A replicação é uma das maneiras mais comuns de obter alta disponibilidade para MySQL e MariaDB. Tornou-se muito mais robusto com a adição de GTIDs e é exaustivamente testado por milhares e milhares de usuários. A replicação do MySQL não é uma propriedade de 'definir e esquecer', porém, ela precisa ser monitorada para possíveis problemas e mantida para que permaneça em boa forma. Nesta postagem do blog, gostaríamos de compartilhar algumas dicas e truques sobre como manter, solucionar e corrigir problemas com a replicação do MySQL.
Como determinar se a replicação do MySQL está em boas condições?
Esta é de longe a habilidade mais importante que qualquer pessoa que cuida de uma configuração de replicação do MySQL deve possuir. Vamos dar uma olhada em onde procurar informações sobre o estado de replicação. Há uma pequena diferença entre MySQL e MariaDB e discutiremos isso também.
MOSTRAR STATUS DE ESCRAVO
Este é de longe o método mais comum de verificar o estado de replicação em um host escravo - está conosco desde sempre e geralmente é o primeiro lugar para onde vamos se esperamos que haja algum problema com a replicação.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Alguns detalhes podem diferir entre MySQL e MariaDB, mas a maioria do conteúdo terá a mesma aparência. As alterações serão visíveis na seção GTID, pois o MySQL e o MariaDB o fazem de maneira diferente. A partir de SHOW SLAVE STATUS, você pode derivar algumas informações - qual mestre é usado, qual usuário e qual porta é usada para se conectar ao mestre. Temos alguns dados sobre a posição atual do log binário (não é mais tão importante, pois podemos usar o GTID e esquecer os logs binários) e o estado dos threads de replicação SQL e I/O. Então você pode ver se e como a filtragem está configurada. Você também pode encontrar algumas informações sobre erros, atraso de replicação, configurações de SSL e GTID. O exemplo acima vem do MySQL 5.7 slave que está em um estado saudável. Vamos dar uma olhada em alguns exemplos em que a replicação é interrompida.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Este exemplo foi retirado do MariaDB 10.1, você pode ver as alterações na parte inferior da saída para fazê-lo funcionar com os GTIDs do MariaDB. O que é importante para nós é o erro - você pode ver que algo não está certo no thread SQL:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Discutiremos esse problema específico mais tarde, por enquanto basta que você veja como verificar se há algum erro na replicação usando SHOW SLAVE STATUS.
Outra informação importante que vem de SHOW SLAVE STATUS é - o quanto nosso escravo está atrasado. Você pode conferir na coluna “Seconds_Behind_Master”. Essa métrica é especialmente importante para rastrear se você souber que seu aplicativo é sensível quando se trata de leituras obsoletas.
No ClusterControl você pode acompanhar esses dados na seção “Visão geral”:
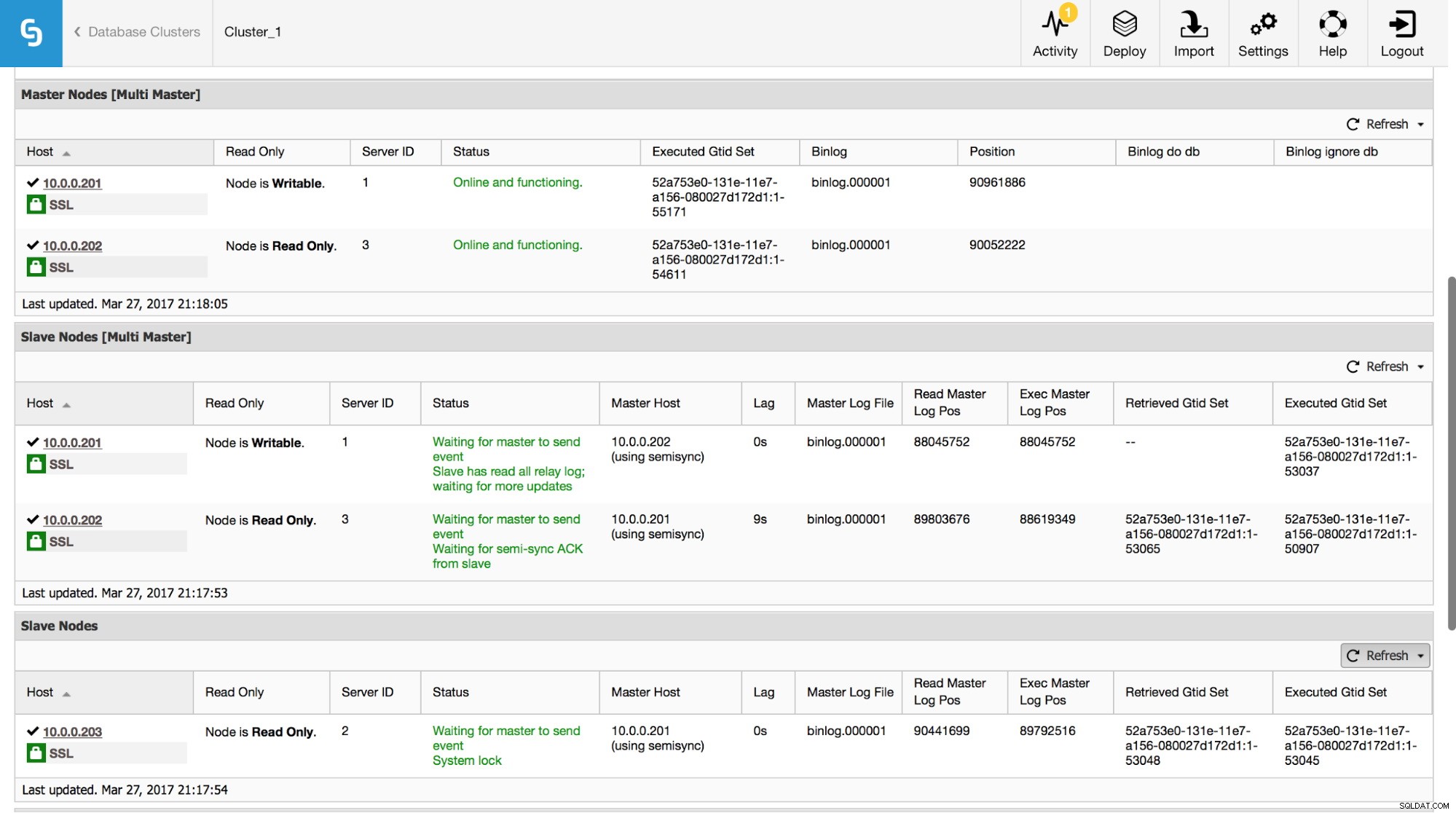
Tornamos visíveis todas as informações mais importantes do comando SHOW SLAVE STATUS. Você pode verificar o status da replicação, quem é o mestre, se há um atraso de replicação ou não, as posições do log binário. Você também pode encontrar GTIDs recuperados e executados.
Esquema de desempenho
Outro local onde você pode procurar as informações sobre replicação é o performance_schema. Isso se aplica apenas ao MySQL 5.7 da Oracle - versões anteriores e o MariaDB não coleta esses dados.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Abaixo você encontra alguns exemplos de dados disponíveis em algumas dessas tabelas.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Como você pode ver, podemos verificar o estado da replicação, último erro, conjunto de transações recebido e mais alguns dados. O que é importante - se você ativou a replicação multithread, na tabela replication_applier_status_by_worker, você verá o estado de cada trabalhador - isso ajuda a entender o estado da replicação para cada um dos segmentos de trabalho.
Atraso de replicação
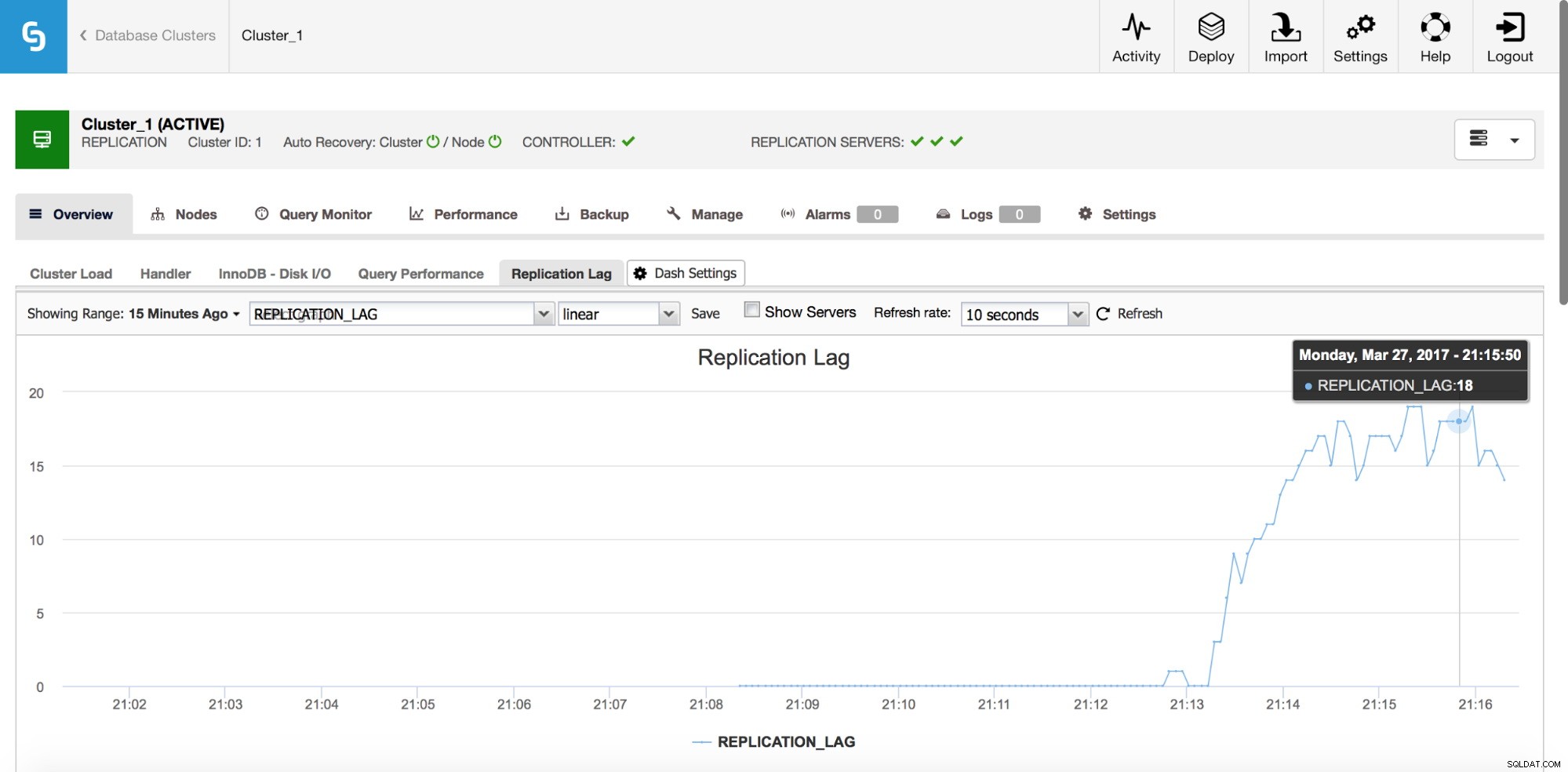
O atraso é definitivamente um dos problemas mais comuns que você enfrentará ao trabalhar com a replicação do MySQL. O atraso de replicação aparece quando um dos escravos não consegue acompanhar a quantidade de operações de gravação executadas pelo mestre. Os motivos podem ser diferentes - configuração de hardware diferente, carga mais pesada no escravo, alto grau de paralelização de gravação no mestre que deve ser serializado (quando você usa um único thread para a replicação) ou as gravações não podem ser paralelizadas na mesma extensão que esteve no mestre (quando você usa replicação multithread).
Como detectá-lo?
Existem alguns métodos para detectar o atraso de replicação. Em primeiro lugar, você pode verificar “Seconds_Behind_Master” na saída SHOW SLAVE STATUS - ele irá dizer se o slave está atrasado ou não. Funciona bem na maioria dos casos, mas em topologias mais complexas, quando você usa mestres intermediários, em hosts em algum lugar baixo na cadeia de replicação, pode não ser preciso. Outra solução melhor é confiar em ferramentas externas como pt-heartbeat. A ideia é simples - uma tabela é criada com, entre outras, uma coluna de timestamp. Esta coluna é atualizada no mestre em intervalos regulares. Em um escravo, você pode comparar o carimbo de data/hora dessa coluna com o tempo atual - ele informará o quão atrasado está o escravo.
Independentemente da maneira como você calcula o atraso, certifique-se de que seus hosts estejam sincronizados no tempo. Use ntpd ou outro meio de sincronização de tempo - se houver um desvio de tempo, você verá um atraso "falso" em seus escravos.
Como reduzir o atraso?
Esta não é uma pergunta fácil de responder. Em suma, depende do que está causando o atraso e do que se tornou um gargalo. Existem dois padrões típicos - escravo é limitado por E/S, o que significa que seu subsistema de E/S não pode lidar com a quantidade de operações de gravação e leitura. Segundo - o escravo é vinculado à CPU, o que significa que o thread de replicação usa toda a CPU possível (um thread pode usar apenas um núcleo de CPU) e ainda não é suficiente para lidar com todas as operações de gravação.
Quando a CPU é um gargalo, a solução pode ser tão simples quanto usar a replicação multithread. Aumente o número de threads de trabalho para permitir maior paralelização. Porém, nem sempre é possível - nesse caso você pode querer brincar um pouco com variáveis de commit de grupo (para MySQL e MariaDB) para atrasar os commits por um pequeno período de tempo (estamos falando de milissegundos aqui) e, desta forma , aumenta a paralelização de commits.
Se o problema estiver na E/S, o problema é um pouco mais difícil de resolver. Claro, você deve revisar suas configurações de E/S do InnoDB - talvez haja espaço para melhorias. Se o ajuste do my.cnf não ajudar, você não tem muitas opções - melhore suas consultas (sempre que possível) ou atualize seu subsistema de E/S para algo mais capaz.
A maioria dos proxies (por exemplo, todos os proxies que podem ser implantados do ClusterControl:ProxySQL, HAProxy e MaxScale) oferecem a possibilidade de remover um escravo fora de rotação se o atraso da replicação ultrapassar algum limite predefinido. Este não é de forma alguma um método para reduzir o atraso, mas pode ser útil para evitar leituras obsoletas e, como efeito colateral, reduzir a carga em um escravo, o que deve ajudá-lo a recuperar o atraso.
Claro, o ajuste de consulta pode ser uma solução em ambos os casos - é sempre bom melhorar as consultas que são pesadas em CPU ou E/S.
Transações Errantes
Transações errantes são transações que foram executadas apenas em um escravo, não no mestre. Em suma, eles tornam um escravo inconsistente com o mestre. Ao usar a replicação baseada em GTID, isso pode causar sérios problemas se o escravo for promovido a mestre. Temos uma postagem detalhada sobre esse tópico e incentivamos você a analisá-la e se familiarizar com como detectar e corrigir problemas com transações errôneas. Também incluímos informações sobre como o ClusterControl detecta e trata transações errôneas.
Nenhum arquivo Binlog no mestre
Como identificar o problema?
Em algumas circunstâncias, pode acontecer que um escravo se conecte a um mestre e solicite um arquivo de log binário inexistente. Uma razão para isso pode ser a transação errônea - em algum momento, uma transação foi executada em um escravo e depois esse escravo se torna um mestre. Outros hosts, configurados para serem escravos desse mestre, solicitarão essa transação ausente. Se foi executado há muito tempo, há uma chance de que os arquivos de log binários já tenham sido limpos.
Outro exemplo mais típico - você deseja provisionar um escravo usando xtrabackup. Você copia o backup em um host, aplica o log, altera o proprietário do diretório de dados do MySQL - operações típicas que você faz para restaurar um backup. Você executa
SET GLOBAL gtid_purged=baseado nos dados do xtrabackup_binlog_info e você executa CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (isso é no MySQL, o MariaDB tem um processo um pouco diferente), inicie o slave e então você acaba com um erro como:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'no MySQL ou:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'em MariaDB.
Isso basicamente significa que o mestre não possui todos os logs binários necessários para executar todas as transações ausentes. Muito provavelmente, o backup é muito antigo e o mestre já limpou alguns dos logs binários criados entre o momento em que o backup foi criado e quando o escravo foi provisionado.
Como resolver este problema?
Infelizmente, não há muito que você possa fazer neste caso específico. Se você tiver alguns hosts MySQL que armazenam logs binários por mais tempo que o master, você pode tentar usar esses logs para reproduzir transações ausentes no slave. Vejamos como isso pode ser feito.
Antes de tudo, vamos dar uma olhada no GTID mais antigo nos logs binários do mestre:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Portanto, ‘binlog.000021’ é o arquivo mais recente (e único). Vamos verificar qual é a primeira entrada GTID neste arquivo:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Como podemos ver, a entrada de log binário mais antiga disponível é:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Também precisamos verificar qual é o último GTID coberto no backup:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666É:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, então não temos dois eventos:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Vamos ver se podemos encontrar essas transações em outro escravo.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Parece que 'binlog.000003' é o log binário mais recente. Precisamos verificar se nossos GTIDs ausentes podem ser encontrados nele:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Por favor, tenha em mente que você pode querer copiar arquivos binlog fora do servidor de produção, pois processá-los pode adicionar alguma carga. Como verificamos que esses GTIDs existem, podemos extraí-los:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlApós um rápido scp, podemos aplicar esses eventos no escravo
slave1:~# mysql -ppass < to_apply_on_slave1.sqlUma vez feito, podemos verificar se esses GTIDs foram aplicados olhando para a saída de SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set parece bom, portanto, podemos iniciar threads escravos:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Vamos verificar se funcionou bem. Vamos, novamente, usar a saída SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Parece bom, está funcionando!
Outro método de resolver esse problema será fazer um backup mais uma vez e provisionar o escravo novamente, usando dados novos. Isso provavelmente será mais rápido e definitivamente mais confiável. Não é sempre que você tem diferentes políticas de limpeza de log binário no mestre e nos escravos)
Continuaremos discutindo outros tipos de problemas de replicação na próxima postagem do blog.