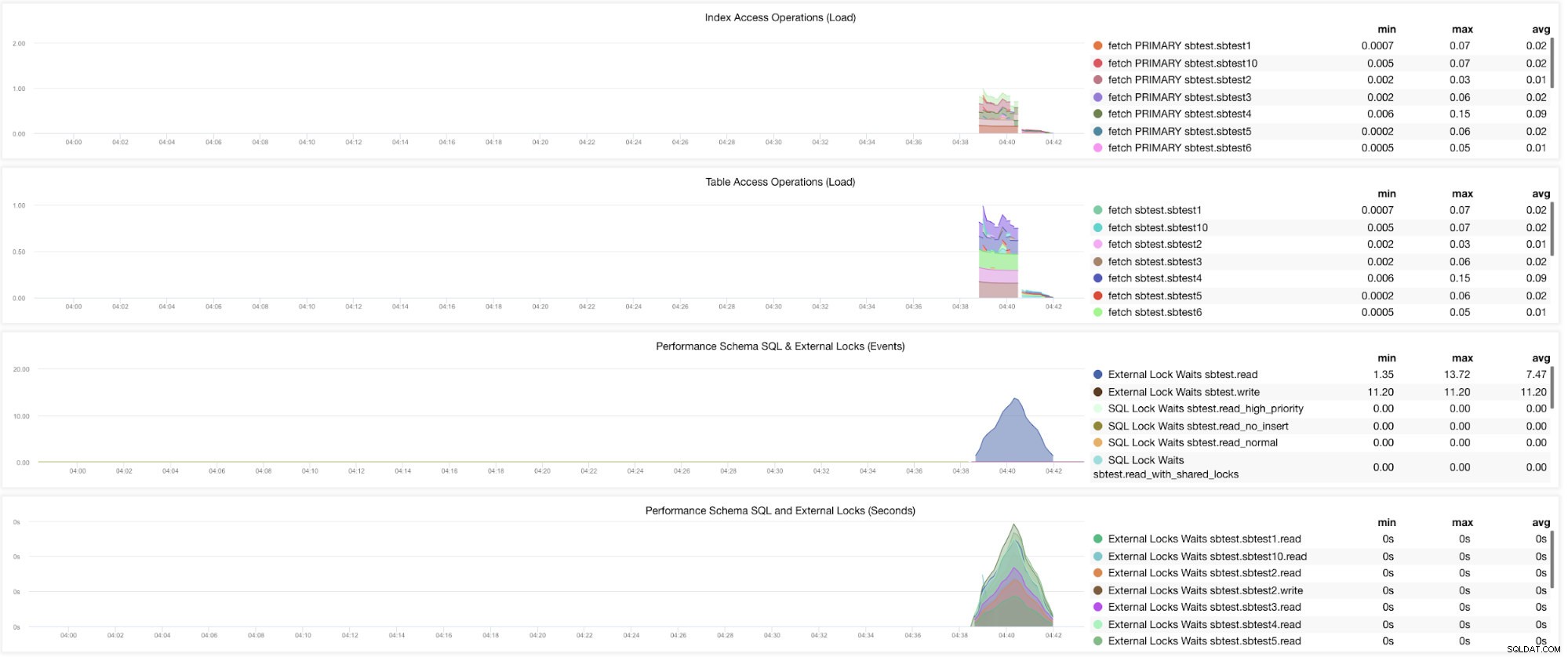
No entanto, noto que na versão do MariaDB 10.3 (particularmente 10.3.11), a configuração performance_schema=ON preencherá as métricas necessárias para o MySQL Performance Schema Dashboard. Isso é uma grande vantagem porque não precisa definir innodb_monitor_enable=ON, o que adicionaria sobrecarga extra no servidor de banco de dados.
Solução de problemas avançada
Existe alguma solução de problemas avançada que eu possa recomendar? Sim existe! No entanto, você precisa de algumas habilidades de JavaScript, pelo menos. Como os SCUMM Dashboards usando o Prometheus dependem de highcharts, a maneira como as métricas que estão sendo usadas para solicitações PromQL podem ser determinadas por meio do script app.js mostrado abaixo:
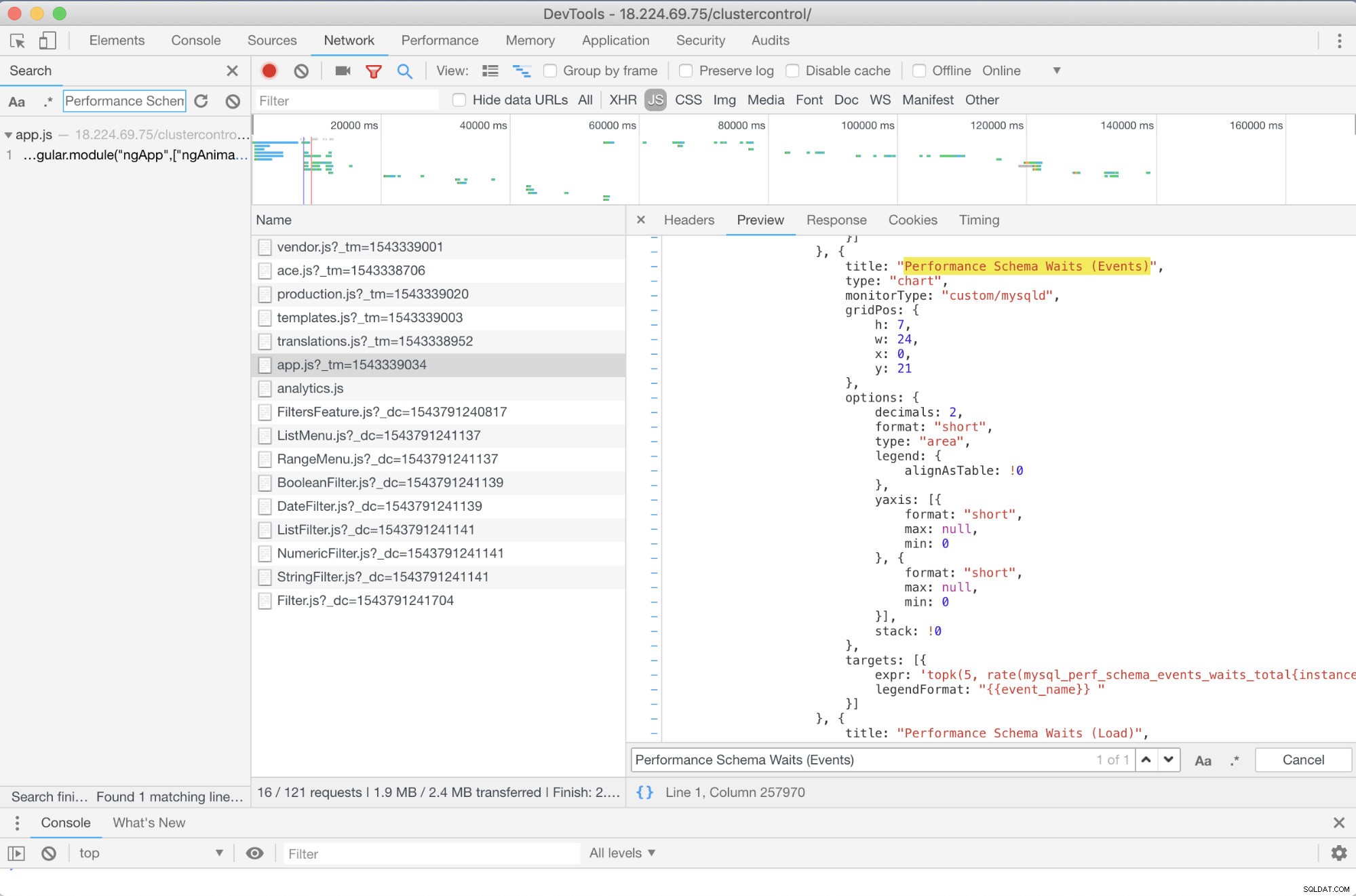
Então, neste caso, estou usando o DevTools do Google Chrome e tentei procurar por Performance Schema Waits (Events) . Como isso pode ajudar? Bem, se você olhar para os alvos, verá:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]Agora, você pode usar as métricas solicitadas que são mysql_perf_schema_events_waits_total. Você pode verificar isso, por exemplo, acessando https://
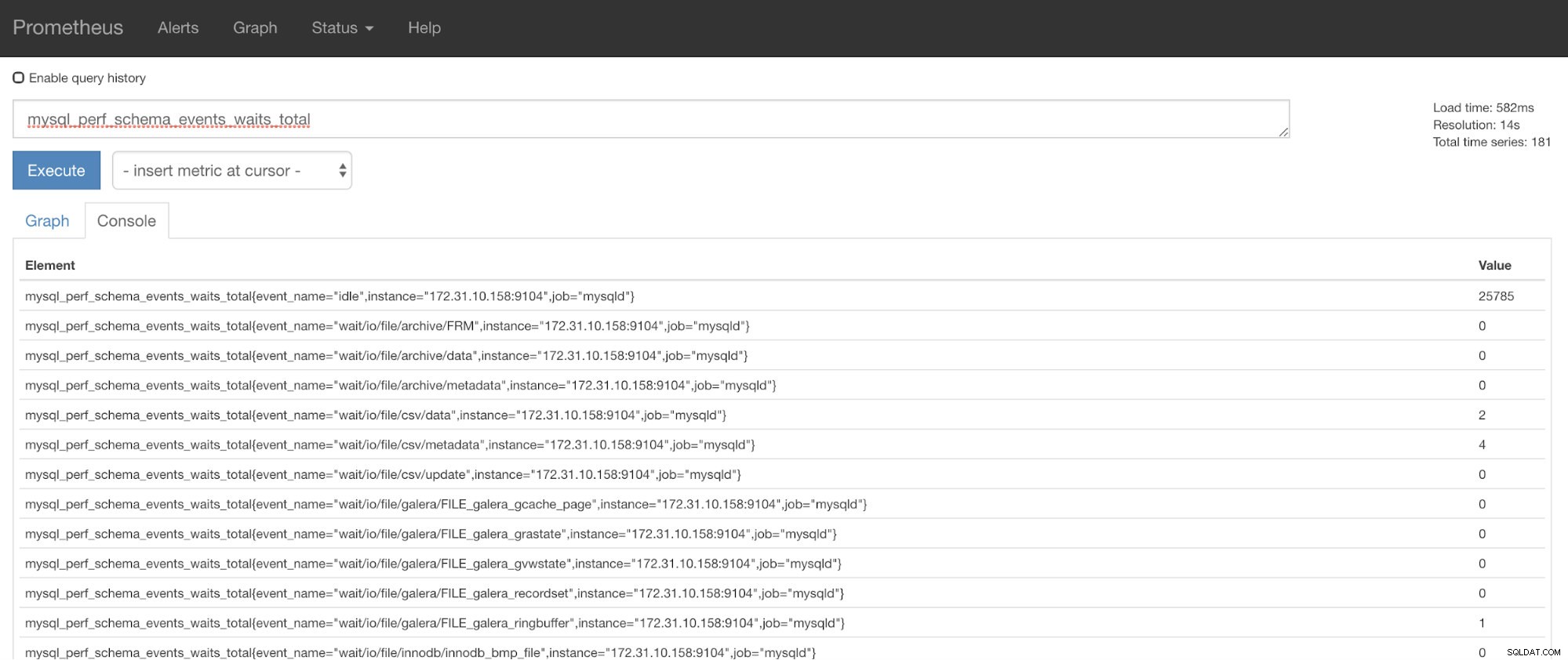
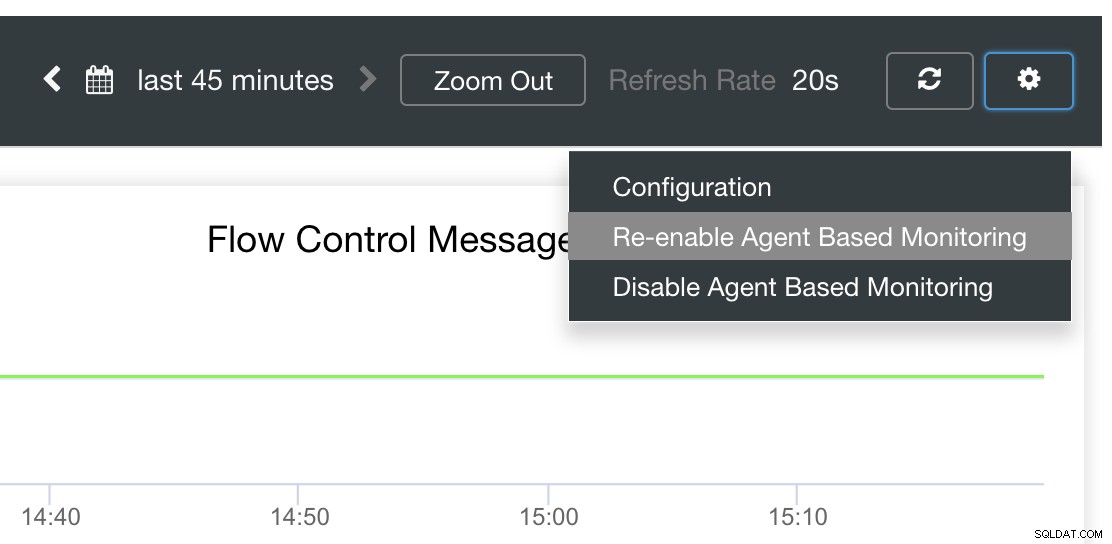
Recuperação automática do ClusterControl para o resgate!
Por fim, a questão principal é:existe uma maneira fácil de reiniciar exportadores com falha? Sim! Mencionamos anteriormente que o ClusterControl observa o estado das exportações e as reinicia, se necessário. Caso você perceba que os SCUMM Dashboards não carregam os gráficos normalmente, certifique-se de ter a Recuperação Automática habilitada. Veja a imagem abaixo:

Quando ativado, isso garantirá que os
Também é possível reinstalar ou reconfigurar os exportadores.
Conclusão
Neste blog, vimos como o ClusterControl usa o Prometheus para oferecer painéis SCUMM. Ele fornece um poderoso conjunto de recursos, desde dados de monitoramento de alta resolução e gráficos ricos. Você aprendeu que, com o PromQL, você pode determinar e solucionar problemas de nossos painéis SCUMM, que permitem agregar dados de séries temporais em tempo real. Você também pode gerar gráficos ou visualizar através do Console todas as métricas que foram coletadas.
Você também aprendeu a depurar nossos painéis SCUMM, especialmente quando nenhum ponto de dados é coletado.
Se você tiver dúvidas, adicione seus comentários ou informe-nos por meio de nossos fóruns da comunidade.



