Uma camada de proxy pode ser bastante útil para aumentar a disponibilidade de sua camada de banco de dados. Isso pode reduzir a quantidade de código no lado do aplicativo para lidar com falhas de banco de dados e alterações na topologia de replicação. Nesta postagem do blog, discutiremos como configurar um HAProxy para funcionar em cima do PostgreSQL.
Primeiramente, o HAProxy funciona com bancos de dados como um proxy de camada de rede. Não há compreensão da topologia subjacente, às vezes complexa. Tudo o que o HAProxy faz é enviar pacotes no modo round-robin para back-ends definidos. Ele não inspeciona pacotes nem entende o protocolo no qual as aplicações conversam com o PostgreSQL. Como resultado, não há como o HAProxy implementar a divisão de leitura/gravação em uma única porta - isso exigiria a análise de consultas. Contanto que seu aplicativo possa dividir leituras de gravações e enviá-las para diferentes IPs ou portas, você pode implementar a divisão R/W usando dois back-ends. Vejamos como isso pode ser feito.
Configuração do HAProxy
Abaixo você encontra um exemplo de dois backends PostgreSQL configurados no HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkComo podemos ver, eles usam as portas 3307 para escrita e 3308 para leitura. Nesta configuração existem três servidores - um ativo e duas réplicas em espera. O que é importante, o tcp-check é usado para rastrear a integridade dos nós. O HAProxy se conectará à porta 9201 e espera ver uma string retornada. Membros saudáveis do back-end retornarão o conteúdo esperado, aqueles que não retornarem a string serão marcados como indisponíveis.
Configuração do Xinetd
Como o HAProxy verifica a porta 9201, algo precisa ouvi-la. Podemos usar o xinetd para ouvir e executar alguns scripts para nós. A configuração de exemplo de tal serviço pode ser semelhante a:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Você precisa ter certeza de adicionar a linha:
postgreschk 9201/tcppara o /etc/services.
Xinetd inicia um script postgreschk, que possui conteúdos como abaixo:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";A lógica do script é a seguinte. Existem duas consultas que são usadas para detectar o estado do nó.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"O primeiro verifica se o PostgreSQL está em recuperação - será 'falso' para o servidor ativo e 'verdadeiro' para servidores em espera. A segunda verifica se o PostgreSQL está em modo somente leitura. O servidor ativo retornará 'desligado' enquanto os servidores em espera retornarão 'ligado'. Com base nos resultados, o script chama a função return_ok() com um parâmetro correto (‘master’ ou ‘slave’, dependendo do que foi detectado). Se as consultas falharem, uma função ‘return_fail’ será executada.
A função Return_ok retorna uma string baseada no argumento que foi passado para ela. Se o host for um servidor ativo, o script retornará “PostgreSQL master is running”. Se for standby, a string retornada será:“PostgreSQL slave is running”. Se o estado não estiver claro, ele retornará:“PostgreSQL está em execução”. É aqui que o loop termina. O HAProxy verifica o estado conectando-se ao xinetd. O último inicia um script, que retorna uma string que o HAProxy analisa.
Como você deve se lembrar, o HAProxy espera as seguintes strings:
tcp-check expect string master\ is\ runningpara o back-end de gravação e
tcp-check expect string is\ running.para o back-end somente leitura. Isso torna o servidor ativo o único host disponível no back-end de gravação enquanto no back-end de leitura, tanto os servidores ativos quanto os de espera podem ser usados.
PostgreSQL e HAProxy no ClusterControl
A configuração acima não é complexa, mas leva algum tempo para configurá-la. ClusterControl pode ser usado para configurar tudo isso para você.
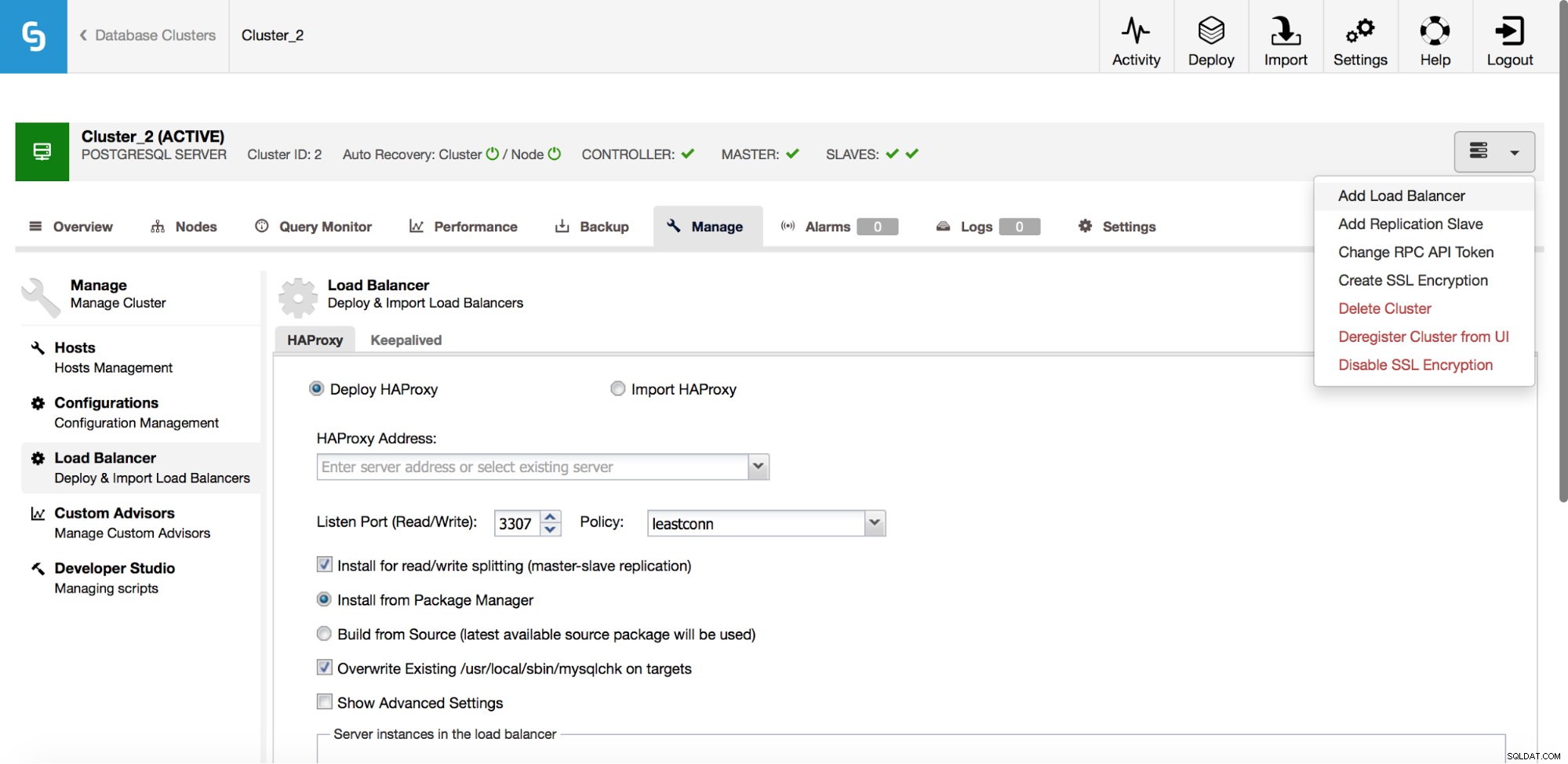
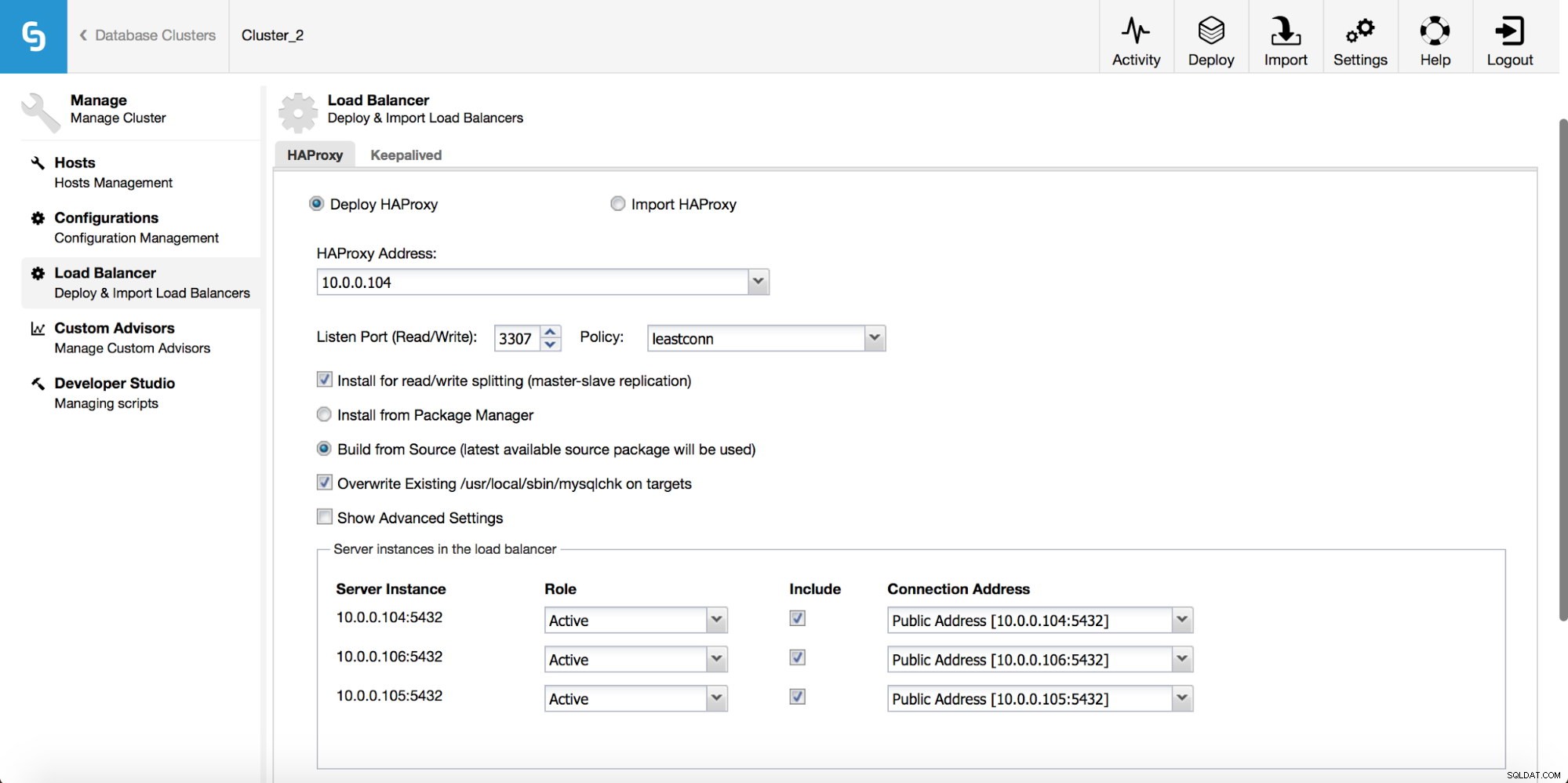
No menu suspenso do trabalho de cluster, você tem a opção de adicionar um balanceador de carga. Em seguida, uma opção para implantar o HAProxy é exibida. Você precisa preencher onde deseja instalá-lo e tomar algumas decisões:dos repositórios que você configurou no host ou da versão mais recente, compilada a partir do código-fonte. Você também precisará configurar quais nós no cluster você gostaria de adicionar ao HAProxy.
Depois que a instância do HAProxy for implantada, você poderá acessar algumas estatísticas na guia “Nodes”:
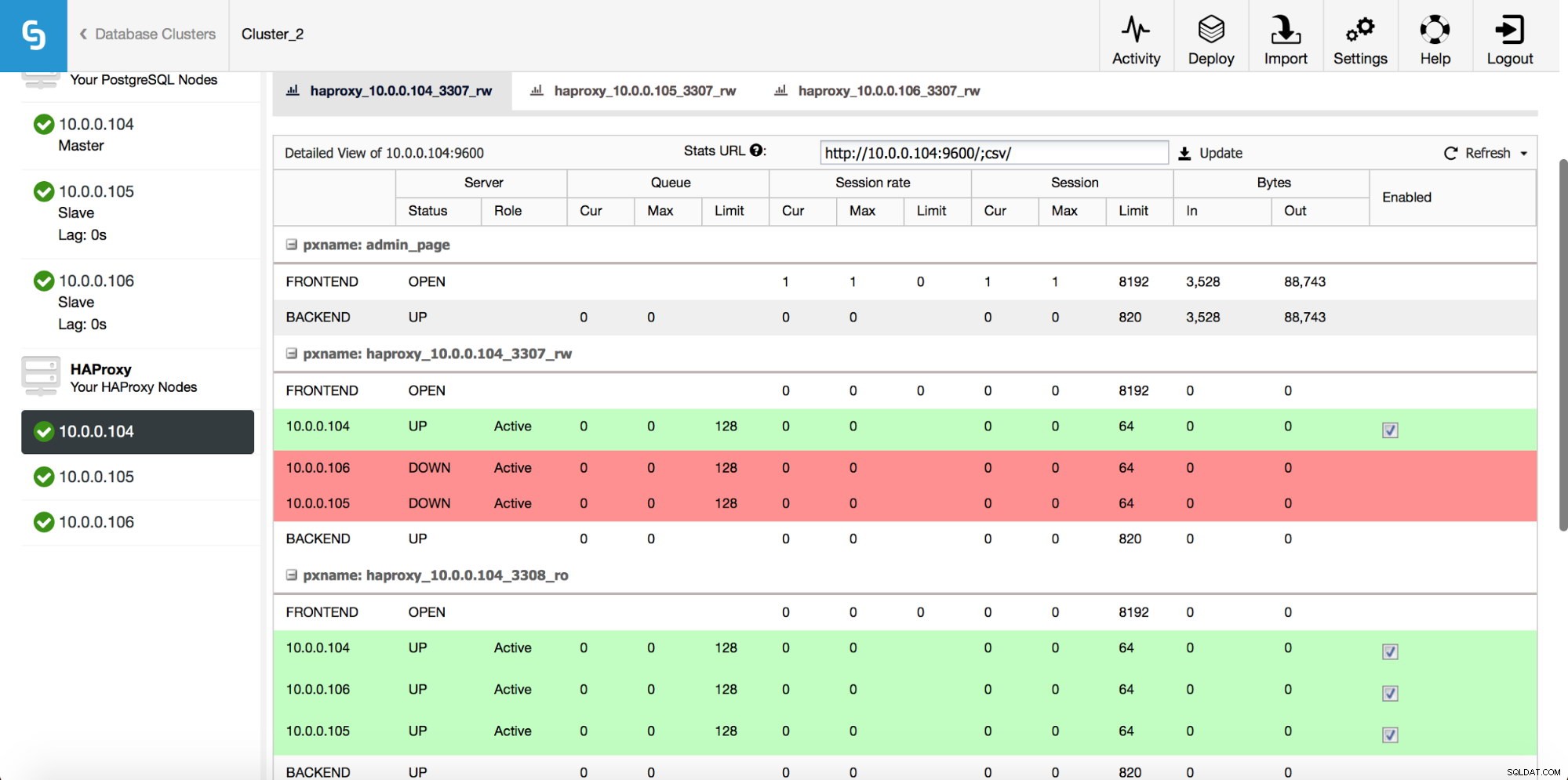
Como podemos ver, para o backend R/W, apenas um host (servidor ativo) é marcado como ativo. Para o back-end somente leitura, todos os nós estão ativos.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Mantido
O HAProxy ficará entre seus aplicativos e instâncias de banco de dados, portanto, desempenhará um papel central. Infelizmente, também pode se tornar um único ponto de falha, caso falhe, não haverá rota para os bancos de dados. Para evitar essa situação, você pode implementar várias instâncias do HAProxy. Mas então a questão é - como decidir a qual host proxy se conectar. Se você implantou o HAProxy do ClusterControl, é tão simples quanto executar outro trabalho “Add Load Balancer”, desta vez implantando o Keepalived.
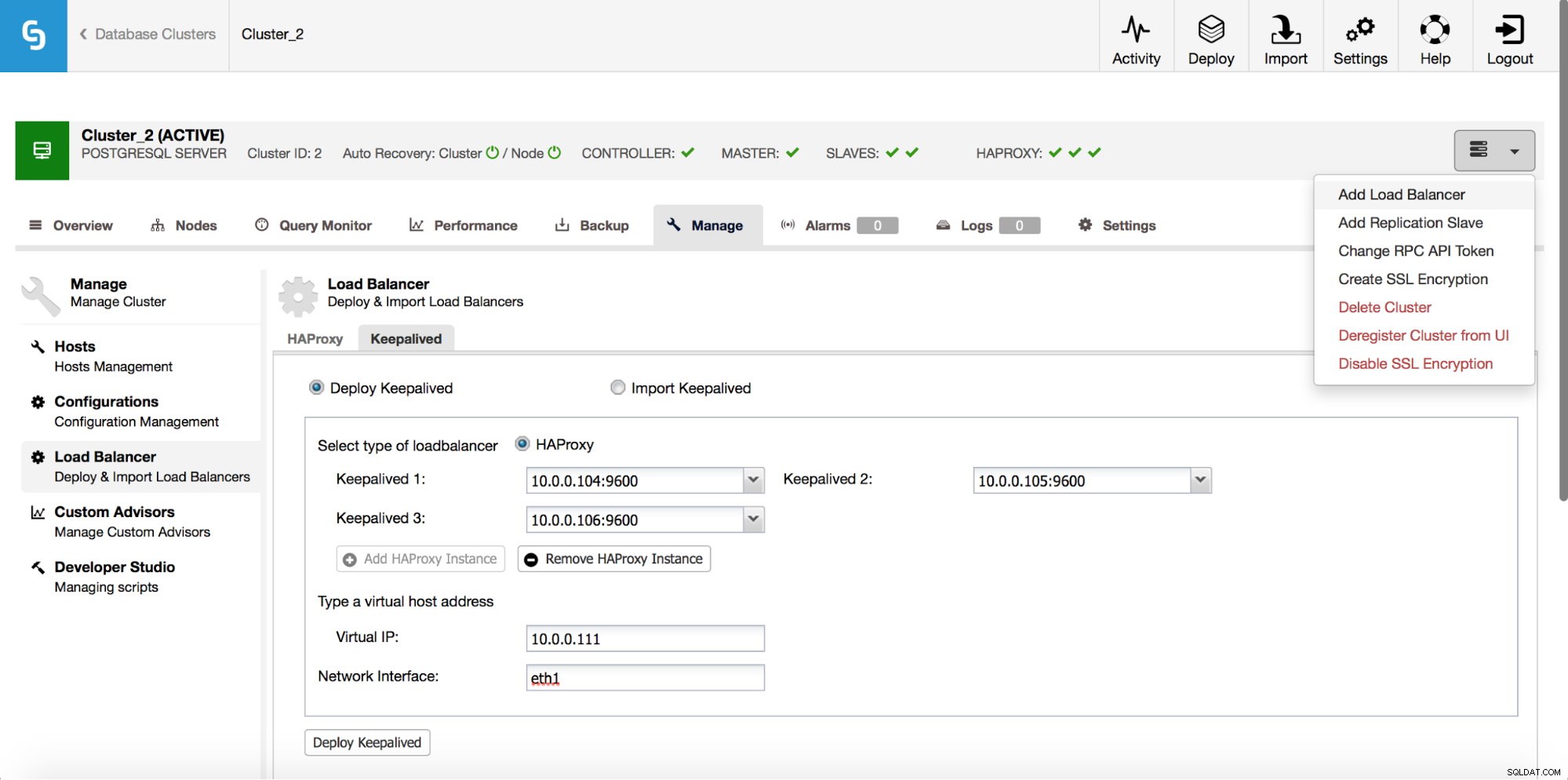
Como podemos ver na captura de tela acima, você pode escolher até três hosts HAProxy e o Keepalived será implantado em cima deles, monitorando seu estado. Um IP virtual (VIP) será atribuído a um deles. Seu aplicativo deve usar esse VIP para se conectar ao banco de dados. Se o HAProxy “ativo” ficar indisponível, o VIP será movido para outro host.
Como vimos, é muito fácil implantar uma pilha completa de alta disponibilidade para o PostgreSQL. Experimente e deixe-nos saber se você tem algum feedback.