A Amazon lançou o S3 no início de 2006 e a primeira ferramenta que permite que scripts de backup do PostgreSQL carreguem dados na nuvem — s3cmd — nasceu um ano depois. Em 2010 (de acordo com minhas habilidades de pesquisa no Google) Abra blogs de BI sobre isso. É seguro dizer que alguns DBAs do PostgreSQL fazem backup de dados no AWS S3 há 9 anos. Mas como? E o que mudou nesse tempo? Embora o s3cmd ainda seja referenciado por alguns no contexto de ferramentas de backup conhecidas do PostgreSQL, os métodos sofreram alterações permitindo uma melhor integração com as opções de backup nativas do sistema de arquivos ou do PostgreSQL para atingir os objetivos de recuperação desejados RTO e RPO.
Por que Amazon S3
Como apontado em toda a documentação do Amazon S3 (as perguntas frequentes do S3 são um bom ponto de partida), as vantagens de usar o serviço S3 são:
- 99,999999999 (onze noves) durabilidade
- armazenamento de dados ilimitado
- baixos custos (ainda mais baixos quando combinados com BitTorrent)
- tráfego de rede de entrada gratuito
- somente o tráfego de rede de saída é faturável
Sugestões de CLI do AWS S3
O kit de ferramentas AWS S3 CLI fornece todas as ferramentas necessárias para transferir dados de e para o armazenamento S3, então por que não usar essas ferramentas? A resposta está nos detalhes de implementação do Amazon S3 que incluem medidas para lidar com as limitações e restrições relacionadas ao armazenamento de objetos:
- Tamanho máximo de 5 TB por objeto armazenado
- Tamanho máximo de 5 GB de um objeto PUT
- upload em várias partes recomendado para objetos maiores que 100 MB
- escolha uma classe de armazenamento apropriada de acordo com o gráfico de desempenho do S3
- aproveite o ciclo de vida do S3
- Modelo de consistência de dados do S3
Como exemplo, consulte a página de ajuda do aws s3 cp:
--expected-size (string) Este argumento especifica o tamanho esperado de um fluxo em termos de bytes. Observe que esse argumento é necessário apenas quando um fluxo está sendo carregado para s3 e o tamanho é maior que 5 GB. A não inclusão desse argumento nessas condições pode resultar em falha no upload devido a muitas partes no upload.
Evitar essas armadilhas requer um conhecimento profundo do ecossistema S3, que é o que as ferramentas de backup PostgreSQL e S3 estão tentando alcançar.
Ferramentas de backup nativo do PostgreSQL com suporte ao Amazon S3
A integração S3 é fornecida por algumas das ferramentas de backup mais conhecidas, implementando os recursos de backup nativos do PostgreSQL.
BarmanS3
BarmanS3 é implementado como scripts de gancho do Barman. Ele depende da AWS CLI, sem abordar as recomendações e limitações listadas acima. A configuração simples o torna um bom candidato para pequenas instalações. O desenvolvimento está um pouco parado, última atualização há cerca de um ano, tornando este produto uma opção para quem já utiliza o Barman em seus ambientes.
Despejos S3
S3dumps é um projeto ativo, implementado usando a biblioteca Python da Amazon Boto3. A instalação é facilmente realizada via pip. Embora dependa do Amazon S3 Python SDK, uma pesquisa no código-fonte por palavras-chave regex como multi.*part ou storage.*class não revela nenhum dos recursos avançados do S3, como transferências multipart.
pgBackRest
pgBackRest implementa o S3 como uma opção de repositório. Esta é uma das mais conhecidas ferramentas de backup do PostgreSQL, fornecendo um conjunto rico em recursos de opções de backup, como backup e restauração paralelos, criptografia e suporte a tablespaces. É principalmente código C, que fornece a velocidade e a taxa de transferência que procuramos, no entanto, quando se trata de interagir com a API do AWS S3, isso tem o preço do trabalho adicional necessário para implementar os recursos de armazenamento do S3. A versão recente implementa o upload em várias partes do S3.
WAL-G
WAL-G anunciado há 2 anos está sendo mantido ativamente. Esta sólida ferramenta de backup PostgreSQL implementa classes de armazenamento, mas não multipart upload (pesquisar o código por CreateMultipartUpload não encontrou nenhuma ocorrência).
PGHoard
pghoard foi lançado há cerca de 3 anos. É uma ferramenta de backup PostgreSQL de alto desempenho e rica em recursos com suporte para transferências de várias partes do S3. Ele não oferece nenhum dos outros recursos do S3, como classe de armazenamento e gerenciamento do ciclo de vida do objeto.
S3 como um sistema de arquivos local
Poder acessar o armazenamento S3 como um sistema de arquivos local é um recurso altamente desejado, pois abre a possibilidade de usar as ferramentas de backup nativas do PostgreSQL.
Para ambientes Linux, a Amazon oferece duas opções:NFS e iSCSI. Eles aproveitam o AWS Storage Gateway.
NFS
Um compartilhamento NFS montado localmente é fornecido pelo serviço de arquivos do AWS Storage Gateway. De acordo com o link, precisamos criar um File Gateway.
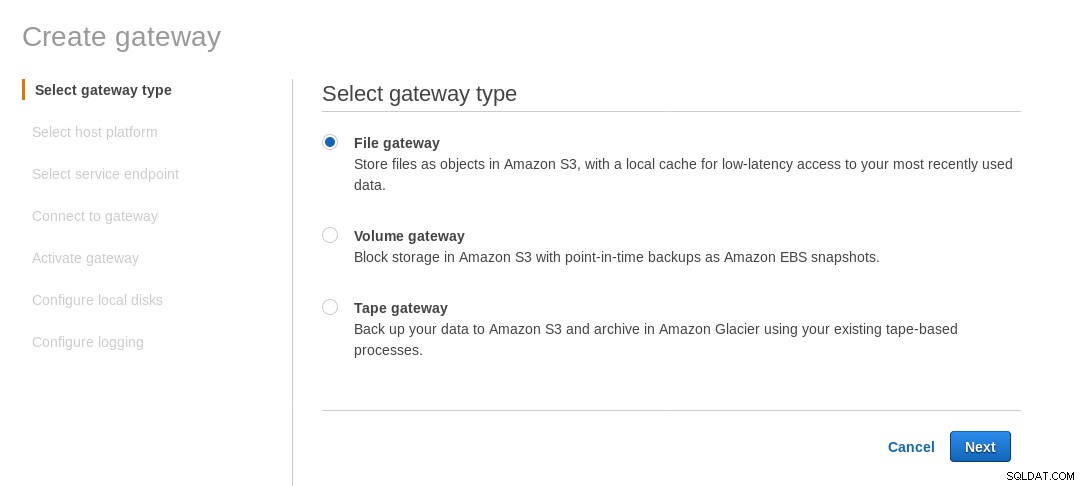
Na tela Select host platform, selecione Amazon EC2 e clique no botão Launch instance para iniciar o assistente do EC2 para criar a instância.
Agora, por curiosidade deste administrador de sistema, vamos inspecionar a AMI usada pelo assistente, pois ela nos dá uma perspectiva interessante sobre algumas das peças internas da AWS. Com o ID da imagem conhecido como ami-0bab9d6dffb52fef5, vejamos os detalhes:
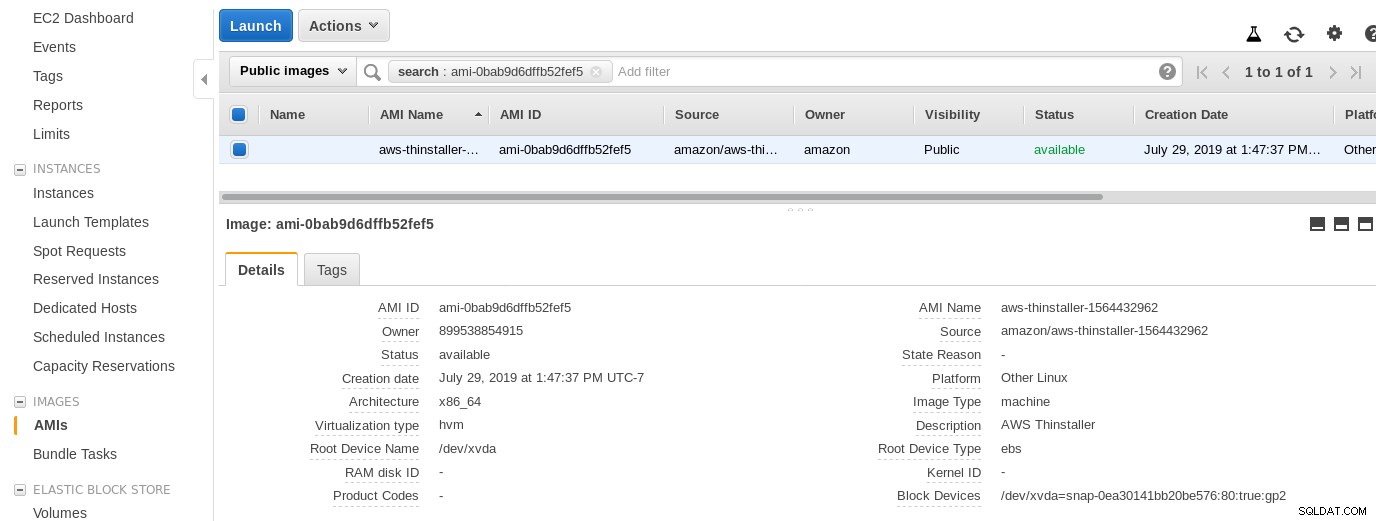
Como mostrado acima, o nome da AMI é aws-thinstaller — então o que é um “thinstaller”? Pesquisas na Internet revelam que o Thinstaller é uma ferramenta de gerenciamento de configuração de software IBM Lenovo para produtos Microsoft e é mencionado primeiro neste blog de 2008 e, posteriormente, nesta postagem no fórum da Lenovo e nesta solicitação de serviço do distrito escolar. Eu não tinha como saber disso, pois meu trabalho de administrador de sistema do Windows terminou 3 anos antes. Assim, esta AMI foi construída com o produto Thinstaller Para tornar as coisas ainda mais confusas, o sistema operacional da AMI está listado como “Outro Linux”, o que pode ser confirmado por SSH no sistema como administrador.
Uma pegadinha do assistente:apesar das instruções de configuração do firewall do EC2, meu navegador estava expirando ao se conectar ao gateway de armazenamento. A permissão da porta 80 está documentada em Requisitos de porta – podemos argumentar que o assistente deve listar todas as portas necessárias ou vincular à documentação, mas no espírito da nuvem, a resposta é “automatizar” com ferramentas como o CloudFormation.
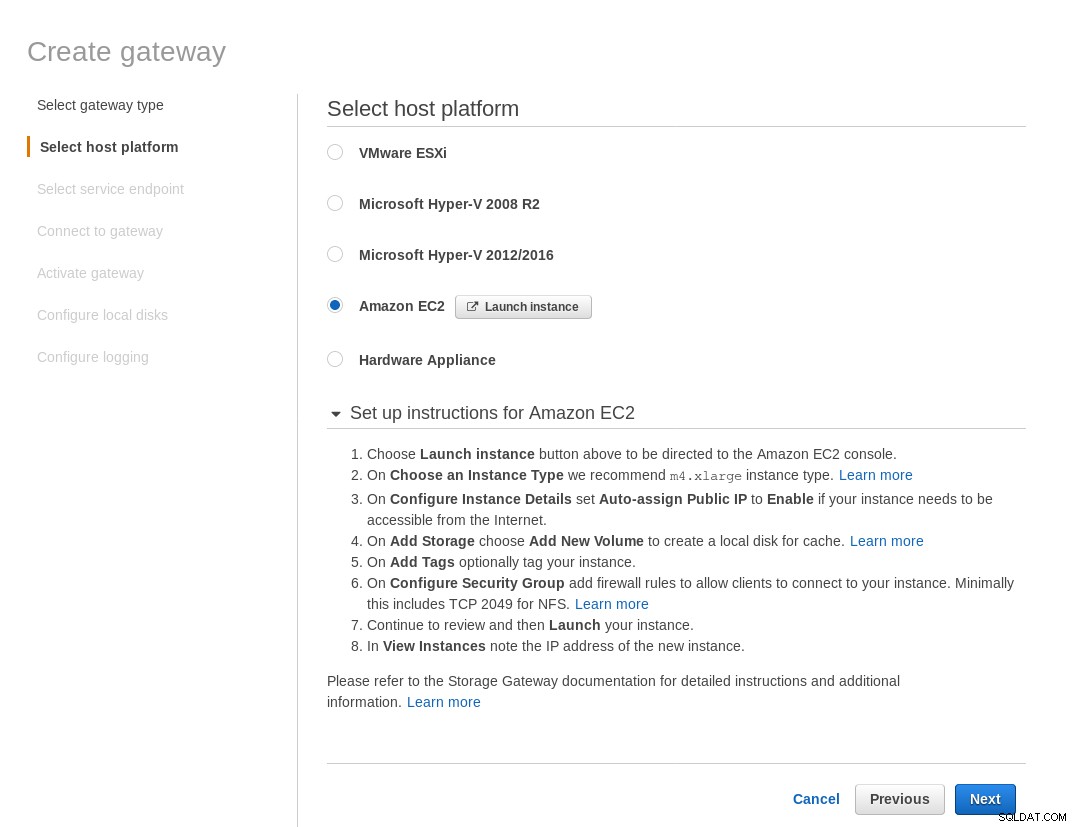
O assistente também sugere iniciar com uma instância de tamanho grande.
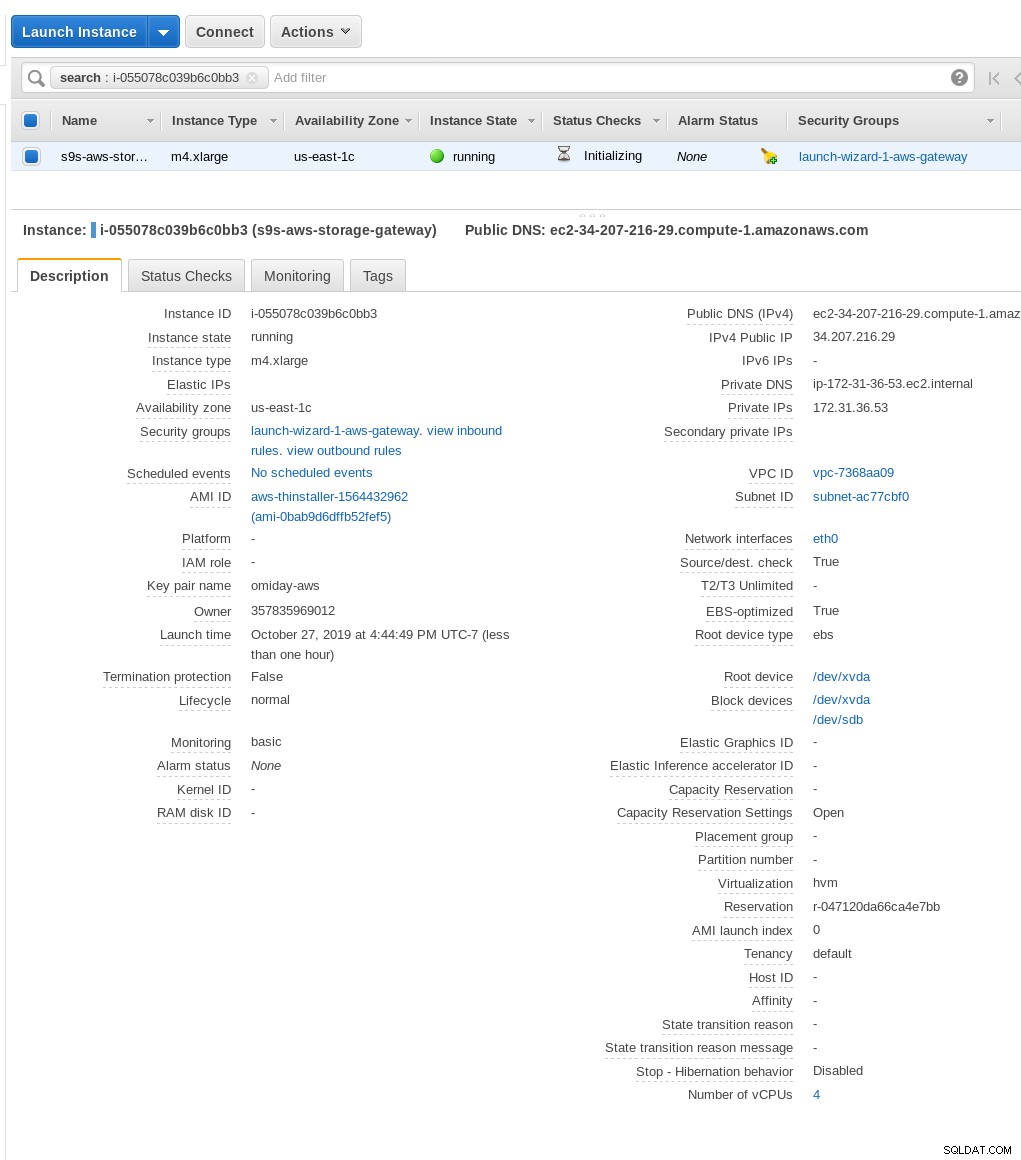
Quando o gateway de armazenamento estiver pronto, configure o compartilhamento NFS clicando no botão Criar botão de compartilhamento de arquivo no menu Gateway:
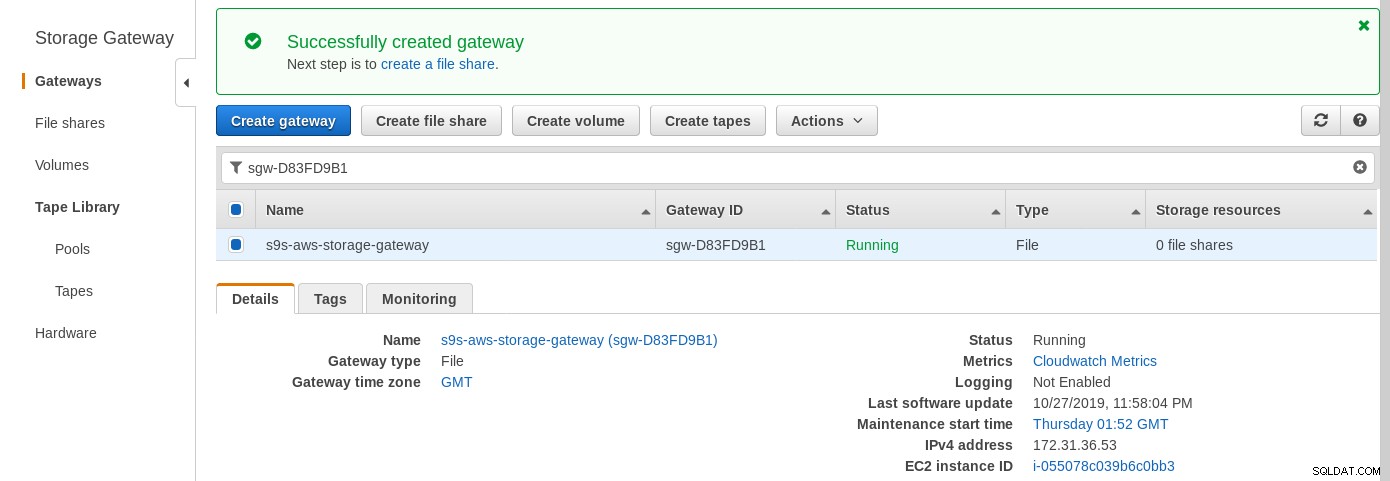
Quando o compartilhamento NFS estiver pronto, siga as instruções para montar o sistema de arquivos:
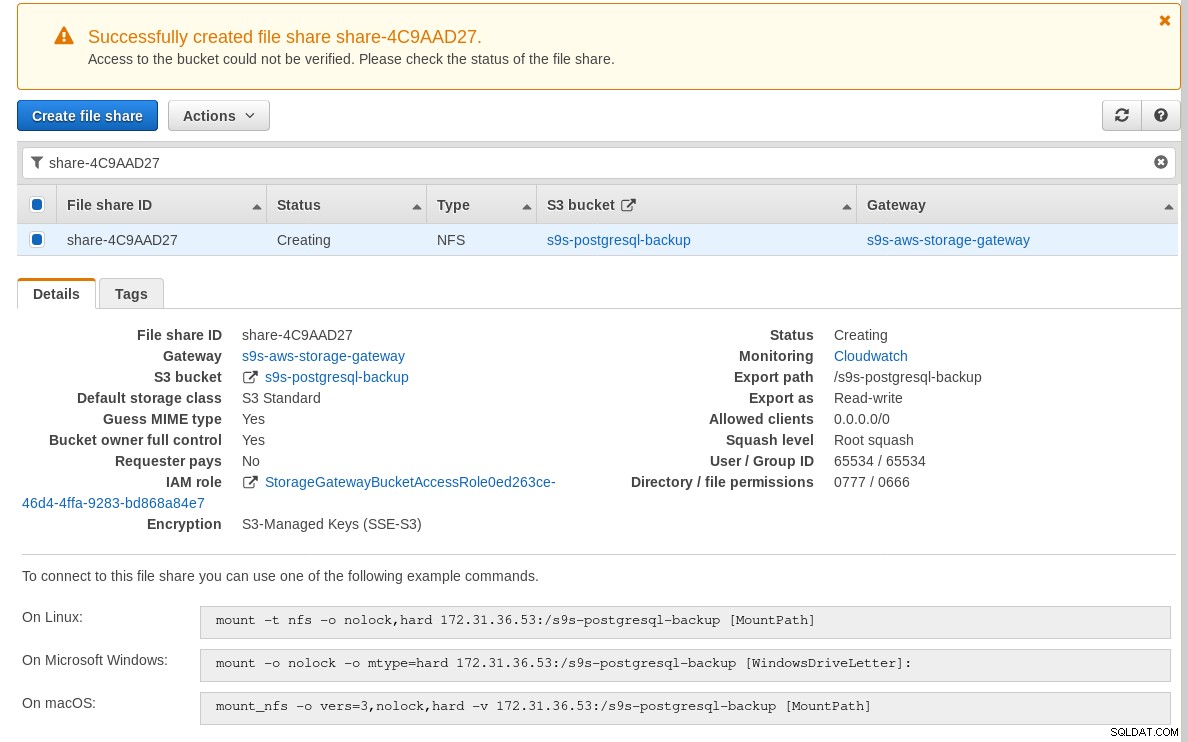
Na captura de tela acima, observe que o comando mount faz referência ao IP privado da instância Morada. Para montar de um host público, basta usar o endereço público da instância, conforme mostrado nos detalhes da instância do EC2 acima.
O assistente não bloqueará se o bucket do S3 não existir no momento da criação do compartilhamento de arquivos, no entanto, uma vez criado o bucket do S3, precisamos reiniciar a instância, caso contrário, o comando mount falha com:
[example@sqldat.com ~]# mount -t nfs -o nolock,hard 34.207.216.29:/s9s-postgresql-backup /mnt
mount.nfs: mounting 34.207.216.29:/s9s-postgresql-backup failed, reason given by server: No such file or directoryVerifique se o compartilhamento foi disponibilizado:
[example@sqldat.com ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
34.207.216.29:/s9s-postgresql-backup 8.0E 0 8.0E 0% /mntAgora vamos fazer um teste rápido:
example@sqldat.com[local]:54311 postgres# \l+ test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 2763 MB | pg_default |
(1 row)
[example@sqldat.com ~]# date ; time pg_dump -d test | gzip -c >/mnt/test.pg_dump.gz ; date
Sun 27 Oct 2019 06:06:24 PM PDT
real 0m29.807s
user 0m15.909s
sys 0m2.040s
Sun 27 Oct 2019 06:06:54 PM PDTObserve que o carimbo de data/hora da última modificação no bucket do S3 é cerca de um minuto depois, o que, conforme mencionado anteriormente, está relacionado ao modelo de consistência de dados do Amazon S3.
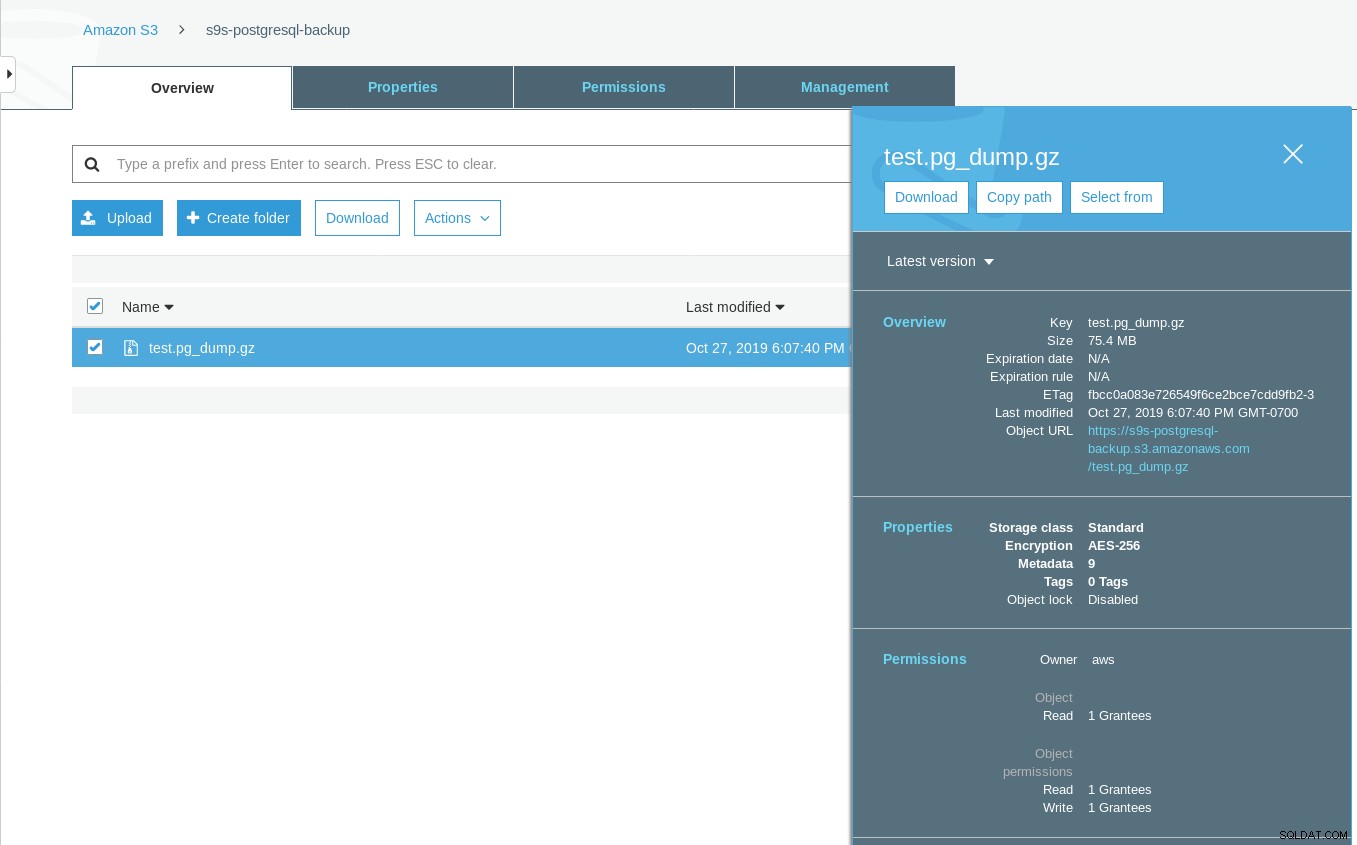
Aqui está um teste mais completo:
~ $ for q in {0..20} ; do touch /mnt/touched-at-$(date +%Y%m%d%H%M%S) ;
sleep 1 ; done
~ $ aws s3 ls s3://s9s-postgresql-backup | nl
1 2019-10-27 19:50:40 0 touched-at-20191027194957
2 2019-10-27 19:50:40 0 touched-at-20191027194958
3 2019-10-27 19:50:40 0 touched-at-20191027195000
4 2019-10-27 19:50:40 0 touched-at-20191027195001
5 2019-10-27 19:50:40 0 touched-at-20191027195002
6 2019-10-27 19:50:40 0 touched-at-20191027195004
7 2019-10-27 19:50:40 0 touched-at-20191027195005
8 2019-10-27 19:50:40 0 touched-at-20191027195007
9 2019-10-27 19:50:40 0 touched-at-20191027195008
10 2019-10-27 19:51:10 0 touched-at-20191027195009
11 2019-10-27 19:51:10 0 touched-at-20191027195011
12 2019-10-27 19:51:10 0 touched-at-20191027195012
13 2019-10-27 19:51:10 0 touched-at-20191027195013
14 2019-10-27 19:51:10 0 touched-at-20191027195014
15 2019-10-27 19:51:10 0 touched-at-20191027195016
16 2019-10-27 19:51:10 0 touched-at-20191027195017
17 2019-10-27 19:51:10 0 touched-at-20191027195018
18 2019-10-27 19:51:10 0 touched-at-20191027195020
19 2019-10-27 19:51:10 0 touched-at-20191027195021
20 2019-10-27 19:51:10 0 touched-at-20191027195022
21 2019-10-27 19:51:10 0 touched-at-20191027195024Outro problema que vale a pena mencionar:depois de brincar com várias configurações, criar e destruir gateways e compartilhamentos, em algum momento ao tentar ativar um gateway de arquivos, estava recebendo um erro interno:
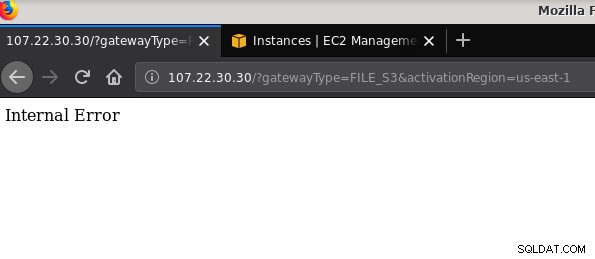
A linha de comando fornece mais alguns detalhes, embora não aponte para nenhum problema:
~$ curl -sv "https://107.22.30.30/?gatewayType=FILE_S3&activationRegion=us-east-1"
* Trying 107.22.30.30:80...
* TCP_NODELAY set
* Connected to 107.22.30.30 (107.22.30.30) port 80 (#0)
> GET /?gatewayType=FILE_S3&activationRegion=us-east-1 HTTP/1.1
> Host: 107.22.30.30
> User-Agent: curl/7.65.3
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 500 Internal Server Error
< Date: Mon, 28 Oct 2019 06:33:30 GMT
< Content-type: text/html
< Content-length: 14
<
* Connection #0 to host 107.22.30.30 left intact
Internal Error~ $Esta postagem no fórum apontou que meu problema pode ter algo a ver com o VPC Endpoint que criei. Minha correção foi excluir o VPC endpoint que eu configurei durante várias execuções de tentativa e erro de iSCSI.
Enquanto o S3 criptografa dados em repouso, o tráfego de fios NFS é texto simples. A saber, aqui está um dump de pacote tcpdump:
23:47:12.225273 IP 192.168.0.11.936 > 107.22.30.30.2049: Flags [P.], seq 2665:3377, ack 2929, win 501, options [nop,nop,TS val 1899459538 ecr 38013066], length 712: NFS request xid 3511704119 708 getattr fh 0,2/53
example@sqldat.com@.......k....... ...c..............
q7s..D.......PZ7...........................4........omiday.can.local...................................................5.......]...........!....................C...
..............&...........]....................# inittab is no longer used.
#
# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target
#
# systemd uses 'targets' instead of runlevels. By default, there are two main targets:
#
# multi-user.target: analogous to runlevel 3
# graphical.target: analogous to runlevel 5
#
# To view current default target, run:
# systemctl get-default
#
# To set a default target, run:
# systemctl set-default TARGET.target
..... .........0..
23:47:12.331592 IP 107.22.30.30.2049 > 192.168.0.11.936: Flags [P.], seq 2929:3109, ack 3377, win 514, options [nop,nop,TS val 38013174 ecr 1899459538], length 180: NFS reply xid 3511704119 reply ok 176 getattr NON 4 ids 0/33554432 sz -2138196387Até que este rascunho do IEE seja aprovado, a única opção segura para se conectar de fora da AWS é usando um túnel VPN. Isso complica a configuração, tornando a opção de NFS local menos atraente do que as ferramentas baseadas em FUSE que discutirei um pouco mais adiante.
iSCSI
Esta opção é fornecida pelo serviço AWS Storage Gateway Volume. Depois que o serviço estiver configurado, vá para a seção de configuração do cliente Linux iSCSI.
A vantagem de usar iSCSI sobre NFS consiste na capacidade de aproveitar os serviços de backup, clonagem e snapshot nativos da nuvem da Amazon. Para obter detalhes e instruções passo a passo, siga os links para AWS Backup, Volume Cloning e EBS Snapshots
Embora haja muitas vantagens, há uma restrição importante que provavelmente afastará muitos usuários:não é possível acessar o gateway por meio de seu endereço IP público. Assim, assim como a opção NFS, esse requisito adiciona complexidade à configuração.
Apesar da clara limitação e convencido de que não conseguirei concluir esta configuração, ainda queria ter uma ideia de como é feito. O assistente redireciona para uma tela de configuração do AWS Marketplace.
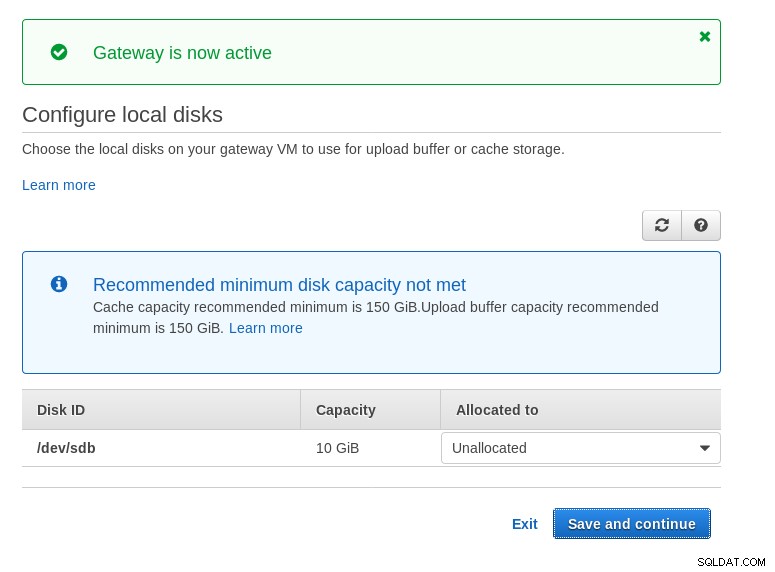
Observe que o assistente do Marketplace cria um disco secundário, mas não grande o suficiente em size e, portanto, ainda precisamos adicionar os dois volumes necessários, conforme indicado pelas instruções de configuração do host. Se os requisitos de armazenamento não forem atendidos, o assistente bloqueará na tela de configuração de discos locais:
Aqui está um vislumbre da tela de configuração do Amazon Marketplace:
Existe uma interface de texto acessível via SSH (faça login como usuário sguser) que fornece ferramentas básicas de solução de problemas de rede e outras opções de configuração que não podem ser executadas por meio da GUI da web:
~ $ ssh example@sqldat.com
Warning: Permanently added 'ec2-3-231-96-109.compute-1.amazonaws.com,3.231.96.109' (ECDSA) to the list of known hosts.
'screen.xterm-256color': unknown terminal type.
AWS Storage Gateway Configuration
#######################################################################
## Currently connected network adapters:
##
## eth0: 172.31.1.185
#######################################################################
1: SOCKS Proxy Configuration
2: Test Network Connectivity
3: Gateway Console
4: View System Resource Check (0 Errors)
0: Stop AWS Storage Gateway
Press "x" to exit session
Enter command:E alguns outros pontos importantes:
- Ao contrário da configuração do NFS, não há acesso direto ao armazenamento do S3, conforme observado na seção de perguntas frequentes do Volume Gateway.
- A documentação da AWS insiste em personalizar as configurações de iSCSI para melhorar o desempenho e a segurança da conexão.
FUSO
Nesta categoria, listei as ferramentas baseadas em FUSE que fornecem uma compatibilidade S3 mais completa em comparação com as ferramentas de backup PostgreSQL e, em contraste com o Amazon Storage Gateway, permitem transferências de dados de um host local para o Amazon S3 sem configuração adicional. Essa configuração pode fornecer armazenamento S3 como um sistema de arquivos local que as ferramentas de backup do PostgreSQL podem usar para aproveitar recursos como o pg_dump paralelo.
s3fs-fuse
s3fs-fuse é escrito em C++, uma linguagem compatível com o kit de ferramentas do Amazon S3 SDK e, como tal, é adequado para implementar recursos avançados do S3, como multipart uploads, armazenamento em cache, classe de armazenamento S3, servidor- criptografia lateral e seleção de região. Também é altamente compatível com POSIX.
O aplicativo está incluído no meu Fedora 30 tornando a instalação simples.
Para testar:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m35.761s
user 0m16.122s
sys 0m2.228s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 03:16:03 79110010 test.pg_dump-20191028-031535.gzObserve que a velocidade é um pouco mais lenta do que usar o Amazon Storage Gateway com a opção NFS. Ele compensa o desempenho inferior fornecendo um sistema de arquivos altamente compatível com POSIX.
S3QL
S3QL fornece recursos do S3, como classe de armazenamento e criptografia do lado do servidor. Os muitos recursos são descritos na documentação exaustiva do S3QL, no entanto, se você estiver procurando por upload em várias partes, isso não será mencionado em nenhum lugar. Isso ocorre porque o S3QL implementa seu próprio algoritmo de divisão de arquivos para fornecer o recurso de eliminação de duplicação. Todos os arquivos são divididos em blocos de 10 MB.
A instalação em um sistema baseado em Red Hat é simples:instale as dependências RPM necessárias via yum:
sqlite-devel-3.7.17-8.14.amzn1.x86_64
fuse-devel-2.9.4-1.18.amzn1.x86_64
fuse-2.9.4-1.18.amzn1.x86_64
system-rpm-config-9.0.3-42.28.amzn1.noarch
python36-devel-3.6.8-1.14.amzn1.x86_64
kernel-headers-4.14.146-93.123.amzn1.x86_64
glibc-headers-2.17-260.175.amzn1.x86_64
glibc-devel-2.17-260.175.amzn1.x86_64
gcc-4.8.5-1.22.amzn1.noarch
gcc48-4.8.5-28.142.amzn1.x86_64
mpfr-3.1.1-4.14.amzn1.x86_64
libmpc-1.0.1-3.3.amzn1.x86_64
libgomp-6.4.1-1.45.amzn1.x86_64
libgcc48-4.8.5-28.142.amzn1.x86_64
cpp48-4.8.5-28.142.amzn1.x86_64
python36-pip-9.0.3-1.26.amzn1.noarch
python36-libs-3.6.8-1.14.amzn1.x86_64
python36-3.6.8-1.14.amzn1.x86_64
python36-setuptools-36.2.7-1.33.amzn1.noarchEm seguida, instale as dependências do Python usando pip3:
pip-3.6 install setuptools cryptography defusedxml apsw dugong pytest requests llfuse==1.3.6Uma característica notável dessa ferramenta é o sistema de arquivos S3QL criado sobre o bucket do S3.
Patetas
goofys é uma opção quando o desempenho supera a conformidade com POSIX. Seus objetivos são o oposto do s3fs-fuse. O foco na velocidade também se reflete no modelo de distribuição. Para Linux existem binários pré-construídos. Depois de baixado execute:
~/temp/goofys $ ./goofys s9s-postgresql-backup ~/mnt/s9s/E backup:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m27.427s
user 0m15.962s
sys 0m2.169s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 04:29:05 79110010 test.pg_dump-20191028-042902.gzObserve que o tempo de criação do objeto no S3 está a apenas 3 segundos do registro de data e hora do arquivo.
ObjectFS
O ObjectFS parece ter sido mantido até cerca de 6 meses atrás. Uma verificação de upload em várias partes revela que ele não está implementado. No artigo de pesquisa do autor, aprendemos que o sistema ainda está em desenvolvimento e, como o artigo foi lançado em 2019, achei que valeria a pena mencioná-lo.
Clientes S3
Como mencionado anteriormente, para usar a AWS S3 CLI, precisamos levar em consideração vários aspectos específicos do armazenamento de objetos em geral e do Amazon S3 em particular. Se o único requisito for a capacidade de transferir dados para dentro e para fora do armazenamento do S3, uma ferramenta que siga de perto as recomendações do Amazon S3 poderá fazer o trabalho.
s3cmd é uma das ferramentas que resistiram ao teste do tempo. Este blog do Open BI de 2010 fala sobre isso, em uma época em que o S3 era o novo garoto do pedaço.
Recursos notáveis:
- criptografia do lado do servidor
- uploads automáticos em várias partes
- limitação da largura de banda
Dirija-se ao S3cmd:FAQ e Knowledge Base para obter mais informações.
Conclusão
As opções disponíveis para fazer backup de um cluster PostgreSQL para o Amazon S3 diferem nos métodos de transferência de dados e como eles se alinham às estratégias do Amazon S3.
O AWS Storage Gateway complementa o armazenamento de objetos S3 da Amazon, ao custo de maior complexidade e conhecimento adicional necessário para aproveitar ao máximo esse serviço. Por exemplo, selecionar o número correto de discos requer um planejamento cuidadoso e uma boa compreensão dos custos relacionados ao S3 da Amazon é essencial para minimizar os custos operacionais.
Embora aplicável a qualquer armazenamento em nuvem, não apenas ao Amazon S3, a decisão de armazenar os dados em uma nuvem pública tem implicações de segurança. O Amazon S3 fornece criptografia para dados em repouso e dados em trânsito, sem garantia de conhecimento zero ou sem provas de conhecimento. As organizações que desejam ter controle total sobre seus dados devem implementar a criptografia do lado do cliente e armazenar as chaves de criptografia fora de sua infraestrutura da AWS.
Para alternativas comerciais ao mapeamento do S3 para um sistema de arquivos local, vale a pena conferir os produtos da ObjectiveFS ou NetApp.
Por fim, as organizações que buscam desenvolver suas próprias ferramentas de backup, seja com base na base fornecida por muitos aplicativos de código aberto, ou começando do zero, devem considerar o uso do teste de compatibilidade S3, disponibilizado pelo projeto Ceph.