Os dados são provavelmente um dos ativos mais valiosos de uma empresa. Por isso, devemos sempre ter um Plano de Recuperação de Desastres (DRP) para evitar a perda de dados em caso de acidente ou falha de hardware.
Um backup é a forma mais simples de DR, mas nem sempre é suficiente para garantir um Objetivo de Ponto de Recuperação (RPO) aceitável. É recomendável que você tenha pelo menos três backups armazenados em locais físicos diferentes.
A prática recomendada diz que os arquivos de backup devem ter um armazenado localmente no servidor de banco de dados (para uma recuperação mais rápida), outro em um servidor de backup centralizado e o último na nuvem.
Para este blog, veremos quais opções a Amazon AWS oferece para o armazenamento de backups do PostgreSQL na nuvem e mostraremos alguns exemplos de como fazer isso.
Sobre a Amazon AWS
A Amazon AWS é um dos provedores de nuvem mais avançados do mundo em termos de recursos e serviços, com milhões de clientes. Se quisermos executar nossos bancos de dados PostgreSQL no Amazon AWS, temos algumas opções...
-
Amazon RDS:Permite criar, gerenciar e dimensionar um banco de dados PostgreSQL (ou diferentes tecnologias de banco de dados) na nuvem de maneira fácil e rápida.
-
Amazon Aurora:é um banco de dados compatível com PostgreSQL criado para a nuvem. De acordo com o site da AWS, é três vezes mais rápido que os bancos de dados PostgreSQL padrão.
-
Amazon EC2:é um serviço da Web que fornece capacidade de computação redimensionável na nuvem. Ele fornece controle completo de seus recursos de computação e permite que você configure tudo sobre suas instâncias, desde seu sistema operacional até seus aplicativos.
Mas, na verdade, não precisamos ter nossos bancos de dados rodando na Amazon para armazenar nossos backups aqui.
Armazenando backups na Amazon AWS
Existem diferentes opções para armazenar nosso backup PostgreSQL na AWS. Se estivermos executando nosso banco de dados PostgreSQL na AWS, temos mais opções e (como estamos na mesma rede) também pode ser mais rápido. Vamos ver como a AWS pode nos ajudar a armazenar nossos backups.
AWS CLI
Primeiro, vamos preparar nosso ambiente para testar as diferentes opções da AWS. Para nossos exemplos, usaremos um servidor PostgreSQL 11 On-prem, rodando no CentOS 7. Aqui, precisamos instalar a AWS CLI seguindo as instruções deste site.
Quando temos nossa AWS CLI instalada, podemos testá-la na linha de comando:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Agora, a próxima etapa é configurar nosso novo cliente executando o comando aws com a opção configure.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Para obter essas informações, você pode acessar a seção IAM AWS e verificar o usuário atual ou, se preferir, pode criar um novo para essa tarefa.
Depois disso, estamos prontos para usar a AWS CLI para acessar nossos serviços Amazon AWS.
Amazon S3
Esta é provavelmente a opção mais usada para armazenar backups na nuvem. O Amazon S3 pode armazenar e recuperar qualquer quantidade de dados de qualquer lugar na Internet. É um serviço de armazenamento simples que oferece uma infraestrutura de armazenamento de dados extremamente durável, altamente disponível e infinitamente escalável a custos baixos.
O Amazon S3 fornece uma interface de serviço web simples que você pode usar para armazenar e recuperar qualquer quantidade de dados, a qualquer momento, de qualquer lugar na web e (com a AWS CLI ou AWS SDK) você pode integrá-lo com diferentes sistemas e linguagens de programação.
Como usar
O Amazon S3 usa buckets. São contêineres exclusivos para tudo o que você armazena no Amazon S3. Portanto, a primeira etapa é acessar o console de gerenciamento do Amazon S3 e criar um novo bucket.
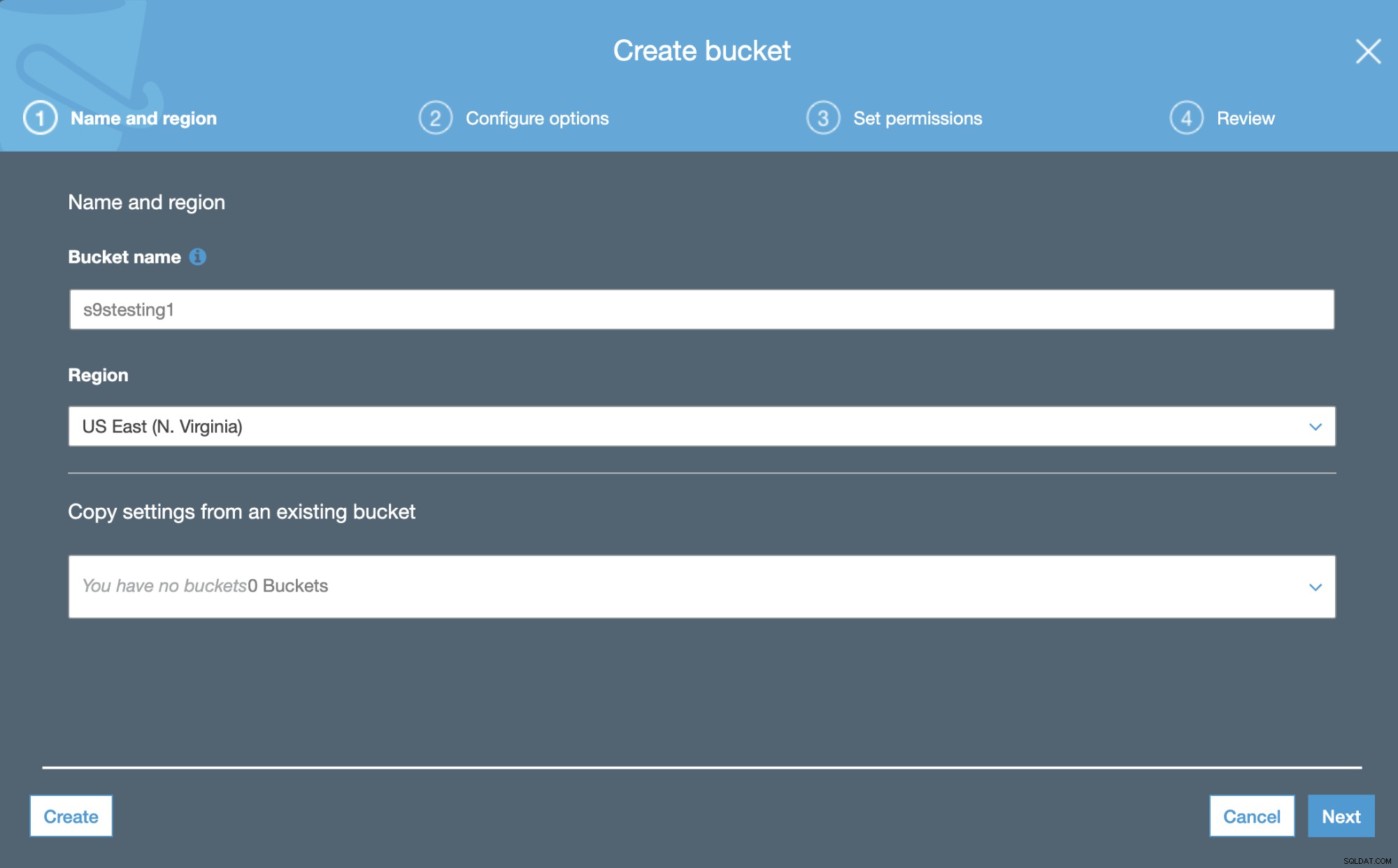
Na primeira etapa, basta adicionar o nome do bucket e o Região da AWS.
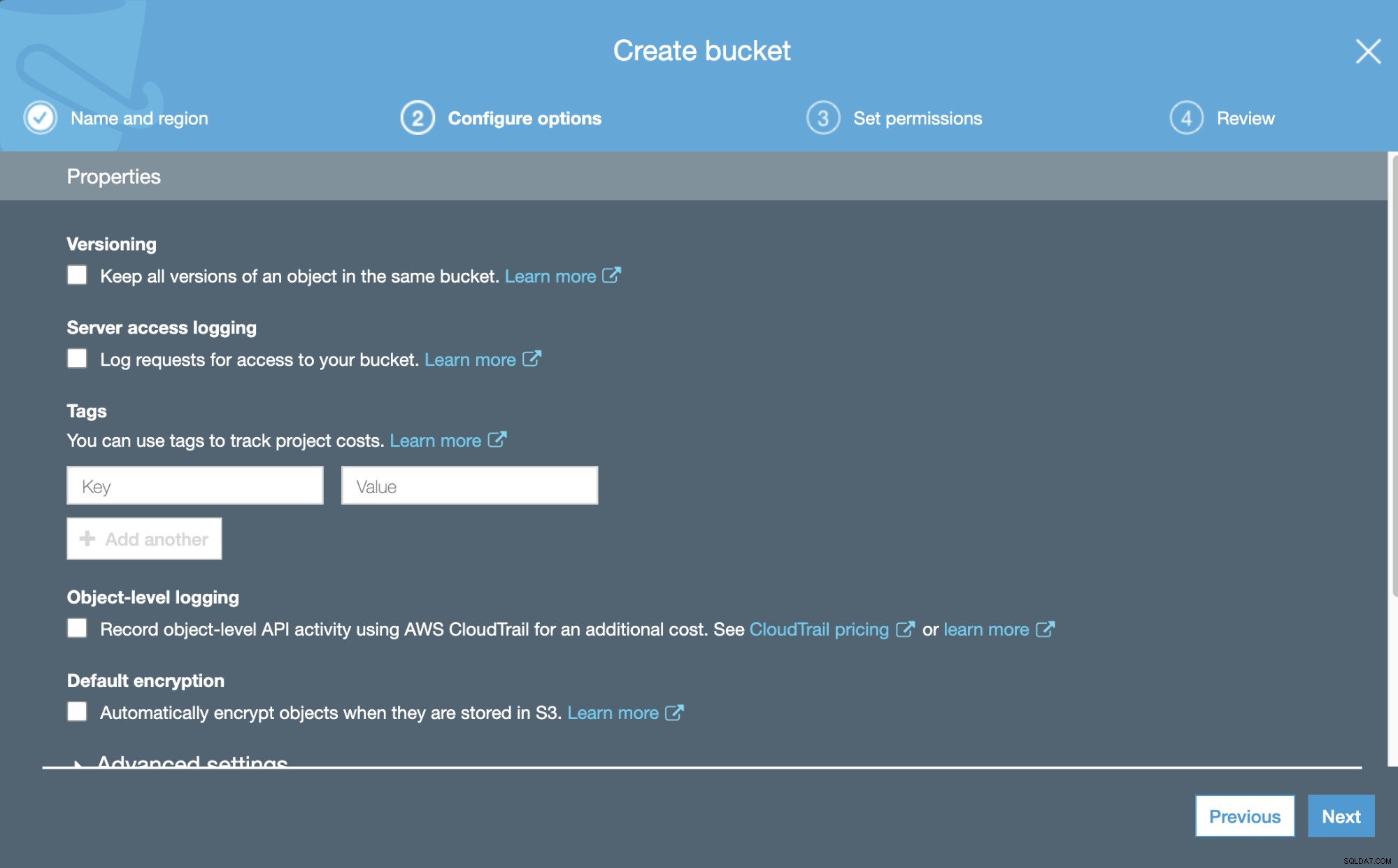
Agora, podemos configurar alguns detalhes sobre nosso novo Bucket, como versionamento e exploração madeireira.

E então, podemos especificar as permissões para este novo Bucket.
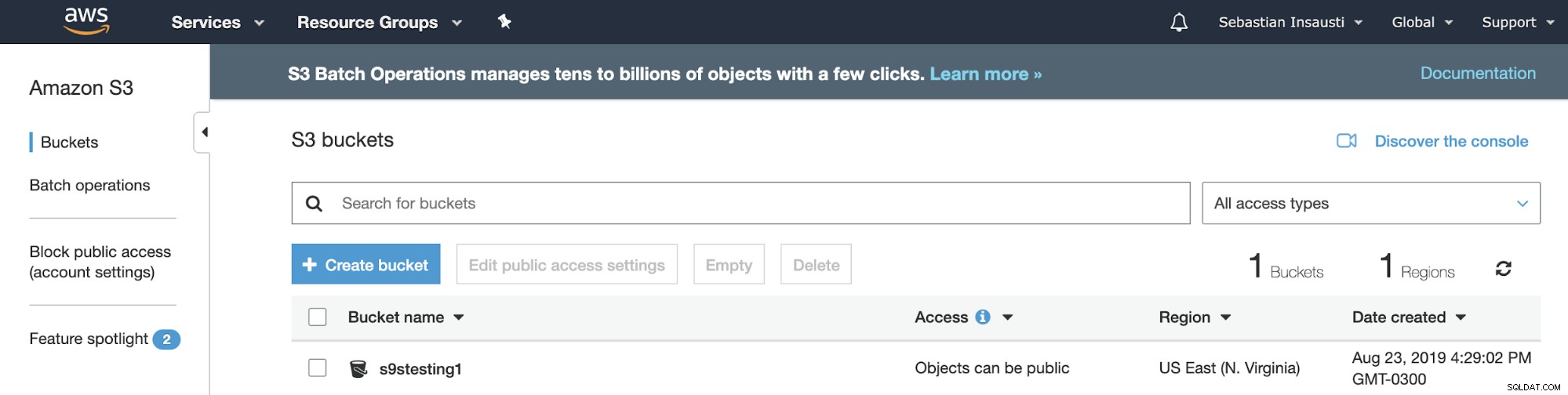
Agora temos nosso Bucket criado, vamos ver como podemos usá-lo para armazenar nossos backups do PostgreSQL.
Primeiro, vamos testar nosso cliente conectando-o ao S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Funciona! Com o comando anterior, listamos os Buckets atuais criados.
Então, agora, podemos apenas enviar o backup para o serviço S3. Para isso, podemos usar o comando aws sync ou aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Podemos verificar o conteúdo do Bucket no site da AWS.
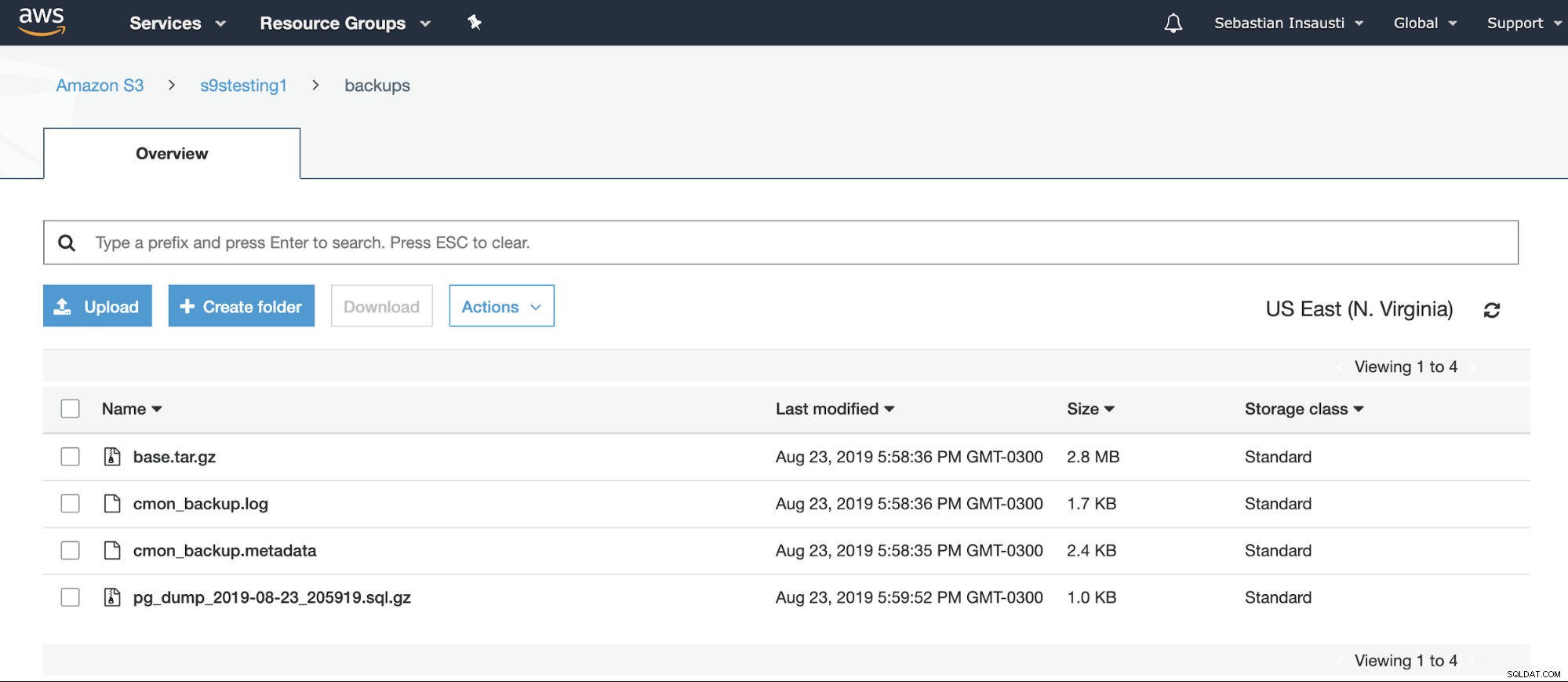
Ou mesmo usando a AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzPara obter mais informações sobre a AWS S3 CLI, você pode verificar a documentação oficial da AWS.
Amazon S3 Glacier
Esta é a versão de baixo custo do Amazon S3. A principal diferença entre eles é a velocidade e acessibilidade. Você pode usar o Amazon S3 Glacier se o custo de armazenamento precisar permanecer baixo e você não precisar de acesso de milissegundos aos seus dados. O uso é outra diferença importante entre eles.
Como usar
Em vez de buckets, o Amazon S3 Glacier usa Vaults. É um recipiente para armazenar qualquer objeto. Portanto, a primeira etapa é acessar o console de gerenciamento do Amazon S3 Glacier e criar um novo Vault.
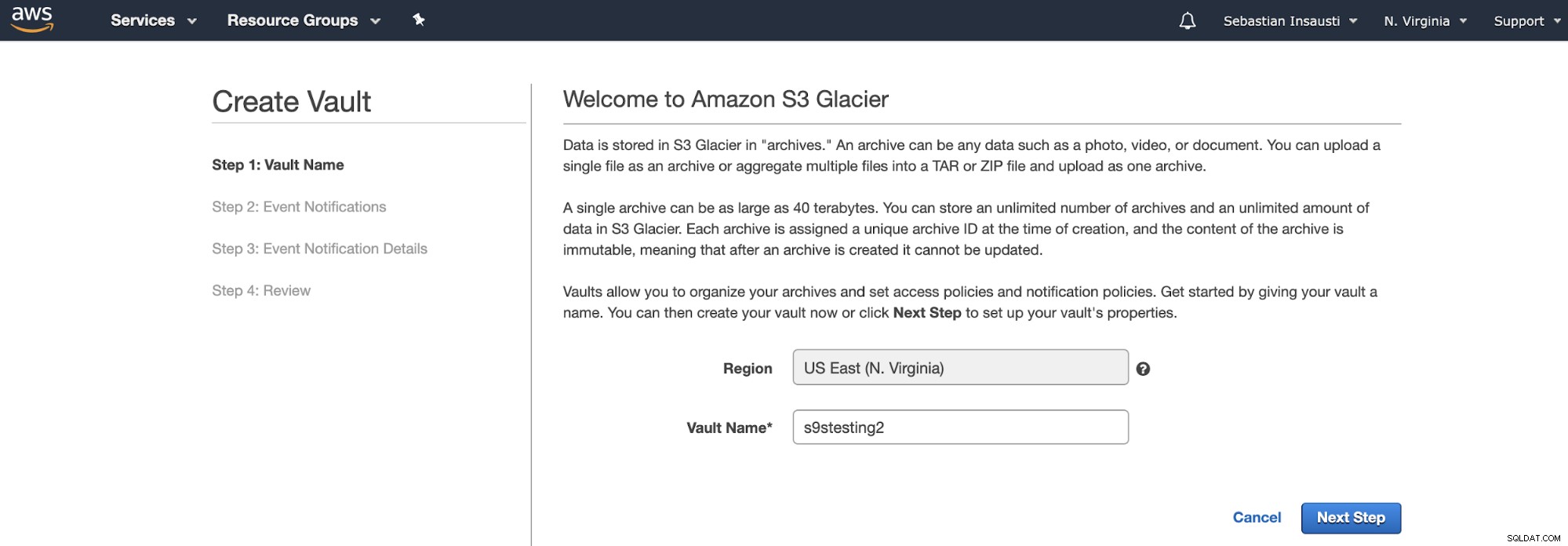
Aqui, precisamos adicionar o nome do cofre e a região e, em na próxima etapa, podemos habilitar as notificações de eventos que usam o Amazon Simple Notification Service (Amazon SNS).
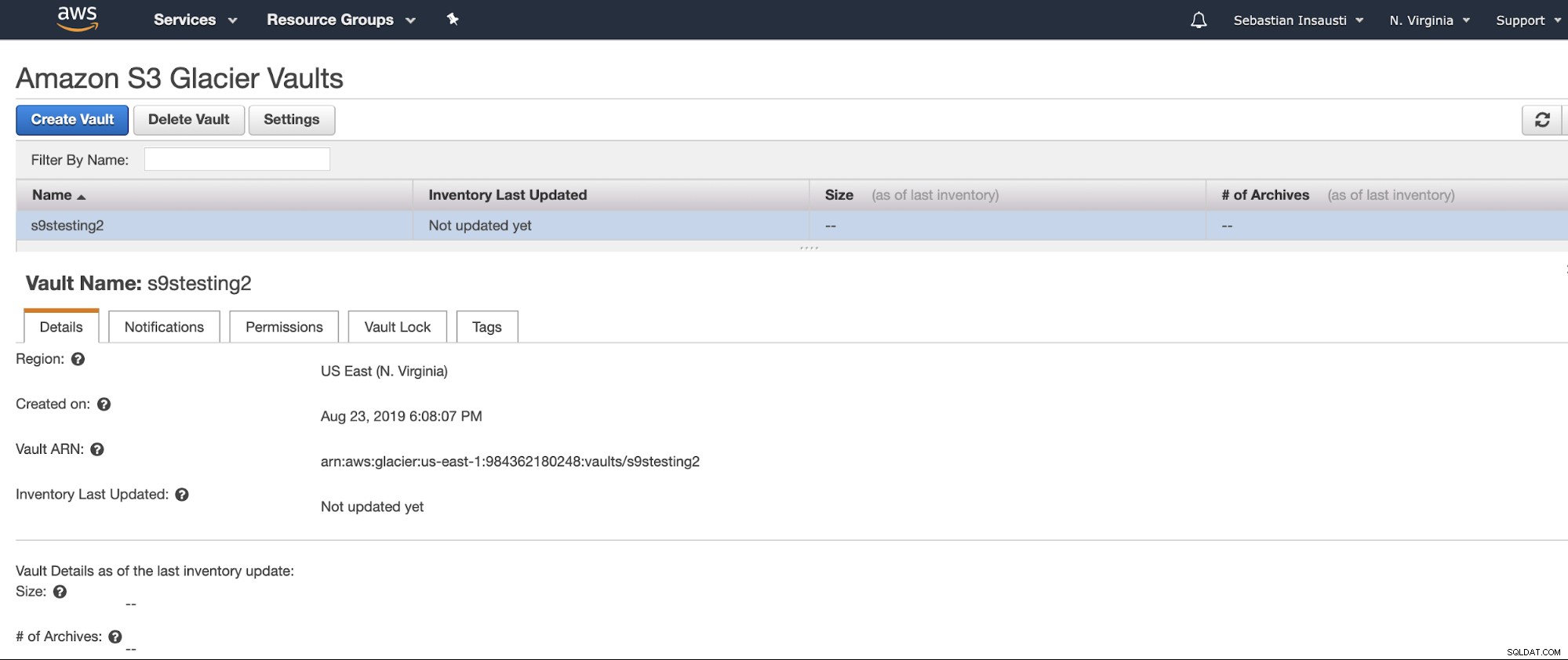
Agora temos nosso Vault criado, podemos acessá-lo na AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Está funcionando. Então agora, podemos fazer o upload do nosso backup aqui.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Uma coisa importante é que o status do Vault é atualizado uma vez por dia, então devemos esperar para ver o arquivo carregado.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Aqui temos nosso arquivo carregado em nosso S3 Glacier Vault.
Para obter mais informações sobre AWS Glacier CLI, você pode verificar a documentação oficial da AWS.
EC2
Esta opção de armazenamento de backup é a mais cara e demorada, mas é útil se você deseja ter controle total sobre o ambiente de armazenamento de backup e deseja executar tarefas personalizadas nos backups (por exemplo, Backup Verification .)
Amazon EC2 (Elastic Compute Cloud) é um serviço da Web que fornece capacidade de computação redimensionável na nuvem. Ele fornece controle completo de seus recursos de computação e permite que você configure tudo sobre suas instâncias, desde seu sistema operacional até seus aplicativos. Ele também permite dimensionar a capacidade rapidamente, tanto para cima quanto para baixo, à medida que seus requisitos de computação mudam.
O Amazon EC2 oferece suporte a diferentes sistemas operacionais, como Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux e FreeBSD.
Como usar
Vá para a seção Amazon EC2 e pressione Launch Instance. Na primeira etapa, você deve escolher o sistema operacional da instância do EC2.
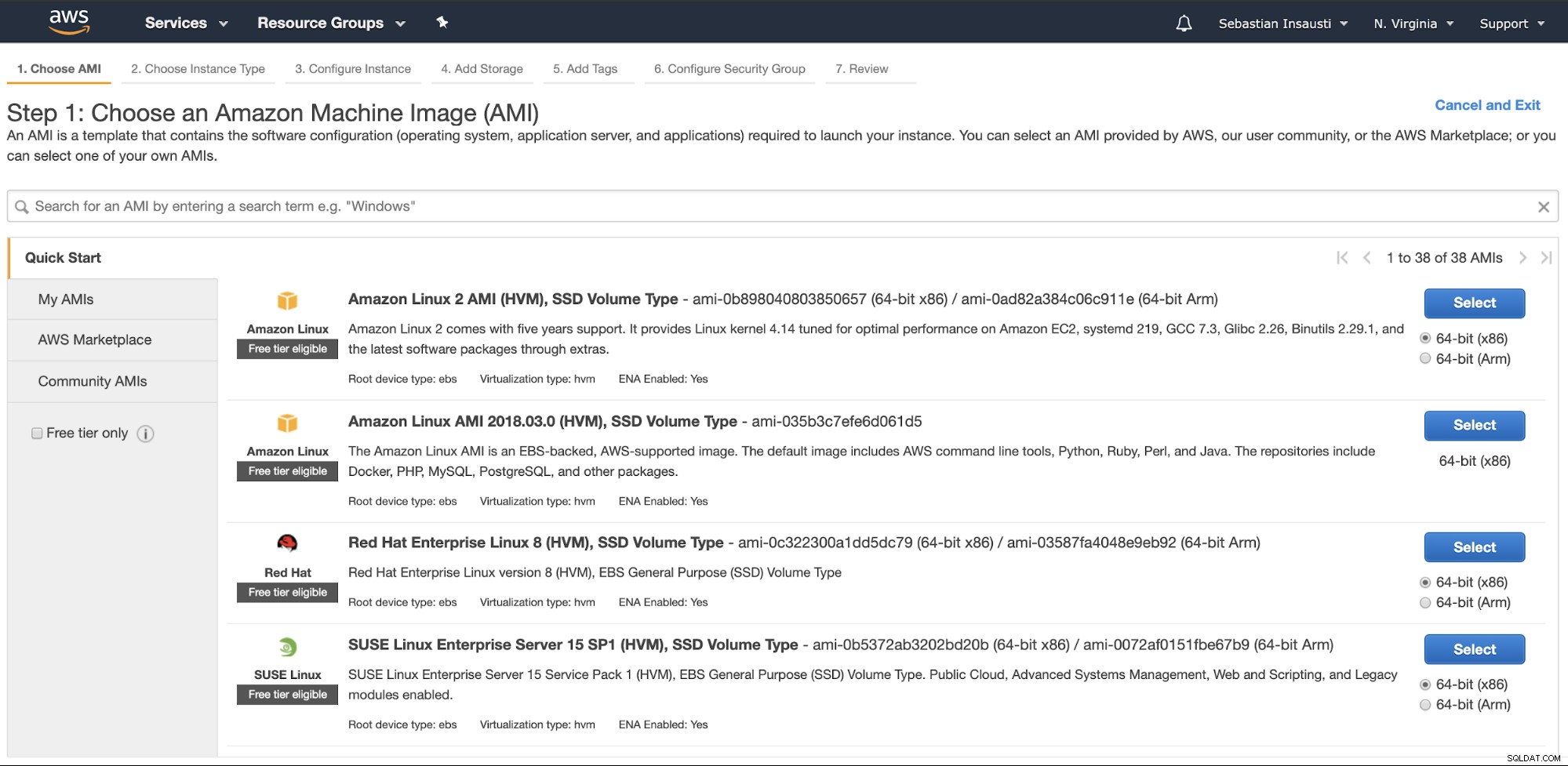
Na próxima etapa, você deve escolher os recursos para a nova instância.
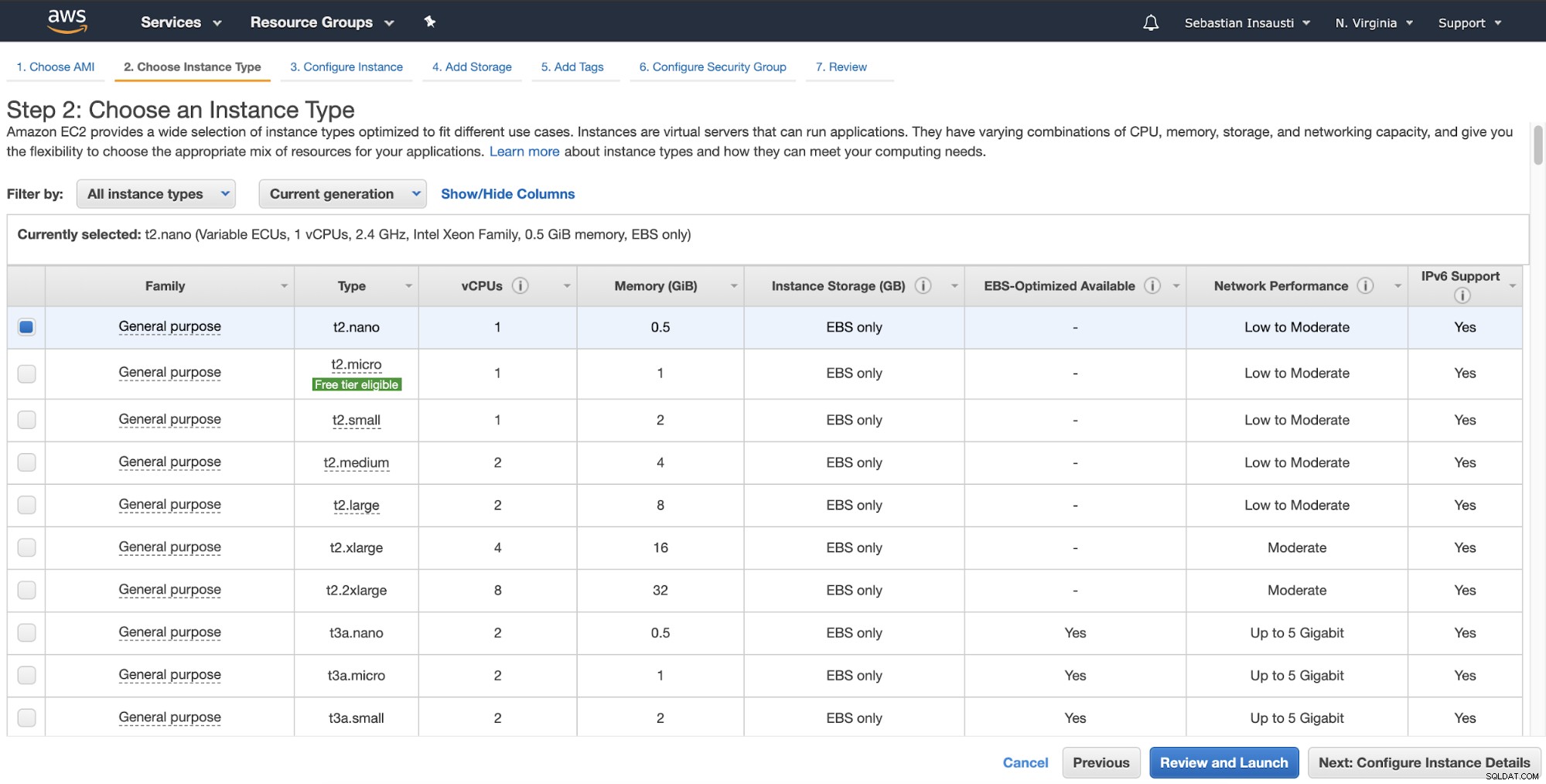
Então, você pode especificar configurações mais detalhadas como rede, sub-rede e mais .
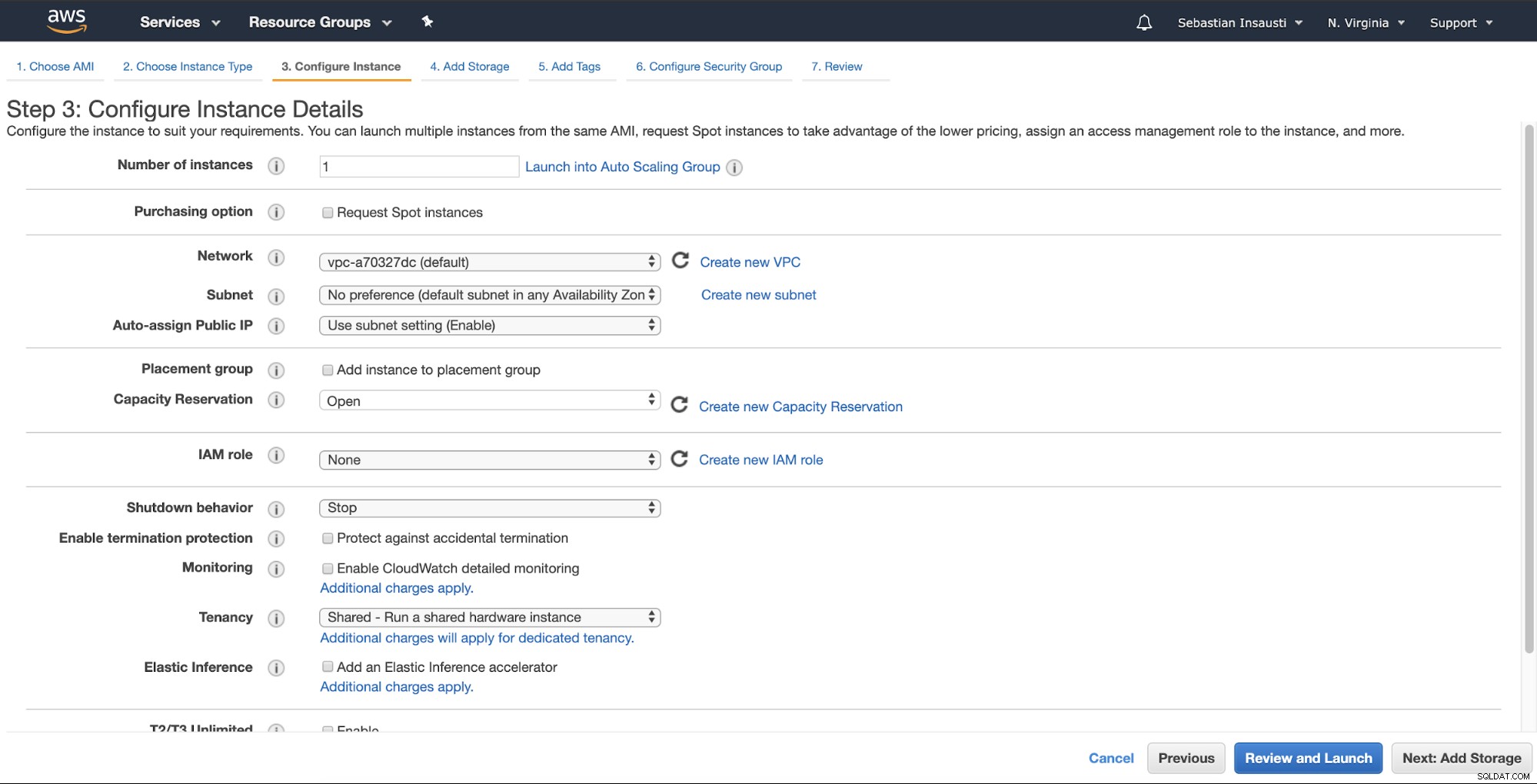
Agora, podemos adicionar mais capacidade de armazenamento nesta nova instância e, conforme um servidor de backup, devemos fazê-lo.
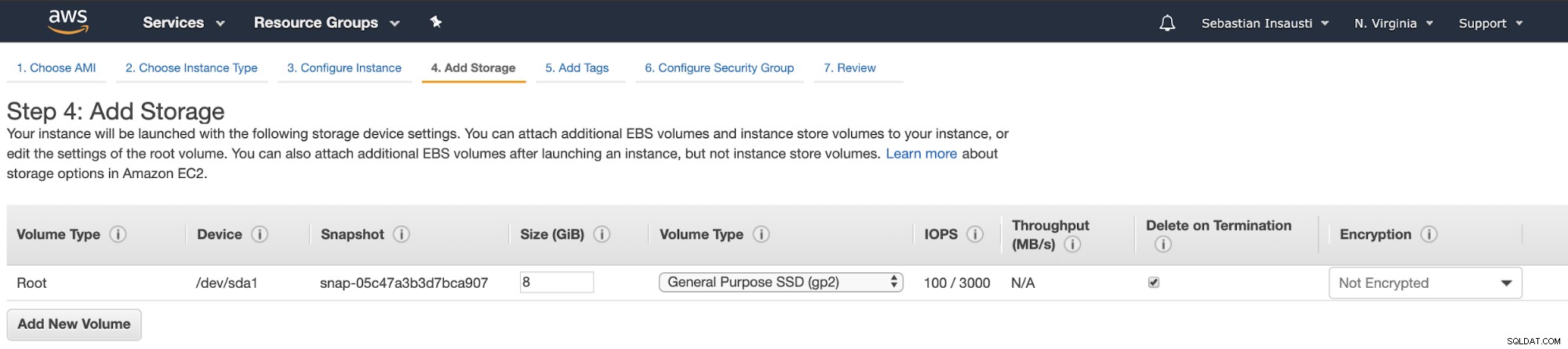
Quando terminarmos a tarefa de criação, podemos ir para a seção Instances para veja nossa nova instância do EC2.
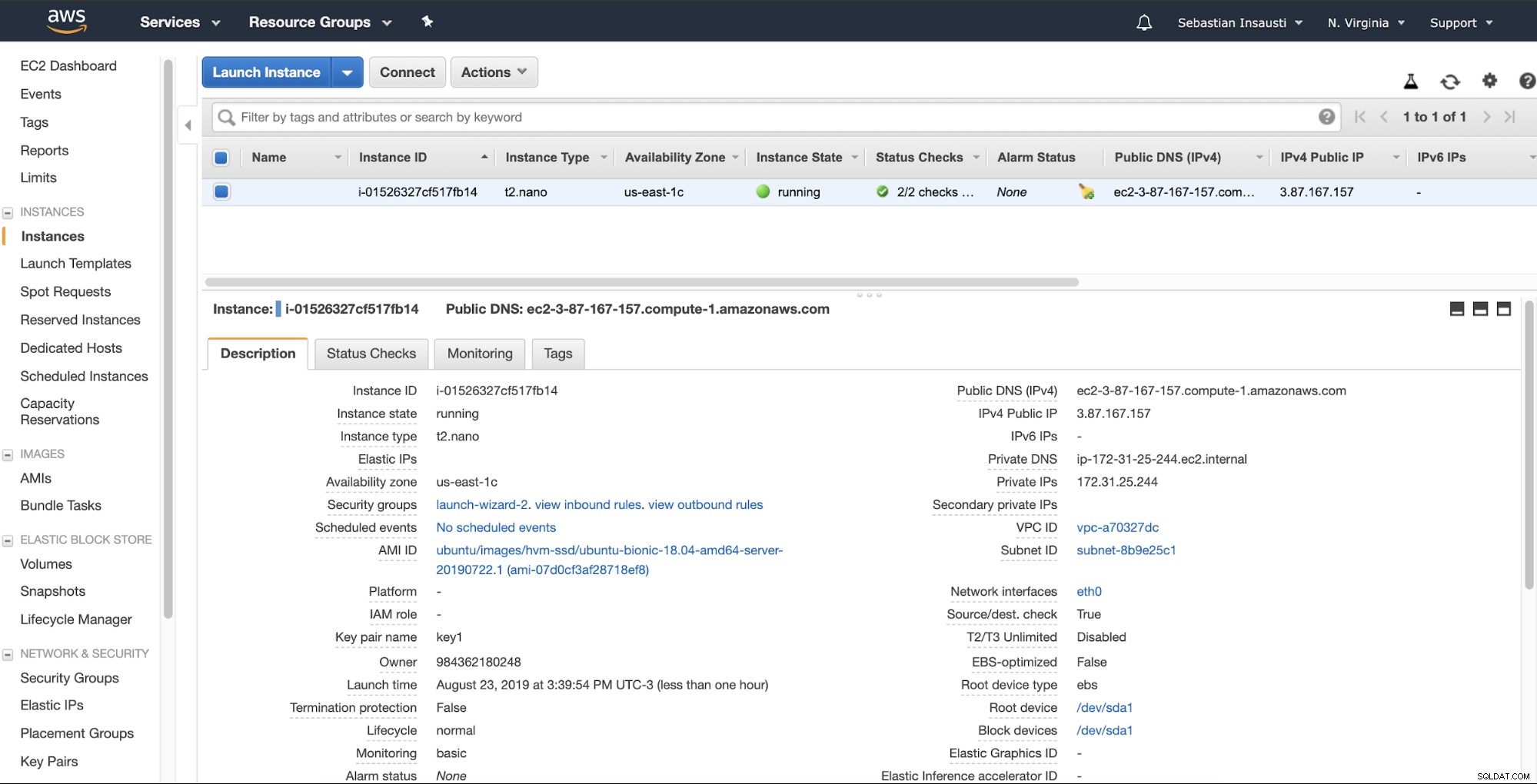
Quando a instância estiver pronta (Estado da instância em execução), você poderá armazenar o backups aqui, por exemplo, enviando via SSH ou FTP usando o DNS público criado pela AWS. Vamos ver um exemplo com Rsync e outro com o comando SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Backup da AWS
O AWS Backup é um serviço de backup centralizado que oferece recursos de gerenciamento de backup, como agendamento de backup, gerenciamento de retenção e monitoramento de backup, além de recursos adicionais, como backups de ciclo de vida para um camada de armazenamento, armazenamento de backup e criptografia independente de seus dados de origem e políticas de acesso de backup.
Você pode usar o AWS Backup para gerenciar backups de volumes do EBS, bancos de dados RDS, tabelas do DynamoDB, sistemas de arquivos EFS e volumes do Storage Gateway.
Como usar
Vá para a seção AWS Backup no Console de gerenciamento da AWS.
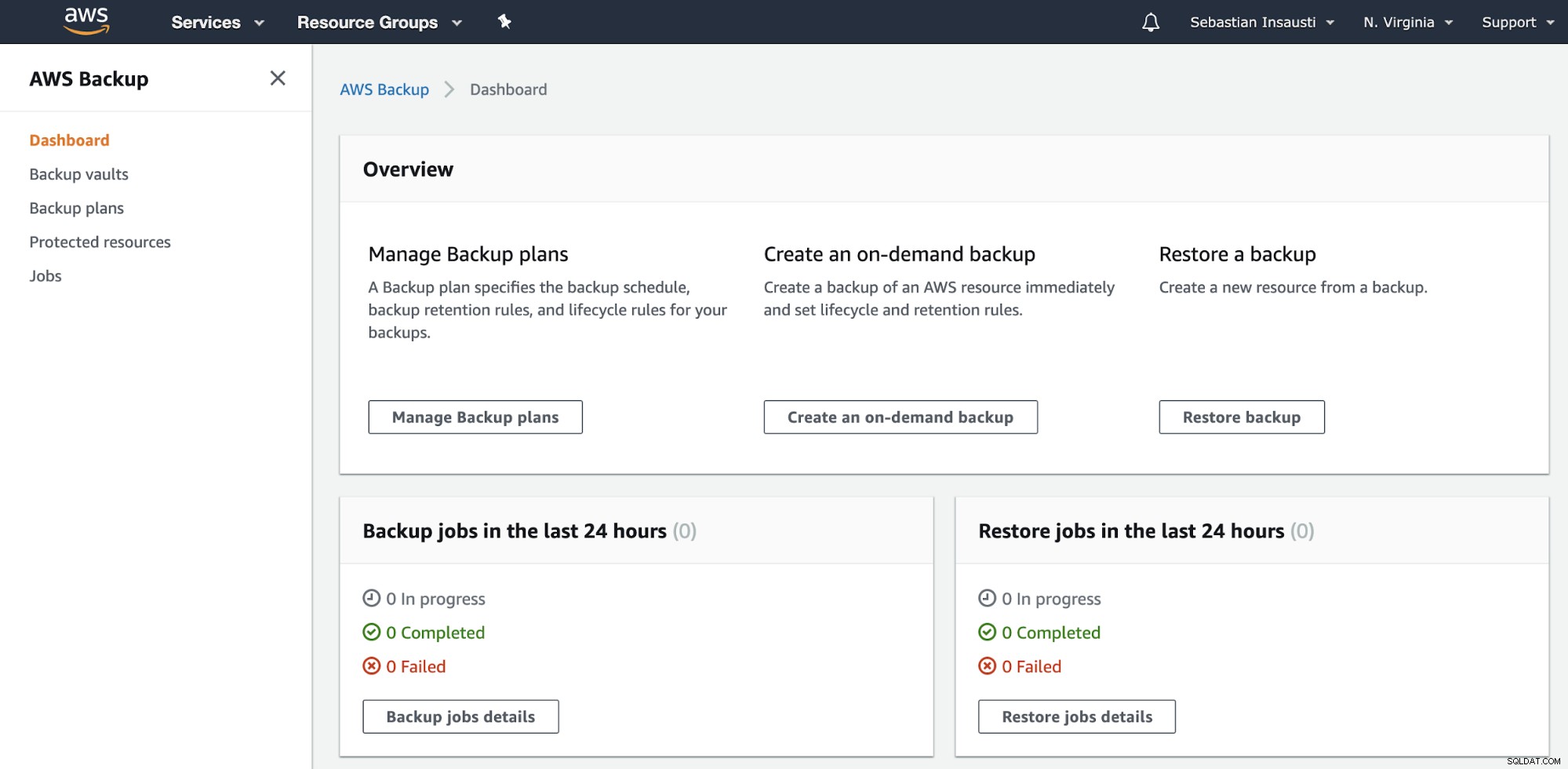
Aqui você tem opções diferentes, como Agendar, Criar ou Restaurar um backup . Vamos ver como criar um novo backup.
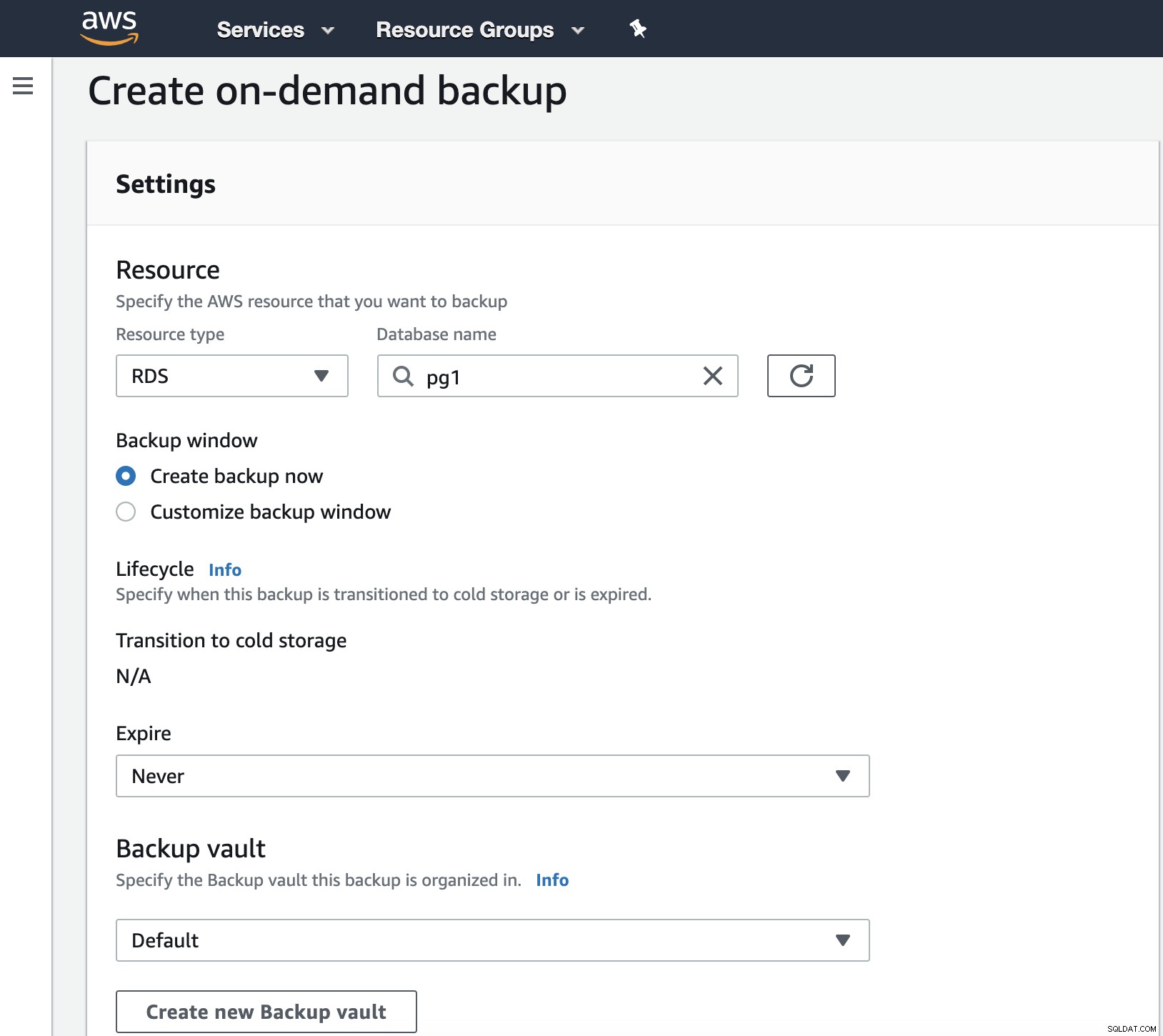
Nesta etapa, devemos escolher o Tipo de Recurso que pode ser DynamoDB, RDS, EBS, EFS ou Storage Gateway e mais detalhes como data de expiração, cofre de backup e função do IAM.
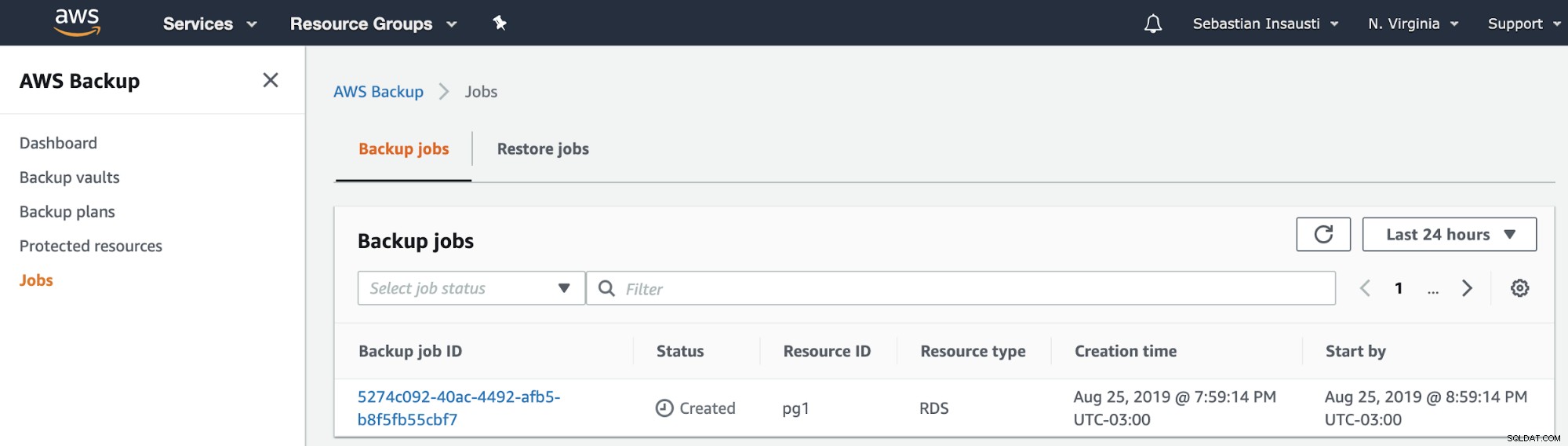
Em seguida, podemos ver a nova tarefa criada na seção AWS Backup Jobs .
Instantâneo
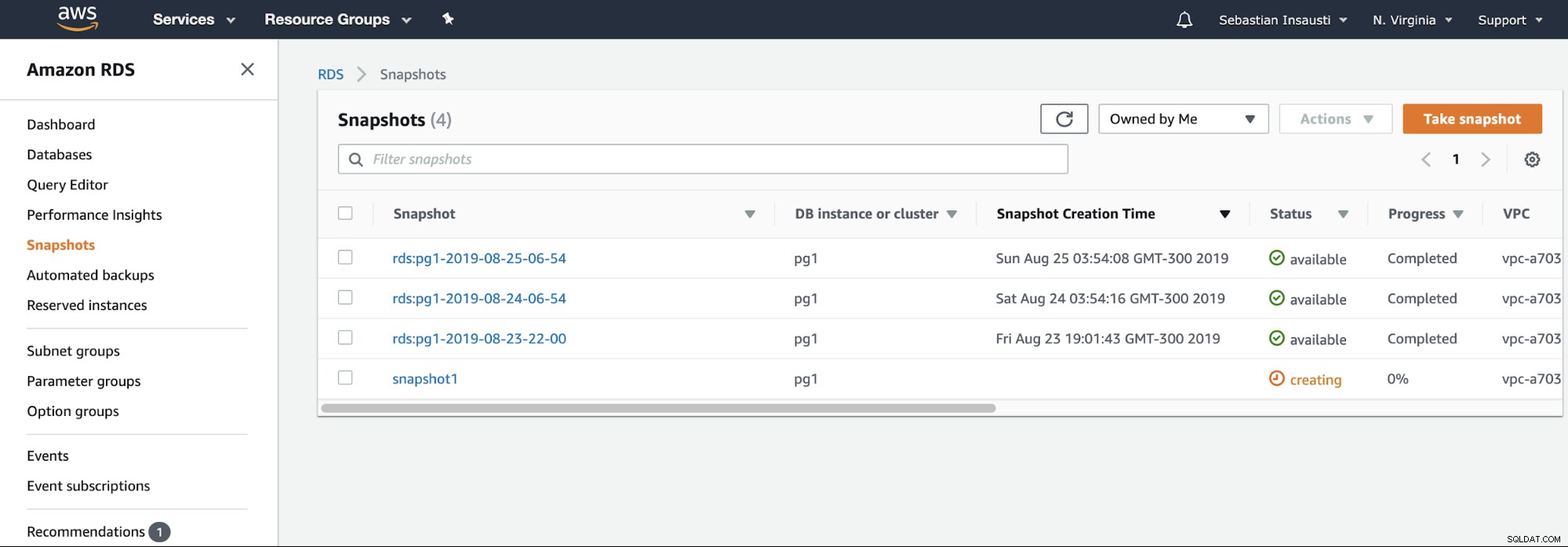
Agora, podemos citar esta opção conhecida em todos os ambientes de virtualização. O snapshot é um backup feito em um momento específico e a AWS nos permite usá-lo para os produtos da AWS. Vejamos um exemplo de um instantâneo do RDS.
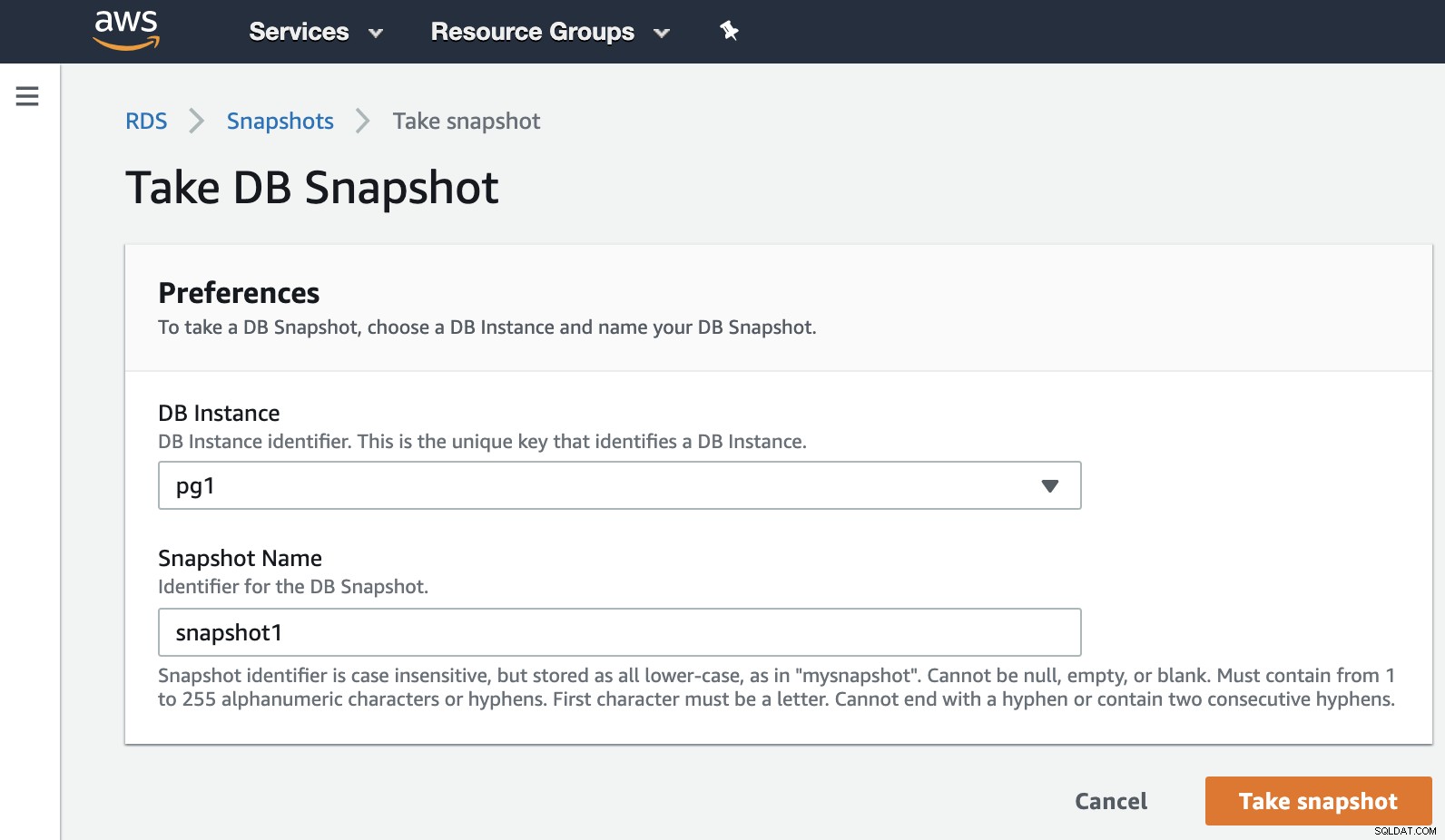
Só precisamos escolher a instância e adicionar o nome do snapshot, e pronto isto. Podemos ver este e o instantâneo anterior na seção RDS Snapshot.
Gerenciando seus backups com ClusterControl
ClusterControl é um sistema de gerenciamento abrangente para bancos de dados de código aberto que automatiza as funções de implantação e gerenciamento, bem como o monitoramento de integridade e desempenho. O ClusterControl oferece suporte à implantação, gerenciamento, monitoramento e dimensionamento para diferentes tecnologias e ambientes de banco de dados, incluindo o EC2. Assim, podemos, por exemplo, criar nossa instância EC2 na AWS e implantar/importar nosso serviço de banco de dados com o ClusterControl.

Criando um backup
Para esta tarefa, vá para ClusterControl -> Selecione Cluster -> Backup -> Criar Backup.
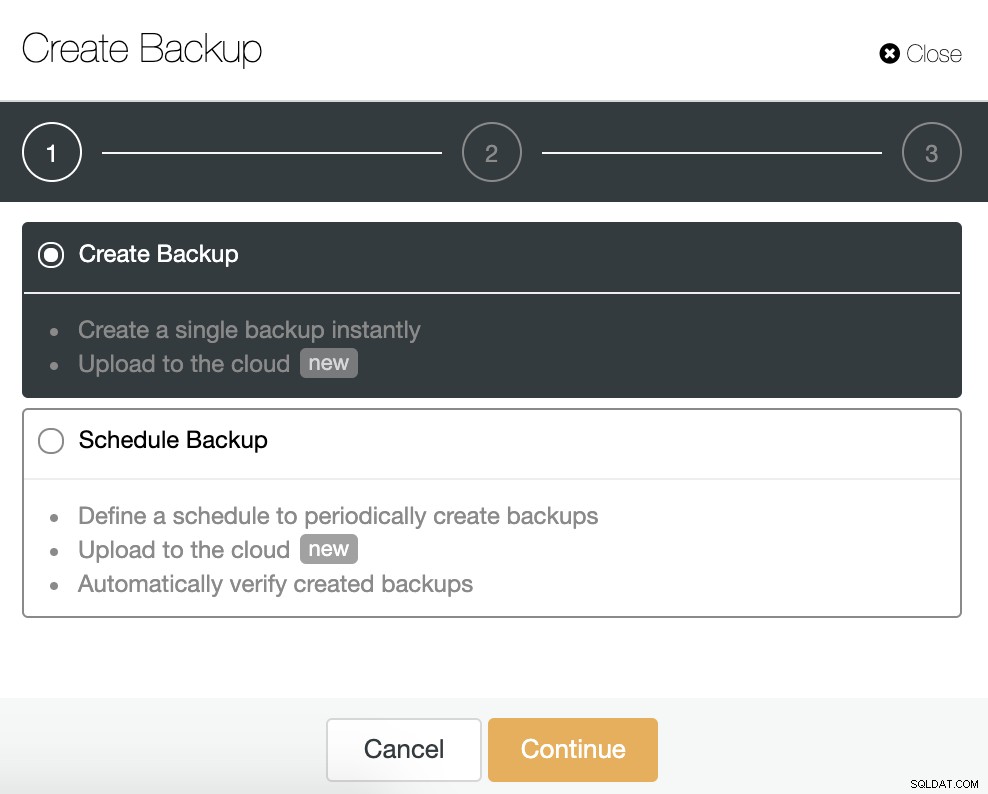
Podemos criar um novo backup ou configurar um agendado. Para o nosso exemplo, criaremos um único backup instantaneamente.
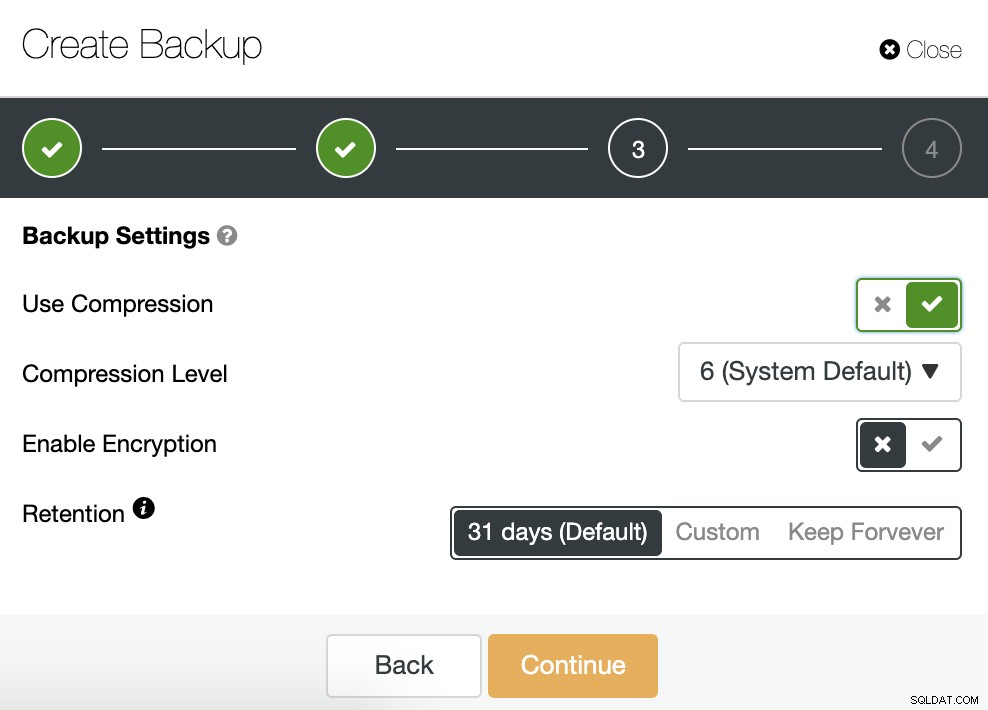
Devemos escolher um método, o servidor do qual o backup será feito , e onde queremos armazenar o backup. Também podemos enviar nosso backup para a nuvem (AWS, Google ou Azure) ativando o botão correspondente.
Depois especificamos o uso de compactação, o nível de compactação, criptografia e retenção período para o nosso backup.
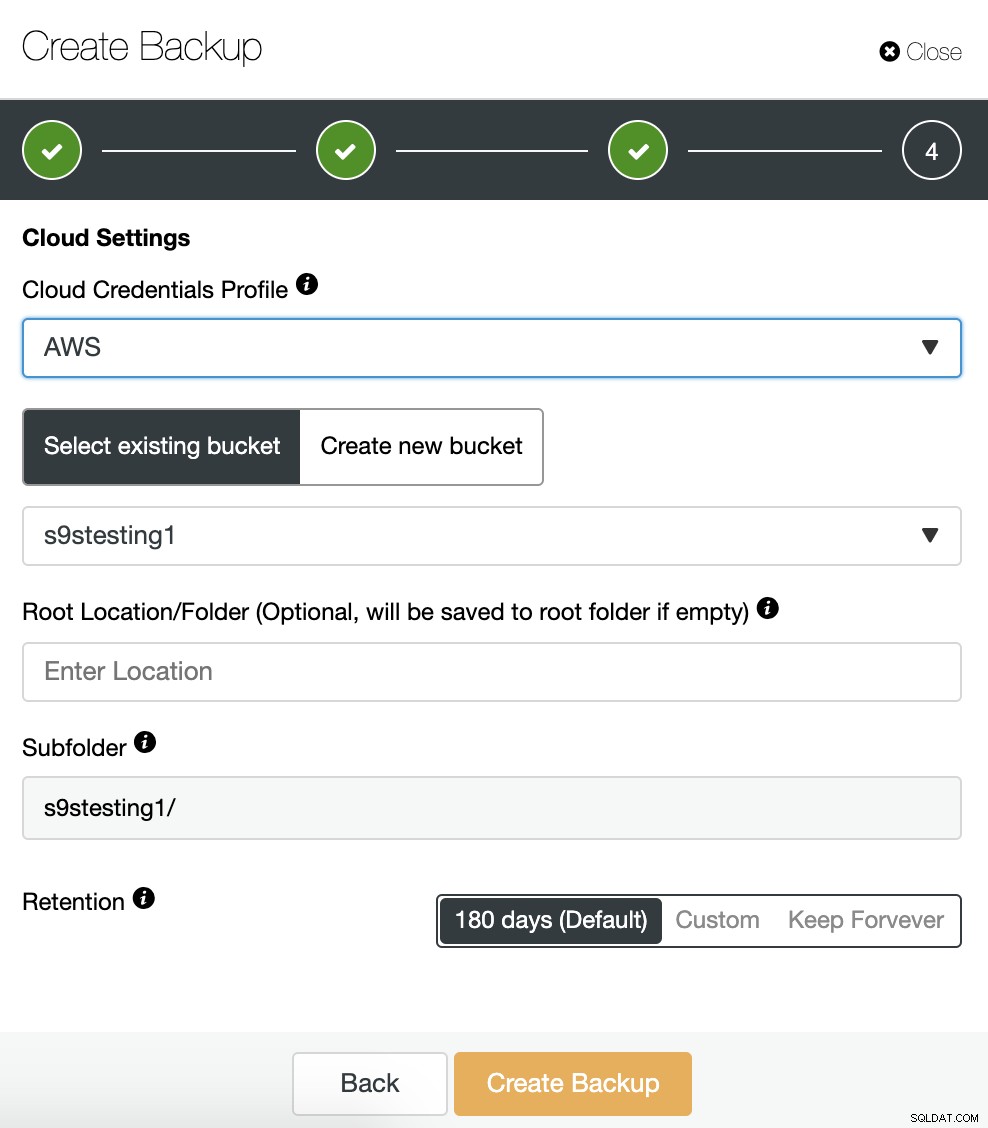
Se habilitamos a opção de upload de backup para a nuvem, veremos uma seção para especificar o provedor de nuvem (neste caso AWS) e as credenciais (ClusterControl -> Integrações -> Provedores de Nuvem). Para AWS, ele usa o serviço S3, então devemos selecionar um Bucket ou até mesmo criar um novo para armazenar nossos backups.
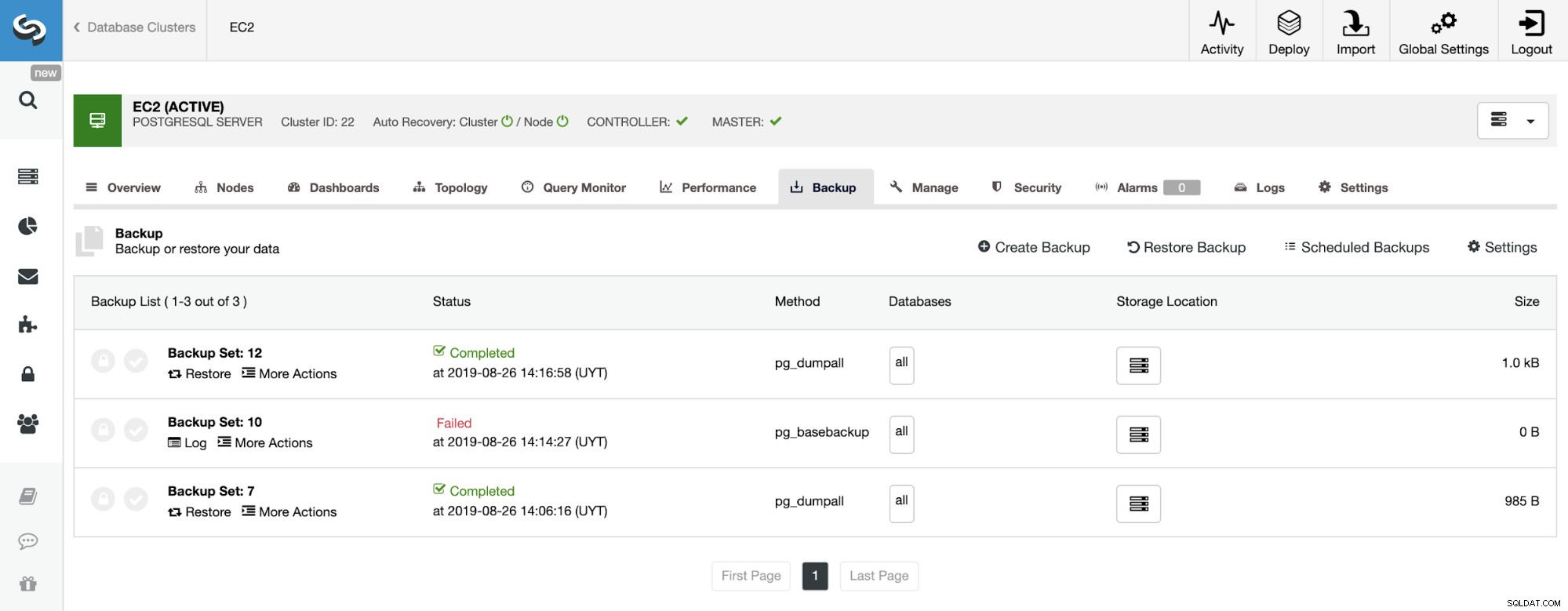
Na seção de backup, podemos ver o progresso do backup e informações como método, tamanho, localização e muito mais.
Conclusão
O Amazon AWS nos permite armazenar nossos backups do PostgreSQL, seja como um provedor de nuvem de banco de dados ou não. Para ter um plano de backup eficaz, considere armazenar pelo menos uma cópia de backup do banco de dados na nuvem para evitar a perda de dados em caso de falha de hardware em outro armazenamento de backup. A nuvem permite armazenar quantos backups você deseja armazenar ou pagar.