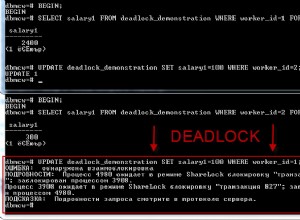
Supondo que a definição da tabela tenha esse núcleo sólido:
CREATE TABLE game_table (
user_id bigint NOT NULL
, date date NOT NULL -- date, not text!
, game_name text NOT NULL
, UNIQUE (date, game_name, user_id) -- !
);
E supondo que você quis dizer o mesmo jogador jogando o mesmo jogo no dia seguinte:
SELECT round(ct_day2 * 100.0 / ct_day1, 2) AS repeat_percentage
FROM (
SELECT count(*) AS ct_day1
, count(d2.user_id) AS ct_day2
FROM instant_game_sessions d1
LEFT JOIN instant_game_sessions d2 ON (d2.user_id, d2.game_name, d2.date)
= (d1.user_id, d1.game_name, d1.date + 1)
WHERE d1.date = '2021-01-07'
AND d1.game_name = 'Chess'
) sub;
O
UNIQUE restrição garante que só pode haver uma única correspondência no dia seguinte. Então count(*) é a contagem correta para o dia 1 e count(d2.user_id) para o dia 2. O resto é óbvio. O
UNIQUE restrição (com nomes de coluna nesta ordem!) também fornece o índice perfeito para a consulta. Ver:Observe que a constante numérica
100.0 o padrão é numérico automaticamente, portanto, não precisamos adicionar nenhum tipo explícito de conversão. Relacionado: