Failover é a capacidade de um sistema continuar funcionando mesmo que ocorra alguma falha. Sugere que as funções do sistema são assumidas por componentes secundários se os componentes primários falharem ou se for necessário. Portanto, se você traduzi-lo para um ambiente multinuvem do PostgreSQL, significa que quando seu nó primário falhar (ou outro motivo, como mencionaremos na próxima seção) em seu provedor de nuvem primário, você deverá ser capaz de promover o nó em espera no secundário para manter os sistemas funcionando.
Em geral, todos os provedores de nuvem oferecem uma opção de failover no mesmo provedor de nuvem, mas é possível que você precise fazer o failover para outro provedor de nuvem diferente. Claro, você pode fazer isso manualmente, mas você também pode usar alguns dos recursos do ClusterControl como auto-failover ou promover a ação do escravo para fazer isso de uma maneira amigável e fácil.
Neste blog, você verá por que precisa de failover, como fazer isso manualmente e como usar o ClusterControl para essa tarefa. Vamos supor que você tenha uma instalação do ClusterControl em execução e já tenha seu cluster de banco de dados criado em dois provedores de nuvem diferentes.
Para que serve o Failover?
Existem vários usos possíveis de failover.
Falha do mestre
Se o seu nó principal estiver inativo ou mesmo se o seu provedor de nuvem principal tiver alguns problemas, você deve fazer o failover para garantir a disponibilidade do seu sistema. Nesse caso, ter uma maneira automática de fazer isso pode ser necessário para diminuir o tempo de inatividade.
Migração
Se você deseja migrar seus sistemas de um provedor de nuvem para outro minimizando o tempo de inatividade, você pode usar o failover. Você pode criar uma réplica no Provedor de Nuvem secundário e, uma vez sincronizado, você deve parar seu sistema, promover sua réplica e failover, antes de apontar seu sistema para o novo nó primário no Provedor de Nuvem secundário.
Manutenção
Se você precisar realizar qualquer tarefa de manutenção em seu nó primário do PostgreSQL, você pode promover sua réplica, executar a tarefa e reconstruir seu antigo primário como um nó em espera.
Depois disso, você pode promover o antigo primário e repetir o processo de reconstrução no nó em espera, retornando ao estado inicial.
Desta forma, você pode trabalhar em seu servidor, sem correr o risco de ficar offline ou perder informações durante a execução de qualquer tarefa de manutenção.
Atualizações
É possível atualizar sua versão do PostgreSQL (desde o PostgreSQL 10) ou até mesmo atualizar seu Sistema Operacional usando replicação lógica com zero downtime, como pode ser feito com outras engines.
As etapas seriam as mesmas para migrar para um novo provedor de nuvem, só que sua réplica estaria em uma versão mais recente do PostgreSQL ou do SO e você precisa usar a replicação lógica, pois não pode usar streaming replicação entre diferentes versões.
Failover não é apenas sobre o banco de dados, mas também sobre o aplicativo. Como eles sabem a qual banco de dados se conectar? Você provavelmente não quer ter que modificar seu aplicativo, pois isso apenas prolongará seu tempo de inatividade, portanto, você pode configurar um Load Balancer que, quando seu nó principal estiver inativo, apontará automaticamente para o servidor que foi promovido.
Ter uma única instância do Load Balancer não é a melhor opção, pois pode se tornar um ponto único de falha. Portanto, você também pode implementar o failover para o Load Balancer, usando um serviço como Keepalived. Dessa forma, se você tiver um problema com seu Load Balancer primário, o Keepalived migrará o IP Virtual para seu Load Balancer secundário e tudo continuará funcionando de forma transparente.
Outra opção é o uso de DNS. Ao promover o nó em espera no provedor de nuvem secundário, você modifica diretamente o endereço IP do nome do host que aponta para o nó primário. Dessa forma, você evita ter que modificar seu aplicativo e, embora não possa ser feito automaticamente, é uma alternativa caso não queira implementar um Load Balancer.
Como fazer failover do PostgreSQL manualmente
Antes de executar um failover manual, você deve verificar o status da replicação. Pode ser possível que, quando você precisar fazer o failover, o nó em espera não esteja atualizado, devido a uma falha de rede, carga alta ou outro problema, portanto, você precisa garantir que seu nó em espera tenha todos (ou quase toda a informação. Se você tiver mais de um nó em espera, também deverá verificar qual deles é o nó mais avançado e escolhê-lo para failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Ao escolher o novo nó primário, primeiro você pode executar o comando pg_lsclusters para obter as informações do cluster:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logEntão, você só precisa executar o comando pg_ctlcluster com a ação de promoção:
$ pg_ctlcluster 12 main promoteEm vez do comando anterior, você pode executar o comando pg_ctl desta forma:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedEntão, seu nó em espera será promovido a primário e você poderá validá-lo executando a seguinte consulta em seu novo nó primário:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Se o resultado for “f”, é seu novo nó primário.
Agora, você deve alterar o endereço IP do banco de dados primário em seu aplicativo, Load Balancer, DNS ou a implementação que você está usando que, como mencionamos, alterar isso manualmente aumentará o tempo de inatividade. Você também precisa ter certeza de que sua conectividade entre os possíveis provedores está funcionando corretamente, o aplicativo pode acessar o novo nó primário, o usuário do aplicativo tem privilégios para acessá-lo de um provedor de nuvem diferente e você deve reconstruir o(s) nó(s) de espera em remoto ou mesmo no provedor de nuvem local, para replicar a partir do novo primário, caso contrário, você não terá uma nova opção de failover, se necessário.
Como fazer failover do PostgreSQL usando o ClusterControl
O ClusterControl possui vários recursos relacionados à replicação do PostgreSQL e failover automatizado. Vamos supor que você tenha seu servidor ClusterControl instalado e que esteja gerenciando seu ambiente Multi-Cloud PostgreSQL.
Com o ClusterControl, você pode adicionar quantos nós de espera ou nós do Load Balancer precisar sem nenhuma restrição de IP de rede. Isso significa que não é necessário que o nó standby esteja na mesma rede do nó primário ou mesmo no mesmo provedor de nuvem. Em termos de failover, o ClusterControl permite que você faça isso manualmente ou automaticamente.
Failover manual
Para executar um failover manual, vá para ClusterControl -> Select Cluster -> Nodes e, nas ações do nó de um de seus nós em espera, selecione "Promote Slave".
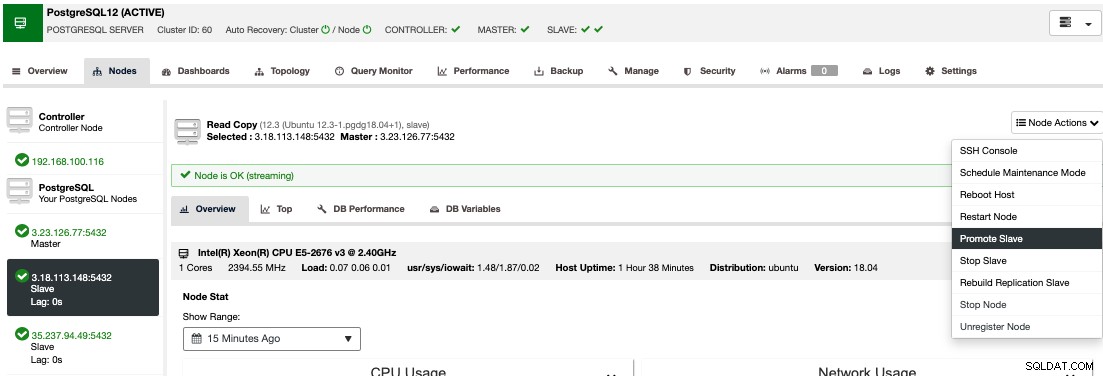
Dessa forma, após alguns segundos, seu nó de espera se torna primário, e o que era seu primário anteriormente, é transformado em standby. Portanto, se sua réplica estiver em outro provedor de nuvem, seu novo nó primário estará lá, funcionando.
Failover automático
No caso de failover automático, o ClusterControl detecta falhas no nó primário e promove um nó em espera com os dados mais atuais como o novo primário. Ele também funciona no restante dos nós de espera para que eles sejam replicados a partir desse novo primário.

Com a opção “Autorecovery” ativada, o ClusterControl executará um failover automático conforme bem como notificá-lo sobre o problema. Desta forma, seus sistemas podem se recuperar em segundos e sem sua intervenção.
ClusterControl oferece a possibilidade de configurar uma lista branca/lista negra para definir como você deseja que seus servidores sejam levados (ou não) em consideração ao decidir sobre um candidato principal.
O ClusterControl também realiza várias verificações sobre o processo de failover, por exemplo, por padrão, se você conseguir recuperar seu antigo nó primário com falha, ele não será reintroduzido automaticamente no cluster, nem como primário nem como standby, você precisará fazê-lo manualmente. Isso evitará a possibilidade de perda ou inconsistência de dados no caso de seu standby (que você promoveu) estar atrasado no momento da falha. Você também pode querer analisar o problema em detalhes, mas ao adicioná-lo ao cluster, possivelmente perderá as informações de diagnóstico.
Balanceadores de carga
Como mencionamos anteriormente, o Load Balancer é uma ferramenta importante a ser considerada para seu failover, especialmente se você quiser usar o failover automático em sua topologia de banco de dados.
Para que o failover seja transparente tanto para o usuário quanto para o aplicativo, você precisa de um componente intermediário, pois não é suficiente promover um novo nó primário. Para isso, você pode usar HAProxy + Keepalived.
Para implementar esta solução com ClusterControl vá para Cluster Actions -> Adicionar Load Balancer -> HAProxy em seu cluster PostgreSQL. Caso você queira implementar o failover para seu Load Balancer, você deve configurar pelo menos duas instâncias HAProxy e, em seguida, pode configurar Keepalived (Ações do Cluster -> Adicionar Load Balancer -> Keepalived). Você pode encontrar mais informações sobre essa implementação nesta postagem do blog.
Após isso, você terá a seguinte topologia:

HAProxy é configurado por padrão com duas portas diferentes, uma de leitura-gravação e um somente leitura.
Na porta de leitura/gravação, você tem seu nó primário como online e o restante dos nós como offline. Na porta somente leitura, você tem os nós primário e de espera online. Dessa forma, você pode equilibrar o tráfego de leitura entre os nós. Ao gravar, será usada a porta de leitura e gravação, que apontará para o nó primário atual.

Quando o HAProxy detecta que um dos nós, primário ou em espera, está não acessível, marca-o automaticamente como offline. O HAProxy não enviará nenhum tráfego para ele. Essa verificação é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Quando o ClusterControl promove um novo nó primário, o HAProxy marca o antigo como offline (para ambas as portas) e coloca o nó promovido online na porta de leitura/gravação. Desta forma, seus sistemas continuam operando normalmente.
Se o HAProxy ativo (que atribuiu um endereço IP virtual ao qual seus sistemas se conectam) falhar, o Keepalived migra esse IP virtual para o HAProxy passivo automaticamente. Isso significa que seus sistemas podem continuar a funcionar normalmente.
Replicação de cluster para cluster na nuvem
Para ter um ambiente Multi-Cloud, você pode usar a ação ClusterControl Add Slave em seu cluster PostgreSQL, mas também o recurso Cluster-to-Cluster Replication. No momento, esse recurso possui uma limitação para o PostgreSQL que permite que você tenha apenas um nó remoto, mas estamos trabalhando para remover essa limitação em breve em uma versão futura.
Para implantá-lo, você pode verificar a seção “Replicação de cluster para cluster na nuvem” nesta postagem do blog.

Quando estiver em vigor, você pode promover o cluster remoto que gerará um cluster PostgreSQL independente com um nó primário em execução no provedor de nuvem secundário.

Então, caso precise, você terá o mesmo cluster rodando em um novo provedor de nuvem em apenas alguns segundos.
Conclusão
Ter um processo de failover automático é obrigatório se você quiser ter o menor tempo de inatividade possível, e também usar tecnologias diferentes como HAProxy e Keepalived melhorará esse failover.
Os recursos do ClusterControl que mencionamos acima permitirão que você faça failover rapidamente entre diferentes provedores de nuvem e gerencie a configuração de maneira fácil e amigável.
A coisa mais importante a ser considerada antes de realizar um processo de failover entre diferentes provedores de nuvem é a conectividade. Você deve certificar-se de que seu aplicativo ou suas conexões de banco de dados funcionarão normalmente usando o provedor de nuvem principal, mas também o secundário em caso de failover e, por motivos de segurança, você deve restringir o tráfego apenas de fontes conhecidas, portanto, apenas entre a nuvem Provedores e não permiti-lo de qualquer fonte externa.