Introdução
Um Carretel de índice ansioso lê todas as linhas de seu operador filho em uma tabela de trabalho indexada, antes de começar a retornar linhas para seu operador pai. Em alguns aspectos, um spool de índice ansioso é a melhor sugestão de índice ausente , mas não é relatado como tal.
Avaliação de custos
A inserção de linhas em uma tabela de trabalho indexada é relativamente barata, mas não é gratuita. O otimizador deve considerar que o trabalho envolvido economiza mais do que custa. Para que isso funcione a favor do carretel, o plano deve ser estimado para consumir linhas do carretel mais de uma vez. Caso contrário, ele também pode pular o spool e apenas fazer a operação subjacente daquela vez.
- Para ser acessado mais de uma vez, o spool deve aparecer no lado interno de um operador de junção de loops aninhados.
- Cada iteração do loop deve buscar um valor de chave de spool de índice específico fornecido pelo lado externo do loop.
Isso significa que a junção precisa ser um aplicar , não uma junção de loops aninhados . Para saber a diferença entre os dois, veja meu artigo Apply versus Nested Loops Join.
Recursos notáveis
Enquanto um spool de índice ansioso pode aparecer apenas no lado interno de um loop aninhado aplicar , não é um “carretel de desempenho”. Um spool de índice antecipado não pode ser desabilitado com o sinalizador de rastreamento 8690 ou o
NO_PERFORMANCE_SPOOL dica de consulta. As linhas inseridas no spool de índice normalmente não são pré-classificadas na ordem de chave de índice, o que pode resultar em divisões de página de índice. O sinalizador de rastreamento não documentado 9260 pode ser usado para gerar uma Classificação operador antes do carretel de índice para evitar isso. A desvantagem é que o custo extra de classificação pode dissuadir o otimizador de escolher a opção de carretel.
O SQL Server não oferece suporte a inserções paralelas em um índice de árvore b. Isso significa que tudo abaixo de um spool de índice ansioso paralelo é executado em um único thread. Os operadores abaixo do carretel ainda estão (de forma enganosa) marcados com o ícone de paralelismo. Um tópico é escolhido para escrever ao carretel. Os outros threads aguardam em
EXECSYNC enquanto isso termina. Depois que o spool for preenchido, ele poderá ser lido de por fios paralelos. Os spools de índice não informam ao otimizador que eles suportam a saída ordenada pelas chaves de índice do spool. Se a saída classificada do spool for necessária, você poderá ver um Classificar desnecessário operador. Os spools de índice ansiosos geralmente devem ser substituídos por um índice permanente de qualquer maneira, portanto, essa é uma preocupação menor na maioria das vezes.
Existem cinco regras do otimizador que podem gerar um Eager Index Spool opção (conhecida internamente como index on-the-fly ). Veremos três deles em detalhes para entender de onde vêm os spools de índice ansiosos.
SelToIndexOnTheFly
Este é o mais comum. Ele corresponde a uma ou mais seleções relacionais (também conhecidas como filtros ou predicados) logo acima de um operador de acesso a dados. O
SelToIndexOnTheFly A regra substitui os predicados por um predicado de busca em um spool de índice ansioso. Demonstração
Um AdventureWorks exemplo de banco de dados é mostrado abaixo:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'; 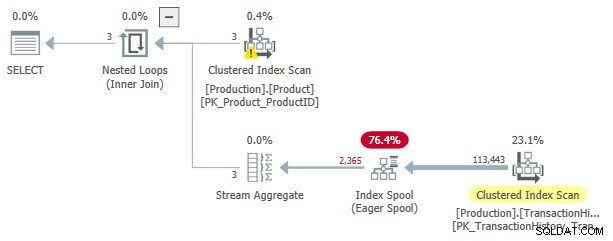
Este plano de execução tem um custo estimado de 3,0881 unidades. Alguns pontos de interesse:
- A junção interna de loops aninhados operador é um aplicar , com
ProductIDeSafetyStockLeveldoProducttabela como referências externas . - Na primeira iteração da aplicação, o Eager Index Spool é totalmente preenchido a partir da Verificação de índice clusterizado do
TransactionHistorytabela. - A tabela de trabalho do spool tem um índice clusterizado codificado em
(ProductID, Quantity). - Linhas que correspondem aos predicados
TH.ProductID = P.ProductIDeTH.Quantity < P.SafetyStockLevelsão respondidas pelo spool usando seu índice. Isso vale para todas as iterações da aplicação, incluindo a primeira. - O
TransactionHistorytabela é verificada apenas uma vez.
Entrada classificada para o spool
É possível impor a entrada classificada para o spool de índice ansioso, mas isso afeta o custo estimado, conforme observado na introdução. Para o exemplo acima, habilitar o sinalizador de rastreamento não documentado produz um plano sem spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260); 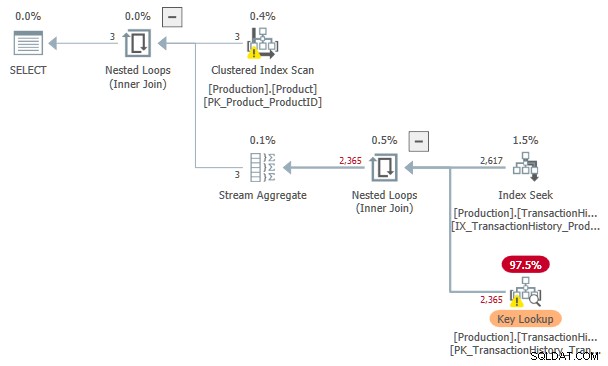
O custo estimado desta Busca de Índice e Pesquisa de chave o plano é 3,11631 unidades. Isso é mais do que o custo do plano com um spool de índice sozinho, mas menor do que o plano com um spool de índice e entrada classificada.
Para ver um plano com entrada classificada para o spool, precisamos aumentar o número esperado de iterações de loop. Isso dá ao carretel a chance de pagar o custo extra da Classificar . Uma maneira de expandir o número de linhas esperado do
Product table é fazer o Name predicado menos restritivo:SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Isso nos dá um plano de execução com entrada classificada para o spool:
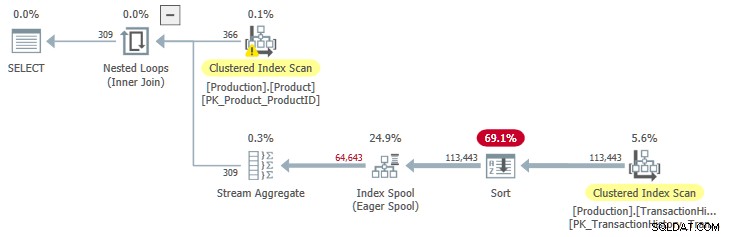
JoinToIndexOnTheFly
Esta regra transforma uma junção interna para uma aplicação , com um carretel de índice ansioso no lado interno. Pelo menos um dos predicados de junção deve ser uma desigualdade para que essa regra seja correspondida.
Esta é uma regra muito mais especializada do que
SelToIndexOnTheFly , mas a ideia é a mesma. Nesse caso, a seleção (predicado) que está sendo transformada em uma busca de spool de índice está associada à junção. A transformação de join para apply permite que o predicado de junção seja movido da própria junção para o lado interno da aplicação. Demonstração
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN); 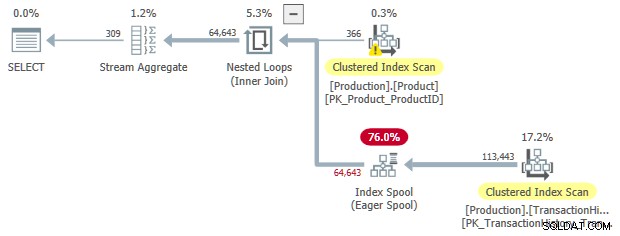
Como antes, podemos solicitar entrada classificada para o spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260); 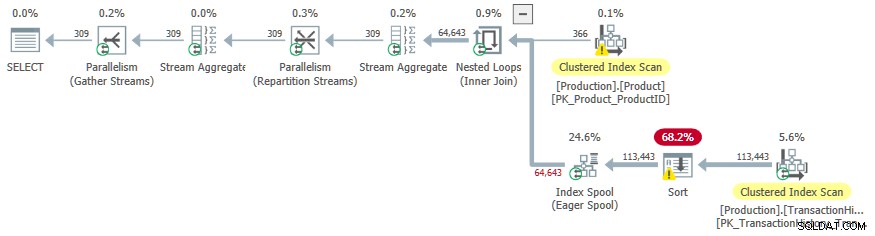
Desta vez, o custo extra de classificação encorajou o otimizador a escolher um plano paralelo.
Um efeito colateral indesejado é o Classificar operador derrama para tempdb . A concessão de memória total disponível para classificação é suficiente, mas é dividida igualmente entre threads paralelos (como de costume). Conforme observado na introdução, o SQL Server não oferece suporte a inserções paralelas em um índice de árvore b, portanto, os operadores abaixo do spool de índice antecipado são executados em um único thread. Este único thread recebe apenas uma fração da concessão de memória, então o Classificar derramamentos para tempdb .
Esse efeito colateral talvez seja um dos motivos pelos quais o sinalizador de rastreamento não é documentado e não é suportado.
SelSTVFToIdxOnFly
Esta regra faz a mesma coisa que
SelToIndexOnTheFly , mas para uma função com valor de tabela de streaming (sTVF) fonte de linha. Esses sTVFs são usados extensivamente internamente para implementar DMVs e DMFs, entre outras coisas. Eles aparecem em planos de execução modernos como Função com valor de tabela operadores (originalmente como varreduras remotas de tabela ). No passado, muitos desses sTVFs não podiam aceitar parâmetros correlacionados de um apply. Eles podem aceitar literais, variáveis e parâmetros de módulo, mas não aplicar referências externas. Ainda há avisos sobre isso na documentação, mas eles estão um pouco desatualizados agora.
De qualquer forma, o ponto é que às vezes não é possível para o SQL Server passar um apply referência externa como parâmetro para um sTVF. Nessa situação, pode fazer sentido materializar parte do resultado sTVF em um spool de índice ansioso. A presente regra prevê essa capacidade.
Demonstração
O próximo exemplo de código mostra uma consulta DMV que foi convertida com sucesso de uma junção para um apply . Referências externas são passados como parâmetros para o segundo DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER); 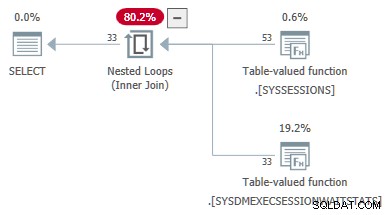
As propriedades do plano das estatísticas de espera TVF mostram os parâmetros de entrada. O segundo valor do parâmetro é fornecido como uma referência externa das sessões DMV:
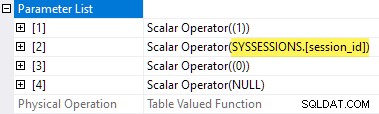
É uma pena que
sys.dm_exec_session_wait_stats é uma visão, não uma função, porque isso nos impede de escrever um apply diretamente. A reescrita abaixo é suficiente para derrotar a conversão interna:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER); Com o
session_id predicados agora não são consumidos como parâmetros, o SelSTVFToIdxOnFly A regra é livre para convertê-los em um spool de índice ansioso: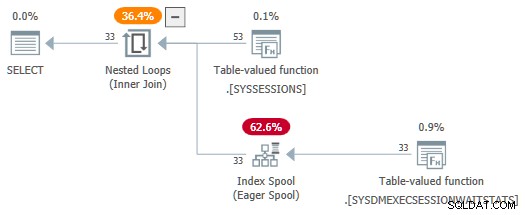
Não quero deixar você com a impressão de que reescritas complicadas são necessárias para obter um spool de índice ansioso em uma fonte DMV – isso apenas facilita a demonstração. Se você encontrar uma consulta com junções de DMV que produz um plano com um spool ansioso, pelo menos você sabe como ele chegou lá.
Você não pode criar índices em DMVs, portanto, pode ser necessário usar uma junção de hash ou mesclagem se o plano de execução não funcionar bem o suficiente.
CTEs recursivos
As duas regras restantes são
SelIterToIdxOnFly e JoinIterToIdxOnFly . Eles são contrapartes diretas de SelToIndexOnTheFly e JoinToIndexOnTheFly para fontes de dados CTE recursivas. Estes são extremamente raros na minha experiência, então não vou fornecer demos para eles. (Só para que o Iter parte do nome da regra faz sentido:vem do fato de que o SQL Server implementa a recursão de cauda como iteração aninhada.) Quando uma CTE recursiva é referenciada várias vezes dentro de uma aplicação, uma regra diferente (
SpoolOnIterator ) pode armazenar em cache o resultado do CTE:WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; O plano de execução apresenta um raro Eager Row Count Spool :
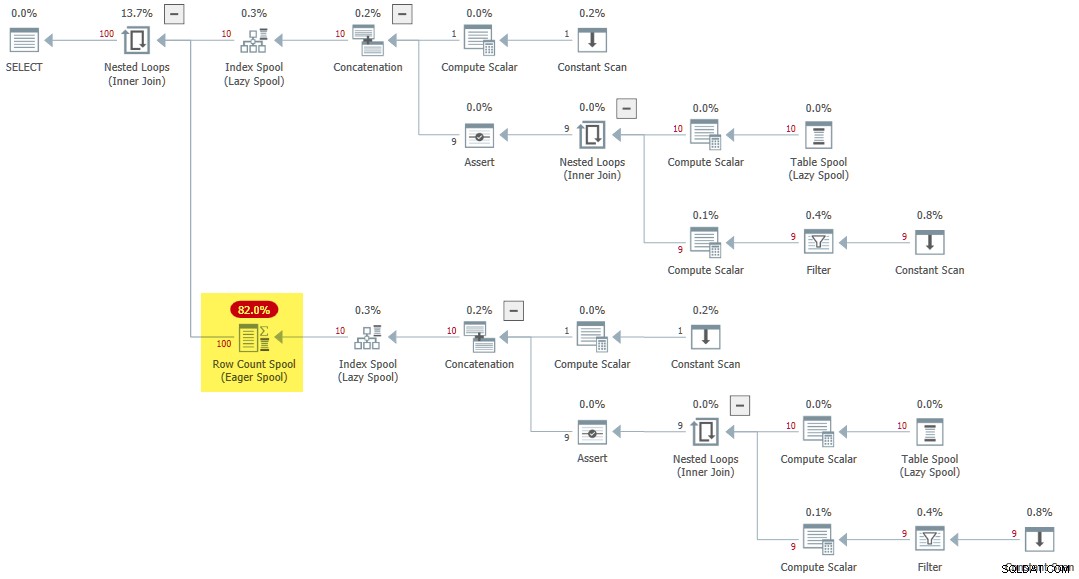
Considerações finais
Os spools de índice ansiosos geralmente são um sinal de que um índice permanente útil está faltando no esquema do banco de dados. Isso nem sempre é o caso, como mostram os exemplos de função com valor de tabela de streaming.



