Usar um ambiente multi-cloud ou multi-datacenter é útil para topologias geo-distribuídas ou mesmo para um plano de recuperação de desastres, e na verdade, está se tornando mais popular hoje em dia, por isso o conceito de split-brain também está se tornando mais importante à medida que o risco de aumentar nesse tipo de cenário. Você deve evitar um cérebro dividido para evitar perda potencial de dados ou inconsistência de dados, o que pode ser um grande problema para os negócios.
Neste blog, veremos o que é um cérebro dividido e como o ClusterControl pode ajudá-lo a evitar esse problema importante.
O que é Split-Brain?
No mundo PostgreSQL, o split-brain ocorre quando mais de um nó primário está disponível ao mesmo tempo (sem nenhuma ferramenta de terceiros para ter um ambiente multimestre) que permite que o aplicativo escreva em ambos os nós. Nesse caso, você terá informações diferentes em cada nó, o que gera inconsistência de dados no cluster. Corrigir esse problema pode ser difícil, pois você deve mesclar dados, algo que às vezes não é possível.
PostgreSQL Split-Brain em uma topologia de várias nuvens
Vamos supor que você tenha a seguinte topologia multinuvem para PostgreSQL (que é uma topologia bastante comum hoje em dia):
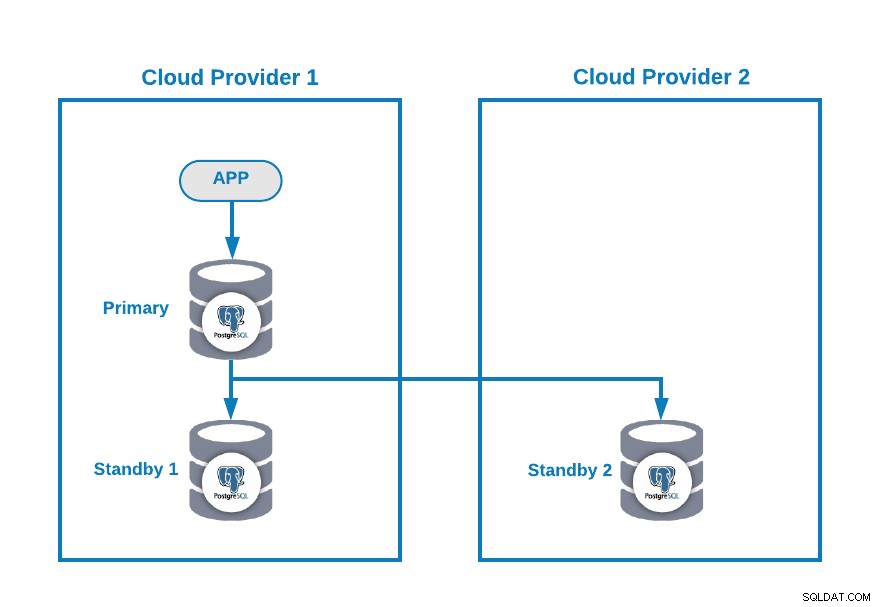
Claro, você pode melhorar este ambiente, por exemplo, adicionando um Application Server no Cloud Provider 2, mas neste caso vamos usar esta configuração básica.
Se seu nó primário estiver inativo, um dos nós em espera deverá ser promovido como novo primário e você deverá alterar o endereço IP em seu aplicativo para usar esse novo nó primário.
Existem várias maneiras de fazer isso de forma automática. Por exemplo, você pode usar um endereço IP virtual atribuído ao seu nó primário e monitorá-lo. Se falhar, promova um dos nós standby e migre o endereço IP virtual para este novo nó primário, assim você não precisa alterar nada em sua aplicação, e isso pode ser feito usando seu próprio script ou ferramenta.
No momento, você não tem nenhum problema, mas… se seu antigo nó primário voltar, você deve certificar-se de que não terá dois nós primários no mesmo cluster ao mesmo tempo .
Os métodos mais comuns para evitar essa situação são:
- STONITH:Atire o outro nó na cabeça.
- SMITH:Dê um tiro na minha cabeça.
O PostgreSQL não oferece nenhuma maneira de automatizar esse processo. Você deve fazê-lo por conta própria.
Como evitar o Split-Brain no PostgreSQL com ClusterControl
Agora, vamos ver como o ClusterControl pode ajudá-lo nessa tarefa.
Primeiro, você pode usá-lo para implantar ou importar seu ambiente PostgreSQL Multi-Cloud de maneira fácil, como você pode ver nesta postagem do blog.
Então, você pode melhorar sua topologia adicionando um Load Balancer (HAProxy), que também pode ser feito usando o ClusterControl seguindo este blog. Então, você terá algo assim:
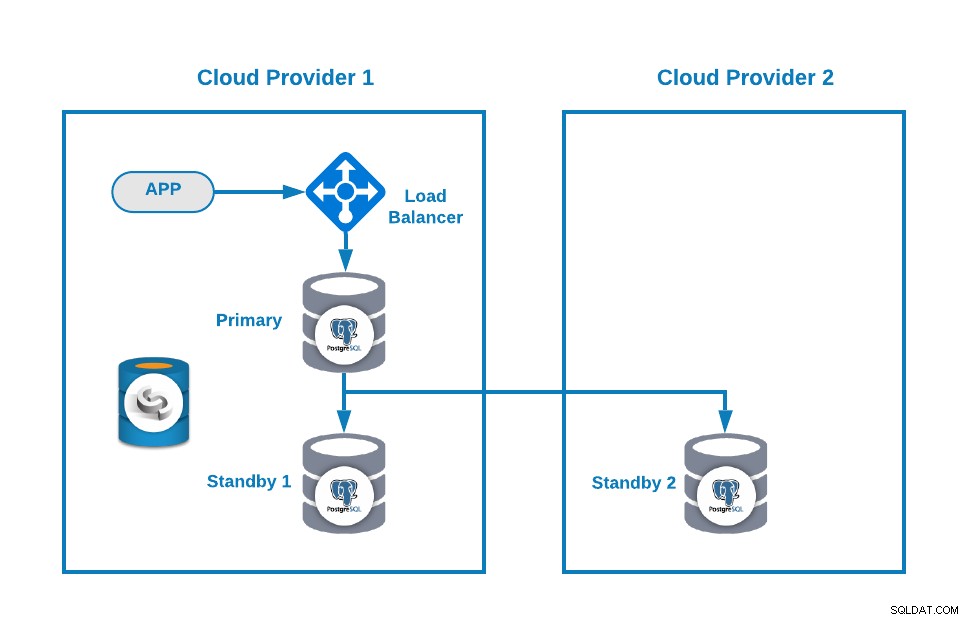
O ClusterControl possui um recurso de failover automático que detecta falhas do mestre e promove um modo de espera nó com os dados mais atuais como um novo primário. Ele também faz failover do restante dos nós em espera para replicar a partir do novo nó primário.
O HAProxy é configurado pelo ClusterControl com duas portas diferentes por padrão, uma de leitura/gravação e outra somente leitura. Na porta de leitura e gravação, você tem seu nó primário como online e o restante de seus nós como offline, e na porta somente leitura, você tem os nós primário e de espera online. Dessa forma, você pode equilibrar o tráfego de leitura entre seus nós, mas garante que no momento da gravação, a porta de leitura e gravação será usada, gravando no nó primário que é o servidor que está online.
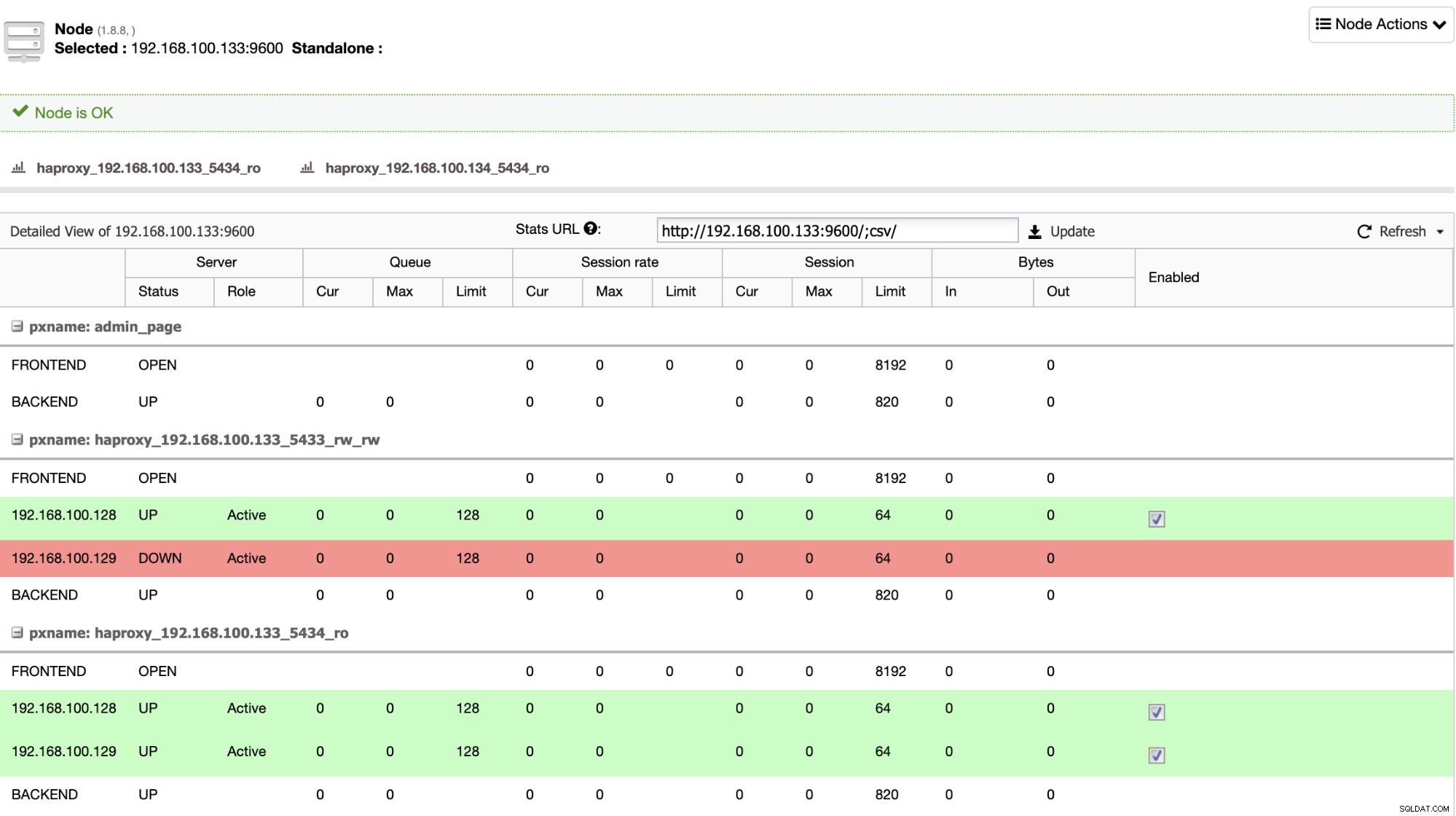
Quando o HAProxy detecta que um de seus nós, primário ou em espera, está não acessível, ele automaticamente o marca como offline e não o leva em consideração para enviar tráfego para ele. Essa verificação é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Se o seu antigo nó primário voltar, o ClusterControl também evitará iniciá-lo, para evitar um potencial split-brain caso você tenha uma conexão direta que não esteja usando o Load Balancer, mas você pode adicioná-lo para o cluster como um nó em espera de maneira automática ou manual usando a UI ou CLI do ClusterControl, então você pode promovê-lo para ter a mesma topologia que você tinha em execução antes do problema.
Conclusão
Com a opção “Autorecovery” ATIVADA, o ClusterControl realizará esse failover automático, além de notificá-lo sobre o problema. Desta forma, seus sistemas podem se recuperar em segundos sem sua intervenção e você evitará uma divisão de cérebros em um ambiente PostgreSQL Multi-Cloud.
Você também pode melhorar seu ambiente de alta disponibilidade adicionando mais nós do ClusterControl usando o recurso CMON HA descrito neste blog.