Analisando um pouco mais a consulta de população-chave
Na parte 3 de nossa série de rastreamento de ODBC, vamos ter uma visão mais aprofundada das chaves de gerenciamento de acesso para tabelas vinculadas de ODBC e como ele classifica e agrupa as consultas SELECT. No artigo anterior, aprendemos como um conjunto de registros do tipo dynaset é, na verdade, 2 consultas separadas, com a primeira consulta buscando apenas as chaves da tabela vinculada ODBC, que é posteriormente usada para preencher os dados. Neste artigo, estudaremos um pouco mais sobre como o Access gerencia as chaves e como ele infere qual é a chave a ser usada para uma tabela vinculada ODBC entre as ramificações que ela possui. Começaremos com a classificação.
Adicionando uma classificação à consulta
Você viu no artigo anterior que começamos com um simples
SELECT sem nenhuma ordenação específica. Você também viu como o Access buscou pela primeira vez o CityID e use o resultado da primeira consulta para preencher as consultas subsequentes para fornecer a aparência de ser rápido ao usuário ao abrir um grande conjunto de registros. Se você já experimentou uma situação em que adicionar uma classificação ou agrupamento a uma consulta, algo repentinamente lento, isso explicará o porquê. Vamos adicionar uma classificação no
StateProvinceID em uma consulta do Access:SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Agora, se rastrearmos o ODBC SQL, devemos ver a saída:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Se você comparar com o rastreamento do artigo anterior, verá que eles são iguais, exceto pela primeira consulta. O Access coloca a ordenação na primeira consulta onde usa para pegar as chaves. Isso faz sentido, pois ao impor a classificação nas chaves que ele usa para percorrer os registros, o Access garante uma correspondência de um para um entre a posição ordinal de um registro e como ele deve ser classificado. Em seguida, ele preenche os registros exatamente da mesma maneira. A única diferença é a sequência de chaves que ele usa para preencher as outras consultas.
Vamos considerar o que acontece quando adicionamos um
GROUP BY fazendo uma contagem das cidades por estado:SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;O rastreamento deve gerar:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Você também deve ter notado que a consulta agora abre lentamente e, embora possa ser definido como um conjunto de registros do tipo dynaset, o Access optou por ignorar isso e basicamente tratá-lo como um conjunto de registros do tipo instantâneo. Isso faz sentido porque a consulta não é atualizável e porque você não pode navegar para uma posição arbitrária em uma consulta como essa. Assim, você deve esperar até que todas as linhas tenham sido buscadas antes de poder navegar livremente. O StateProvinceID não pode ser usado para localizar um registro, pois haveria vários registros nas Cities tabela. Embora eu tenha usado um GROUP BY neste exemplo, ele não precisa ser um agrupamento que faça com que o Access use um conjunto de registros do tipo instantâneo. Usando DISTINCT por exemplo, teria o mesmo efeito. Uma regra prática útil para prever se o Access usará o conjunto de registros do tipo dynaset é perguntar se uma determinada linha no conjunto de registros resultante mapeia de volta para exatamente uma linha na fonte de dados ODBC. Se esse não for o caso, o Access usará o comportamento de instantâneo, mesmo que a consulta devesse usar dynaset. Conseqüentemente, só porque o padrão é um conjunto de registros do tipo dynaset, isso não garante que será de fato um conjunto de registros do tipo dynaset. É apenas um pedido , não uma demanda.
Determinando a chave a ser usada para selecionar
Você deve ter notado no SQL rastreado anterior neste e nos artigos anteriores, o Access usou o
CityID como a chave. Essa coluna foi buscada na primeira consulta e usada nas consultas preparadas subsequentes. Mas como o Access sabe quais colunas de uma tabela vinculada ele deve usar? A primeira inclinação seria dizer que ele verifica uma chave primária e a usa. No entanto, isso seria incorreto. Na verdade, o mecanismo de banco de dados Access fará uso do SQLStatistics do ODBC função durante a vinculação ou re-vinculação da tabela para examinar quais índices estão disponíveis. Essa função retornará um conjunto de resultados com uma linha para cada coluna que participa de um índice para todos os índices. Esse conjunto de resultados é sempre classificado e, por convenção, sempre classificará índices agrupados, índices com hash e outros tipos de índices. Dentro de cada tipo de índice, os índices serão classificados por seus nomes em ordem alfabética. O mecanismo de banco de dados do Access selecionará o primeiro índice exclusivo que encontrar, mesmo que não seja a chave primária real. Para provar isso, vamos criar uma tabela boba com alguns índices ímpares:CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Se preenchermos a tabela com alguns dados e vincularmos a ela no Access e abrirmos uma exibição de folha de dados na tabela vinculada, veremos isso no SQL ODBC rastreado. Por brevidade, apenas os primeiros 2 comandos estão incluídos.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Porque o
OtherStuff participa de um índice clusterizado, ele veio antes da chave primária real e, portanto, foi selecionado pelo mecanismo de banco de dados Access para ser usado no conjunto de registros do tipo dynaset para selecionar uma linha individual. Isso também apesar do fato de que o nome do índice clusterizado exclusivo viria após o nome do índice primário. Uma tática para forçar o mecanismo de banco de dados do Access a selecionar um índice específico para uma tabela seria alterar seu tipo ou renomear o nome para que ele seja classificado em ordem alfabética dentro do grupo do tipo de índice. No caso do SQL Server, as chaves primárias geralmente são clusterizadas e pode haver apenas um índice clusterizado, portanto, é um feliz acidente que geralmente seja o índice correto para o mecanismo de banco de dados do Access usar. No entanto, se o banco de dados do SQL Server contiver tabelas com chaves primárias não clusterizadas e houver um índice exclusivo clusterizado, talvez não seja a escolha ideal. Nos casos em que não há índices agrupados, você pode influenciar quais índices exclusivos são usados nomeando o índice para que ele seja classificado antes de outros índices. Isso pode ser útil com outros softwares RDBMS onde a criação de um índice clusterizado para chave primária não é prático ou possível. Índice do lado do acesso para exibição ou tabela SQL vinculada sem índices
Ao vincular a uma exibição SQL ou a uma tabela SQL que não possui nenhum índice ou chave primária definida, não haverá índices disponíveis para uso do mecanismo de banco de dados do Access. Se você usou o gerenciador de tabelas vinculadas para vincular uma tabela ou uma visualização SQL sem índices, pode ter visto uma caixa de diálogo como esta:
 Se selecionarmos o
Se selecionarmos o ID , conclua a vinculação, abra a tabela vinculada no modo de design e, em seguida, a caixa de diálogo de índices, devemos ver isso: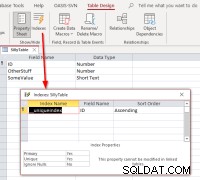 Mostra que a tabela tem um índice chamado
Mostra que a tabela tem um índice chamado __uniqueindex mas não existe na fonte de dados original. O que está acontecendo? A resposta é que o Access criou um Access-side index para seu uso para ajudar a identificar qual pode ser usado como um identificador de registro para tais tabelas ou exibições. Se acontecer de você revincular programaticamente as tabelas em vez de usar o Gerenciador de Tabelas Vinculadas, será necessário replicar o comportamento para tornar essas tabelas vinculadas atualizáveis. Isso pode ser feito executando um comando Access SQL:CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Você pode usar, por exemplo,
CurrentDb.Execute para executar o Access SQL para criar o índice na tabela vinculada. No entanto, você não deve executá-lo como uma consulta de passagem porque o índice não é realmente criado no servidor. É apenas para os benefícios do Access permitir a atualização nessa tabela vinculada. Vale a pena notar que o Access só permitirá exatamente um índice para essa tabela vinculada e somente se já não tiver índices. No entanto, você pode ver que usar uma exibição SQL pode ser uma opção desejável para casos em que o design do banco de dados não permite que você use índices clusterizados e você não queira mexer no nome do índice para persuadir o mecanismo de banco de dados Access a usar esse índice, não esse índice. Você pode controlar explicitamente o índice e as colunas que ele deve incluir ao vincular a exibição SQL.
Conclusões
No artigo anterior, vimos que um conjunto de registros do tipo dynaset geralmente emite 2 consultas. A primeira consulta geralmente lida com o preenchimento do conjunto de registros do tipo dynaset. Vimos como o Access realmente converterá qualquer classificação da consulta original do Access e, em seguida, usará isso na consulta de preenchimento de chaves. Vimos que a ordenação da consulta de população-chave afeta diretamente como os dados no conjunto de registros serão classificados e apresentados ao usuário. Isso permite que o usuário faça coisas como pular para um registro abreviado com base na posição ordinal da lista.
Vimos então que o agrupamento e outras operações SQL que impedem o mapeamento um-um entre a linha retornada e a linha original farão com que o Access trate a consulta do Access como se fosse um conjunto de registros do tipo instantâneo, apesar de solicitar um conjunto de registros do tipo dynaset.
Em seguida, analisamos como o Access determina a chave a ser usada para gerenciar atualizações com uma tabela vinculada ODBC. Ao contrário do que poderíamos esperar, ele não necessariamente selecionará a chave primária da tabela, mas sim o primeiro índice exclusivo que encontrar, dependendo do tipo do índice e do nome do índice. Discutimos estratégias para garantir que o Access selecionará o índice exclusivo correto. Examinamos a exibição SQL que normalmente não possui nenhum índice e discutimos um método para informar ao Access como chavear uma exibição SQL ou uma tabela que não possui nenhuma chave primária, permitindo mais controle sobre como o Access lidará com as atualizações para essas tabelas vinculadas ODBC.
No próximo artigo, veremos como o Access realmente executa atualizações nos dados quando os usuários fazem alterações por meio da consulta ou fonte de registro do Access.
Nossos especialistas em acesso estão disponíveis para ajudar. Ligue para 773-809-5456 ou envie um email para sales@itimpact.com.