Durante anos, a replicação do MySQL costumava ser baseada em eventos de log binários - tudo o que um escravo sabia era o evento exato e a posição exata que acabava de ler do mestre. Qualquer transação única de um mestre pode ter terminado em diferentes logs binários e em diferentes posições nesses logs. Foi uma solução simples que veio com limitações - alterações de topologia mais complexas podem exigir que um administrador interrompa a replicação nos hosts envolvidos. Ou essas alterações podem causar alguns outros problemas, por exemplo, um escravo não pode ser movido para baixo na cadeia de replicação sem um processo de reconstrução demorado (não foi possível alterar facilmente a replicação de A -> B -> C para A -> C -> B sem interromper a replicação em B e C). Todos nós tivemos que contornar essas limitações enquanto sonhávamos com um identificador de transação global.
O GTID foi introduzido junto com o MySQL 5.6 e trouxe algumas mudanças importantes na maneira como o MySQL opera. Em primeiro lugar, cada transação possui um identificador único que a identifica da mesma forma em todos os servidores. Não é mais importante em qual posição do log binário uma transação foi gravada, tudo que você precisa saber é o GTID:‘966073f3-b6a4-11e4-af2c-080027880ca6:4’. O GTID é construído a partir de duas partes - o identificador exclusivo de um servidor onde uma transação foi executada pela primeira vez e um número de sequência. No exemplo acima, podemos ver que a transação foi executada pelo servidor com server_uuid de ‘966073f3-b6a4-11e4-af2c-080027880ca6’ e é a 4ª transação executada lá. Esta informação é suficiente para realizar mudanças complexas na topologia - o MySQL sabe quais transações foram executadas e, portanto, sabe quais transações precisam ser executadas em seguida. Esqueça os logs binários, está tudo no GTID.
Então, onde você pode encontrar GTIDs? Você os encontrará em dois lugares. Em um escravo, em 'mostrar status do escravo;' você encontrará duas colunas:Retrieved_Gtid_Set e Executed_Gtid_Set. O primeiro abrange os GTIDs que foram recuperados do mestre via replicação, o segundo informa sobre todas as transações que foram executadas em determinado host - tanto via replicação quanto executadas localmente.
Configurando um cluster de replicação de maneira fácil
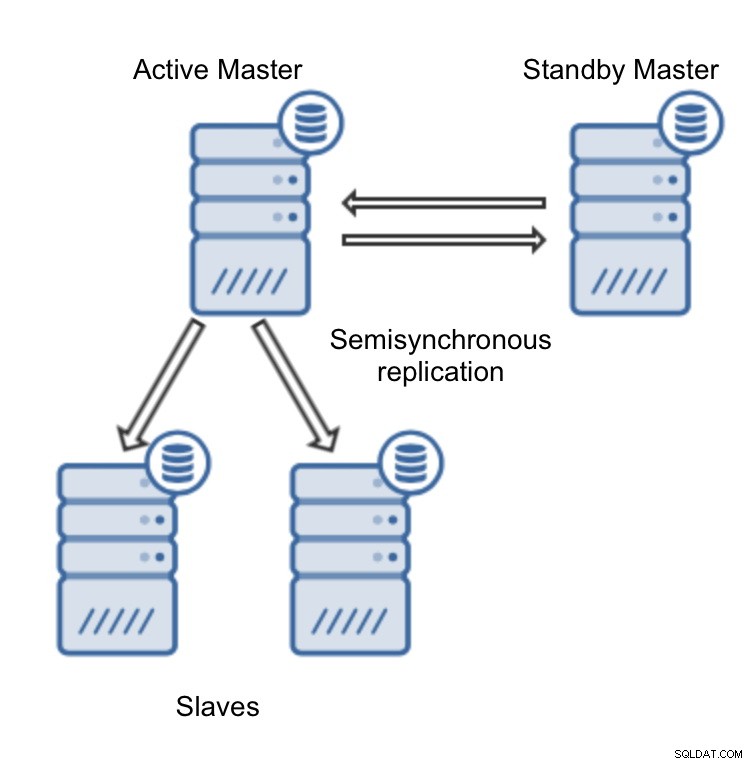
A implantação do cluster de replicação MySQL é muito fácil no ClusterControl (você pode experimentá-lo gratuitamente). O único pré-requisito é que todos os hosts, nos quais você usará para implantar nós MySQL, possam ser acessados a partir da instância ClusterControl usando uma conexão SSH sem senha.
Quando a conectividade está em vigor, você pode implantar um cluster usando a opção "Implantar". Quando a janela do assistente está aberta, você precisa tomar algumas decisões - o que você quer fazer? Implantar um novo cluster? Implante um nó Postgresql ou importe um cluster existente.
Queremos implantar um novo cluster. Em seguida, será apresentada a seguinte tela na qual precisamos decidir que tipo de cluster queremos implantar. Vamos escolher a replicação e, em seguida, passar os detalhes necessários sobre a conectividade ssh.
Quando estiver pronto, clique em Continuar. Desta vez, precisamos decidir qual fornecedor MySQL gostaríamos de usar, qual versão e algumas configurações, incluindo, entre outras, senha para a conta root no MySQL.
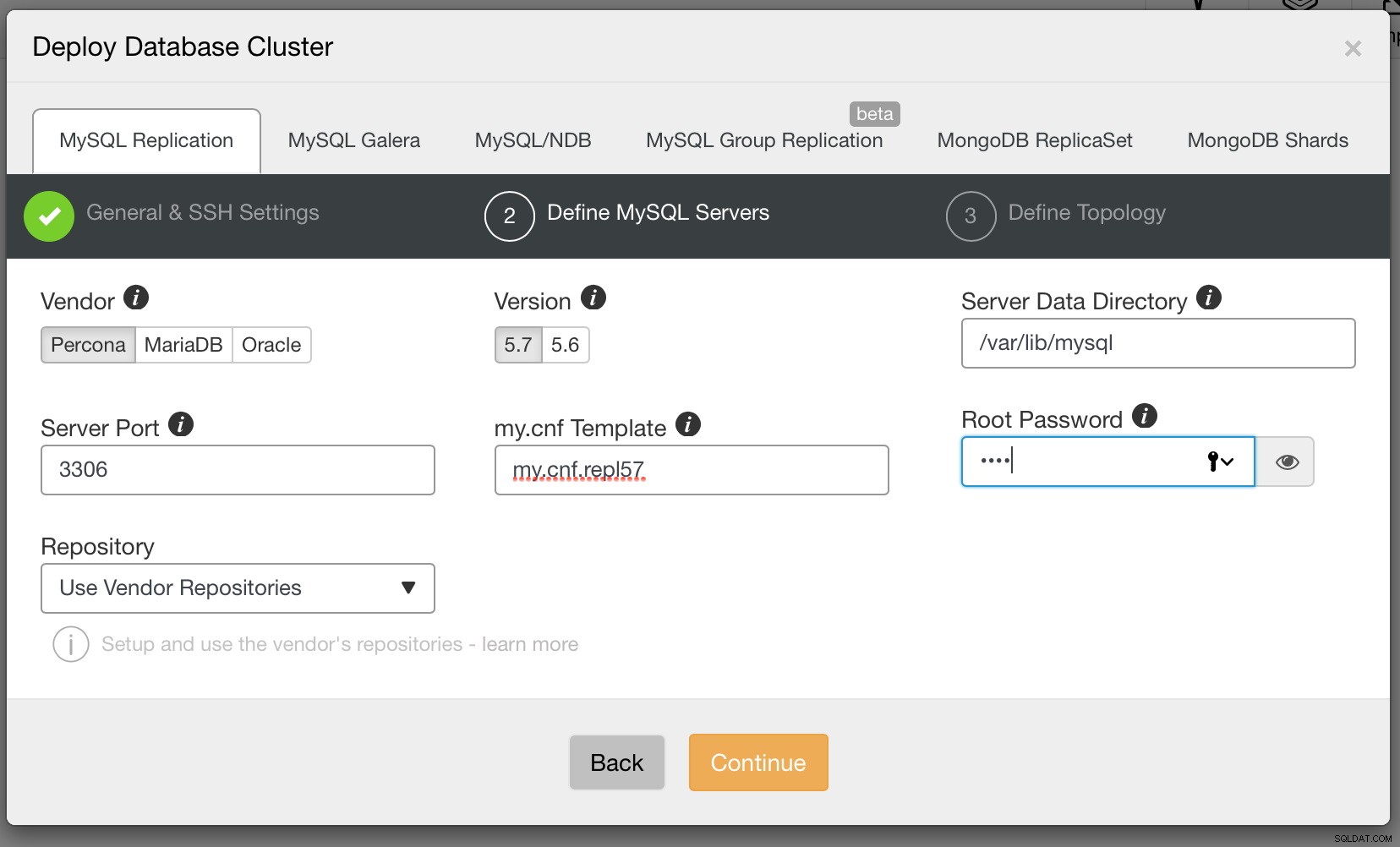
Finalmente, precisamos decidir sobre a topologia de replicação - você pode usar uma configuração típica de mestre-escravo ou criar um par mestre-mestre-mestre mais complexo e ativo em espera (+ escravos, caso queira adicioná-los). Quando estiver pronto, basta clicar em “Deploy” e em alguns minutos você deverá ter seu cluster implantado.
Feito isso, você verá seu cluster na lista de clusters da interface do usuário do ClusterControl.
Com a replicação em funcionamento, podemos dar uma olhada mais de perto em como o GTID funciona.
Transações erradas - qual é o problema?
Como mencionamos no início deste post, os GTID's trouxeram uma mudança significativa na forma como as pessoas devem pensar sobre a replicação do MySQL. É tudo sobre hábitos. Digamos, por algum motivo, que um aplicativo realizou uma gravação em um dos escravos. Não deveria ter acontecido, mas surpreendentemente, acontece o tempo todo. Como resultado, a replicação é interrompida com erro de chave duplicada. Existem algumas maneiras de lidar com esse problema. Um deles seria excluir a linha incorreta e reiniciar a replicação. Outra seria ignorar o evento de log binário e reiniciar a replicação.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Ambas as formas devem trazer a replicação de volta ao trabalho, mas podem introduzir desvio de dados, portanto, é necessário lembrar que a consistência do escravo deve ser verificada após esse evento (pt-table-checksum e pt-table-sync funcionam bem aqui).
Se ocorrer um problema semelhante ao usar o GTID, você notará algumas diferenças. A exclusão da linha incorreta pode parecer corrigir o problema, a replicação deve poder começar. O outro método, usando sql_slave_skip_counter, não funcionará - ele retornará um erro. Lembre-se, agora não se trata de eventos de log binário, trata-se de GTID sendo executado ou não.
Por que excluir a linha apenas "parece" corrigir o problema? Uma das coisas mais importantes a se ter em mente em relação ao GTID é que um escravo, ao se conectar ao mestre, verifica se está faltando alguma transação que foi executada no mestre. São as chamadas transações errantes. Se um escravo encontrar tais transações, ele as executará. Vamos supor que executamos o SQL a seguir para limpar uma linha incorreta:
DELETE FROM mytable WHERE id=100;Vamos verificar o status do escravo:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,E veja de onde vem o 84d15910-b6a4-11e4-af2c-080027880ca6:1:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Como você pode ver, temos 29 transações que vieram do mestre, UUID de 966073f3-b6a4-11e4-af2c-080027880ca6 e uma que foi executada localmente. Digamos que em algum momento fazemos failover e o mestre (966073f3-b6a4-11e4-af2c-080027880ca6) se torna um escravo. Ele verificará sua lista de GTIDs executados e não encontrará este:84d15910-b6a4-11e4-af2c-080027880ca6:1. Como resultado, o SQL relacionado será executado:
DELETE FROM mytable WHERE id=100;Isso não é algo que esperávamos… Se, nesse meio tempo, o log binário contendo esta transação for purgado no escravo antigo, o novo escravo reclamará após o failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Como detectar transações errôneas?
O MySQL fornece duas funções que são muito úteis quando você deseja comparar conjuntos de GTID em diferentes hosts.
GTID_SUBSET() pega dois conjuntos GTID e verifica se o primeiro conjunto é um subconjunto do segundo.
Digamos que temos o seguinte estado.
Mestre:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Escravo:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Podemos verificar se o escravo possui alguma transação errônea executando o seguinte SQL:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Parece que há transações erradas. Como os identificamos? Podemos usar outra função, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Nossos GTIDs ausentes são ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - essas transações foram executadas no escravo, mas não no mestre.
Como resolver problemas causados por transações erradas?
Existem duas maneiras - injetar transações vazias ou excluir transações do histórico do GTID.
Para injetar transações vazias podemos usar o seguinte SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Isso deve ser executado em todos os hosts da topologia de replicação que não possuem esses GTIDs executados. Se o mestre estiver disponível, você pode injetar essas transações lá e deixá-las replicar na cadeia. Se o mestre não estiver disponível (por exemplo, ele travou), essas transações vazias devem ser executadas em cada escravo. A Oracle desenvolveu uma ferramenta chamada mysqlslavetrx, projetada para automatizar esse processo.
Outra abordagem é remover os GTIDs do histórico:
Parar escravo:
mysql> STOP SLAVE;Imprima Executed_Gtid_Set no escravo:
mysql> SHOW MASTER STATUS\GRedefinir informações do GTID:
RESET MASTER;Defina GTID_PURGED para um conjunto GTID correto. baseado em dados de SHOW MASTER STATUS. Você deve excluir transações errôneas do conjunto.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Iniciar escravo.
mysql> START SLAVE\GEm todos os casos, você deve verificar a consistência de seus escravos usando pt-table-checksum e pt-table-sync (se necessário) - transações errôneas podem resultar em um desvio de dados.
Failover no ClusterControl
A partir da versão 1.4, o ClusterControl aprimorou seus processos de manipulação de failover para a Replicação MySQL. Você ainda pode realizar uma chave mestre manual promovendo um dos escravos a mestre. O restante dos escravos fará o failover para o novo mestre. A partir da versão 1.4, o ClusterControl também tem a capacidade de executar um failover totalmente automatizado caso o mestre falhe. Cobrimos isso detalhadamente em uma postagem no blog descrevendo o ClusterControl e o failover automatizado. Ainda gostaríamos de mencionar um recurso, diretamente relacionado ao tema deste post.
Por padrão, o ClusterControl executa o failover de uma “maneira segura” - no momento do failover (ou switchover, se for o usuário que executou um switch mestre), o ClusterControl escolhe um candidato mestre e verifica se esse nó não possui transações errôneas o que afetaria a replicação assim que fosse promovido a mestre. Se uma transação errônea for detectada, o ClusterControl interromperá o processo de failover e o candidato mestre não será promovido a um novo mestre.
Se você quiser ter 100% de certeza de que o ClusterControl promoverá um novo mestre mesmo que alguns problemas (como transações errôneas) sejam detectados, você pode fazer isso usando a configuração replication_stop_on_error=0 na configuração cmon. É claro que, como discutimos, isso pode levar a problemas com a replicação - os escravos podem começar a solicitar um evento de log binário que não está mais disponível.
Para lidar com esses casos, adicionamos suporte experimental para reconstrução de escravos. Se você definir replication_auto_rebuild_slave=1 na configuração do cmon e seu escravo estiver marcado como inativo com o seguinte erro no MySQL, o ClusterControl tentará reconstruir o escravo usando dados do mestre:
Ocorreu o erro fatal 1236 do mestre ao ler dados do log binário:'O escravo está se conectando usando CHANGE MASTER TO MASTER_AUTO_POSITION =1, mas o mestre limpou os logs binários contendo GTIDs que o escravo requer.'
Essa configuração pode nem sempre ser apropriada, pois o processo de reconstrução induzirá um aumento de carga no mestre. Também pode ser que seu conjunto de dados seja muito grande e uma reconstrução regular não seja uma opção - é por isso que esse comportamento está desabilitado por padrão.



