Na postagem anterior, discutimos como verificar se a Replicação do MySQL está em boas condições. Também analisamos alguns dos problemas típicos. Neste post, veremos mais alguns problemas que você pode encontrar ao lidar com a replicação do MySQL.
Entradas ausentes ou duplicadas
Isso é algo que não deveria acontecer, mas acontece com muita frequência - uma situação em que uma instrução SQL executada no mestre é bem-sucedida, mas a mesma instrução executada em um dos escravos falha. O principal motivo é o desvio do escravo - algo (geralmente transações errôneas, mas também outros problemas ou bugs na replicação) faz com que o escravo seja diferente de seu mestre. Por exemplo, uma linha que existia no mestre não existe no escravo e não pode ser excluída ou atualizada. A frequência com que esse problema aparece depende principalmente de suas configurações de replicação. Em resumo, existem três maneiras pelas quais o MySQL armazena eventos de log binários. Primeiro, “instrução” significa que o SQL é escrito em texto simples, assim como foi executado em um mestre. Esta configuração tem a maior tolerância no desvio do escravo, mas também é a que não pode garantir a consistência do escravo - é difícil recomendar seu uso em produção. O segundo formato, “linha”, armazena o resultado da consulta em vez da instrução da consulta. Por exemplo, um evento pode ter a seguinte aparência:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Isso significa que estamos atualizando uma linha na tabela 'tab' no esquema 'test' onde a primeira coluna tem um valor de 2 e a segunda coluna tem um valor de 5. Definimos a primeira coluna como 2 (o valor não muda) e a segunda coluna para 4. Como você pode ver, não há muito espaço para interpretação - é definido com precisão qual linha é usada e como ela é alterada. Como resultado, esse formato é ótimo para consistência de escravos, mas, como você pode imaginar, é muito vulnerável quando se trata de desvio de dados. Ainda é a maneira recomendada de executar a replicação do MySQL.
Finalmente, o terceiro, “misto”, funciona de forma que os eventos que são seguros para escrever na forma de declarações usem o formato “declaração”. Aqueles que podem causar desvio de dados usarão o formato “linha”.
Como você os detecta?
Como de costume, SHOW SLAVE STATUS nos ajudará a identificar o problema.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Como você pode ver, os erros são claros e autoexplicativos (e são basicamente idênticos entre MySQL e MariaDB.
Como você corrige o problema?
Esta é, infelizmente, a parte complexa. Em primeiro lugar, você precisa identificar uma fonte de verdade. Qual host contém os dados corretos? Mestre ou escravo? Normalmente você assumiria que é o mestre, mas não o assume por padrão - investigue! Pode ser que, após o failover, alguma parte do aplicativo ainda tenha emitido gravações para o antigo mestre, que agora atua como escravo. Pode ser que read_only não tenha sido configurado corretamente nesse host ou talvez o aplicativo use superusuário para se conectar ao banco de dados (sim, vimos isso em ambientes de produção). Nesse caso, o escravo poderia ser a fonte da verdade - pelo menos até certo ponto.
Dependendo de quais dados devem permanecer e quais devem ir, o melhor curso de ação seria identificar o que é necessário para sincronizar a replicação novamente. Em primeiro lugar, a replicação está quebrada, então você precisa atender a isso. Faça login no mestre e verifique o log binário, mesmo que tenha causado a interrupção da replicação.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Como você pode ver, perdemos um evento:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Vamos verificar nos logs binários do mestre:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Podemos ver que foi uma inserção que define a primeira coluna como 3 e a segunda como 7. Vamos verificar como nossa tabela se parece agora:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Agora temos duas opções, dependendo de quais dados devem prevalecer. Se os dados corretos estiverem no mestre, podemos simplesmente excluir a linha com id=3 no escravo. Apenas certifique-se de desabilitar o log binário para evitar a introdução de transações errôneas. Por outro lado, se decidirmos que os dados corretos estão no escravo, precisamos executar o comando REPLACE no mestre para definir a linha com id=3 para corrigir o conteúdo de (3, 10) do atual (3, 7). No escravo, porém, teremos que pular o GTID atual (ou, para ser mais preciso, teremos que criar um evento GTID vazio) para poder reiniciar a replicação.
A exclusão de uma linha em um escravo é simples:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Inserir um GTID vazio é quase tão simples:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Outro método de resolver esse problema específico (desde que aceitemos o mestre como fonte de verdade) é usar ferramentas como pt-table-checksum e pt-table-sync para identificar onde o escravo não é consistente com seu mestre e o que SQL deve ser executado no mestre para trazer o escravo de volta à sincronia. Infelizmente, esse método é bastante pesado - muita carga é adicionada ao mestre e várias consultas são gravadas no fluxo de replicação, o que pode afetar o atraso nos escravos e o desempenho geral da configuração da replicação. Isso é especialmente verdadeiro se houver um número significativo de linhas que precisam ser sincronizadas.
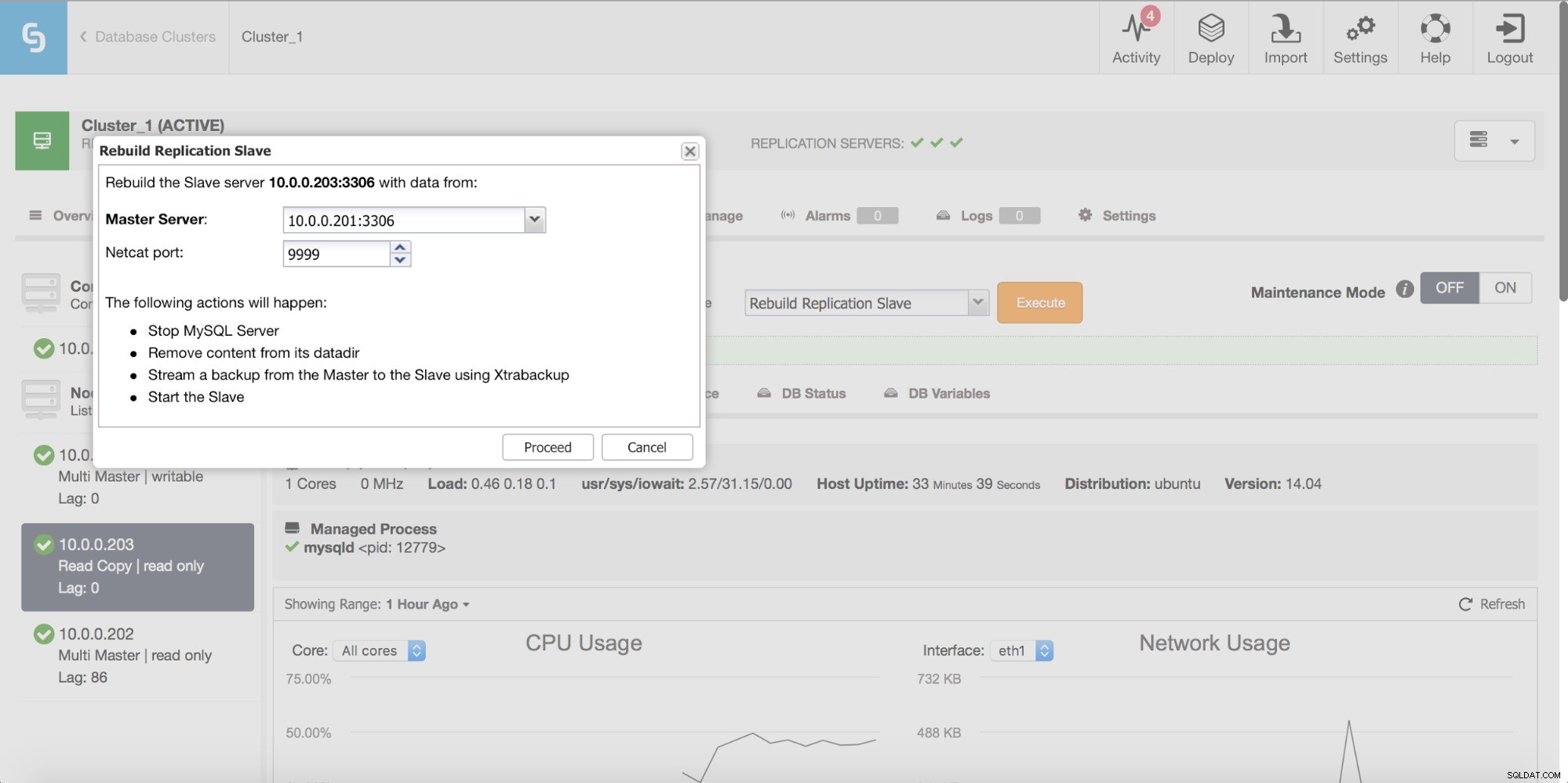
Finalmente, como sempre, você pode reconstruir seu escravo usando dados do mestre - desta forma, você pode ter certeza de que o escravo será atualizado com os dados mais recentes e atualizados. Na verdade, isso não é necessariamente uma má ideia - quando estamos falando de um grande número de linhas para sincronizar usando pt-table-checksum/pt-table-sync, isso vem com uma sobrecarga significativa no desempenho da replicação, CPU geral e E/S carga e horas-homem necessárias.
O ClusterControl permite reconstruir um escravo, usando uma nova cópia dos dados mestre.
Verificações de consistência
Como mencionamos no capítulo anterior, a consistência pode se tornar um problema sério e pode causar muitas dores de cabeça para usuários que executam configurações de replicação do MySQL. Vamos ver como você pode verificar se seus escravos MySQL estão em sincronia com o mestre e o que você pode fazer a respeito.
Como detectar um escravo inconsistente
Infelizmente, a maneira típica de um usuário saber que um escravo é inconsistente é se deparar com um dos problemas que mencionamos no capítulo anterior. Para evitar que o monitoramento proativo da consistência do escravo seja necessário. Vamos verificar como isso pode ser feito.
Vamos usar uma ferramenta do Percona Toolkit:pt-table-checksum. Ele foi projetado para verificar o cluster de replicação e identificar quaisquer discrepâncias.
Construímos um cenário personalizado usando o sysbench e introduzimos um pouco de inconsistência em um dos escravos. O que é importante (se você quiser testá-lo como fizemos), você precisa aplicar um patch abaixo para forçar pt-table-checksum a reconhecer o esquema 'sbtest' como esquema não-sistema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Primeiramente, vamos executar pt-table-checksum da seguinte maneira:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Algumas notas importantes sobre como invocamos a ferramenta. Em primeiro lugar, o usuário que definimos deve existir em todos os escravos. Se desejar, você também pode usar ‘--slave-user’ para definir outro usuário menos privilegiado para acessar escravos. Outra coisa que vale a pena explicar - usamos replicação baseada em linha que não é totalmente compatível com pt-table-checksum. Se você tiver replicação baseada em linha, o que acontece é que pt-table-checksum mudará o formato de log binário em um nível de sessão para 'instrução', pois esse é o único formato suportado. O problema é que tal mudança funcionará apenas em um primeiro nível de escravos que estão diretamente conectados a um mestre. Se você tiver mestres intermediários (portanto, mais de um nível de escravos), usar pt-table-checksum pode quebrar a replicação. É por isso que, por padrão, se a ferramenta detectar a replicação baseada em linha, ela sai e imprime o erro:
“A réplica slave1 tem binlog_format ROW que pode fazer com que pt-table-checksum interrompa a replicação. Leia "Réplicas usando replicação baseada em linha" na seção LIMITAÇÕES da documentação da ferramenta. Se você entender os riscos, especifique --no-check-binlog-format para desabilitar esta verificação.”
Usamos apenas um nível de escravos, então era seguro especificar “--no-check-binlog-format” e seguir em frente.
Finalmente, definimos o atraso máximo para 5 segundos. Se este limite for atingido, pt-table-checksum fará uma pausa por um tempo necessário para trazer o atraso abaixo do limite.
Como você pode ver na saída,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2uma inconsistência foi detectada na tabela sbtest.sbtest2.
Por padrão, pt-table-checksum armazena somas de verificação na tabela percona.checksums. Esses dados podem ser usados para outra ferramenta do Percona Toolkit, pt-table-sync, para identificar quais partes da tabela devem ser verificadas em detalhes para encontrar a diferença exata nos dados.
Como corrigir escravo inconsistente
Como mencionado acima, usaremos pt-table-sync para fazer isso. No nosso caso vamos usar dados coletados por pt-table-checksum embora também seja possível apontar pt-table-sync para dois hosts (o mestre e um escravo) e ele irá comparar todos os dados em ambos os hosts. É definitivamente um processo que consome mais tempo e recursos, portanto, desde que você já tenha dados de pt-table-checksum, é muito melhor usá-lo. Foi assim que o executamos para testar a saída:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Como você pode ver, como resultado, algum SQL foi gerado. Importante notar é a variável --replicate. O que acontece aqui é que apontamos pt-table-sync para a tabela gerada por pt-table-checksum. Também apontamos para o mestre.
Para verificar se o SQL faz sentido, usamos a opção --print. Observe que o SQL gerado é válido apenas no momento em que é gerado - você não pode realmente armazená-lo em algum lugar, revisá-lo e executá-lo. Tudo o que você pode fazer é verificar se o SQL faz algum sentido e, imediatamente após, reexecutar a ferramenta com o sinalizador --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeIsso deve fazer o escravo voltar a sincronizar com o mestre. Podemos verificá-lo com pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Como você pode ver, não há mais diferenças na tabela sbtest.sbtest2.
Esperamos que você tenha achado esta postagem do blog informativa e útil. Clique aqui para saber mais sobre a Replicação MySQL. Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para entrar em contato conosco através dos comentários abaixo.