Problemas de atraso de replicação no PostgreSQL não são um problema generalizado para a maioria das configurações. Embora isso possa ocorrer e, quando ocorrer, poderá afetar suas configurações de produção. O PostgreSQL foi projetado para lidar com vários threads, como paralelismo de consulta ou implantação de threads de trabalho para lidar com tarefas específicas com base nos valores atribuídos na configuração. O PostgreSQL foi projetado para lidar com cargas pesadas e estressantes, mas às vezes (devido a uma configuração ruim) seu servidor ainda pode falhar.
Identificar o atraso de replicação no PostgreSQL não é uma tarefa complicada, mas existem algumas abordagens diferentes para analisar o problema. Neste blog, veremos o que observar quando a replicação do PostgreSQL estiver atrasada.
Tipos de replicação no PostgreSQL
Antes de mergulhar no tópico, vamos ver primeiro como a replicação no PostgreSQL evolui, pois existem diversos conjuntos de abordagens e soluções ao lidar com a replicação.
Warm standby para PostgreSQL foi implementado na versão 8.2 (em 2006) e foi baseado no método de envio de logs. Isso significa que os registros WAL são movidos diretamente de um servidor de banco de dados para outro para serem aplicados, ou simplesmente uma abordagem análoga ao PITR, ou muito parecido com o que você está fazendo com o rsync.
Essa abordagem, mesmo antiga, ainda é usada hoje e algumas instituições realmente preferem essa abordagem mais antiga. Essa abordagem implementa um envio de log baseado em arquivo, transferindo os registros WAL um arquivo (segmento WAL) por vez. Embora tenha uma desvantagem; Uma grande falha nos servidores primários, as transações ainda não enviadas serão perdidas. Há uma janela para perda de dados (você pode ajustar isso usando o parâmetro archive_timeout, que pode ser definido para alguns segundos, mas uma configuração tão baixa aumentará substancialmente a largura de banda necessária para o envio de arquivos).
No PostgreSQL versão 9.0, a Replicação de Streaming foi introduzida. Esse recurso nos permitiu ficar mais atualizados quando comparado ao envio de logs baseado em arquivo. Sua abordagem é transferir registros WAL (um arquivo WAL é composto de registros WAL) em tempo real (apenas um envio de log baseado em registro), entre um servidor mestre e um ou vários servidores em espera. Esse protocolo não precisa esperar o preenchimento do arquivo WAL, ao contrário do envio de log baseado em arquivo. Na prática, um processo chamado receptor WAL, executado no servidor em espera, se conectará ao servidor primário usando uma conexão TCP/IP. No servidor primário, existe outro processo chamado WAL remetente. Seu papel é o de enviar os registros WAL para o(s) servidor(es) em espera à medida que eles acontecem.
As configurações de replicação assíncrona na replicação de streaming podem gerar problemas como perda de dados ou atraso de escravo, portanto, a versão 9.1 introduz a replicação síncrona. Na replicação síncrona, cada confirmação de uma transação de gravação aguardará até que seja recebida a confirmação de que a confirmação foi gravada no log de gravação antecipada no disco do servidor primário e de espera. Esse método minimiza a possibilidade de perda de dados, pois para isso precisaremos que tanto o master quanto o standby falhem ao mesmo tempo.
A desvantagem óbvia dessa configuração é que o tempo de resposta para cada transação de gravação aumenta, pois precisamos esperar até que todas as partes tenham respondido. Ao contrário do MySQL, não há suporte, como em um ambiente semi-síncrono do MySQL, ele fará failback para assíncrono se o tempo limite tiver ocorrido. Assim, com o PostgreSQL, o tempo para um commit é (no mínimo) a viagem de ida e volta entre o primário e o standby. As transações somente leitura não serão afetadas por isso.
À medida que evolui, o PostgreSQL está melhorando continuamente e ainda assim sua replicação é diversificada. Por exemplo, você pode usar a replicação assíncrona de streaming físico ou usar a replicação de streaming lógica. Ambos são monitorados de forma diferente, embora usem a mesma abordagem ao enviar dados pela replicação, que ainda é a replicação de streaming. Para mais detalhes consulte o manual para diferentes tipos de soluções no PostgreSQL ao lidar com replicação.
Causas do atraso na replicação do PostgreSQL
Conforme definido em nosso blog anterior, um atraso de replicação é o custo de atraso para transação(ões) ou operação(ões) calculado pela diferença de tempo de execução entre o primário/mestre e o de espera/escravo nó.
Como o PostgreSQL está usando a replicação de streaming, ele foi projetado para ser rápido, pois as alterações são registradas como um conjunto de sequências de registros de log (byte a byte) conforme interceptado pelo receptor WAL e, em seguida, grava esses registros de log para o arquivo WAL. Em seguida, o processo de inicialização do PostgreSQL reproduz os dados desse segmento WAL e a replicação de streaming começa. No PostgreSQL, um atraso de replicação pode ocorrer por estes fatores:
- Problemas de rede
- Não é possível encontrar o segmento WAL do primário. Normalmente, isso se deve ao comportamento de ponto de verificação em que os segmentos WAL são girados ou reciclados
- Nós ocupados (principais e em espera). Pode ser causado por processos externos ou algumas consultas incorretas que consomem muitos recursos
- Hardware ruim ou problemas de hardware causando atraso
- Configuração ruim no PostgreSQL, como um pequeno número de max_wal_senders sendo definido durante o processamento de toneladas de solicitações de transação (ou grande volume de alterações).
O que procurar com o atraso de replicação do PostgreSQL
A replicação do PostgreSQL ainda é diversificada, mas o monitoramento da integridade da replicação é sutil, mas não complicado. Nesta abordagem que mostraremos são baseados em uma configuração de espera primária com replicação de streaming assíncrona. A replicação lógica não pode beneficiar a maioria dos casos que estamos discutindo aqui, mas a visão pg_stat_subscription pode ajudá-lo a coletar informações. No entanto, não vamos nos concentrar nisso neste blog.
Usando a visualização pg_stat_replication
A abordagem mais comum é executar uma consulta referenciando essa visualização no nó primário. Lembre-se, você só pode coletar informações do nó primário usando esta visualização. Esta visualização contém a seguinte definição de tabela baseada no PostgreSQL 11, conforme mostrado abaixo:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Onde os campos são definidos como (inclui PG <10 versão),
- pid :ID do processo walsender
- usesysid :OID do usuário que é usado para replicação de streaming.
- nome de usuário :Nome do usuário que é usado para replicação de streaming
- nome_do_aplicativo :Nome do aplicativo conectado ao mestre
- client_addr :Endereço de replicação em espera/streaming
- client_hostname :nome do host de espera.
- client_port :número da porta TCP em que se comunica em espera com o remetente WAL
- backend_start :hora de início quando o SR se conectou ao mestre.
- backend_xmin :horizonte xmin do standby informado por hot_standby_feedback.
- estado :estado atual do remetente WAL, ou seja, streaming
- enviado_lsn /local_enviado :último local de transação enviado para espera.
- write_lsn /write_location :Última transação gravada no disco em espera
- flush_lsn /flush_location :última transação liberada no disco em espera.
- replay_lsn /replay_location :última transação liberada no disco em espera.
- write_lag :tempo decorrido durante WALs confirmados do primário para o standby (mas ainda não confirmados no standby)
- flush_lag :tempo decorrido durante os WALs confirmados do primário para o standby (os WALs já foram liberados, mas ainda não aplicados)
- replay_lag :tempo decorrido durante WALs confirmados do primário para o standby (totalmente confirmado no nó standby)
- sync_priority :Prioridade do servidor em espera sendo escolhido como espera síncrona
- sync_state :estado de espera de sincronização (é assíncrono ou síncrono).
Uma consulta de amostra teria a seguinte aparência no PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncIsso basicamente informa quais blocos de localização nos segmentos WAL foram gravados, liberados ou aplicados. Ele fornece uma visão granular do status de replicação.
Consultas a serem usadas no nó de espera
No nó de espera, há funções com suporte para as quais você pode reduzir isso em uma consulta e fornecer a visão geral da integridade da replicação em espera. Para fazer isso, você pode executar a seguinte consulta abaixo (a consulta é baseada na versão PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Nas versões mais antigas, você pode usar a seguinte consulta:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06O que a consulta diz? As funções são definidas de acordo aqui,
- pg_is_in_recovery ():(boolean) True se a recuperação ainda estiver em andamento.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) O local do log de gravação antecipada recebido e sincronizado com o disco pela replicação de streaming.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) O último local de registro de gravação antecipada reproduzido durante a recuperação. Se a recuperação ainda estiver em andamento, isso aumentará monotonicamente.
- pg_last_xact_replay_timestamp (): (timestamp com fuso horário) Obtenha o timestamp da última transação repetida durante a recuperação.
Usando um pouco de matemática básica, você pode combinar essas funções. As funções mais comuns usadas pelos DBAs são,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
ou nas versões PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Embora essa consulta tenha sido praticada e usada por DBAs. Ainda assim, ele não fornece uma visão precisa do atraso. Por quê? Vamos discutir isso na próxima seção.
Identificando o atraso causado pela ausência do segmento WAL
Os nós de espera do PostgreSQL, que estão no modo de recuperação, não informam a você o estado exato do que está acontecendo em sua replicação. A menos que você veja o log do PG, você pode coletar informações do que está acontecendo. Não há nenhuma consulta que você possa executar para determinar isso. Na maioria dos casos, organizações e até pequenas instituições criam softwares de terceiros para permitir que sejam alertados quando um alarme é acionado.
Um deles é o ClusterControl, que oferece observabilidade, envia alertas quando são acionados alarmes ou recupera seu nó em caso de desastre ou catástrofe. Vamos pegar este cenário, meu cluster de replicação de streaming assíncrono de espera primária falhou. Como você saberia se algo está errado? Vamos combinar o seguinte:
Etapa 1:determinar se há um atraso
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Etapa 2:determine os segmentos WAL recebidos do primário e compare com o nó de espera
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Para versões mais antigas do PG <10, use pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Isso parece ruim.
Etapa 3:determine quão ruim pode ser
Agora, vamos misturar a fórmula do passo #1 e do passo #2 e obter o diff. Como fazer isso, o PostgreSQL tem uma função chamada pg_wal_lsn_diff que é definida como,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (local pg_lsn, local pg_lsn): (numérico) Calcular a diferença entre dois locais de registro de gravação antecipada
Agora, vamos usá-lo para determinar o atraso. Você pode executá-lo em qualquer nó PG, pois forneceremos apenas os valores estáticos:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Vamos estimar quanto é 1800913104, que parece ser cerca de 1,6GiB pode estar ausente no nó de espera,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Por último, você pode prosseguir ou mesmo antes da consulta olhar os logs como usar tail -5f para seguir e verificar o que está acontecendo. Faça isso para os nós primários/em espera. Neste exemplo, veremos que há um problema,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Ao encontrar esse problema, é melhor reconstruir seus nós de espera. No ClusterControl, é tão fácil quanto um clique. Basta ir para a seção Nós/Topologia e reconstruir o nó como abaixo:
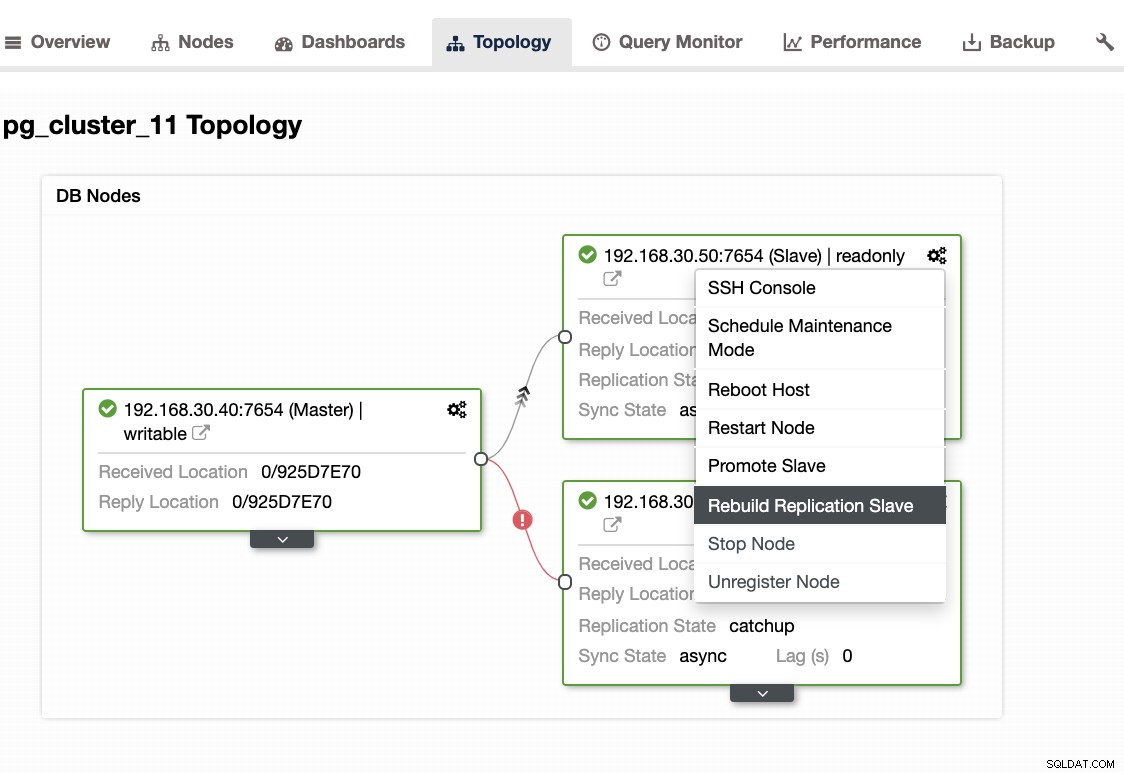
Outras coisas para verificar
Você pode usar a mesma abordagem em nosso blog anterior (no MySQL), usando ferramentas do sistema como combinação ps, top, iostat, netstat. Por exemplo, você também pode obter o segmento WAL recuperado atual do nó de espera,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Como o ClusterControl pode ajudar?
ClusterControl oferece uma maneira eficiente de monitorar seus nós de banco de dados dos nós primários aos escravos. Ao acessar a guia Visão geral, você já tem a visualização da integridade da sua replicação:
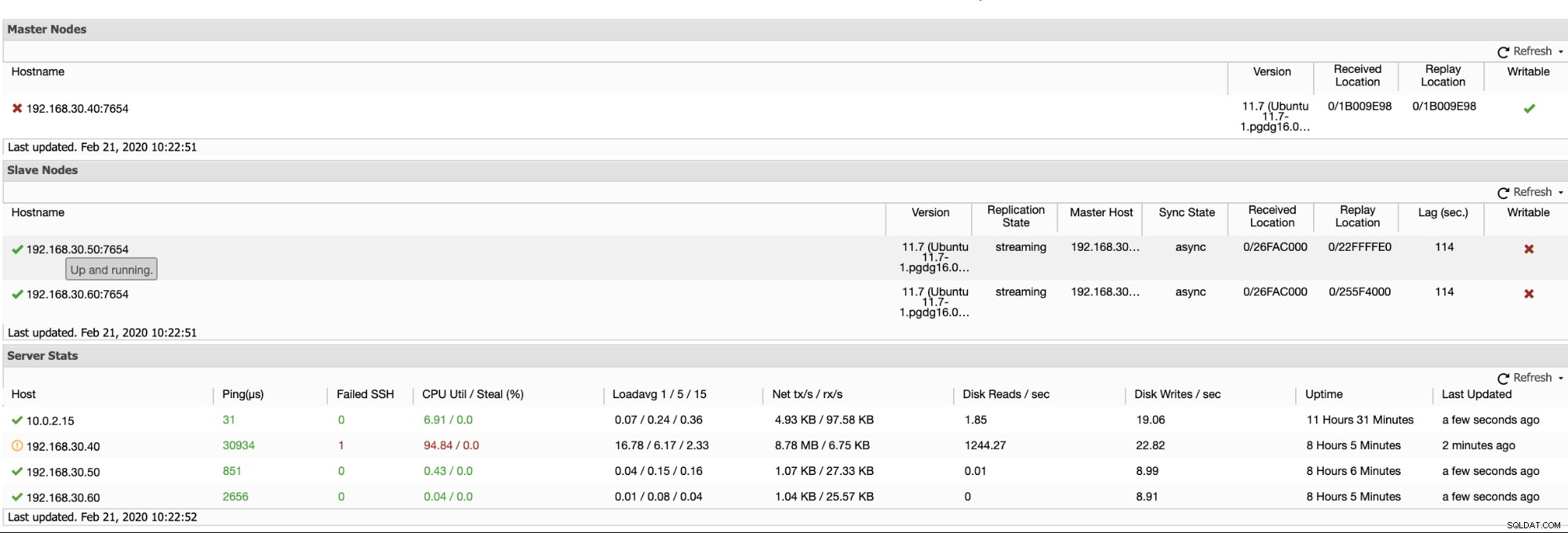
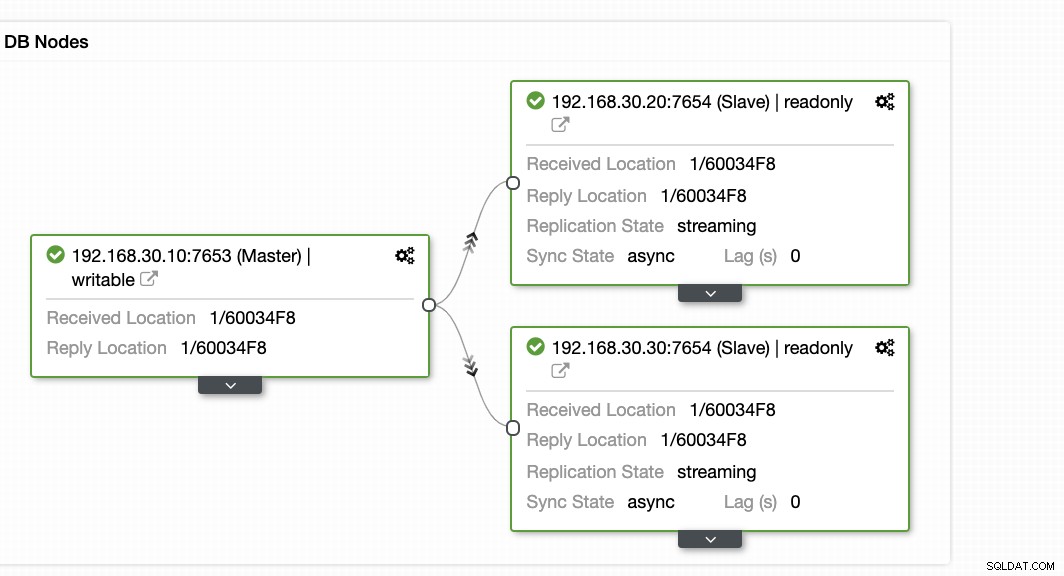
Basicamente, as duas capturas de tela acima exibem como está a integridade da replicação e qual é a atual segmentos WAL. Isso não é nada. ClusterControl também mostra a atividade atual do que está acontecendo com seu cluster.
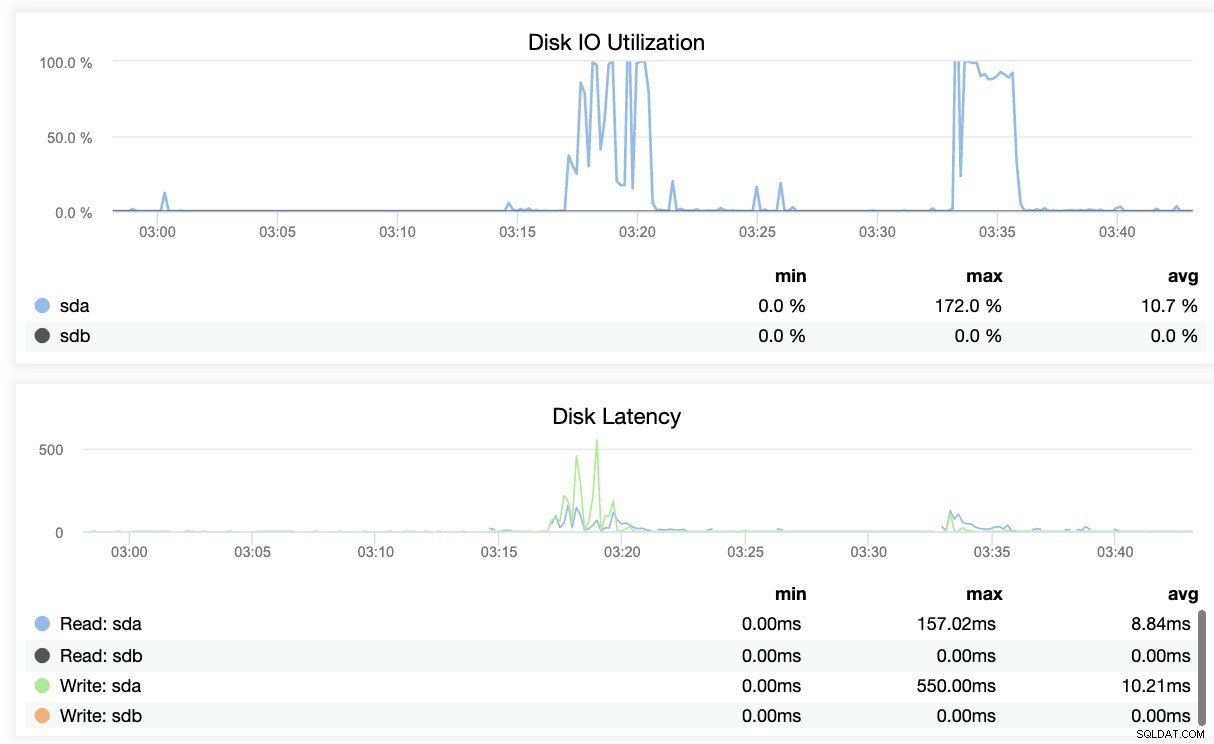
Conclusão
Monitorar a integridade da replicação no PostgreSQL pode resultar em uma abordagem diferente, desde que você consiga atender às suas necessidades. Usar ferramentas de terceiros com observabilidade que podem notificá-lo em caso de catástrofe é o caminho perfeito, seja de código aberto ou corporativo. O mais importante é que você tenha seu plano de recuperação de desastres e continuidade de negócios planejados antes de tais problemas.