Os bancos de dados alimentam quase todas as plataformas digitais do planeta:de sites a blogs, mídias sociais e serviços de streaming. A maioria dos usuários finais conhece bancos de dados como o MySQL como uma ferramenta para armazenar dados. Essa é uma descrição bastante precisa, embora fundamental, do que é um banco de dados. No entanto, eles são muito mais do que isso.
Os diferentes tipos de bancos de dados
O termo geral banco de dados muitas vezes confunde dois componentes separados e distintos:o banco de dados e o sistema de gerenciamento de banco de dados (DBMS). O banco de dados armazena os dados e o DBMS é a ferramenta, ou conjunto de ferramentas, que você usa para gerenciar os dados. O SGBD é abordado aqui, pois compreende as ferramentas que permitem que os administradores de banco de dados se comuniquem com o banco de dados para que possam gerenciá-lo e governá-lo totalmente.
Os sistemas de gerenciamento de banco de dados são divididos em três camadas:
- Cliente :faz solicitações por meio da linha de comando ou de uma tela GUI usando consultas SQL válidas.
- Servidor :Responsável por toda a funcionalidade lógica do servidor.
- Armazenamento :lida com o armazenamento de dados.
Dentro dessas camadas estão ferramentas como um manipulador de encadeamento, uma linguagem de consulta, um analisador, um otimizador, um cache de consulta, um buffer, cache de metadados de tabela e um cache de chave. Essas peças se juntam para formar um sistema poderoso para administradores, usuários e software usarem para armazenar e recuperar dados.
Um aspecto crucial do SGBD é a linguagem de consulta. Esta é a linguagem especial usada para interagir com um banco de dados. É uma linguagem muito particular e deve ser utilizada de acordo com as especificações definidas pelo SGBD. Alguns SGBDs têm suas próprias linguagens de consulta proprietárias, mas as mais populares são:
- SQL - Structured Query Language é uma das linguagens de consulta mais usadas no mercado e é usada pelo MS SQL e MySQL.
- XQuery - Usa o formato de arquivo XML para extrair e manipular dados.
- OQL - A linguagem de consulta de objetos é a linguagem padrão para bancos de dados orientados a objetos que são frequentemente usados em casos de uso de Big Data.
- SQL/XML - Uma combinação de SQL e XQuery e suporta instruções SQL em dados XML.
- GraphQL - Uma linguagem de código aberto capaz de trabalhar com APIs e também um tempo de execução que pode ser usado para consultas em dados existentes.
- LINQ - O Language Integrated Query extrai e processa dados de várias fontes, como documentos XML e bancos de dados relacionais.
Bancos de dados relacionais e não relacionais
Os SGBDs usam dois tipos principais de banco de dados:Relacional e Não Relacional. A distinção entre esses dois é importante, pois ajudam a definir o melhor caso de uso para um banco de dados.
Um banco de dados relacional é aquele que armazena informações em tabelas contendo dados relacionados. O que dá nome a um banco de dados relacional é que os relacionamentos podem ser feitos entre duas ou mais tabelas. Os relacionamentos correlacionam linhas pertencentes a duas tabelas diferentes em uma terceira tabela. Os bancos de dados relacionais são melhor usados quando os dados que eles contêm não mudam com frequência e quando a precisão dos dados é crucial.
Bancos de dados não relacionais (também chamados de Bancos de Dados NoSQL) armazenam suas informações em um formato não tabular. Em vez disso, bancos de dados não relacionais armazenam dados em modelos de dados, dos quais os quatro tipos mais comuns são:
- Orientado a documentos - os dados são armazenados como documentos JSON.
- Valor-chave - os dados são armazenados em pares de chaves.
- Gráfico - os dados são armazenados em uma estrutura nó-borda-nó.
- Coluna larga - os dados são armazenados em formato tabular com colunas flexíveis que podem variar de linha para linha.
Como armazenam dados dessa maneira, os bancos de dados não relacionais são muito mais flexíveis. Eles podem armazenar uma grande variedade de diferentes tipos de dados. Isso os torna ideais quando é necessário armazenar grandes quantidades de dados complexos, como ao trabalhar com aplicativos de Big Data.
O que procurar em um banco de dados
A primeira pergunta a fazer é:“Devo usar um banco de dados relacional ou não relacional?” Um banco de dados relacional é melhor usado para instâncias que exigem ACID (Atomicidade, Consistência, Isolamento, Durabilidade) conformidade, precisão de dados, normalização e simplicidade, mas não exigem escalabilidade, flexibilidade e alto desempenho. Um bom exemplo de caso de uso de banco de dados relacional é um site dinâmico, orientado a banco de dados, como o WordPress.
Por outro lado, um banco de dados não relacional é melhor usado quando a flexibilidade, a velocidade e a escalabilidade dos dados são cruciais. Um bom exemplo de caso de uso de banco de dados não relacional é um aplicativo baseado em nuvem que depende de dimensionamento massivo.
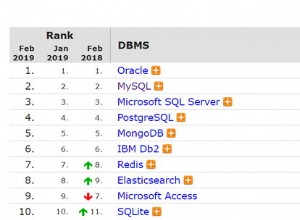
Oito bancos de dados populares
Esta lista dos oito bancos de dados mais populares é dividida em 4 bancos de dados relacionais e 4 não relacionais.
Bancos de dados relacionais
A seguir estão os bancos de dados relacionais mais populares no mercado hoje.
Oráculo
O banco de dados Oracle foi desenvolvido originalmente em 1977, o que o torna o banco de dados mais antigo da lista. Em janeiro de 2022, a Oracle ocupa o primeiro lugar como o sistema de gerenciamento de banco de dados relacional mais usado no mundo (com uma pontuação no ranking Statista de 1266,89).
O Oracle Database vem em cinco edições:
- Empresa - inclui todos os recursos do DBMS, bem como a opção Oracle Real Application Clusters para alta disponibilidade.
- Pessoal - inclui todos os recursos, menos a opção Oracle Real Application Clusters.
- Padrão - inclui funcionalidade básica.
- Expresso - versão limitada leve e gratuita para Windows e Linux.
- Oracle Lite - para casos de uso de dispositivos móveis.
A principal razão pela qual o Oracle Database detém o primeiro lugar no mercado é que ele é um dos bancos de dados relacionais mais escaláveis. Ele consegue isso dividindo sua arquitetura entre o lógico e o físico. Ao fazer isso, a localização dos dados torna-se irrelevante e transparente, o que permite uma estrutura mais modular que pode ser modificada sem afetar o próprio banco de dados. Ao construir o Oracle Database dessa forma, é possível compartilhar recursos para obter uma rede de dados muito mais flexível.
Alguns dos recursos de destaque do Oracle Database incluem:
- Real Application Clustering (RAC) e portabilidade que possibilita o dimensionamento sem perder desempenho e consistência de dados.
- Cache de memória eficiente.
- Particionamento de alto desempenho, que possibilita dividir tabelas maiores em várias partes.
- Backups quentes, frios e incrementais por meio da ferramenta Recovery Manager.
- Ferramentas para controlar o acesso e o uso de dados.
As vantagens do Oracle Database incluem:
- Usa a linguagem de consulta SQL.
- Alto desempenho.
- Portátil (pode ser executado em quase 20 protocolos de rede e várias plataformas de hardware).
- O Instance Caging possibilita a execução de vários gerenciamentos de banco de dados a partir de um único servidor.
- Várias edições para melhor se adequar ao seu negócio e/ou caso de uso.
- Agrupamento para escalabilidade, balanceamento de carga, redundância e desempenho.
- Recuperação de falhas por meio da ferramenta RMAN (Recovery Manager).
- Suporte a PL/SQL.
As desvantagens do Oracle Database incluem:
- Proprietário - O Oracle não é de código aberto.
- Complexidade - É um dos bancos de dados relacionais mais complexos do mercado.
- Custo - O Oracle Database pode ser até 10 vezes mais caro que o MS SQL.
Descubra como usar o Oracle Database Express Edition com Linode.
MySQL
O MySQL é um dos bancos de dados relacionais de código aberto mais populares do mercado. De acordo com a DB-Engines, o MySQL está em segundo lugar, atrás do Oracle Database, em seus bancos de dados mais usados no mercado.
Lançado em maio de 1995, o MySQL é maduro e confiável. É uma das opções mais confiáveis disponíveis. Escrito em C e C++, o MySQL roda em Linux, Solaris, macOS, Windows e FreeBSD, e é licenciado sob a GPLv2.
O MySQL é um banco de dados relacional e não é dimensionado na extensão de um banco de dados não relacional, mas suporta multi-threading, o que possibilita dimensioná-lo de forma que possa lidar com mais de 50 milhões de linhas com um arquivo padrão limite de tamanho de 4 GB, com um limite teórico de 8 TB.
Alguns dos recursos de destaque do MySQL incluem:
Segurança - Usa uma sólida camada de segurança de dados para proteger dados confidenciais e todas as senhas são criptografadas.Reversão - Permite que as transações sejam revertidas.Memória eficiente - Tem vazamento de memória muito baixo.Produtivo - Usa acionadores, procedimentos armazenados e visualizações para maior produtividade.Particionamento - Suporta particionamento para melhorar o desempenho de bancos de dados muito grandes.GUIs - MySQL Workbench GUI gerencia o banco de dados.
As vantagens de usar o MySQL incluem:
- Gratuito - este é um banco de dados gratuito e de código aberto que pode ser instalado em quantas instâncias de servidor você precisar.
- Familiaridade - O MySQL usa a linguagem de consulta SQL, portanto, os administradores de banco de dados familiarizados com a linguagem estão atualizados rapidamente com este DBMS. O MySQL também segue a arquitetura cliente/estrutura típica.
- Velocidade - É um dos bancos de dados relacionais mais rápidos, graças a um mecanismo de armazenamento exclusivo.
- Integração - O MySQL se integra a milhares de aplicativos de terceiros, como sistemas de blogs, CRMs, HRMs, ERPs e muitos outros tipos de aplicativos.
Aprenda como instalar uma instância MySQL em um servidor Linode.
Microsoft SQL Server
Microsoft SQL Server é o DBMS desenvolvido pela Microsoft. Esse banco de dados é uma solução proprietária, mas pode ser instalado tanto no Linux quanto no Windows. O MS SQL Server foi lançado pela primeira vez em 24 de abril de 1989 e agora é oferecido em cinco edições diferentes:
- Padrão - Funcionalidade principal necessária para a maioria dos aplicativos.
- Web - Opção de baixo custo que difere da edição padrão em termos de memória máxima permitida para o pool de buffers e capacidade máxima de computação.
- Empresa - Suporta uma ampla variedade de recursos de data warehouse e inclui recursos avançados, como compactação de dados, segurança aprimorada e suporte para dados maiores.
- Desenvolvedor - Projetado para desenvolvedores e inclui a capacidade de criar procedimentos armazenados, funções e visualizações.
- Expresso - Limitado a indivíduos ou pequenas organizações e não inclui nenhuma funcionalidade avançada.
O MS SQL Server funciona com a linguagem de consulta SQL e usa o SQL Server Operating System (SQLOS), que gerencia recursos de memória e E/S, trabalhos e processamento de dados.
As vantagens do Microsoft SQL Server incluem:
- Suporte nativo para Visual Studio - O suporte para programação de dados é integrado ao Visual Studio, para que os administradores de banco de dados possam criar, visualizar e editar esquemas de banco de dados.
- Serviço de pesquisa de texto completo - Permite pesquisas de consultas baseadas em palavras.
- Suporte a várias versões - Permite a instalação de várias versões do MS SQL Server em uma máquina.
- Fácil instalação - Pode ser instalado com um único clique.
- Restauração e recuperação de dados - Ferramentas integradas para recuperação de dados.
- Suporte - O MS SQL Server tem uma enorme comunidade de usuários com muita ajuda e suporte disponíveis de várias fontes.
As desvantagens do MS SQL são poucas, mas devem ser consideradas por quem pensa em adotar esta plataforma de banco de dados. Essas desvantagens incluem:
- Preços caros e confusos.
- Interface de usuário ruim.
- Concede apenas controle parcial sobre bancos de dados.
PostgreSQL
O PostgreSQL (também chamado de Postgres) é outro sistema de gerenciamento de banco de dados gratuito e de código aberto que originalmente serviu como sucessor do banco de dados Ingres. O PostgreSQL se autodenomina “o banco de dados relacional de código aberto mais avançado do mundo” e atualmente detém uma participação de mercado de 14,70% para bancos de dados relacionais.
Lançado em 1996, o PostgreSQL possui um ciclo de desenvolvimento muito ativo e uma grande comunidade de suporte. O que diferencia o PostgreSQL de outros bancos de dados relacionais de código aberto é que ele é um sistema de gerenciamento de banco de dados objeto-relacional, o que significa que é semelhante a um banco de dados relacional, mas usa um modelo de banco de dados orientado a objetos.
O PostgreSQL é orientado a catálogos, portanto, permite que os usuários definam tipos de dados, tipos de índice e linguagens funcionais, tornando-o mais extensível do que outros bancos de dados relacionais.
Alguns dos recursos de destaque do PostgreSQL incluem:
- Conformidade com ACID.
- Altamente simultâneo.
- Inclui suporte NoSQL
- Suporte de esquema e linguagem de consulta para objetos, classes, herança e sobrecarga de função.
- Expressão de tabela comum (os resultados temporários de uma consulta usada no contexto de uma consulta maior).
- Particionamento declarativo (que reduz a quantidade de trabalho necessária para particionar dados).
- Pesquisa de texto completo.
- Suporte ao Sistema de Informações Geográficas/Sistema de Referência Espacial (para capturar, armazenar, verificar e exibir dados relacionados a posições na superfície da Terra).
- Suporte a JSON.
- Replicação lógica (que é um método de replicação de objetos de dados com base em uma chave primária).
As vantagens do PostgreSQL são:
- Ideal para operações de dados complexas e de alto volume.
- Altamente personalizável por meio de plug-ins e uso de funções personalizadas escritas em C, C++ e Java.
- Controle de simultaneidade de várias versões (uma técnica avançada para melhorar o desempenho do banco de dados em um ambiente multiusuário).
- Os bloqueios de leitura não são necessários, por isso oferece maior escalabilidade do que outros bancos de dados relacionais.
- Multiplataforma (disponível para BSD, Linux, macOS, Solaris e Windows).
Quanto às desvantagens, o PostgreSQL sofre algumas, como:
- Mais complicado que o MySQL.
- Mais lento que o MySQL.
- Não é fácil migrar dados de outros RDBMSes.
- Baixa compactação de dados.
- Escala horizontal complicada.
- Suporte de cluster ruim.
- Não há suporte integrado para aprendizado de máquina.
Confira nosso guia sobre como instalar o PostgreSQL em um servidor Ubuntu 20.04 para obter mais informações.
Bancos de dados não relacionais
As seções a seguir cobrem os bancos de dados não relacionais mais populares no mercado atualmente.
Redis
Redis é um armazenamento de estrutura de dados na memória que é usado como um banco de dados NoSQL de valor-chave distribuído. Redis significa Remote Dictionary Server e usa um armazenamento de valor-chave avançado que inclui durabilidade opcional. O Redis é frequentemente chamado de servidor de estrutura de dados porque as chaves podem conter strings, hashes, listas, conjuntos e conjuntos classificados.
O Redis é um banco de dados volátil na memória, o que o torna uma boa opção para sistemas com uma grande quantidade de dados ativos. O Redis armazena dados em cache, o que torna a leitura/gravação mais rápida e os dados sempre altamente disponíveis.
Os recursos que tornam o Redis excelente incluem:
- Complexidade mínima em comparação com outros bancos de dados NoSQL.
- Leve e não requer dependências externas.
- Funciona em todos os ambientes POSIX.
- Suporte para replicação mestre/escravo síncrona, sem bloqueio, para alta disponibilidade.
- Sistema de cache baseado em valor-chave mapeado, que é comparável ao memcached.
- Sem regras rígidas para definir esquemas ou tabelas.
- Suporte para vários modelos ou tipos de dados.
- Suporte a fragmentação.
- Pode ser usado em conjunto com outros bancos de dados para reduzir a carga e aumentar o desempenho.
As vantagens de usar o Redis incluem:
- Permite armazenar pares de valores-chave de até 512 MB.
- Usa seu próprio mecanismo de hash.
- Graças à replicação de dados, o cache do Redis resiste a falhas e ainda oferece serviço ininterrupto.
- Todas as linguagens de programação populares o suportam.
- Suporta a inserção de grandes quantidades de dados em seu cache.
- Devido ao seu tamanho reduzido, ele pode ser instalado em hardware Raspberry Pi e ARM.
As desvantagens de usar o Redis incluem o seguinte:
- Todos os seus dados devem caber na memória e você não pode gerenciar mais dados do que tem memória.
- Não há linguagem de consulta ou suporte para álgebra relacional.
- Oferece apenas duas opções de persistência (instantâneos e arquivos somente anexados).
- Recursos básicos de segurança.
- Só é executado em um núcleo de CPU no modo de thread único, portanto, a escalabilidade requer várias instâncias do Redis.
Confira nosso guia sobre como instalar e configurar o Redis em um servidor Ubuntu 20.04 para obter mais informações.
MongoDB
O MongoDB é um banco de dados NoSQL de código aberto e orientado a documentos, focado no armazenamento de dados de alto volume. O MongoDB é considerado sem esquema, portanto, não impõe uma estrutura específica em documentos contidos em uma coleção. Originalmente lançado em 2009, esse banco de dados NoSQL usa documentos semelhantes a JSON com esquemas opcionais e pode ser instalado no local ou totalmente gerenciado na nuvem. O MongoDB é considerado um bom candidato para big data e pode ser usado por organizações de todos os tamanhos.
Os recursos que destacam o MongoDB incluem:
- Suporta pesquisas de campo, intervalo e regex.
- Alcança alta disponibilidade com conjuntos de réplicas.
- Suporta fragmentação.
- Pode ser usado como um sistema de arquivos (chamado GridFS).
- Suporta pipeline, função de redução de mapa e métodos de agregação de propósito único.
- JavaScript suportado em consultas.
- Suporta coleções de tamanho fixo, chamadas de coleções limitadas.
- Os índices podem ser criados para melhorar o desempenho da pesquisa.
- Permite que operações sejam executadas em dados agrupados para um único resultado ou resultado calculado.
As vantagens do banco de dados MongoDB incluem:
- Suporta uma linguagem de consulta expressiva.
- Não é necessário gastar tempo projetando um esquema de banco de dados porque ele não tem esquema.
- Flexível e de alto desempenho.
- Suporta eficiência geoespacial.
- Suporta várias transições ACID de documentos.
- Não requer injeção de SQL.
- Pode ser rapidamente integrado ao Hadoop.
- Código aberto e de uso gratuito.
As desvantagens do banco de dados MongoDB incluem:
- Requer uma grande quantidade de memória, especialmente ao dimensionar.
- Limite de armazenamento de documentos de dados de 16 MB.
- Limite de 100 níveis de aninhamento de dados.
- Não é compatível com transações.
- Juntar documentos é complicado.
- Pode ser lento se os índices não forem usados corretamente.
- Como os relacionamentos não são bem definidos, eles podem levar a dados duplicados.
Confira nosso guia sobre casos de uso do MongoDB para obter mais informações.
Apache Cassandra
O Apache Cassandra é um sistema de gerenciamento de banco de dados NoSQL de código aberto e distribuído. Ele foi projetado para lidar com grandes quantidades de dados em servidores comuns. O Cassandra foi originalmente desenvolvido no Facebook para potencializar o recurso de pesquisa de índice da plataforma. Em julho de 2008, o Facebook abriu o Cassandra via Google Code e, em março de 2009, tornou-se oficialmente um projeto Apache Incubator.
Os recursos que destacam o Cassandra incluem:
- Todos os nós distribuídos têm a mesma função, portanto, não há um único ponto de falha.
- Suporta replicação e replicação de vários data centers.
- A taxa de transferência de leitura/gravação aumenta linearmente à medida que as máquinas são adicionadas para obter alta escalabilidade.
- Os dados são replicados automaticamente para vários nós distribuídos.
- Disponibilidade e tolerância de partição são mais importantes que consistência, classificando-o assim como um sistema AP (dentro do teorema CAP).
- Suporta integração Hadoop com suporte MapReduce.
- Inclui sua própria linguagem de consulta, Cassandra Query Language.
As vantagens do Apache Cassandra incluem:
- A escalabilidade elástica possibilita escalar o Cassandra para cima e para baixo conforme necessário, sem tempo de inatividade.
- Segue uma arquitetura ponto a ponto, portanto, a falha é rara em comparação com as configurações mestre-escravo.
- Quatro métodos principais de análise de dados, incluindo integração baseada em Solr, análise em lote (com integração do Hadoop), análise externa (com a ajuda do Hadoop e Cloudera/Hortonworks).
- Análise quase em tempo real.
- Suporte para vários data centers e nuvem híbrida.
- Os dados podem ser armazenados como dados estruturados, semiestruturados ou não estruturados.
As desvantagens do Apache Cassandra incluem:
- Suporte limitado de ACID.
- A latência pode ser um problema devido à grande quantidade de E/S.
- Os dados são modelados em torno de consultas, em vez de estrutura, o que pode resultar em informações duplicadas armazenadas várias vezes.
- Sem suporte para associação ou subconsulta.
- Embora as gravações sejam rápidas, as leituras podem ser lentas.
- Documentação oficial limitada.
Confira nossos guias no Apache Cassandra para saber mais.
CouchDB
O CouchDB é nosso último banco de dados NoSQL de código aberto e orientado a documentos. Essa ferramenta específica armazena dados em documentos JSON e usa JavaScript como linguagem de consulta com a ajuda do MapReduce. O CouchDB abraça a web acessando documentos via HTTP. Uma vez acessados, esses documentos podem ser consultados, combinados e transformados com JavaScript. Esse banco de dados NoSQL é perfeitamente adequado para aplicativos da Web e móveis, graças às transformações de documentos em tempo real e notificações de alterações em tempo real.
Os recursos que destacam o CouchDB incluem:
- Replicação de banco de dados em várias instâncias de servidor.
- Indexação e recuperação rápidas.
- Interface tipo REST.
- Várias bibliotecas facilitam o uso do idioma de sua escolha.
- A GUI baseada em navegador gerencia dados, permissões e configurações.
- Suporte para replicação.
- Segue todos os recursos das propriedades ACID.
- Autenticação e suporte à sessão.
- Segurança no nível do banco de dados.
- Suporte integrado para Map/reduce (modelo para processamento e geração de grandes conjuntos de dados com um algoritmo paralelo distribuído).
As vantagens de usar o CouchDB incluem:
- Capacidade de armazenar o mesmo documento em várias instâncias de banco de dados.
- Os objetos serializados podem ser armazenados como dados não estruturados em documentos JSON.
- Armazenamento de dados redundante. Pode replicar e sincronizar com navegadores, via PouchDB.
- Suporte a fragmentação e clustering.
- A replicação de mestre para mestre permite backup contínuo.
As desvantagens do CouchDB incluem:
- Mais lento que alguns bancos de dados NoSQL.
- Requer muita sobrecarga.
- Consultas arbitrárias são caras.
- As visualizações temporárias de grandes conjuntos de dados são lentas.
- Não há suporte para transações.
- A replicação de banco de dados grande não é confiável.
Confira nosso guia sobre como usar o CouchDB 2.0 no Ubuntu 20.04 para obter mais informações.
Conclusão
Não importa o projeto em que você está trabalhando, há um banco de dados que atende perfeitamente às suas necessidades. Esteja você desenvolvendo um pequeno site dinâmico que depende de altos níveis de consistência de dados, onde você usaria um banco de dados relacional ou um aplicativo que será dimensionado para grandes proporções, onde você usaria um banco de dados não relacional, você tem opções. Com Linode, você pode trabalhar com qualquer um desses bancos de dados para armazenar efetivamente seus dados e interagir com seus aplicativos. É importante, no entanto, saber exatamente o que seu aplicativo precisa de um banco de dados antes de selecionar qual deles. Faça a escolha errada e pode ser caro reequipar.