Introdução
Rebobina são específicos para operadores no lado interno de uma junção ou aplicação de loops aninhados. A ideia é reutilizar resultados previamente computados de parte de um plano de execução onde for seguro fazê-lo.
O exemplo canônico de um operador de plano que pode retroceder é o preguiçoso Spool de tabela . Sua razão de ser é armazenar em cache as linhas de resultado de uma subárvore do plano e, em seguida, reproduzir essas linhas nas iterações subsequentes se algum parâmetro de loop correlacionado não for alterado. Reproduzir linhas pode ser mais barato do que reexecutar a subárvore que as gerou. Para obter mais informações sobre esses spools de desempenho veja meu artigo anterior.
A documentação diz que apenas os seguintes operadores podem retroceder:
- Carretel de mesa
- Carretel de contagem de linhas
- Spool de índice não clusterizado
- Função com valor de tabela
- Classificar
- Consulta Remota
- Afirmar e Filtrar operadores com uma Expressão de inicialização
Os três primeiros itens são, na maioria das vezes, carretéis de desempenho, embora possam ser introduzidos por outros motivos (quando podem ser ansiosos ou preguiçosos).
Funções com valor de tabela use uma variável de tabela, que pode ser usada para armazenar em cache e reproduzir resultados em circunstâncias adequadas. Se você estiver interessado em retrocessos de função com valor de tabela, consulte minhas perguntas e respostas sobre o Database Administrators Stack Exchange.
Com isso fora do caminho, este artigo é exclusivamente sobre Classificações e quando eles podem rebobinar.
Ordenar retrocessos
Classificações usam armazenamento (memória e talvez disco se derramarem) para que tenham um recurso capaz de armazenar linhas entre iterações de loop. Em particular, a saída classificada pode, em princípio, ser reproduzida (rebobinada).
Ainda assim, a resposta curta para a pergunta do título, “Do Sorts Rewind?” é:
Sim, mas você não o verá com muita frequência.
Tipos de classificação
As classificações vêm em muitos tipos diferentes internamente, mas para nossos propósitos atuais, existem apenas dois:
- Classificação na memória (
CQScanInMemSortNew).- Sempre na memória; não pode derramar para o disco.
- Usa a classificação rápida da biblioteca padrão.
- Máximo de 500 linhas e duas páginas de 8 KB no total.
- Todas as entradas devem ser constantes de tempo de execução. Normalmente, isso significa que toda a subárvore de classificação deve consistir em somente Verificação Constante e/ou Computar escalar operadores.
- Somente distinguível explicitamente em planos de execução quando plano de exibição detalhado está habilitado (sinalizador de rastreamento 8666). Isso adiciona propriedades extras ao Classificar operador, um dos quais é “InMemory=[0|1]”.
- Todas as outras classificações.
(Ambos os tipos de Classificar operador inclua sua Classificação N Top e Classificação distinta variantes).
Retroceder comportamentos
-
Classificações na memória pode sempre retroceder quando é seguro. Se não houver parâmetros de loop correlacionados ou se os valores dos parâmetros não forem alterados desde a iteração imediatamente anterior, esse tipo de classificação pode reproduzir seus dados armazenados em vez de executar novamente os operadores abaixo dele no plano de execução.
-
Classificações fora da memória pode retroceder quando seguro, mas somente se a opção Classificar operador contém no máximo uma linha . Observe uma Classificação input pode fornecer uma linha em algumas iterações, mas não em outras. O comportamento do tempo de execução pode, portanto, ser uma mistura complexa de retrocessos e religações. Depende completamente de quantas linhas são fornecidas ao Classificar em cada iteração em tempo de execução. Geralmente, você não pode prever o que uma Classificação fará em cada iteração inspecionando o plano de execução.
A palavra “seguro” nas descrições acima significa:Ou não ocorreu uma mudança no parâmetro, ou nenhum operador abaixo do Classificar têm uma dependência do valor alterado.
Nota importante sobre planos de execução
Os planos de execução nem sempre relatam retrocessos (e religações) corretamente para Classificar operadores. O operador relatará um retrocesso se quaisquer parâmetros correlacionados não forem alterados e um rebind caso contrário.
Para classificações fora da memória (de longe o mais comum), um retrocesso relatado só reproduzirá os resultados de classificação armazenados se houver no máximo uma linha no buffer de saída de classificação. Caso contrário, a classificação relatará um retrocesso, mas a subárvore ainda será totalmente reexecutada (uma religação).
Para verificar quantos retrocessos relatados foram retrocessos reais, verifique o Número de execuções propriedade em operadores abaixo de Classificar .
Histórico e minha explicação
A Classificação o comportamento de retrocesso do operador pode parecer estranho, mas foi assim (pelo menos) do SQL Server 2000 ao SQL Server 2019 inclusive (assim como o Banco de Dados SQL do Azure). Não consegui encontrar nenhuma explicação ou documentação oficial sobre isso.
Minha opinião pessoal é que Classificar os retrocessos são muito caros devido ao maquinário de classificação subjacente, incluindo recursos de derramamento e o uso de transações do sistema em tempdb .
Na maioria dos casos, o otimizador fará melhor ao introduzir um spool de desempenho explícito quando detecta a possibilidade de parâmetros de loop correlacionados duplicados. Os spools são a maneira menos dispendiosa de armazenar resultados parciais em cache.
É possível que reproduzir uma Classificação resultado só seria mais econômico do que um Carretel quando a Classificar contém no máximo uma linha. Afinal, classificar uma linha (ou nenhuma linha!) na verdade não envolve nenhuma classificação, portanto, grande parte da sobrecarga pode ser evitada.
Pura especulação, mas alguém era obrigado a perguntar, então aí está.
Demonstração 1:retrocessos imprecisos
Este primeiro exemplo apresenta duas variáveis de tabela. O primeiro contém três valores duplicados três vezes na coluna
c1 . A segunda tabela contém duas linhas para cada correspondência em c2 = c1 . As duas linhas correspondentes são distinguidas por um valor na coluna c3 . A tarefa é retornar a linha da segunda tabela com o maior
c3 valor para cada correspondência em c1 = c2 . O código é provavelmente mais claro do que a minha explicação:DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL); O
NO_PERFORMANCE_SPOOL A dica existe para evitar que o otimizador introduza um spool de desempenho. Isso pode acontecer com variáveis de tabela quando, por exemplo, o sinalizador de rastreamento 2453 está habilitado ou a compilação adiada da variável de tabela está disponível, para que o otimizador possa ver a verdadeira cardinalidade da variável de tabela (mas não a distribuição de valor). Os resultados da consulta mostram o
c2 e c3 os valores retornados são os mesmos para cada c1 distinto valor: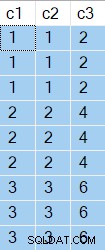
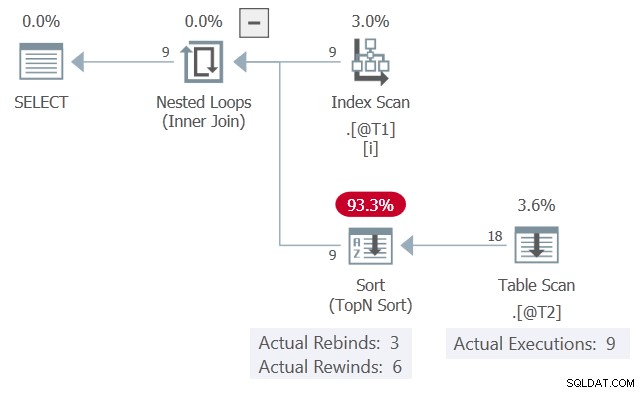
O plano de execução real para a consulta é:
O
c1 os valores, apresentados em ordem, correspondem à iteração anterior 6 vezes e mudam 3 vezes. A Classificação relata isso como 6 rebobinas e 3 religações. Se isso for verdade, a Verificação de tabela executaria apenas 3 vezes. A Classificação repetiria (rebobinaria) seus resultados nas outras 6 ocasiões.
Como está, podemos ver o Table Scan foi executado 9 vezes, uma vez para cada linha da tabela
@T1 . Nenhum retrocesso aconteceu aqui . Demonstração 2:classificar retrocessos
O exemplo anterior não permitia o Classificar para retroceder porque (a) não é uma Classificação na Memória; e (b) em cada iteração do loop, o Classificar continha duas fileiras. O Plan Explorer mostra um total de 18 linhas da Table Scan , duas linhas em cada uma das 9 iterações.
Vamos ajustar o exemplo agora para que haja apenas um linha na tabela
@T2 para cada linha correspondente de @T1 :DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL); Os resultados são os mesmos mostrados anteriormente porque mantivemos a linha correspondente classificada mais alta na coluna
c3 . O plano de execução também é superficialmente semelhante, mas com uma diferença importante: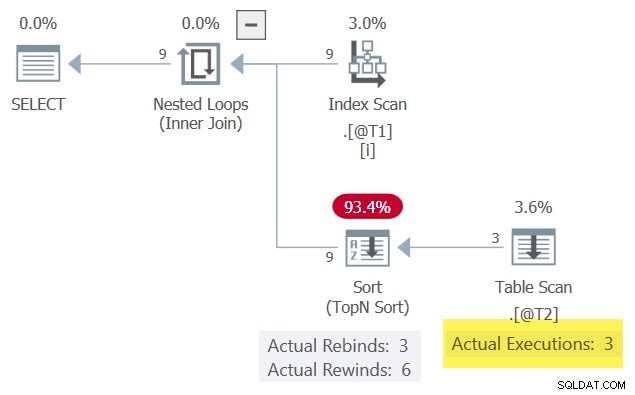
Com uma linha em Classificar a qualquer momento, é capaz de retroceder quando o parâmetro correlacionado
c1 não muda. A Verificação de Tabela é executado apenas 3 vezes como resultado. Observe a Classificação produz mais linhas (9) do que recebe (3). Esta é uma boa indicação de que uma Classificação conseguiu armazenar em cache um conjunto de resultados uma ou mais vezes – um retrocesso bem-sucedido.
Demo 3:Rebobinando nada
Mencionei antes que uma Classificação não armazenada na memória pode retroceder quando contém no máximo uma linha.
Para ver isso em ação com zero linhas , mudamos para um
OUTER APPLY e não coloque nenhuma linha na tabela @T2 . Por motivos que ficarão aparentes em breve, também pararemos de projetar a coluna c2 :DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL); Os resultados agora têm
NULL na coluna c3 como esperado: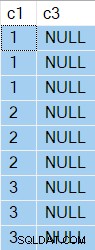
O plano de execução é:
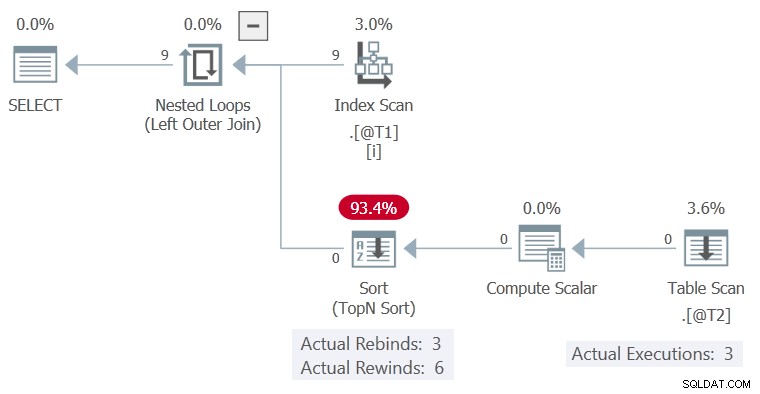
A Classificação foi capaz de retroceder sem linhas em seu buffer, então o Table Scan foi executado apenas 3 vezes, cada coluna de tempo
c1 valor alterado. Demonstração 4:Retrocesso máximo!
Como os outros operadores que suportam retrocessos, um Sort apenas religará sua subárvore se um parâmetro correlacionado foi alterado e a subárvore depende desse valor de alguma forma.
Restaurando a coluna
c2 a projeção para a demonstração 3 mostrará isso em ação:DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL); Os resultados agora mostram dois
NULL colunas, claro: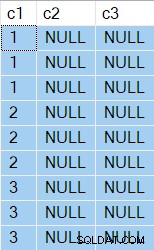
O plano de execução é bem diferente:
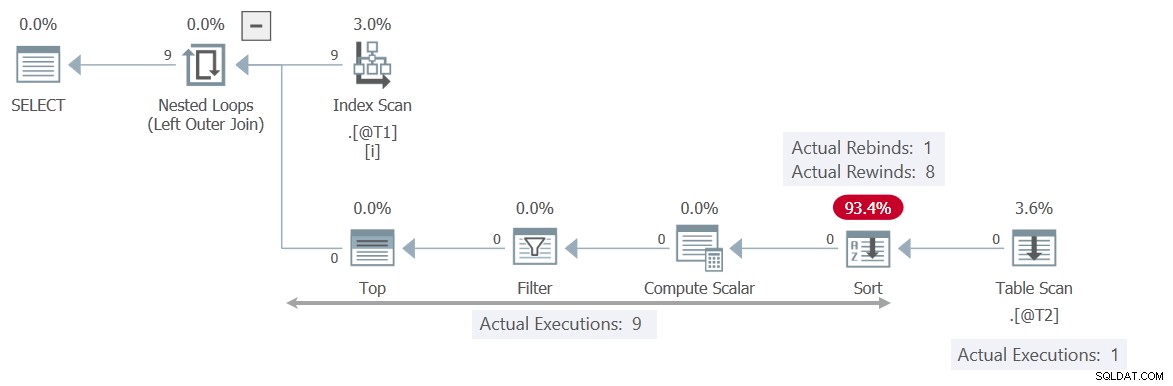
Desta vez, o Filtro contém a verificação
T2.c2 = T1.c1 , fazendo a Verificação de Tabela independente do valor atual do parâmetro correlacionado c1 . A Classificação pode retroceder 8 vezes com segurança, o que significa que a verificação só é executada uma vez . Demonstração 5:classificação na memória
O próximo exemplo mostra uma Classificação na memória operador:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Os resultados obtidos variam de execução para execução, mas aqui está um exemplo:
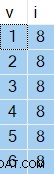
O interessante são os valores na coluna
i será sempre o mesmo — apesar do ORDER BY NEWID() cláusula. Você provavelmente já deve ter adivinhado que o motivo disso é o Classificar resultados de cache (rebobinagem). O plano de execução mostra a Verificação Constante executando apenas uma vez, produzindo 11 linhas no total:
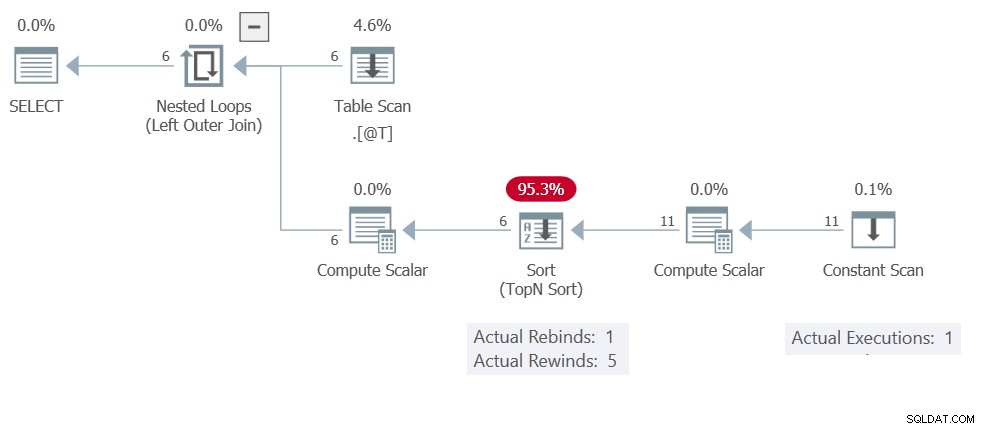
Esta Classificação tem apenas Compute Scalar e Verificação Constante operadores em sua entrada, então é um In Memory Sort . Lembre-se, eles não estão limitados a no máximo uma única linha - eles podem acomodar 500 linhas e 16 KB.
Como mencionado anteriormente, não é possível ver explicitamente se um Classificar é na memória ou não inspecionando um plano de execução regular. Precisamos de saída detalhada do plano de apresentação , ativado com o sinalizador de rastreamento não documentado 8666. Com isso ativado, as propriedades extras do operador aparecem:
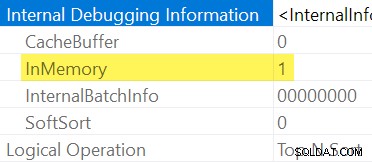
Quando não for prático usar sinalizadores de rastreamento não documentados, você pode inferir que um Classificar é "InMemory" por sua Fração de Memória de Entrada sendo zero e Uso de memória elementos que não estão disponíveis no plano de exibição pós-execução (nas versões do SQL Server que suportam essas informações).
De volta ao plano de execução:Não há parâmetros correlacionados, então o Classificar é livre para retroceder 5 vezes, o que significa que a Verificação Constante é executado apenas uma vez. Sinta-se à vontade para alterar o
TOP (1) para TOP (3) ou o que você quiser. O rebobinamento significa que os resultados serão os mesmos (em cache/rebobinados) para cada linha de entrada. Você pode ser incomodado pelo
ORDER BY NEWID() cláusula que não impede o rebobinamento. Este é, de fato, um ponto controverso, mas não limitado a tipos. Para uma discussão mais completa (aviso:possível toca de coelho), consulte este Q &A. A versão curta é que esta é uma decisão deliberada de design de produto, otimizando o desempenho, mas há planos para tornar o comportamento mais intuitivo ao longo do tempo. Demonstração 6:Sem classificação na memória
Isso é o mesmo que a demonstração 5, exceto que a string replicada é um caractere a mais:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Novamente, os resultados irão variar por execução, mas aqui está um exemplo. Observe o
i os valores agora não são todos iguais:
O caractere extra é suficiente para empurrar o tamanho estimado dos dados classificados para mais de 16 KB. Isso significa uma Classificação na memória não pode ser usado e os retrocessos desaparecem.
O plano de execução é:
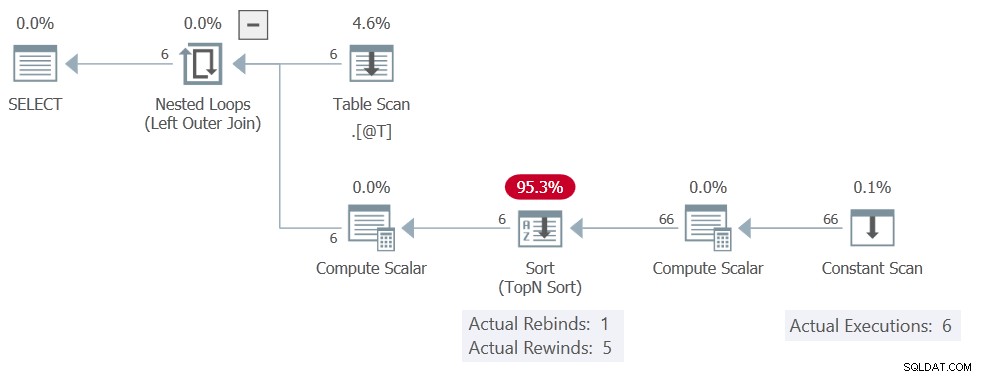
A Classificação ainda relatórios 5 retrocessos, mas o Constant Scan é executado 6 vezes, significando que nenhum retrocesso realmente ocorreu. Ele produz todas as 11 linhas em cada uma das 6 execuções, totalizando 66 linhas.
Resumo e Considerações Finais
Você não verá uma Classificar operador verdadeiramente rebobinando com muita frequência, embora você o veja dizendo que sim bastante.
Lembre-se, uma Classificação normal só pode retroceder se for seguro e há no máximo uma linha na classificação no momento. Ser "seguro" significa que não há alteração nos parâmetros de correlação de loop ou nada abaixo do Classificar é afetado pelas mudanças de parâmetro.
Uma classificação na memória pode operar em até 500 linhas e 16 KB de dados provenientes de Varredura Constante e Compute Escalar apenas operadores. Ele também só retrocederá quando for seguro (deixando de lado os bugs do produto!), mas não está limitado a um máximo de uma linha.
Estes podem parecer detalhes esotéricos, e suponho que sejam. Assim dizendo, eles me ajudaram a entender um plano de execução e encontrar boas melhorias de desempenho mais de uma vez. Talvez você ache a informação útil um dia também.
Fique atento às Classificações que produzem mais linhas do que têm em sua entrada!
Se você quiser ver um exemplo mais realista de Classificar rebobina com base em uma demo que Itzik Ben-Gan forneceu na primeira parte de sua Correspondência mais próxima série, consulte Correspondência mais próxima com retrocessos de classificação.