SQLAlchemy ajuda você a trabalhar com bancos de dados em Python. Neste post, contamos tudo o que você precisa saber para começar a usar este módulo.
No artigo anterior, falamos sobre como usar o Python no processo de ETL. Nós nos concentramos em fazer o trabalho executando procedimentos armazenados e consultas SQL. Neste artigo e no próximo, usaremos uma abordagem diferente. Em vez de escrever código SQL, usaremos o kit de ferramentas SQLAlchemy. Você também pode usar este artigo separadamente, como uma introdução rápida sobre como instalar e usar o SQLAlchemy.
Preparar? Vamos começar.
O que é SQLAlchemy?
Python é bem conhecido por seu número e variedade de módulos. Esses módulos reduzem significativamente nosso tempo de codificação porque implementam rotinas necessárias para realizar uma tarefa específica. Vários módulos que trabalham com dados estão disponíveis, incluindo SQLAlchemy.
Para descrever SQLAlchemy, usarei uma citação de SQLAlchemy.org:
SQLAlchemy é o kit de ferramentas Python SQL e o Mapeador Relacional de Objetos que oferece aos desenvolvedores de aplicativos todo o poder e flexibilidade do SQL.
Ele fornece um conjunto completo de persistência de nível empresarial bem conhecido padrões, projetados para acesso eficiente e de alto desempenho ao banco de dados, adaptado em uma linguagem de domínio simples e Python.
A parte mais importante aqui é a parte sobre o ORM (mapeador relacional de objetos), que nos ajuda a tratar objetos de banco de dados como objetos Python em vez de listas.
Antes de prosseguirmos com o SQLAlchemy, vamos fazer uma pausa e falar sobre ORMs.
Os prós e contras do uso de ORMs
Comparado ao SQL bruto, os ORMs têm seus prós e contras – e a maioria deles também se aplica ao SQLAlchemy.
As coisas boas:
- Portabilidade de código. O ORM cuida das diferenças sintáticas entre os bancos de dados.
- Apenas um idioma é necessário para lidar com seu banco de dados. Embora, para ser honesto, essa não deva ser a principal motivação para usar um ORM.
- ORMs simplificam seu código , por exemplo. eles cuidam dos relacionamentos e os tratam como objetos, o que é ótimo se você estiver acostumado com POO.
- Você pode manipular seus dados dentro do programa .
Infelizmente, tudo tem um preço. As coisas não tão boas sobre ORMs:
- Em alguns casos, um ORM pode ser lento .
- Escrevendo consultas complexas pode se tornar ainda mais complicado ou resultar em consultas lentas. Mas este não é o caso ao usar SQLAlchemy.
- Se você conhece bem seu DBMS, é uma perda de tempo aprender a escrever as mesmas coisas em um ORM.
Agora que lidamos com esse tópico, vamos voltar ao SQLAlchemy.
Antes de começarmos...
… vamos nos lembrar do objetivo deste artigo. Se você está interessado apenas em instalar o SQLAlchemy e precisa de um tutorial rápido sobre como executar comandos simples, este artigo fará isso. No entanto, os comandos apresentados neste artigo serão usados no próximo artigo para realizar o processo ETL e substituir o SQL (procedimentos armazenados) e o código Python que apresentamos nos artigos anteriores.
Ok, agora vamos começar logo no início:com a instalação do SQLAlchemy.
Instalando SQLAlchemy
1. Verifique se o módulo já está instalado
Para usar um módulo Python, você precisa instalá-lo (ou seja, se não tiver sido instalado anteriormente). Uma maneira de verificar quais módulos foram instalados é usando este comando no Python Shell:
help('modules')
Para verificar se um módulo específico está instalado, tente importá-lo. Use estes comandos:
import sqlalchemy sqlalchemy.__version__
Se SQLAlchemy já estiver instalado, a primeira linha será executada com sucesso. import é um comando padrão do Python usado para importar módulos. Se o módulo não estiver instalado, o Python lançará um erro – na verdade uma lista de erros, em texto vermelho – que você não pode perder :)
O segundo comando retorna a versão atual do SQLAlchemy. O resultado retornado é mostrado abaixo:

Também precisaremos de outro módulo, que é o PyMySQL . Esta é uma biblioteca de cliente MySQL leve puro-Python. Este módulo suporta tudo o que precisamos para trabalhar com um banco de dados MySQL, desde a execução de consultas simples até ações de banco de dados mais complexas. Podemos verificar se ele existe usando help('modules') , conforme descrito anteriormente, ou usando as duas instruções a seguir:
import pymysql pymysql.__version__
Claro, esses são os mesmos comandos que usamos para testar se o SQLAlchemy foi instalado.
E se o SQLAlchemy ou o PyMySQL ainda não estiver instalado?
Importar módulos instalados anteriormente não é difícil. Mas e se os módulos que você precisa ainda não estiverem instalados?
Alguns módulos têm um pacote de instalação, mas principalmente você usará o comando pip para instalá-los. PIP é uma ferramenta Python usada para instalar e desinstalar módulos. A maneira mais fácil de instalar um módulo (no sistema operacional Windows) é:
- Use Prompt de Comando -> Executar -> cmd .
- Posição no diretório Python cd C:\...\Python\Python37\Scripts .
- Execute o comando pip
install(no nosso caso, executaremospip install pyMySQLepip install sqlAlchemy.
O PIP também pode ser usado para desinstalar o módulo existente. Para fazer isso, você deve usar
pip uninstall . 2. Conectando-se ao banco de dados
Embora instalar tudo o que é necessário para usar o SQLAlchemy seja essencial, não é muito interessante. Nem é realmente parte do que nos interessa. Nem mesmo nos conectamos aos bancos de dados que queremos usar. Vamos resolver isso agora:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Usando o script acima, estabeleceremos uma conexão com o banco de dados localizado em nosso servidor local, o subscription_live base de dados.
(Observação: Substitua
Vamos passar pelo script, comando por comando.
import sqlalchemy from sqlalchemy.engine import create_engine
Estas duas linhas importam nosso módulo e o create_engine função.
Em seguida, estabeleceremos uma conexão com o banco de dados localizado em nosso servidor.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
A função create_engine cria o mecanismo e usa .connect() , conecta-se ao banco de dados. O create_engine função usa estes parâmetros:
dialect+driver://username:password@host:port/database
No nosso caso, o dialeto é mysql , o driver é pymysql (instalado anteriormente) e as variáveis restantes são específicas para o servidor e banco(s) de dados aos quais queremos nos conectar.
(Observação: Se você estiver se conectando localmente, use localhost em vez de seu endereço IP "local", 127.0.0.1 e a porta apropriada :3306 .)

O resultado do comando print(engine_live.table_names()) é mostrado na imagem acima. Como esperado, obtivemos a lista de todas as tabelas do nosso banco de dados operacional/ativo.
3. Executando comandos SQL usando SQLAlchemy
Nesta seção, analisaremos os comandos SQL mais importantes, examinaremos a estrutura da tabela e executaremos todos os quatro comandos DML:SELECT, INSERT, UPDATE e DELETE.
Discutiremos as instruções usadas neste script separadamente. Observe que já passamos pela parte de conexão deste script e já listamos os nomes das tabelas. Há pequenas alterações nesta linha:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Acabamos de importar tudo que usaremos do SQLAlchemy.
Tabelas e estrutura
Executaremos o script digitando o seguinte comando no Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
O resultado é o script executado. Agora vamos analisar o resto do script.
SQLAlchemy importa informações relacionadas a tabelas, estrutura e relações. Para trabalhar com essa informação, pode ser útil verificar a lista de tabelas (e suas colunas) no banco de dados:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Isso simplesmente retorna uma lista de todas as tabelas do banco de dados conectado.
Observação: O table_names() O método retorna uma lista de nomes de tabela para o mecanismo fornecido. Você pode imprimir a lista inteira ou iterar por ela usando um loop (como faria com qualquer outra lista).
Em seguida, retornaremos uma lista de todos os atributos da tabela selecionada. A parte relevante do script e o resultado são mostrados abaixo:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
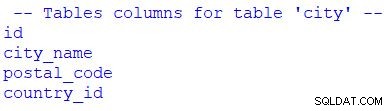
Você pode ver que eu usei for para percorrer o conjunto de resultados. Poderíamos substituir table_city.c com table_city.columns .
Observação: O processo de carregar a descrição do banco de dados e criar metadados no SQLAlchemy é chamado de reflexão.
Observação: MetaData é o objeto que mantém as informações sobre os objetos no banco de dados, portanto, as tabelas no banco de dados também estão vinculadas a esse objeto. Em geral, esse objeto armazena informações sobre a aparência do esquema do banco de dados. Você o usará como um único ponto de contato quando quiser fazer alterações ou obter fatos sobre o esquema de banco de dados.
Observação: Os atributos autoload = True e autoload_with = engine_live deve ser usado para garantir que os atributos da tabela sejam carregados (caso ainda não tenham sido).
SELECIONAR
Acho que não preciso explicar o quão importante é a instrução SELECT :) Então, vamos apenas dizer que você pode usar SQLAlchemy para escrever instruções SELECT. Se você está acostumado com a sintaxe do MySQL, levará algum tempo para se adaptar; ainda assim, tudo é bastante lógico. Para colocar da forma mais simples possível, eu diria que a instrução SELECT é dividida e algumas partes são omitidas, mas tudo ainda está na mesma ordem.
Vamos tentar algumas instruções SELECT agora.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
O primeiro é uma instrução SELECT simples retornando todos os valores da tabela fornecida. A sintaxe desta instrução é muito simples:coloquei o nome da tabela no select() . Observe que eu:
- Preparou a instrução -
stmt = select([table_city]. - Imprimiu a instrução usando
print(stmt), o que nos dá uma boa ideia sobre a instrução que acabou de ser executada. Isso também pode ser usado para depuração. - Imprimiu o resultado com
print(connection_live.execute(stmt).fetchall()). - Percorreu o resultado e imprimiu cada registro.
Observação: Como também carregamos restrições de chave primária e estrangeira no SQLAlchemy, a instrução SELECT usa uma lista de objetos de tabela como argumentos e estabelece relacionamentos automaticamente quando necessário.
O resultado é mostrado na imagem abaixo:

O Python buscará todos os atributos da tabela e os armazenará no objeto. Como mostrado, podemos usar este objeto para realizar operações adicionais. O resultado final de nossa declaração é uma lista de todas as cidades da city tabela.
Agora, estamos prontos para uma consulta mais complexa. Acabei de adicionar uma cláusula ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Observação: O asc() O método executa a classificação ascendente em relação ao objeto pai, usando colunas definidas como parâmetros.
A lista retornada é a mesma, mas agora está classificada pelo valor de id, em ordem crescente. É importante observar que simplesmente adicionamos .order_by( para a consulta SELECT anterior. O .order_by(...) O método nos permite alterar a ordem do conjunto de resultados retornado, da mesma maneira que usaríamos em uma consulta SQL. Portanto, os parâmetros devem seguir a lógica SQL, usando nomes de coluna ou ordem de coluna e ASC ou DESC.
Em seguida, adicionaremos WHERE à nossa instrução SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Observação: O .where() é usado para testar uma condição que usamos como argumento. Também podemos usar o .filter() método, que é melhor para filtrar condições mais complexas.
Mais uma vez, o .where parte é simplesmente concatenada à nossa instrução SELECT. Observe que colocamos a condição dentro dos colchetes. Qualquer condição que esteja entre colchetes é testada da mesma maneira que seria testada na parte WHERE de uma instrução SELECT. A condição de igualdade é testada usando ==em vez de =.
A última coisa que vamos tentar com SELECT é juntar duas tabelas. Vamos dar uma olhada no código e seu resultado primeiro.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Há duas partes importantes na declaração acima:
select([table_city.columns.city_name, table_country.columns.country_name])define quais colunas serão retornadas em nosso resultado..select_from(table_city.join(table_country))define a condição/tabela de junção. Observe que não precisamos anotar a condição de junção completa, incluindo as chaves. Isso ocorre porque o SQLAlchemy “sabe” como essas duas tabelas são unidas, pois as regras de chaves primárias e chaves estrangeiras são importadas em segundo plano.
INSERIR / ATUALIZAR / EXCLUIR
Estes são os três comandos DML restantes que abordaremos neste artigo. Embora sua estrutura possa ficar muito complexa, esses comandos geralmente são muito mais simples. O código utilizado é apresentado a seguir.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
O mesmo padrão é usado para todas as três instruções:preparar a instrução, imprimi-la e executá-la e imprimir o resultado após cada instrução para que possamos ver o que realmente aconteceu no banco de dados. Observe mais uma vez que partes da instrução foram tratadas como objetos (.values(), .where()).

Usaremos esse conhecimento no próximo artigo para criar um script ETL inteiro usando SQLAlchemy.
Próximo:SQLAlchemy no processo ETL
Hoje analisamos como configurar o SQLAlchemy e como executar comandos DML simples. No próximo artigo, usaremos esse conhecimento para escrever o processo ETL completo usando SQLAlchemy.
Você pode baixar o script completo, usado neste artigo aqui.