não tenho certeza se existe mesmo uma solução com manipulação automática de transações encadeadas / multinível que funcione de maneira confiável (ou não precise de muitos recursos no lado do banco de dados)
bem, você pode combinar as duas etapas em uma:
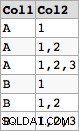
- leia da primeira tabela A
- use o processador para atualizar a tabela A
- use o processador para ler a tabela B
- use o escritor para atualizar a tabela B
o desempenho sofrerá muito, pois a leitura na tabela B será uma leitura única versus o cursor baseado na tabela a
eu iria com uma estratégia de compensação como esta
- As tabelas (opcionais) em uso são tabelas temporárias e não as tabelas reais de "produção", facilita o trabalho de compensação com a dissociação dos armazenamentos de dados da produção
- uma etapa 1 com falha aciona outra etapa ou outro trabalho/script
- esta etapa/trabalho/script exclui conforme necessário (linhas ou tabela completa)