Na primeira parte desta série de blogs, apresentei alguns resultados de benchmark mostrando como o desempenho do OLTP do PostgreSQL mudou desde o 8.3, lançado em 2008. Nesta parte, pretendo fazer a mesma coisa, mas para consultas analíticas/BI, processando grandes quantidades de dados.
Há vários benchmarks do setor para testar essa carga de trabalho, mas provavelmente o mais usado é o TPC-H, então é isso que usarei para esta postagem no blog. Há também o TPC-DS, outro benchmark TPC para testar sistemas de apoio à decisão, que pode ser visto como uma evolução ou substituição do TPC-H. Decidi ficar com o TPC-H por alguns motivos.
Em primeiro lugar, o TPC-DS é muito mais complexo, tanto em termos de esquema (mais tabelas) quanto em número de consultas (22 vs. 99). Ajustar isso corretamente, principalmente ao lidar com várias versões do PostgreSQL, seria muito mais difícil. Em segundo lugar, algumas das consultas TPC-DS usam recursos que não são suportados por versões mais antigas do PostgreSQL (por exemplo, conjuntos de agrupamento), tornando essas consultas irrelevantes para algumas versões. E, finalmente, eu diria que as pessoas estão muito mais familiarizadas com o TPC-H em comparação com o TPC-DS.
O objetivo disso não é permitir a comparação com outros produtos de banco de dados, apenas fornecer uma caracterização de longo prazo razoável de como o desempenho do PostgreSQL evoluiu desde o PostgreSQL 8.3.
Observação :Para uma análise muito interessante do benchmark TPC-H, recomendo fortemente o artigo “TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark” de Boncz, Neumann e Erling.
O hardware
A maioria dos resultados desta postagem do blog vem da “caixa maior” que tenho em nosso escritório, que possui esses parâmetros:
- 2x E5-2620 v4 (16 núcleos, 32 threads)
- 64 GB de RAM
- Intel Optane 900P 280GB NVMe SSD (dados)
- 3 x 7,2k SATA RAID0 (espaço de tabela temporário)
- kernel 5.6.15, sistema de arquivos ext4
Tenho certeza de que você pode comprar máquinas significativamente mais robustas, mas acredito que isso seja bom o suficiente para nos fornecer dados relevantes. Havia duas variantes de configuração – uma com paralelismo desabilitado, outra com paralelismo habilitado. A maioria dos valores dos parâmetros são os mesmos em ambos os casos, ajustados aos recursos de hardware disponíveis (CPU, RAM, armazenamento). Você pode encontrar informações mais detalhadas sobre a configuração no final deste post.
A referência
Quero deixar bem claro que não é meu objetivo implementar um benchmark TPC-H válido que possa passar por todos os critérios exigidos pelo TPC. Meu objetivo é avaliar como o desempenho de diferentes consultas analíticas mudou ao longo do tempo, não perseguir alguma medida abstrata de desempenho por dólar ou algo assim.
Então, decidi usar apenas um subconjunto de TPC-H – basicamente apenas carregar os dados e executar as 22 consultas (os mesmos parâmetros em todas as versões). Não há atualizações de dados, o conjunto de dados é estático após o carregamento inicial. Eu escolhi uma série de fatores de escala, 1, 10 e 75, para que tenhamos resultados para buffers compartilhados (1), memória interna (10) e mais que memória (75) . Eu iria para 100 para torná-lo uma “sequência legal”, que não caberia no armazenamento de 280 GB em alguns casos (graças a índices, arquivos temporários etc.). Observe que o fator de escala 75 nem é reconhecido pelo TPC-H como um fator de escala válido.
Mas faz sentido comparar conjuntos de dados de 1 GB ou 10 GB? As pessoas tendem a se concentrar em bancos de dados muito maiores, então pode parecer um pouco tolo se preocupar em testá-los. Mas eu não acho que isso seria útil – a grande maioria dos bancos de dados na natureza é bastante pequena, na minha experiência. pedidos não resolvidos, etc. Então eu acredito que faz sentido testar mesmo com esses pequenos conjuntos de dados.
Carregamentos de dados
Primeiro, vamos ver quanto tempo leva para carregar dados no banco de dados – sem e com paralelismo. Mostrarei apenas os resultados do conjunto de dados de 75 GB, porque o comportamento geral é quase o mesmo para os casos menores.
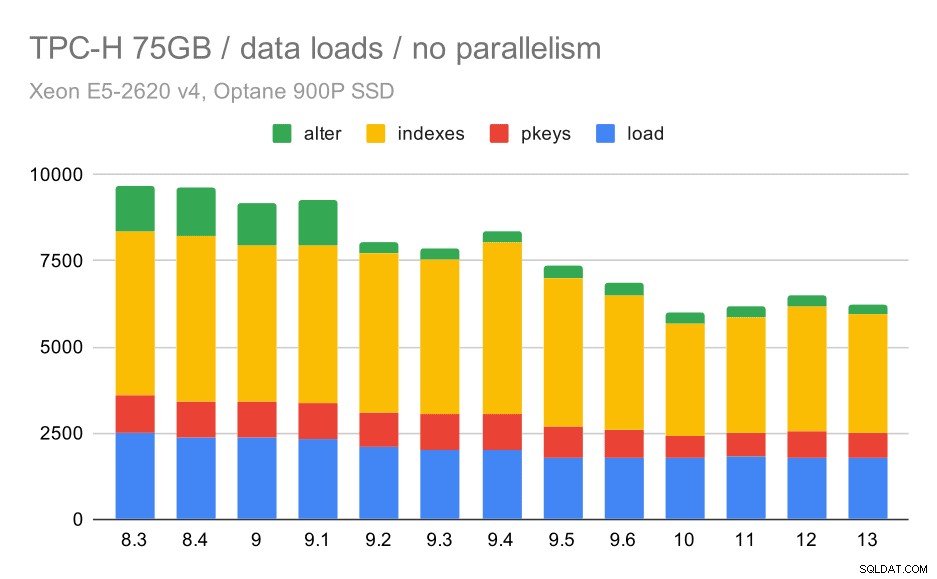
Duração do carregamento de dados TPC-H – dimensione 75 GB, sem paralelismo
Você pode ver claramente que há uma tendência constante de melhorias, reduzindo cerca de 30% da duração apenas melhorando a eficiência em todas as quatro etapas – COPIAR, criar chaves primárias e índices e (especialmente) configurar chaves estrangeiras. A melhoria "alter" em 9.2 é particularmente clara.
| COPIAR | PKEYS | INDEXES | ALTER | |
| 8,3 | 2531 | 1156 | 1922 | 1615 |
| 8,4 | 2374 | 1171 | 1891 | 1370 |
| 9,0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9,2 | 2104 | 1120 | 1833 | 1157 |
| 9,3 | 2008 | 1089 | 1836 | 1229 |
| 9,4 | 1990 | 1168 | 1818 | 1197 |
| 9,5 | 1982 | 1000 | 1903 | 1203 |
| 9,6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Agora, vamos ver como habilitar o paralelismo muda o comportamento. O gráfico a seguir compara resultados com paralelismo ativado – marcado com “(p)” – com resultados com paralelismo desativado.
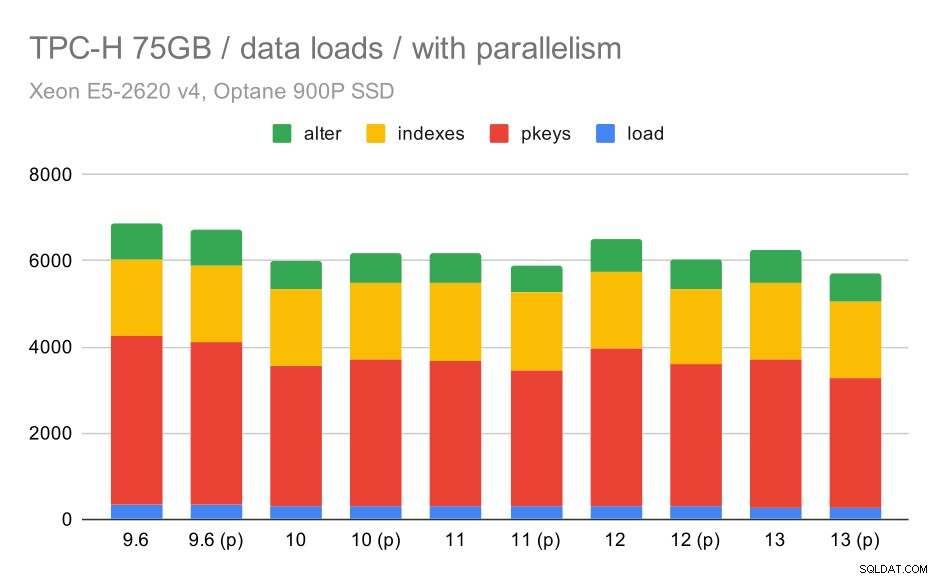
Duração do carregamento de dados TPC-H – escala 75 GB, paralelismo ativado.
Infelizmente, parece que o efeito do paralelismo é muito limitado neste teste – ajuda um pouco, mas as diferenças são bem pequenas. Portanto, a melhoria geral permanece em torno de 30%.
| COPIAR | PKEYS | INDEXES | ALTER | |
| 9,6 | 344 | 3902 | 1786 | 831 |
| 9,6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Consultas
Agora podemos dar uma olhada nas consultas. O TPC-H tem 22 modelos de consulta – gerei um conjunto de consultas reais e as executei em todas as versões duas vezes – primeiro depois de descartar todos os caches e reiniciar a instância, depois com o cache aquecido. Todos os números apresentados nos gráficos são os melhores dessas duas corridas (na maioria dos casos é a segunda, claro).
Sem paralelismo
Sem paralelismo, os resultados no menor conjunto de dados são bastante claros – cada barra é dividida em várias partes com cores diferentes para cada uma das 22 consultas. É difícil dizer qual parte mapeia para qual consulta exata, mas é suficiente para identificar casos em que uma consulta melhora ou piora muito entre duas execuções. Por exemplo, no primeiro gráfico, fica muito claro que o Q21 ficou muito mais rápido entre 8,3 e 8,4.
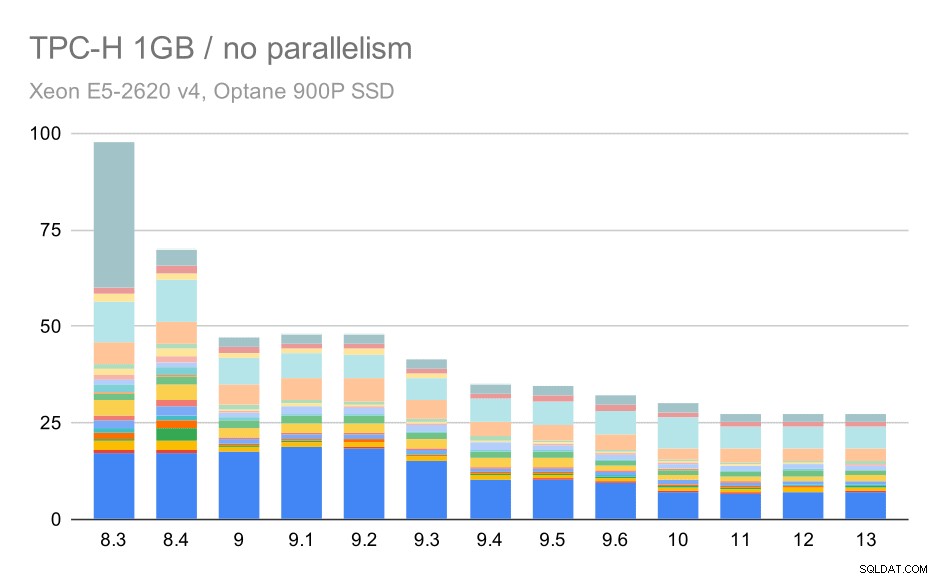
Consultas TPC-H em conjunto de dados pequeno (1 GB) – paralelismo desativado
Para a escala de 10 GB, os resultados são um pouco difíceis de interpretar, porque em 8,3 uma das consultas (Q21) leva tanto tempo para ser executada que supera todo o resto.
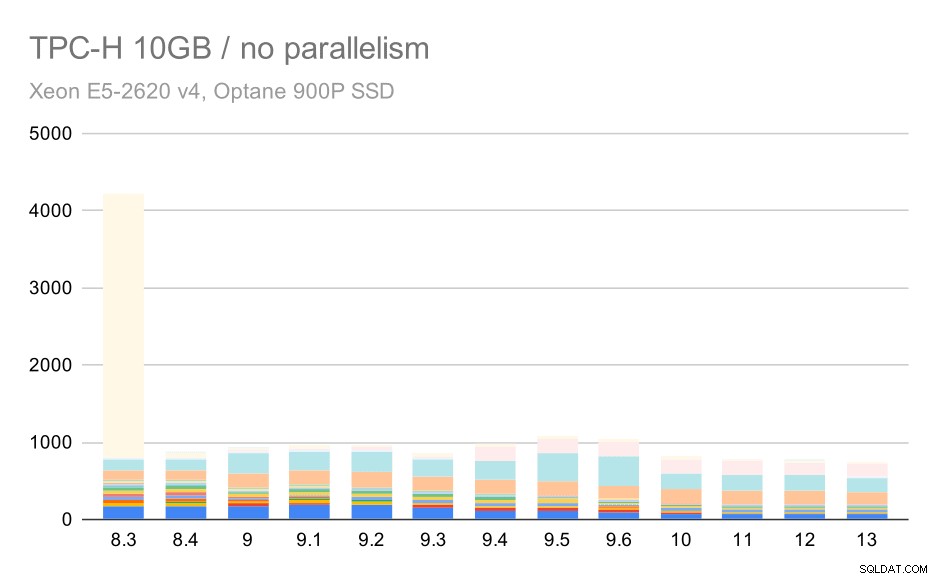
Consultas TPC-H no conjunto de dados médio (10 GB) – paralelismo desativado
Então, vamos ver como ficaria o gráfico sem o Q21:
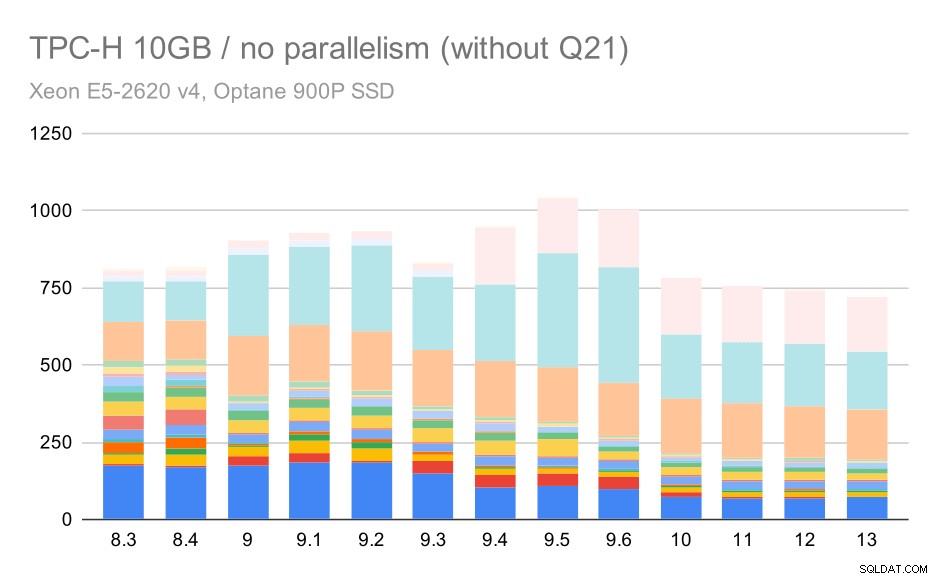
Consultas TPC-H no conjunto de dados médio (10 GB) – paralelismo desabilitado, sem problemas no segundo trimestre
OK, isso é mais fácil de ler. Podemos ver claramente que a maioria das consultas (até Q17) ficou mais rápida, mas duas das consultas (Q18 e Q20) ficaram um pouco mais lentas. Veremos um problema semelhante no maior conjunto de dados, então discutirei qual pode ser a causa raiz.
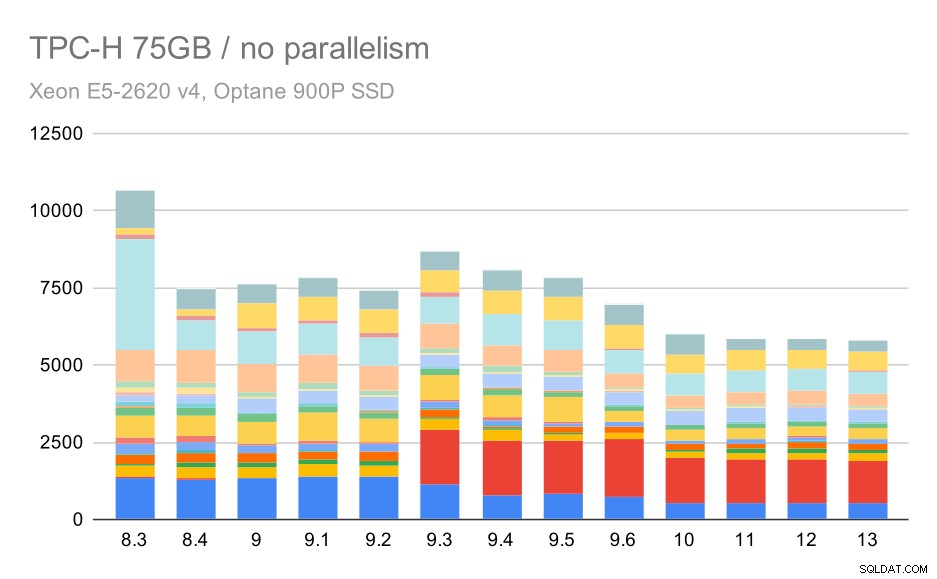
Consultas TPC-H em grandes conjuntos de dados (75 GB) – paralelismo desabilitado
Novamente, vemos um aumento repentino para uma das consultas em 9.3 – desta vez é o segundo trimestre, sem o qual o gráfico fica assim:
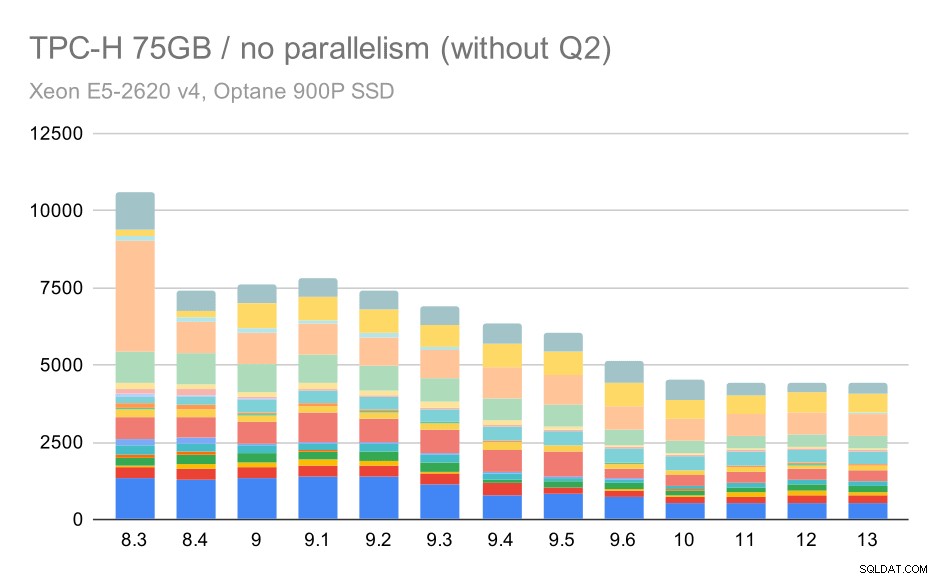
Consultas TPC-H em grandes conjuntos de dados (75 GB) – paralelismo desabilitado, sem problemas no segundo trimestre
Essa é uma melhoria muito boa em geral, acelerando toda a execução de ~ 2,7 horas para apenas ~ 1,2 h, apenas tornando o planejador e o otimizador mais inteligentes e tornando o executor mais eficiente (lembre-se, o paralelismo foi desativado nessas execuções) .
Então, qual poderia ser o problema com o Q2, tornando-o mais lento no 9.3? A resposta simples é que toda vez que você torna o planejador e otimizador mais inteligente – seja construindo novos tipos de caminhos/planos, ou tornando-o dependente de algumas estatísticas, isso também significa que novos erros podem ser cometidos quando as estatísticas ou estimativas estão erradas. No segundo trimestre, a cláusula WHERE faz referência a uma subconsulta agregada – uma versão simplificada da consulta pode ter esta aparência:
selecione 1From Partsupwhere Ps_supplyCost =(selecione min (ps_supplycost) de Partsupp, fornecedor, nação, região onde p_partKey =ps_partKey e s_suppkey =r_s_suppkey e s_nationKey =n_nationKey e n_regionAkey =r_nation;
O problema é que não sabemos o valor médio no momento do planejamento, tornando impossível calcular estimativas suficientemente boas para a condição WHERE. O Q2 real contém junções adicionais, e o planejamento dessas fundamentalmente depende de boas estimativas das relações unidas. Nas versões mais antigas, o otimizador parece estar fazendo a coisa certa, mas na 9.3 nós o tornamos mais inteligente de alguma forma, mas com a estimativa ruim, ele não consegue tomar a decisão certa. Em outras palavras, os bons planos nas versões mais antigas eram apenas sorte, graças às limitações do planejador.
Aposto que as regressões de Q18 e Q20 no conjunto de dados menor também são causadas por algo semelhante, embora eu não tenha investigado isso em detalhes.
Acredito que alguns desses problemas do otimizador podem ser corrigidos ajustando os parâmetros de custo (por exemplo, random_page_cost etc.), mas não tentei isso devido a restrições de tempo. No entanto, mostra que as atualizações não melhoram automaticamente todas as consultas – às vezes, uma atualização pode desencadear uma regressão, portanto, o teste apropriado de seu aplicativo é uma boa ideia.
Paralelismo
Então, vamos ver o quanto o paralelismo de consulta altera os resultados. Novamente, veremos apenas os resultados das versões desde 9.6 rotulando os resultados com “(p)” onde a consulta paralela está habilitada.
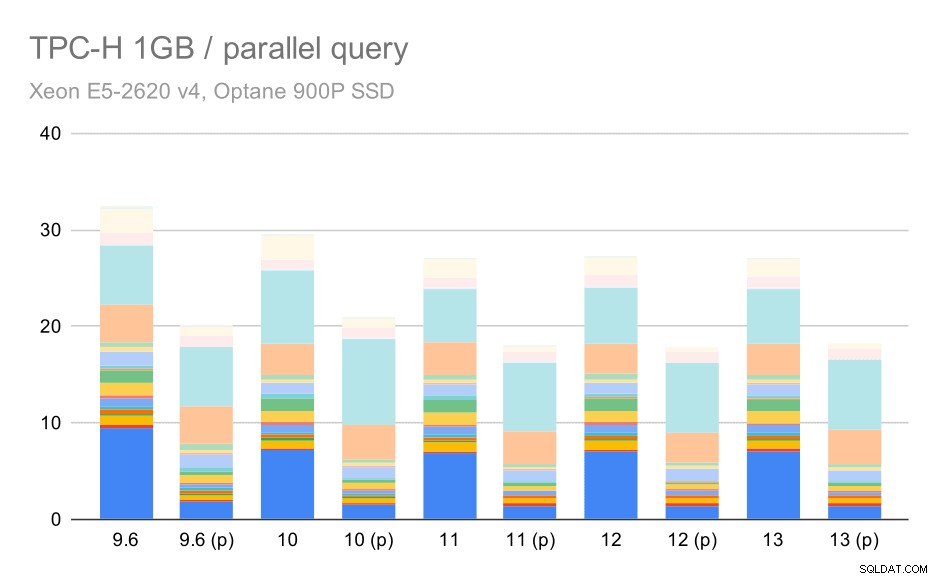
Consultas TPC-H em conjunto de dados pequeno (1 GB) – paralelismo ativado
Claramente, o paralelismo ajuda bastante – reduz cerca de 30% mesmo neste pequeno conjunto de dados. No conjunto de dados médio, não há muita diferença entre execuções regulares e paralelas:
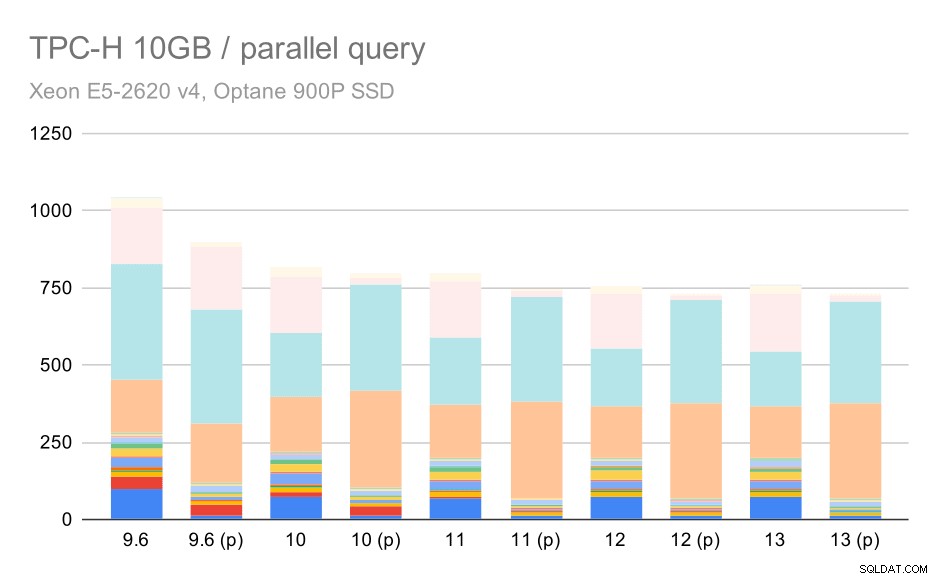
Consultas TPC-H no conjunto de dados médio (10 GB) – paralelismo ativado
Esta é mais uma demonstração da questão já discutida – habilitar o paralelismo permite considerar planos de consulta adicionais, e claramente as estimativas ou custos não condizem com a realidade, resultando em más escolhas de planos.
E, finalmente, o grande conjunto de dados, onde os resultados completos são assim:
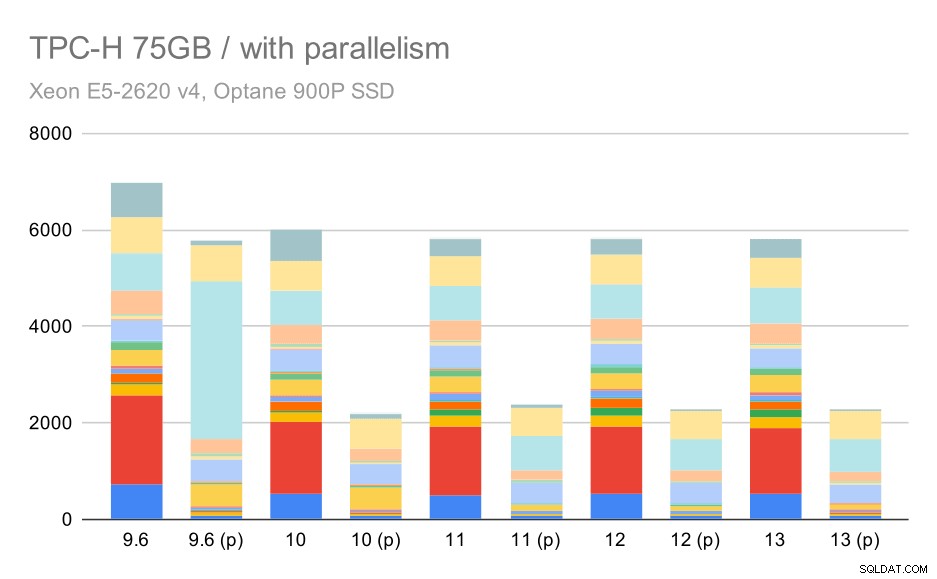
Consultas TPC-H em grandes conjuntos de dados (75 GB) – paralelismo ativado
Aqui, habilitar o paralelismo funciona em nossa vantagem – o otimizador consegue construir um plano paralelo mais barato para Q2, substituindo a escolha de plano ruim introduzida em 9.3. Mas apenas para completar, aqui estão os resultados sem Q2.
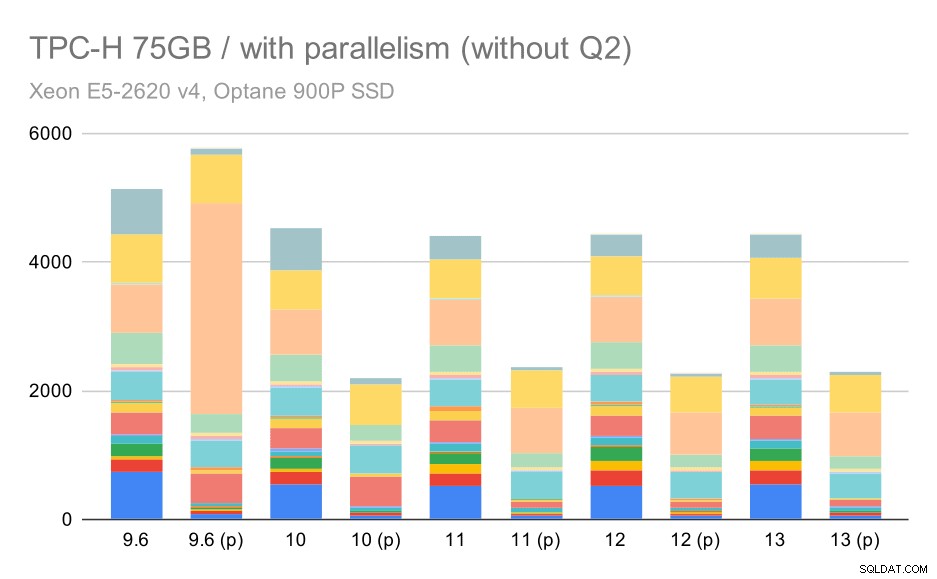
Consultas TPC-H em grandes conjuntos de dados (75 GB) – paralelismo ativado, sem problemas no segundo trimestre
Mesmo aqui você pode identificar algumas escolhas de planos paralelos ruins – por exemplo, o plano paralelo para Q9 é pior até 11, onde fica mais rápido – provavelmente graças ao suporte de 11 nós executores paralelos adicionais. Por outro lado, algumas consultas paralelas (Q18, Q20) ficam mais lentas no 11, então não são apenas arco-íris e unicórnios.
Resumo e futuro
Acho que esses resultados demonstram bem as otimizações implementadas desde o PostgreSQL 8.3. Os testes com paralelismo desabilitado ilustram melhorias na eficiência (ou seja, fazer mais com a mesma quantidade de recursos) – as cargas de dados ficaram ~30% mais rápidas e as consultas ficaram ~2x mais rápidas. É verdade que tive alguns problemas com planos de consulta ineficientes, mas esse é um risco inerente ao tornar o planejador de consulta mais inteligente. Estamos trabalhando continuamente para tornar os resultados mais confiáveis e tenho certeza de que poderia mitigar a maioria desses problemas ajustando um pouco a configuração.
Os resultados com paralelismo ativado mostram que podemos utilizar recursos extras de forma eficaz (núcleos de CPU em particular). As cargas de dados não parecem se beneficiar muito disso – pelo menos não neste benchmark, mas o impacto na execução da consulta é significativo, resultando em uma aceleração de ~2x (embora consultas diferentes sejam afetadas de maneira diferente, é claro).
Existem muitas oportunidades para melhorar isso em futuras versões do PostgreSQL. Por exemplo, há uma série de patches implementando paralelismo para COPY, acelerando os carregamentos de dados. Existem vários patches que melhoram a execução de consultas analíticas - de pequenas otimizações localizadas a grandes projetos, como armazenamento e execução colunar, push-down agregado, etc. Muito pode ser ganho usando o particionamento declarativo também - um recurso que eu ignorei principalmente enquanto trabalhava nisso referência, simplesmente porque aumentaria muito o escopo. E tenho certeza de que existem muitas outras oportunidades que nem consigo imaginar, mas pessoas mais inteligentes da comunidade PostgreSQL já estão trabalhando nelas.
Apêndice:Configuração do PostgreSQL
Paralelismo desativado
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32 GB
Paralelismo ativado
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizedefault_statistics_target =1000random_page_cost =60effective_cache_size =32 GB



