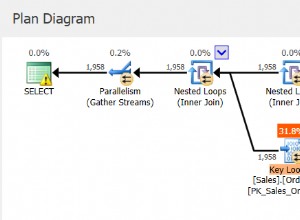
Há alguma falta de precisão nas definições de índices primários e secundários.
Usando dois textos universitários populares como referência:
Fundamentos de sistemas de banco de dados, Elmasri e Navathe os define como:
Database Systems:The Complete Book, Garcia-Molina et. al os define como:
Algumas propriedades que são verdadeiras para qualquer definição acima:
- chaves primárias podem ser índices primários
- pode haver no máximo 1 índice primário por tabela
- os índices primários determinam exclusivamente onde um registro é mantido no armazenamento físico.
- Todos os outros índices são classificados como secundários.
No entanto, se o posicionamento dos registros no arquivo de dados não for determinado por nenhum campo, um índice primário não poderá ser construído.
Assim, para arquivos ordenados, faz sentido falar sobre o índice primário (que seria a lista de campos sobre os quais se baseia a ordenação). Não consigo encontrar outros exemplos de estruturas de arquivos físicos onde um índice primário possa ser construído.
O Postgresql utiliza uma estrutura de heap para o armazenamento físico de registros. Heaps não são classificados (alerta de trocadilho:eles são classificados). Portanto, mesmo as chaves primárias são implementadas usando índices secundários e, como tal, todos os índices no Postgresql são secundários.
Outros sistemas RDBMS fazem implemente formatos de armazenamento que suportem índices primários:
- O InnoDB do MySQL chama isso de índice clusterizado
- O MSSQL também se refere ao índice primário como um índice clusterizado
- A Oracle chama isso de tabelas organizadas por índice
A linguagem na documentação do Postgres é imprecisa.
Isso é verdade.
Não é por isso que todos os índices são secundários no Postgresql. Os índices primários também podem ser armazenados separadamente da área de dados principal da tabela.