@rob_farley sua solução stackoverflow recente para ordenar primeiro por um valor e depois um campo é gênio! Queria agradecer pessoalmente.
— Joel Sacco (@Jsac90) 11 de agosto de 2016
Eu vi esse tweet passar…
E isso me fez olhar para o que estava se referindo, porque eu não tinha escrito nada 'recentemente' no StackOverflow sobre ordenação de dados. Acontece que foi esta resposta que eu escrevi , que embora não tenha sido a resposta aceita, recebeu mais de uma centena de votos.
A pessoa que fez a pergunta tinha um problema muito simples – querer que certas linhas aparecessem primeiro. E minha solução foi simples:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Parece ter sido uma resposta popular, inclusive para Joel Sacco (de acordo com o tweet acima).
A ideia é formar uma expressão, e ordenar por ela. ORDER BY não se importa se é uma coluna real ou não. Você poderia ter feito o mesmo usando APPLY, se realmente preferir usar uma 'coluna' em sua cláusula ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Se eu usar algumas consultas em WideWorldImporters, posso mostrar por que essas duas consultas realmente são exatamente as mesmas. Vou consultar a tabela Sales.Orders, pedindo que os Orders for Salesperson 7 apareçam primeiro. Também vou criar um índice de cobertura apropriado:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Os planos para essas duas consultas parecem idênticos. Eles executam de forma idêntica – mesmas leituras, mesmas expressões, eles realmente são a mesma consulta. Se houver uma pequena diferença na CPU ou na duração real, isso é um acaso devido a outros fatores.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
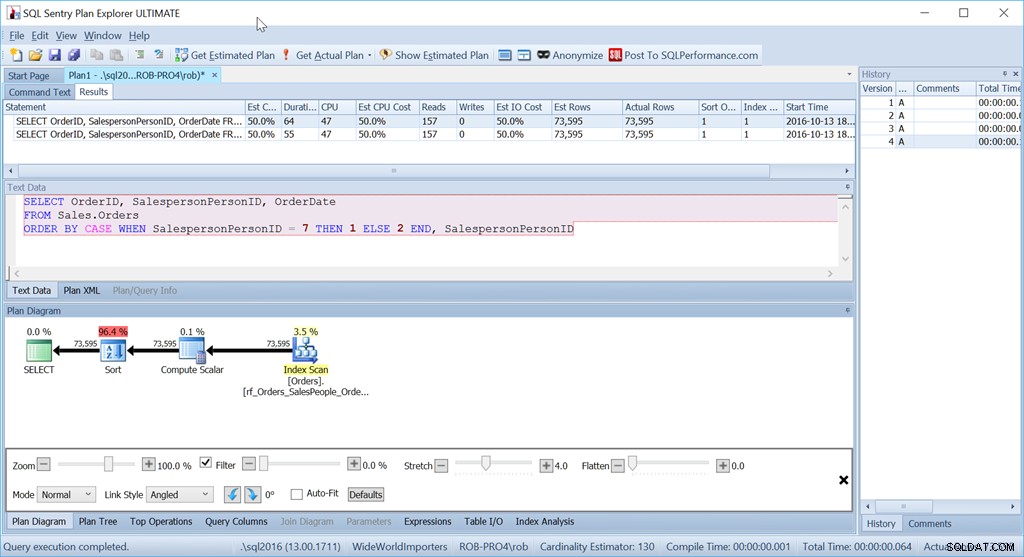
E, no entanto, essa não é a consulta que eu realmente usaria nessa situação. Não se o desempenho fosse importante para mim. (Geralmente é, mas nem sempre vale a pena escrever uma consulta longa se a quantidade de dados for pequena.)
O que me incomoda é esse operador Sort. É 96,4% do custo!
Considere se queremos simplesmente fazer o pedido por SalespersonPersonID:
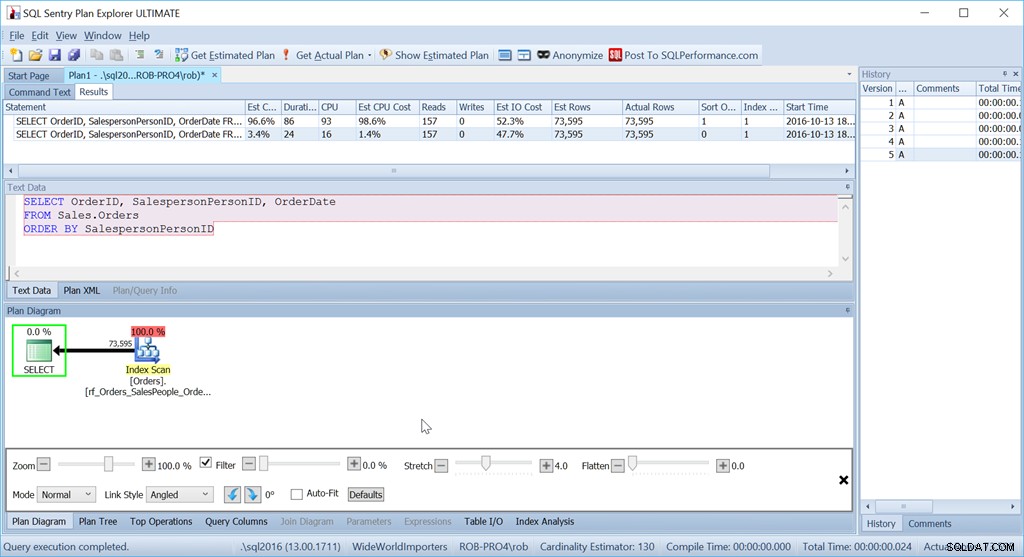
Vemos que o custo estimado de CPU dessa consulta mais simples é de 1,4% do lote, enquanto o da versão com classificação personalizada é de 98,6%. Isso é SETENTA VEZES pior. As leituras são as mesmas – isso é bom. A duração é muito pior, e a CPU também.
Não gosto de Sortes. Eles podem ser desagradáveis.
Uma opção que tenho aqui é adicionar uma coluna computada à minha tabela e indexá-la, mas isso terá um impacto em qualquer coisa que procure todas as colunas na tabela, como ORMs, Power BI ou qualquer coisa que faça SELECT * . Portanto, isso não é tão bom (embora, se alguma vez adicionarmos colunas computadas ocultas, isso seria uma opção muito boa aqui).
Outra opção, que é mais prolixa (alguns podem sugerir que combina comigo – e se você pensou assim:Oi! Não seja tão rude!), e usa mais leituras, é considerar o que faríamos na vida real se precisávamos fazer isso.
Se eu tivesse uma pilha de 73.595 pedidos, ordenados por pedido do vendedor, e precisasse devolvê-los primeiro com um vendedor específico, eu não desconsideraria a ordem em que eles estavam e simplesmente classificaria todos eles, começaria mergulhando e encontrar os do Vendedor 7 – mantendo-os na ordem em que estavam. Então eu encontraria os que não eram os que não eram do Vendedor 7 – colocando-os em seguida e novamente mantendo-os na ordem em que já estavam dentro.
No T-SQL, isso é feito assim:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
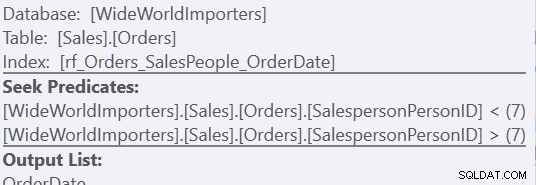
ORDER BY o.OrderingCol, o.SalespersonPersonID; Isso obtém dois conjuntos de dados e os concatena. Mas o Query Optimizer pode ver que precisa manter o pedido SalespersonPersonID, uma vez que os dois conjuntos são concatenados, então ele faz um tipo especial de concatenação que mantém esse pedido. É uma junção de mesclagem (concatenação) e o plano se parece com isso:
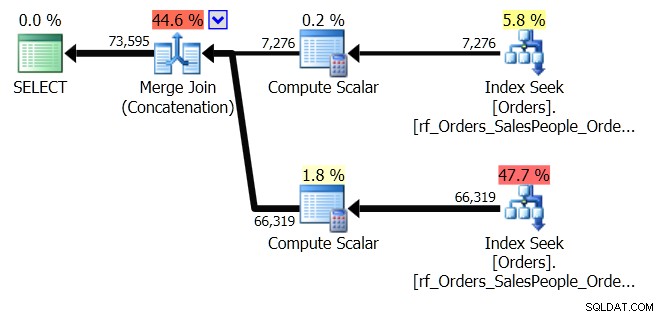
Você pode ver que é muito mais complicado. Mas esperamos que você também perceba que não há um operador Sort. A junção de mesclagem (concatenação) extrai os dados de cada ramificação e produz um conjunto de dados que está na ordem correta. Nesse caso, ele extrairá todas as 7.276 linhas do Vendedor 7 primeiro e, em seguida, extrairá as outras 66.319, porque esse é o pedido necessário. Dentro de cada conjunto, os dados estão na ordem SalespersonPersonID, que é mantida à medida que os dados fluem.
Eu mencionei anteriormente que ele usa mais leituras, e ele faz. Se eu mostrar a saída SET STATISTICS IO, comparando as duas consultas, vejo isso:
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leitura lógica 0, leitura física 0, leitura antecipada 0, leitura lógica lob 0, leitura física lob 0, leitura antecipada lob 0.
Tabela 'Pedidos'. Contagem de varredura 1, leituras lógicas 157, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Pedidos '. Contagem de varredura 3, leituras lógicas 163, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Usando a versão "Custom Sort", é apenas uma varredura do índice, usando 157 leituras. Usando o método "Union All", são três varreduras - uma para SalespersonPersonID =7, uma para SalespersonPersonID <7 e uma para SalespersonPersonID> 7. Podemos ver os dois últimos observando as propriedades do segundo Index Seek:
Para mim, porém, o benefício vem na falta de uma mesa de trabalho.
Veja o custo estimado da CPU:

Não é tão pequeno quanto nosso 1,4% quando evitamos a classificação completamente, mas ainda é uma grande melhoria em relação ao nosso método de classificação personalizada.
Mas um aviso…
Suponha que eu tenha criado esse índice de forma diferente e tivesse OrderDate como uma coluna de chave em vez de uma coluna incluída.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Agora, meu método "Union All" não funciona como pretendido.
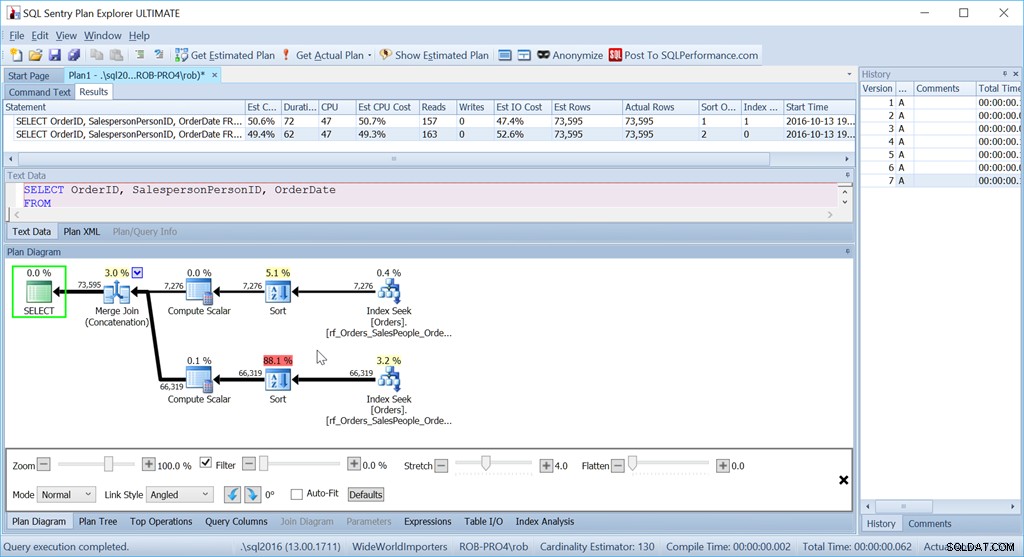
Apesar de usar exatamente as mesmas consultas de antes, meu bom plano agora tem dois operadores de classificação e funciona quase tão mal quanto minha versão original de digitalização + classificação.
A razão para isso é uma peculiaridade do operador Merge Join (Concatenação) e a pista está no operador Sort.

Está ordenando por SalespersonPersonID seguido por OrderID – que é a chave de índice clusterizado da tabela. Ele escolhe isso porque isso é conhecido por ser exclusivo e é um conjunto menor de colunas para classificar do que SalespersonPersonID seguido por OrderDate seguido por OrderID, que é a ordem do conjunto de dados produzida por três varreduras de intervalo de índice. Uma daquelas vezes em que o Otimizador de Consulta não percebe uma opção melhor que está ali.
Com esse índice, precisaríamos de nosso conjunto de dados ordenado por OrderDate também para produzir nosso plano preferido.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate; 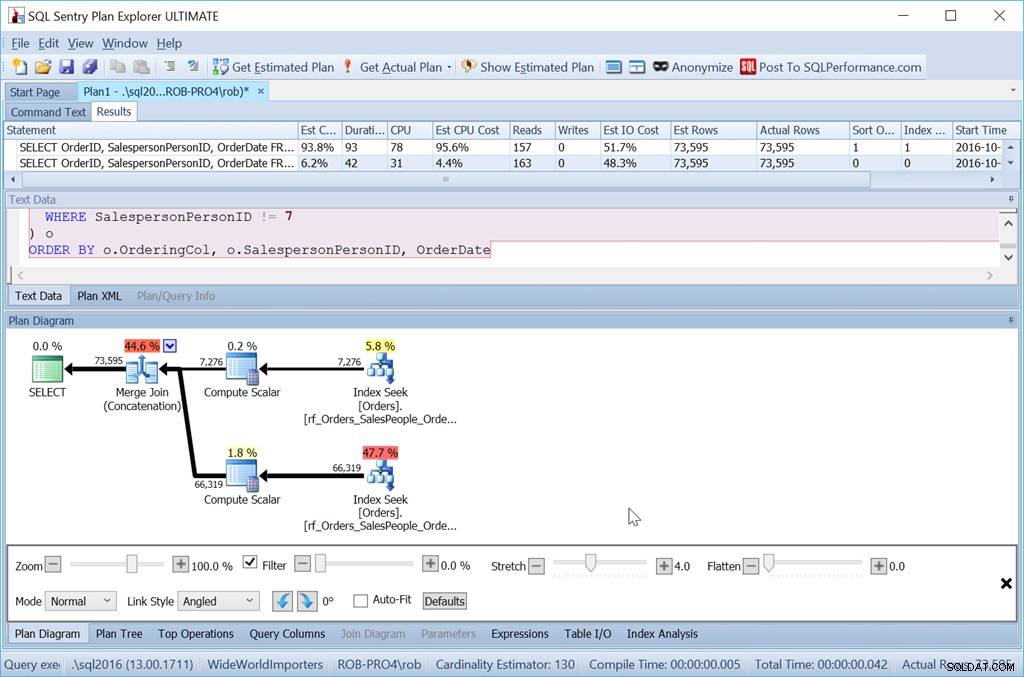
Então é definitivamente mais esforço. A consulta é mais longa para eu escrever, é mais leituras e tenho que ter um índice sem colunas de chave extra. Mas certamente é mais rápido. Com ainda mais linhas, o impacto é ainda maior, e também não preciso correr o risco de um Sort derramar no tempdb.
Para conjuntos pequenos, minha resposta do StackOverflow ainda é boa. Mas quando esse operador Sort está me custando em desempenho, então vou com o método Union All / Merge Join (Concatenação).