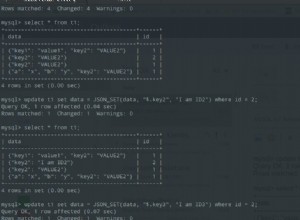
A consulta provavelmente pode ser simplificada para:
SELECT u.name AS user_name
, p.name AS project_name
, tl.created_on::date AS changeday
, coalesce(sum(nullif(new_value, '')::numeric), 0)
- coalesce(sum(nullif(old_value, '')::numeric), 0) AS hours
FROM users u
LEFT JOIN (
tasks t
JOIN fixins f ON f.id = t.fixin_id
JOIN projects p ON p.id = f.project_id
JOIN task_log_entries tl ON tl.task_id = t.id
AND tl.field_id = 18
AND (tl.created_on IS NULL OR
tl.created_on >= '2013-09-08' AND
tl.created_on < '2013-09-09') -- upper border!
) ON t.assignee_id = u.id
WHERE EXISTS (SELECT 1 FROM tasks t1 WHERE t1.assignee_id = u.id)
GROUP BY 1, 2, 3
ORDER BY 1, 2, 3;
Isso retorna todos os usuários que já tiveram alguma tarefa.
Mais dados por projeto e dia onde os dados existem no intervalo de datas especificado em
task_log_entries . Pontos principais
-
A função agregadasum()ignoraNULLvalores.COALESCE()por linha não é mais necessário assim que você reformular o cálculo como a diferença de duas somas:
,coalesce(sum(nullif(new_value, '')::numeric), 0) - coalesce(sum(nullif(old_value, '')::numeric), 0) AS hours
No entanto, se é possível que todos as colunas de uma seleção têmNULLou strings vazias, envolva as somas emCOALESCEuma vez.
Estou usandonumericem vez defloat, alternativa mais segura para minimizar erros de arredondamento.
-
Sua tentativa de obter valores distintos da junção deusersetasksé inútil, já que você se junta ataskmais uma vez mais abaixo. Aplaine toda a consulta para torná-la mais simples e rápida.
-
Estes referências posicionais são apenas uma conveniência de notação:
GROUP BY 1, 2, 3 ORDER BY 1, 2, 3
... fazendo o mesmo que na sua consulta original.
-
Para obter umadatede umtimestampvocê pode simplesmente transmitir paradate:
tl.created_on::date AS changeday
Mas é muito melhor testar com valores originais noWHEREcláusula ouJOINcondição (se possível, e é possível aqui), então o Postgres pode usar índices simples na coluna (se disponível):
AND (tl.created_on IS NULL OR tl.created_on >= '2013-09-08' AND tl.created_on < '2013-09-09') -- next day as excluded upper border
Observe que um literal de data é convertido para umtimestampàs00:00do dia no seu horário atual zona . Você precisa escolher o próximo dia e excluir -lo como borda superior. Ou forneça um literal de carimbo de data/hora mais explícito, como'2013-09-22 0:0 +2':: timestamptz. Mais sobre como excluir a borda superior:
-
Para o requisitoevery user who has ever been assigned to a taskadicione oWHEREcláusula:
WHERE EXISTS (SELECT 1 FROM tasks t1 WHERE t1.assignee_id = u.id) -
O mais importante :ALEFT [OUTER] JOINpreserva todas as linhas à esquerda da junção. Adicionando umWHEREcláusula sobre o direito tabela pode anular este efeito. Em vez disso, mova a expressão de filtro paraJOINcláusula. Mais explicação aqui:
-
Parênteses pode ser usado para forçar a ordem na qual as tabelas são unidas. Raramente necessário para consultas simples, mas muito útil neste caso. Eu uso o recurso para participar datask,fixins,projectsetask_log_entriesantes de juntar tudo à esquerda parausers- sem subconsulta.
-
Aliases de tabela tornar a escrita de consultas complexas mais fácil.