Você já deve ter ouvido falar do termo “failover” no contexto da replicação do MySQL. Talvez você tenha se perguntado o que é isso ao iniciar sua aventura com bancos de dados. Talvez você saiba o que é, mas não tem certeza sobre possíveis problemas relacionados a ele e como eles podem ser resolvidos?
Nesta postagem do blog, tentaremos fornecer uma introdução ao tratamento de failover no MySQL e no MariaDB.
Discutiremos o que é o failover, por que é inevitável, qual é a diferença entre failover e switchover. Discutiremos o processo de failover na forma mais genérica. Também abordaremos um pouco diferentes questões com as quais você terá que lidar em relação ao processo de failover.
O que significa "failover"?
A replicação do MySQL é um coletivo de nós, cada um deles pode servir a uma função de cada vez. Pode se tornar um mestre ou uma réplica. Há apenas um nó mestre em um determinado momento. Esse nó recebe tráfego de gravação e replica as gravações em suas réplicas.
Como você pode imaginar, sendo um único ponto de entrada de dados no cluster de replicação, o nó mestre é muito importante. O que aconteceria se tivesse falhado e se tornado indisponível?
Esta é uma condição bastante séria para um cluster de replicação. Ele não pode aceitar nenhuma gravação em um determinado momento. Como você pode esperar, uma das réplicas terá que assumir as tarefas do mestre e começar a aceitar gravações. O restante da topologia de replicação também pode ter que ser alterado - as réplicas restantes devem alterar seu mestre do nó antigo e com falha para o novo escolhido. Esse processo de “promoção” de uma réplica para se tornar mestre após a falha do antigo mestre é chamado de “failover”.
Por outro lado, a “troca” acontece quando o usuário aciona a promoção da réplica. Um novo mestre é promovido a partir de uma réplica apontada pelo usuário e o antigo mestre, normalmente, torna-se uma réplica para o novo mestre.
A diferença mais importante entre “failover” e “switchover” é o estado do antigo mestre. Quando um failover é executado, o antigo mestre fica, de alguma forma, inacessível. Pode ter travado, pode ter sofrido um particionamento de rede. Ele não pode ser usado em um determinado momento e seu estado é, normalmente, desconhecido.
Por outro lado, quando uma transição é realizada, o antigo mestre está vivo e bem. Isso tem consequências graves. Se um mestre estiver inacessível, isso pode significar que alguns dos dados ainda não foram enviados aos escravos (a menos que a replicação semi-síncrona tenha sido usada). Alguns dos dados podem ter sido corrompidos ou enviados parcialmente.
Existem mecanismos para evitar a propagação de tais corrupções nos escravos, mas o ponto é que alguns dos dados podem ser perdidos no processo. Por outro lado, ao realizar uma alternância, o antigo mestre fica disponível e a consistência dos dados é mantida.
Processo de failover
Vamos passar algum tempo discutindo como exatamente o processo de failover se parece.
A falha principal foi detectada
Para começar, um mestre precisa travar antes que o failover seja executado. Quando não estiver disponível, um failover será acionado. Até agora, parece simples, mas a verdade é que já estamos em terreno escorregadio.
Em primeiro lugar, como o master health é testado? É testado a partir de um local ou os testes são distribuídos? O software de gerenciamento de failover apenas tenta se conectar ao mestre ou implementa verificações mais avançadas antes que a falha do mestre seja declarada?
Vamos imaginar a seguinte topologia:
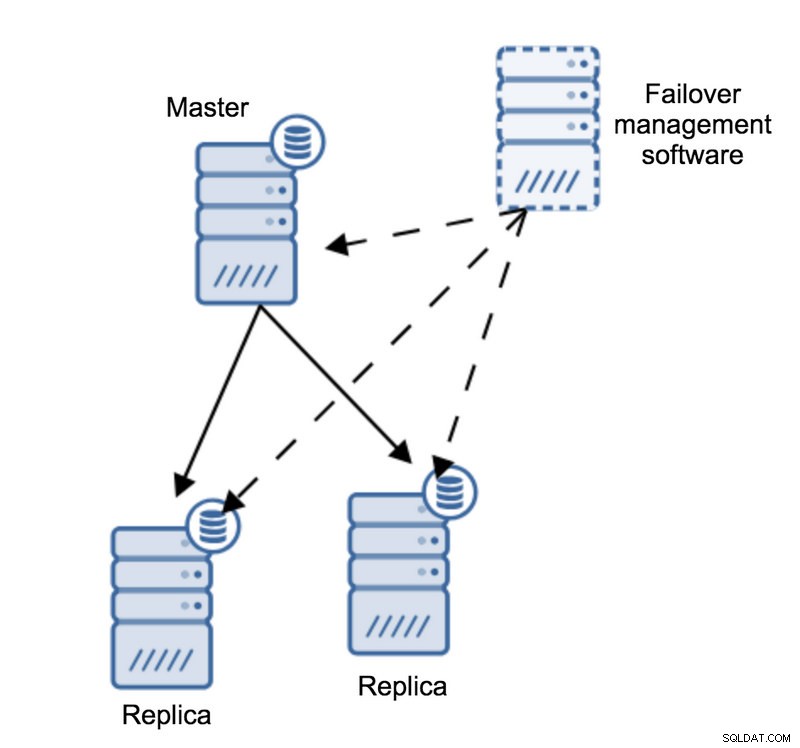
Temos uma master e duas réplicas. Também temos um software de gerenciamento de failover localizado em algum host externo. O que aconteceria se uma conexão de rede entre o host com software de failover e o mestre falhasse?
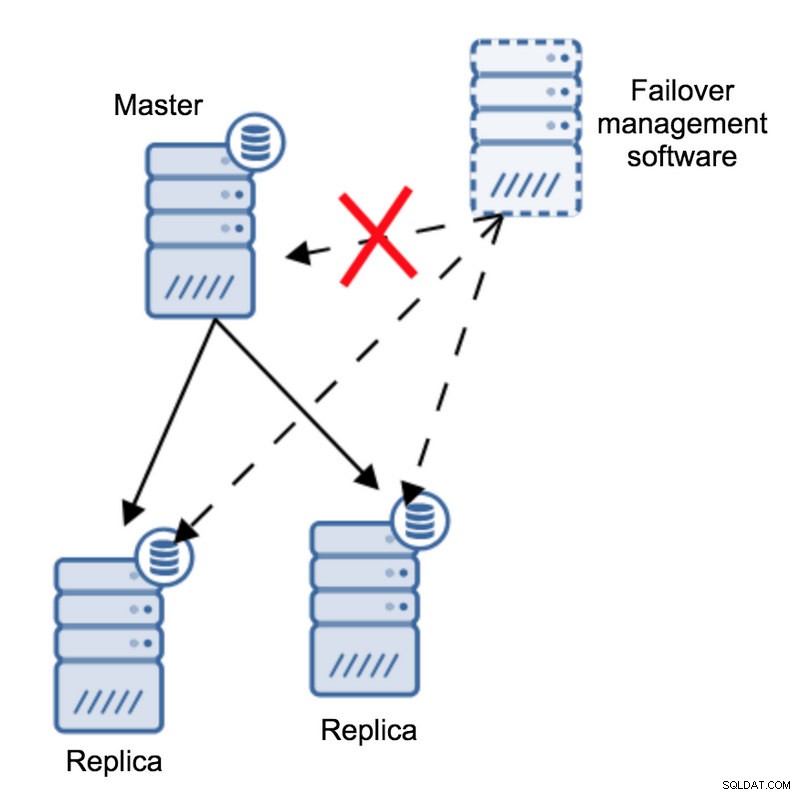
De acordo com o software de gerenciamento de failover, o mestre travou - não há conectividade com ele. Ainda assim, a replicação em si está funcionando bem. O que deveria acontecer aqui é que o software de gerenciamento de failover tentaria se conectar às réplicas e ver qual é o ponto de vista delas.
Eles reclamam de uma replicação quebrada ou estão replicando alegremente?
As coisas podem se tornar ainda mais complexas. E se adicionarmos um proxy (ou um conjunto de proxies)? Ele será usado para rotear o tráfego - gravações no mestre e leituras nas réplicas. E se um proxy não puder acessar o mestre? E se nenhum dos proxies puder acessar o mestre?
Isso significa que o aplicativo não pode funcionar nessas condições. O failover (na verdade, seria mais uma alternância, pois o mestre está tecnicamente ativo) deve ser acionado?
Tecnicamente, o mestre está ativo, mas não pode ser usado pelo aplicativo. Aqui, a lógica de negócios deve entrar e uma decisão deve ser tomada.
Evitando que o velho mestre corra
Não importa como e por que, se houver a decisão de promover uma das réplicas para se tornar um novo mestre, o antigo mestre deve ser interrompido e, idealmente, não deve ser iniciado novamente.
Como isso pode ser alcançado depende dos detalhes do ambiente específico; portanto, essa parte do processo de failover geralmente é reforçada por scripts externos integrados ao processo de failover por meio de diferentes ganchos.
Esses scripts podem ser projetados para usar ferramentas disponíveis no ambiente específico para interromper o antigo mestre. Pode ser uma chamada de CLI ou API que interromperá uma VM; pode ser um código shell que executa comandos por meio de algum tipo de dispositivo de “gerenciamento de luzes apagadas”; pode ser um script que envia traps SNMP para a Unidade de Distribuição de Energia que desativa as tomadas que o antigo mestre está usando (sem energia elétrica podemos ter certeza que não irá reiniciar).
Se um software de gerenciamento de failover for parte de um produto mais complexo, que também trata da recuperação de nós (como é o caso do ClusterControl), o mestre antigo pode ser marcado como excluído das rotinas de recuperação.
Você pode se perguntar por que é tão importante evitar que o antigo mestre fique disponível mais uma vez?
O principal problema é que nas configurações de replicação, apenas um nó pode ser usado para gravações. Normalmente, você garante isso habilitando uma variável read_only (e super_read_only, se aplicável) em todas as réplicas e mantendo-a desabilitada apenas no mestre.
Uma vez que um novo mestre é promovido, ele terá somente leitura desabilitado. O problema é que, se o mestre antigo não estiver disponível, não podemos alterá-lo para read_only=1. Se o MySQL ou um host travar, isso não é um grande problema, pois as boas práticas são ter my.cnf configurado com essa configuração, então, uma vez que o MySQL é iniciado, ele sempre inicia no modo somente leitura.
O problema aparece quando não é uma falha, mas um problema de rede. O antigo mestre ainda está em execução com read_only desabilitado, mas não está disponível. Quando as redes convergirem, você terminará com dois nós graváveis. Isso pode ou não ser um problema. Alguns dos proxies usam a configuração read_only como um indicador se um nó é um mestre ou uma réplica. Dois mestres aparecendo em um determinado momento podem resultar em um grande problema, pois os dados são gravados em ambos os hosts, mas as réplicas recebem apenas metade do tráfego de gravação (a parte que atinge o novo mestre).
Às vezes, trata-se de configurações codificadas em alguns dos scripts que são configurados para se conectar apenas a um determinado host. Normalmente eles falhariam e alguém perceberia que o mestre mudou.
Com o antigo mestre disponível, eles se conectarão com prazer a ele e a discrepância de dados surgirá. Como você pode ver, garantir que o antigo mestre não inicie é um item de alta prioridade.
Decidir sobre um candidato a mestre
O antigo mestre está caído e não retornará de seu túmulo, agora é hora de decidir qual host devemos usar como novo mestre. Normalmente, há mais de uma réplica para escolher, então uma decisão deve ser tomada. Há muitas razões pelas quais uma réplica pode ser escolhida em detrimento de outra, portanto, as verificações devem ser executadas.
Listas brancas e listas negras
Para começar, uma equipe que gerencia bancos de dados pode ter seus motivos para escolher uma réplica em vez de outra ao decidir sobre um candidato mestre. Talvez esteja usando um hardware mais fraco ou tenha algum trabalho específico atribuído a ele (essa réplica executa backup, consultas analíticas, os desenvolvedores têm acesso a ele e executam consultas personalizadas e feitas à mão). Talvez seja uma réplica de teste onde uma nova versão esteja passando por testes de aceitação antes de prosseguir com a atualização. A maioria dos softwares de gerenciamento de failover oferece suporte a listas brancas e negras, que podem ser utilizadas para definir com precisão quais réplicas devem ou não ser usadas como candidatos mestres.
Replicação semi-síncrona
Uma configuração de replicação pode ser uma mistura de réplicas assíncronas e semi-síncronas. Há uma grande diferença entre eles - a réplica semi-síncrona é garantida para conter todos os eventos do mestre. Uma réplica assíncrona pode não ter recebido todos os dados, portanto, o failover para ela pode resultar em perda de dados. Preferimos ver réplicas semi-síncronas a serem promovidas.
Atraso de replicação
Mesmo que uma réplica semi-síncrona contenha todos os eventos, esses eventos ainda podem residir apenas em logs de retransmissão. Com tráfego intenso, todas as réplicas, não importa se semi-síncronas ou assíncronas, podem apresentar atraso.
O problema com o atraso de replicação é que, ao promover uma réplica, você deve redefinir as configurações de replicação para que ela não tente se conectar ao mestre antigo. Isso também removerá todos os logs de retransmissão, mesmo que ainda não tenham sido aplicados - o que leva à perda de dados.
Mesmo que você não redefina as configurações de replicação, você ainda não poderá abrir um novo mestre para conexões se ele não tiver aplicado todos os eventos de seu log de retransmissão. Caso contrário, você correrá o risco de que as novas consultas afetem as transações do log de retransmissão, desencadeando todos os tipos de problemas (por exemplo, um aplicativo pode remover algumas linhas que são acessadas por transações do log de retransmissão).
Levando tudo isso em consideração, a única opção segura é esperar que o log de retransmissão seja aplicado. Ainda assim, pode demorar um pouco se a réplica estiver muito atrasada. Decisões devem ser feitas sobre qual réplica seria um mestre melhor - assíncrono, mas com pequeno atraso ou semi-síncrono, mas com atraso que exigiria uma quantidade significativa de tempo para aplicar.
Transações erradas
Mesmo que as réplicas não devam ser gravadas, ainda pode acontecer que alguém (ou algo) tenha escrito nelas.
Pode ter sido apenas uma única forma de transação no passado, mas ainda pode ter um efeito sério na capacidade de realizar um failover. O problema está estritamente relacionado ao Global Transaction ID (GTID), um recurso que atribui um ID distinto a cada transação executada em um determinado nó MySQL.
Hoje em dia é uma configuração bastante popular, pois traz grandes níveis de flexibilidade e permite melhor desempenho (com réplicas multi-thread).
O problema é que, ao reescravizar para um novo mestre, a replicação do GTID exige que todos os eventos desse mestre (que não foram executados na réplica) sejam replicados para a réplica.
Vamos considerar o seguinte cenário:em algum momento no passado, ocorreu uma gravação em uma réplica. Foi há muito tempo e esse evento foi removido dos logs binários da réplica. Em algum momento, um mestre falhou e a réplica foi nomeada como um novo mestre. Todas as réplicas restantes serão escravizadas do novo mestre. Eles perguntarão sobre as transações executadas no novo mestre. Ele responderá com uma lista de GTIDs que vieram do antigo mestre e o único GTID relacionado a essa gravação antiga. Os GTIDs do mestre antigo não são um problema, pois todas as réplicas restantes contêm pelo menos a maioria deles (se não todos) e todos os eventos ausentes devem ser recentes o suficiente para estarem disponíveis nos logs binários do novo mestre.
Na pior das hipóteses, alguns eventos ausentes serão lidos dos logs binários e transferidos para réplicas. O problema é com essa gravação antiga - aconteceu apenas em um novo mestre, enquanto ainda era uma réplica, portanto, não existe nos hosts restantes. É um evento antigo, portanto, não há como recuperá-lo de logs binários. Como resultado, nenhuma das réplicas poderá escravizar o novo mestre. A única solução aqui é realizar uma ação manual e injetar um evento vazio com esse GTID problemático em todas as réplicas. Isso também significa que, dependendo do que aconteceu, as réplicas podem não estar sincronizadas com o novo mestre.
Como você pode ver, é muito importante rastrear transações errôneas e determinar se é seguro promover uma determinada réplica para se tornar um novo mestre. Se contiver transações errôneas, pode não ser a melhor opção.
Tratamento de failover para o aplicativo
É crucial ter em mente que a chave mestre, forçada ou não, afeta toda a topologia. As gravações devem ser redirecionadas para um novo nó. Isso pode ser feito de várias maneiras e é fundamental garantir que essa alteração seja o mais transparente possível para o aplicativo. Nesta seção, veremos alguns dos exemplos de como o failover pode se tornar transparente para o aplicativo.
DNS
Uma das maneiras pelas quais um aplicativo pode ser apontado para um mestre é utilizando entradas DNS. Com TTL baixo, é possível alterar o endereço IP para o qual uma entrada DNS, como ‘master.dc1.example.com’ aponta. Essa alteração pode ser feita por meio de scripts externos executados durante o processo de failover.
Descoberta de serviço
Ferramentas como Consul ou etc.d também podem ser usadas para direcionar o tráfego para um local correto. Essas ferramentas podem conter informações de que o IP do mestre atual está definido para algum valor. Alguns deles também oferecem a capacidade de usar pesquisas de nome de host para apontar para um IP correto. Novamente, as entradas nas ferramentas de descoberta de serviço precisam ser mantidas e uma das maneiras de fazer isso é fazer essas alterações durante o processo de failover, usando ganchos executados em diferentes estágios do failover.
Procurado
Os proxies também podem ser usados como fonte de verdade sobre a topologia. De um modo geral, não importa como eles descobrem a topologia (pode ser um processo automático ou o proxy precisa ser reconfigurado quando a topologia muda), eles devem conter o estado atual da cadeia de replicação, caso contrário não seriam capazes de roteie as consultas corretamente.
A abordagem de usar um proxy como fonte de verdade pode ser bastante comum em conjunto com a abordagem de colocar proxies em hosts de aplicativos. Existem inúmeras vantagens em colocar servidores proxy e web:comunicação rápida e segura usando soquete Unix, mantendo uma camada de cache (já que alguns dos proxies, como o ProxySQL também podem fazer o cache) próximo ao aplicativo. Nesse caso, faz sentido que o aplicativo apenas se conecte ao proxy e assuma que ele roteará as consultas corretamente.
Failover no ClusterControl
O ClusterControl aplica as melhores práticas do setor para garantir que o processo de failover seja executado corretamente. Ele também garante que o processo será seguro - as configurações padrão destinam-se a abortar o failover se possíveis problemas forem detectados. Essas configurações podem ser substituídas pelo usuário caso ele queira priorizar o failover sobre a segurança dos dados.
Depois que uma falha mestre é detectada pelo ClusterControl, um processo de failover é iniciado e um primeiro gancho de failover é executado imediatamente:

Em seguida, a disponibilidade do mestre é testada.

O ClusterControl faz testes extensivos para garantir que o mestre esteja realmente indisponível. Esse comportamento é habilitado por padrão e é gerenciado pela seguinte variável:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.A seguir, o ClusterControl garante que o antigo mestre esteja inativo e, caso contrário, o ClusterControl não tentará recuperá-lo:

O próximo passo é determinar qual host pode ser usado como candidato mestre. O ClusterControl verifica se uma lista branca ou uma lista negra está definida.
Você pode fazer isso usando as seguintes variáveis no arquivo de configuração cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Também é possível configurar o ClusterControl para procurar diferenças nos filtros de log binários em todas as réplicas. Isso pode ser feito usando a variável replication_check_binlog_filtration_bf_failover. Por padrão, essas verificações estão desabilitadas. O ClusterControl também verifica se não há transações errôneas, o que pode causar problemas.

Você também pode pedir ao ClusterControl para reconstruir automaticamente as réplicas que não podem replicar do novo mestre usando a seguinte configuração no arquivo de configuração cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Em seguida, um segundo script é executado:ele é definido na configuração replication_pre_failover_script. Em seguida, o candidato passa por um processo de preparação.


O ClusterControl aguarda a aplicação dos redo logs (garantindo que a perda de dados seja mínima). Ele também verifica se há outras transações disponíveis nas réplicas restantes, que não foram aplicadas ao candidato mestre. Ambos os comportamentos podem ser controlados pelo usuário, usando as seguintes configurações no arquivo de configuração cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Como você pode ver, você pode forçar um failover mesmo que nem todos os eventos de redo log tenham sido aplicados - isso permite que o usuário decida o que tem a prioridade mais alta - consistência de dados ou velocidade de failover.


Finalmente, o mestre é eleito e o último script é executado (um script que pode ser definido como replication_post_failover_script.
Se você ainda não experimentou o ClusterControl, recomendo que faça o download (é grátis) e experimente.
Detecção de mestre no ClusterControl
O ClusterControl oferece a capacidade de implantar uma pilha completa de alta disponibilidade, incluindo camadas de banco de dados e proxy. A descoberta do mestre é sempre uma das questões a serem tratadas.
Como funciona no ClusterControl?
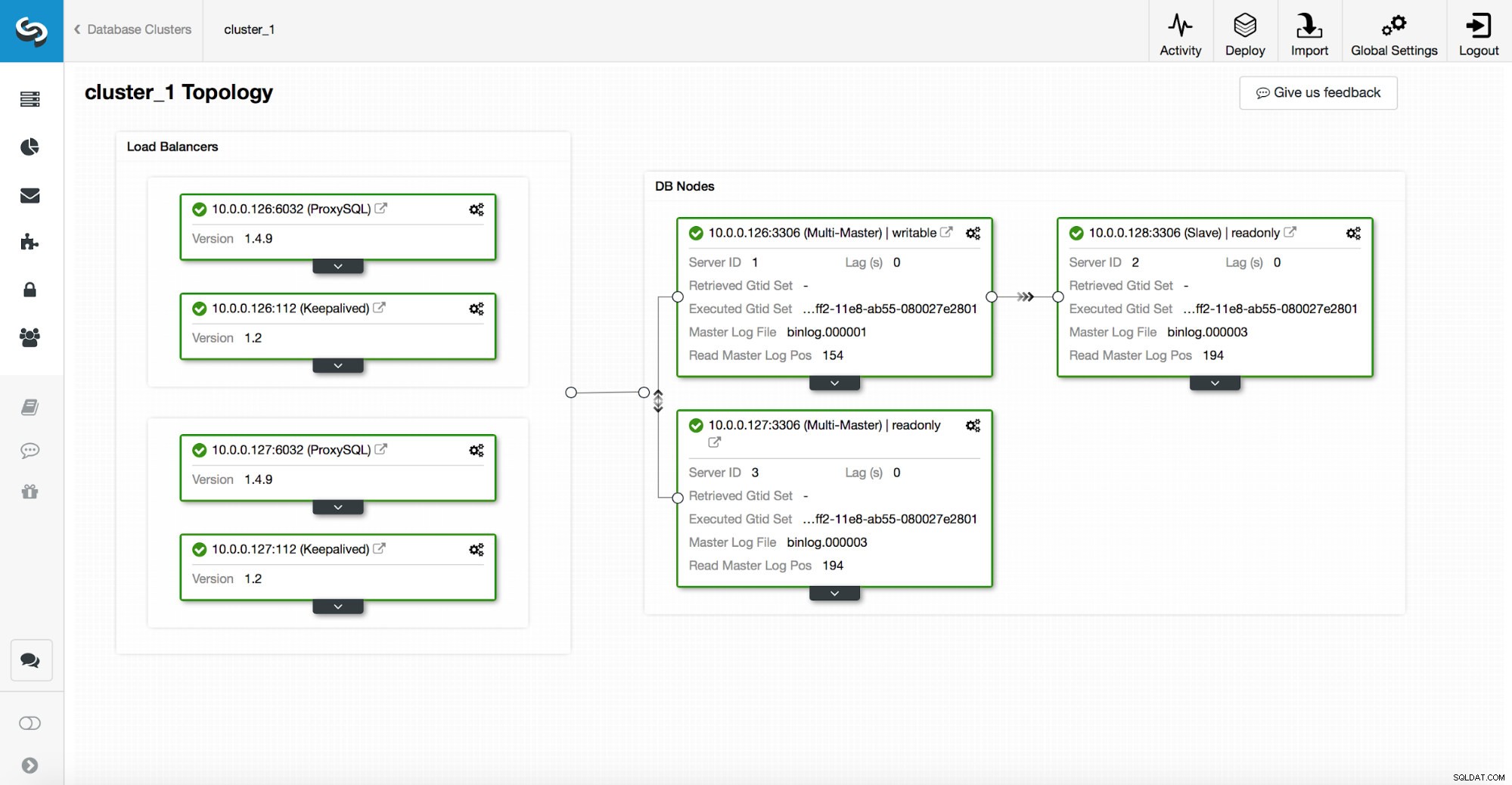
Uma pilha de alta disponibilidade, implantada por meio do ClusterControl, consiste em três partes:
- camada de banco de dados
- camada proxy que pode ser HAProxy ou ProxySQL
- camada keepalived, que, com uso de IP Virtual, garante alta disponibilidade da camada proxy
Os proxies dependem de variáveis read_only nos nós.
Como você pode ver na captura de tela acima, apenas um nó na topologia está marcado como “gravável”. Este é o mestre e este é o único nó que receberá gravações.
Um proxy (neste exemplo, ProxySQL) monitorará essa variável e se reconfigurará automaticamente.
Do outro lado dessa equação, o ClusterControl cuida das alterações de topologia:failovers e alternâncias. Ele fará as alterações necessárias no valor read_only para refletir o estado da topologia após a alteração. Se um novo mestre for promovido, ele se tornará o único nó gravável. Se um mestre for eleito após o failover, ele terá somente leitura desabilitado.
No topo da camada de proxy, o keepalived é implantado. Ele implanta um VIP e monitora o estado dos nós de proxy subjacentes. O VIP aponta para um nó proxy em um determinado momento. Se esse nó ficar inativo, o IP virtual será redirecionado para outro nó, garantindo que o tráfego direcionado ao VIP chegue a um nó proxy íntegro.
Para resumir, um aplicativo se conecta ao banco de dados usando o endereço IP virtual. Este IP aponta para um dos proxies. Os proxies redirecionam o tráfego de acordo com a estrutura da topologia. As informações sobre a topologia são derivadas do estado read_only. Esta variável é gerenciada pelo ClusterControl e é definida com base nas alterações de topologia solicitadas pelo usuário ou no ClusterControl realizadas automaticamente.