Quando você precisa implementar um sistema de análise para uma empresa, muitas vezes surge a questão de onde os dados devem ser armazenados. Nem sempre há uma opção perfeita para todos os requisitos e isso depende do orçamento, da quantidade de dados e das necessidades da empresa.
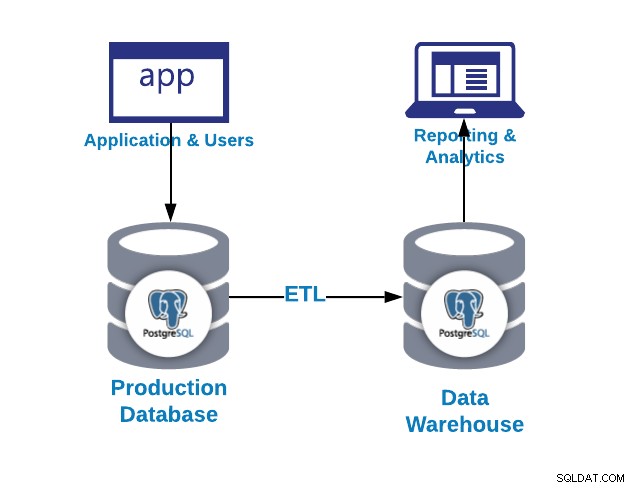
O PostgreSQL, como o banco de dados de código aberto mais avançado, é tão flexível que pode servir como um banco de dados relacional simples, um banco de dados de série temporal e até mesmo como uma solução de armazenamento de dados eficiente e de baixo custo. Você também pode integrá-lo a várias ferramentas de análise.
Se você está procurando um data warehouse amplamente compatível, de baixo custo e de alto desempenho, a melhor opção de banco de dados pode ser o PostgreSQL, mas por quê? Neste blog, veremos o que é um data warehouse, por que ele é necessário e por que o PostgreSQL pode ser a melhor opção aqui.
O que é um Data Warehouse
Um Data Warehouse é um sistema padronizado, consistente e integrado que contém dados atuais ou históricos de uma ou mais fontes que são usados para relatórios e análise de dados. É considerado um componente central da inteligência de negócios, que é a estratégia e tecnologia utilizada por uma empresa para um melhor entendimento de seu contexto comercial.
A primeira pergunta que você pode fazer é por que preciso de um data warehouse?
- Integração:integre/centralize dados de vários sistemas/bancos de dados
- Padronizar:padronizar todos os dados no mesmo formato
- Analytics:analise dados em um contexto histórico
Alguns dos benefícios de um data warehouse podem ser...
- Integre dados de várias fontes em um único banco de dados
- Evite bloqueio ou carregamento de produção devido a consultas de longa duração
- Armazenar informações históricas
- Reestruture os dados para atender aos requisitos de análise
Como pudemos ver na imagem anterior, podemos usar o PostgreSQL para propostas OLAP e OLTP. Vamos ver a diferença.
- OLTP:processamento de transações online. Em geral, possui um grande número de transações on-line curtas (INSERT, UPDATE, DELETE) geradas pela atividade do usuário. Esses sistemas enfatizam o processamento de consultas muito rápido e a manutenção da integridade dos dados em ambientes multiacesso. Aqui, a eficácia é medida pelo número de transações por segundo. Os bancos de dados OLTP contêm dados detalhados e atuais.
- OLAP:Processamento analítico online. Em geral, possui um baixo volume de transações complexas geradas por grandes relatórios. O tempo de resposta é uma medida de eficácia. Esses bancos de dados armazenam dados históricos agregados em esquemas multidimensionais. Os bancos de dados OLAP são usados para analisar dados multidimensionais de várias fontes e perspectivas.
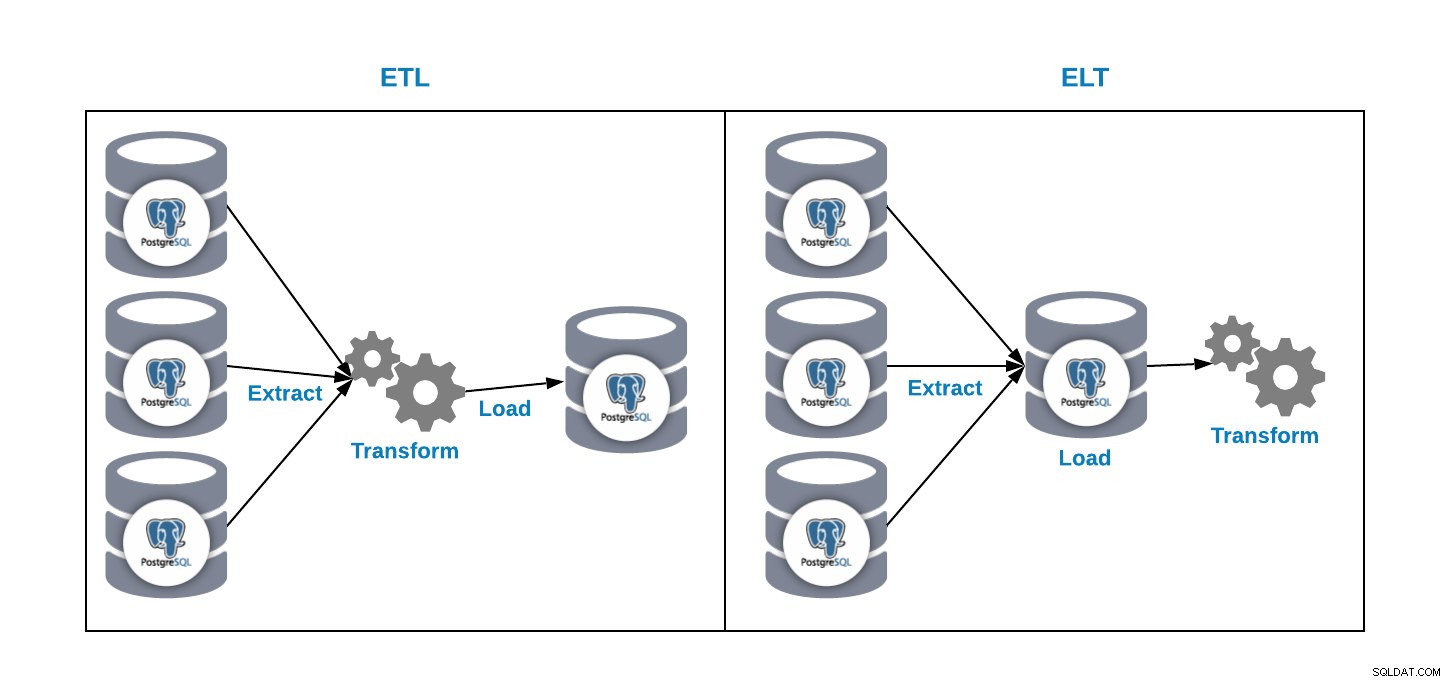
Temos duas maneiras de carregar dados em nosso banco de dados de análise:
- ETL:Extraia, transforme e carregue. Esta é a maneira de gerar nosso data warehouse. Primeiro, extraia os dados do banco de dados de produção, transforme os dados de acordo com nossos requisitos e, em seguida, carregue os dados em nosso data warehouse.
- ELT:Extraia, carregue e transforme. Primeiro, extraia os dados do banco de dados de produção, carregue-os no banco de dados e depois transforme os dados. Essa forma é chamada de Data Lake e é um novo conceito para gerenciar nosso big data.
E agora, a segunda pergunta, por que devo usar o PostgreSQL para meu data warehouse?
Benefícios do PostgreSQL como um Data Warehouse
Vejamos alguns dos benefícios de usar o PostgreSQL como um data warehouse...
- Custo:se você estiver usando um ambiente local, o custo do produto em si será de US$ 0, mesmo se estiver usando algum produto na nuvem, provavelmente o custo de um produto baseado em PostgreSQL será menor que o restante dos produtos.
- Escala:você pode dimensionar as leituras de maneira simples adicionando quantos nós de réplica desejar.
- Desempenho:Com uma configuração correta, o PostgreSQL tem um desempenho muito bom em diferentes cenários.
- Compatibilidade:você pode integrar o PostgreSQL com ferramentas ou aplicativos externos para mineração de dados, OLAP e relatórios.
- Extensibilidade:o PostgreSQL tem tipos de dados e funções definidos pelo usuário.
Existem também alguns recursos do PostgreSQL que podem nos ajudar a gerenciar nossas informações de data warehouse...
- Tabelas temporárias:é uma tabela de curta duração que existe durante uma sessão de banco de dados. O PostgreSQL elimina automaticamente as tabelas temporárias no final de uma sessão ou transação.
- Procedimentos armazenados:você pode usá-lo para criar procedimentos ou funções em vários idiomas (PL/pgSQL, PL/Perl, PL/Python, etc).
- Particionamento:Isso é muito útil para manutenção de banco de dados, consultas usando chave de partição e desempenho de INSERT.
- Visualização materializada:os resultados da consulta são mostrados como uma tabela.
- Tablespaces:você pode alterar o local dos dados para um disco diferente. Dessa forma, você terá acesso ao disco paralelizado.
- Compatível com PITR:você pode criar backups compatíveis com recuperação pontual, portanto, em caso de falha, você pode restaurar o estado do banco de dados em um período de tempo específico.
- Enorme comunidade:E por último, mas não menos importante, o PostgreSQL tem uma enorme comunidade onde você pode encontrar suporte para diversos problemas.
Configurando o PostgreSQL para uso do data warehouse
Não há melhor configuração para usar em todos os casos e em todas as tecnologias de banco de dados. Depende de muitos fatores, como hardware, uso e requisitos do sistema. Abaixo estão algumas dicas para configurar seu banco de dados PostgreSQL para funcionar como um data warehouse da forma correta.
Baseado na memória
- max_connections:como um banco de dados de data warehouse, você não precisa de uma grande quantidade de conexões porque isso será usado para relatórios e trabalhos de análise, portanto, você pode limitar o número máximo de conexões usando esse parâmetro.
- shared_buffers:define a quantidade de memória que o servidor de banco de dados usa para buffers de memória compartilhada. Um valor razoável pode ser de 15% a 25% da memória RAM.
- effective_cache_size:esse valor é usado pelo planejador de consultas para levar em conta os planos que podem ou não caber na memória. Isso é levado em consideração nas estimativas de custo do uso de um índice; um valor alto torna mais provável que as varreduras de índice sejam usadas e um valor baixo torna mais provável que as varreduras sequenciais sejam usadas. Um valor razoável seria cerca de 75% da memória RAM.
- work mem:Especifica a quantidade de memória que será usada pelas operações internas das tabelas ORDER BY, DISTINCT, JOIN e hash antes de gravar nos arquivos temporários no disco. Ao configurar este valor devemos levar em conta que várias sessões estão executando estas operações ao mesmo tempo e cada operação poderá usar a quantidade de memória especificada por este valor antes de começar a escrever dados em arquivos temporários. Um valor razoável pode ser cerca de 2% da memória RAM.
- maintenance_work_mem:especifica a quantidade máxima de memória que as operações de manutenção usarão, como VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Um valor razoável pode ser cerca de 15% da memória RAM.
Com base em CPU
- Max_worker_processes:define o número máximo de processos em segundo plano que o sistema pode suportar. Um valor razoável pode ser o número de CPUs.
- Max_parallel_workers_per_gather:define o número máximo de workers que podem ser iniciados por um único nó Gather ou Gather Merge. Um valor razoável pode ser 50% do número de CPU.
- Max_parallel_workers:define o número máximo de trabalhadores que o sistema pode suportar para consultas paralelas. Um valor razoável pode ser o número de CPUs.
Como os dados carregados em nosso data warehouse não devem ser alterados, também podemos desativar o Autovacuum para evitar uma carga extra em seu banco de dados PostgreSQL. Os processos Aspirar e Analisar podem fazer parte do processo de carregamento em lote.
Conclusão
Se você está procurando por um data warehouse amplamente compatível, de baixo custo e alto desempenho, você deve definitivamente considerar o PostgreSQL como uma opção para seu banco de dados de data warehouse. O PostgreSQL tem muitos benefícios e recursos úteis para gerenciar nosso data warehouse, como particionamento, procedimentos armazenados e muito mais.