É bastante comum usar a nuvem para armazenar seus dados ou como opção de failover em caso de falha do mestre. Existem vários provedores de nuvem que permitem armazenar, gerenciar, recuperar e manipular dados por meio de uma plataforma de nuvem; acessível pela internet. Cada provedor de nuvem tem suas próprias ofertas de produtos e recursos exclusivos, cada um com diferentes modelos de custo.
O Microsoft Azure é um desses provedores possíveis. Neste blog, veremos quais recursos o Microsoft Azure oferece para armazenamento primário, como um site de recuperação de desastres, e veremos especificamente como ele lida com um ambiente de banco de dados PostgreSQL misto.
Implantando uma instância de banco de dados PostgreSQL no Microsoft Azure
Antes de executar esta tarefa, você precisa decidir como usará essa instância e qual produto do Azure é melhor para você. Há duas maneiras básicas de implantar uma instância do PostgreSQL no Microsoft Azure.
- Banco de dados do Azure para PostgreSQL :é um serviço gerenciado que você pode usar para executar, gerenciar e dimensionar bancos de dados PostgreSQL altamente disponíveis na nuvem. Está disponível em duas opções de implantação:servidor único e hiperescala.
- Máquina Virtual :Fornece uma infraestrutura virtualizada sob demanda, de alta escala e segura. Ele tem suporte para Ubuntu Server, RedHat Enterprise Linux, SUSE Linux Enterprise Server, CentOS, Debian e Windows Server e permite desenvolver, testar, executar aplicativos e estender seu datacenter em apenas alguns segundos.
Para este blog, veremos como podemos criar um banco de dados do Azure para PostgreSQL e usar uma máquina virtual Azure do Portal do Microsoft Azure.
Implantando o Banco de Dados do Azure para PostgreSQL
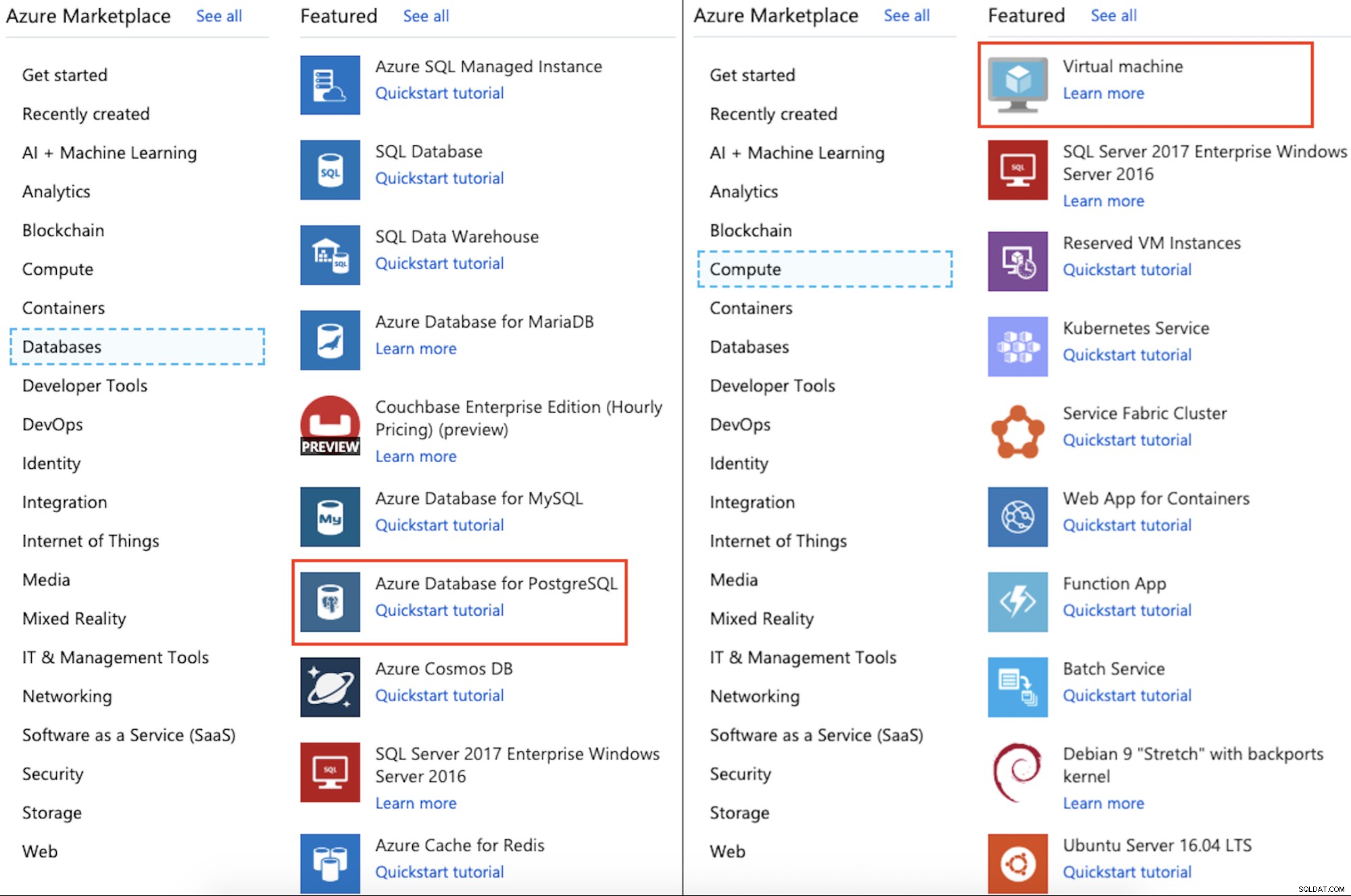
Se você acessar o Portal do Azure -> Criar um Recurso -> Bancos de Dados -> Banco de Dados do Azure para PostgreSQL, poderá escolher entre Servidor Único ou Hiperescala. Para este blog, usaremos um servidor único, pois a opção Hyperscale está em pré-visualização e ainda não oferece um SLA.
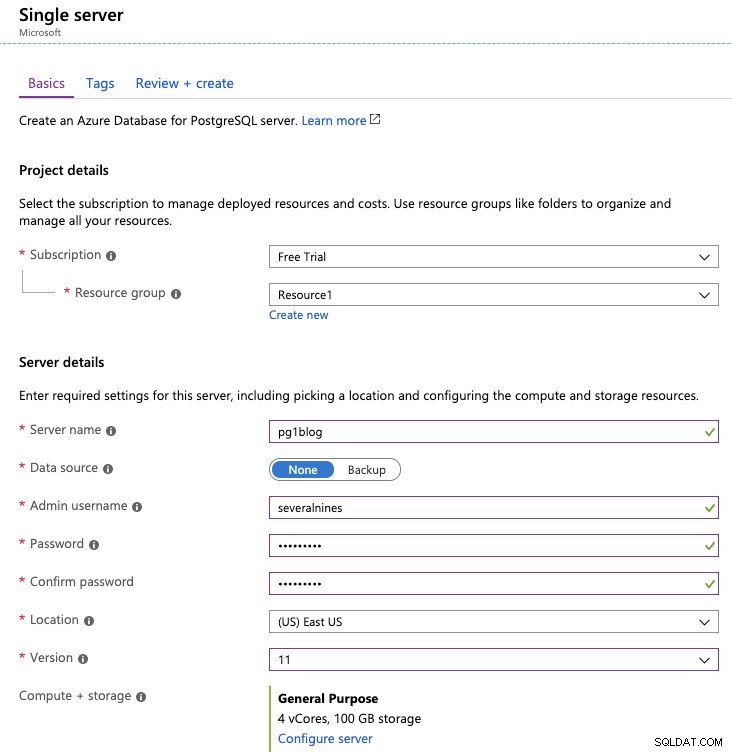
Aqui você precisa adicionar algumas informações sobre sua nova instância do PostgreSQL; como assinatura, nome do servidor, credenciais do usuário e local. Você também pode escolher qual versão do PostgreSQL usar (as versões 9.5, 9.6, 10 ou 11 estão disponíveis no momento) e o hardware virtual para executá-lo (Compute + Storage).
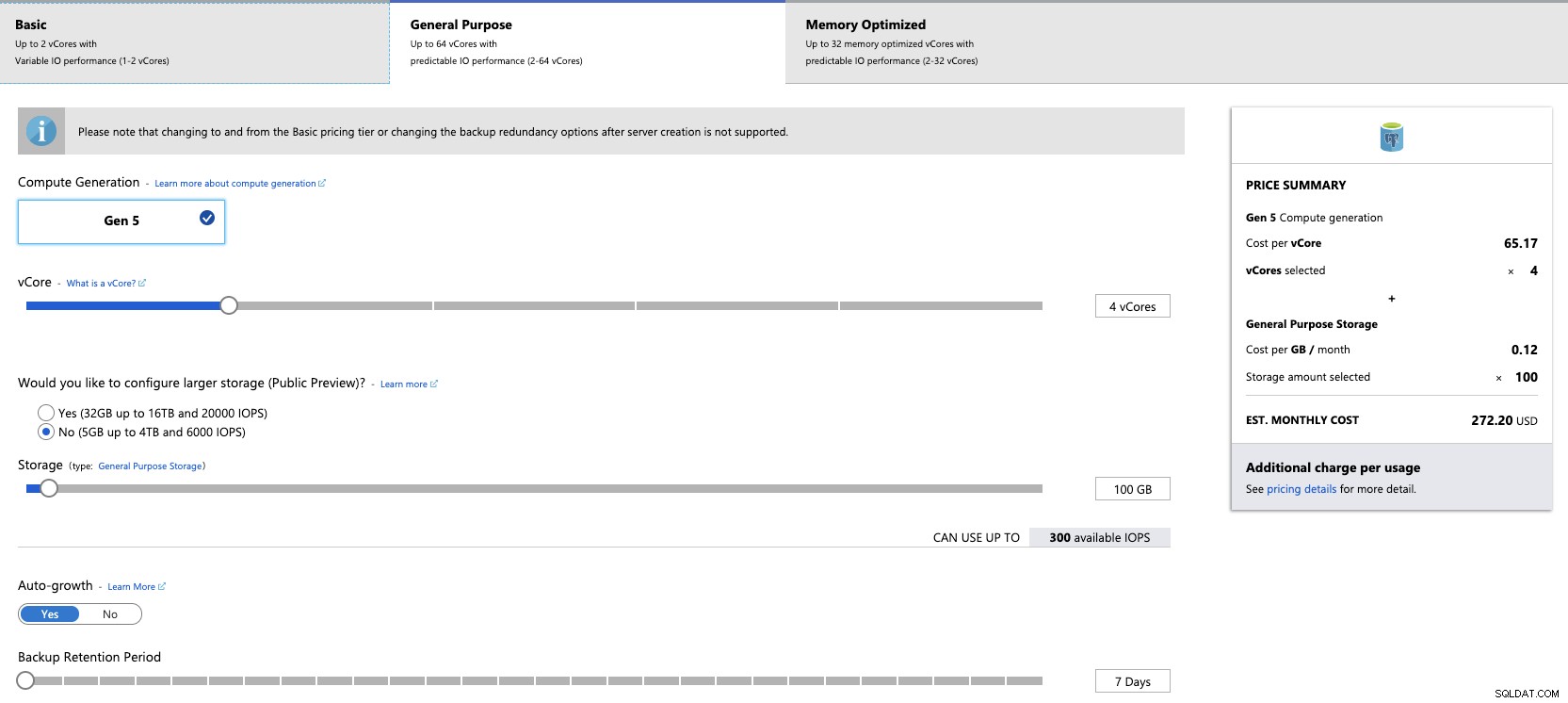
Ao especificar o hardware, você verá o preço estimado em reais -Tempo. Isso é realmente útil para evitar uma grande surpresa no próximo mês. Após esta etapa, basta confirmar a configuração do recurso e aguardar alguns minutos até que o Azure termine o trabalho de criação.
Ao criar o novo recurso, você pode acessar Todos os recursos para ver as opções de recursos disponíveis.
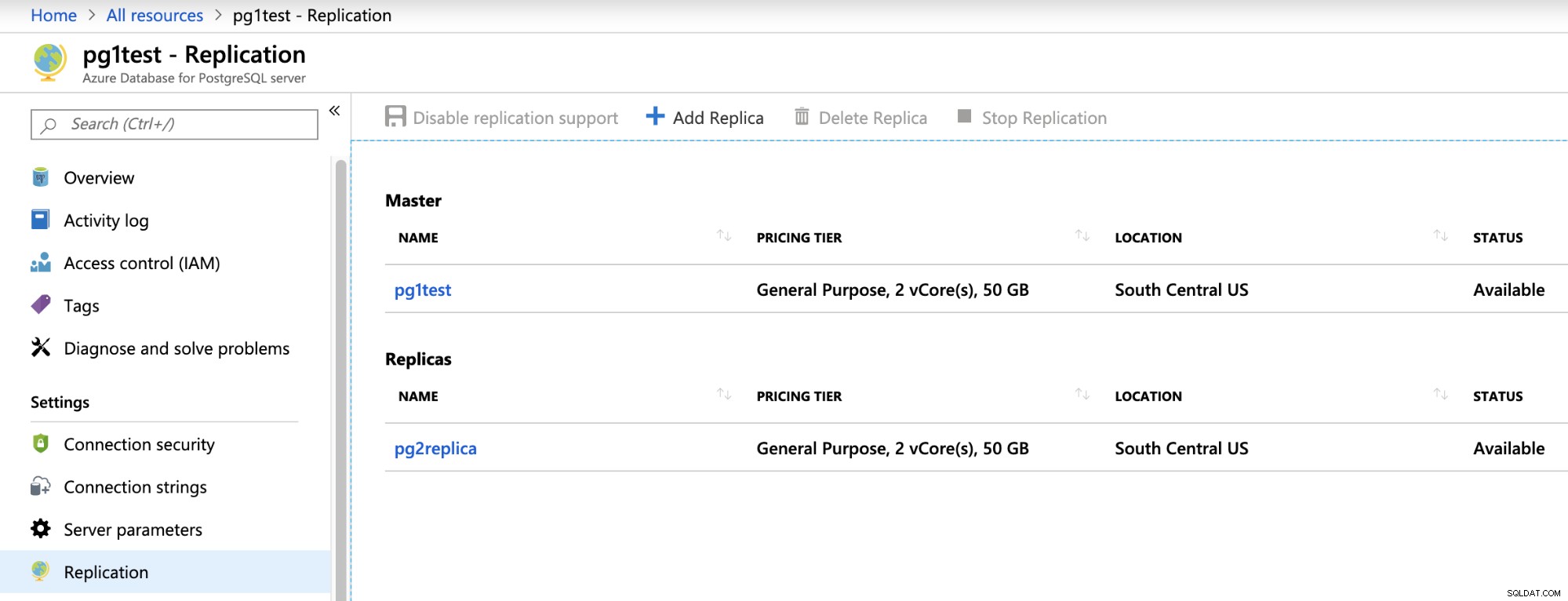
Nas opções de recursos criados, você pode ir para Replicação para habilitá-lo e replicar do servidor mestre para até cinco réplicas. Você também deve verificar a seção Segurança da Conexão para habilitar ou desabilitar o acesso externo. Para conhecer as informações de acesso, você deve visitar a seção de recursos de visão geral.
$ psql -h pg1blog.postgres.database.azure.com -U example@sqldat.com postgres
Password for user example@sqldat.com:
psql (11.5, server 11.4)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=>Failover no Banco de Dados do Azure para PostgreSQL
Infelizmente, o failover automatizado entre servidores mestre e de réplica não está disponível. Se você excluir a instância mestre, no entanto, o Azure executará um processo de failover para promover a réplica de maneira automática.
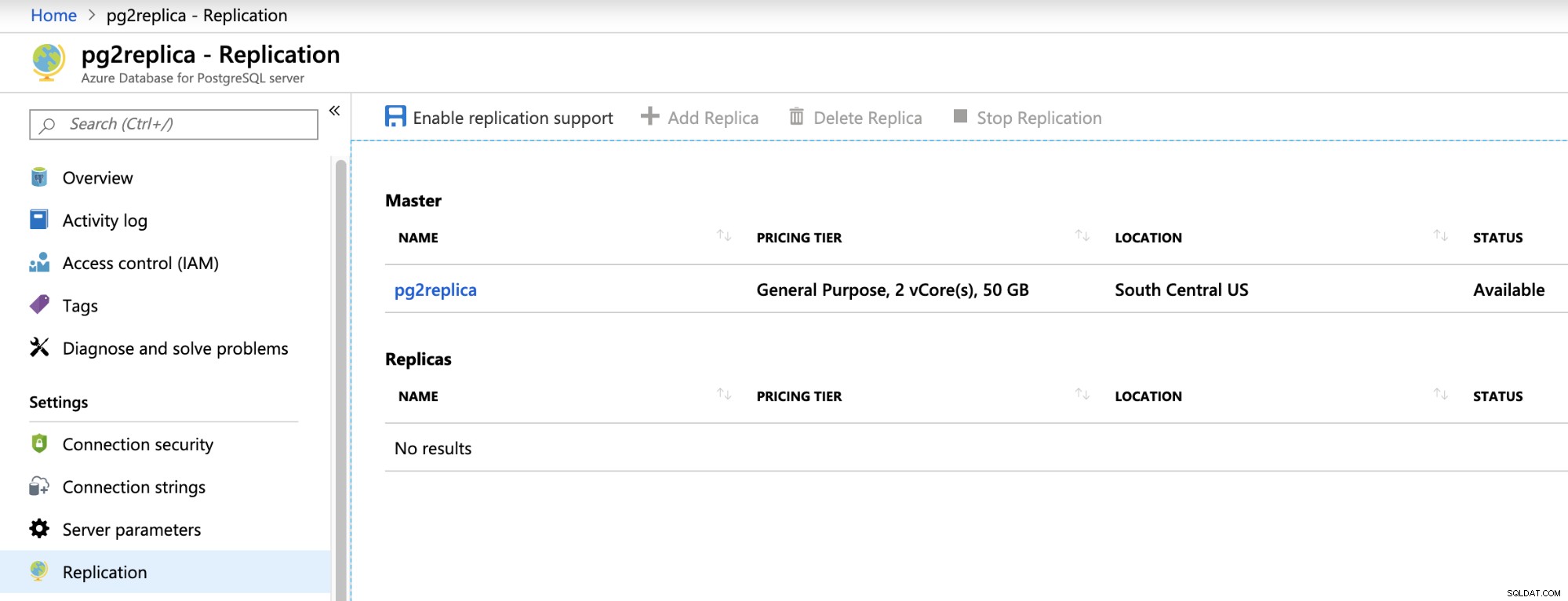
Existe uma opção para executar esta tarefa de failover manualmente, que exige que você interrompa a réplica e configure o novo endpoint em seu aplicativo para apontar para o novo mestre. A réplica será promovida e desvinculada do mestre. Não há como vincular novamente esta réplica ao seu mestre.
Implantando PostgreSQL na Máquina Virtual do Azure
Se você for para o Portal do Azure -> Criar um Recurso -> Computação -> Máquina Virtual, você abrirá a seção Criar uma máquina virtual onde poderá especificar configurações diferentes para sua nova Máquina Virtual do Azure .
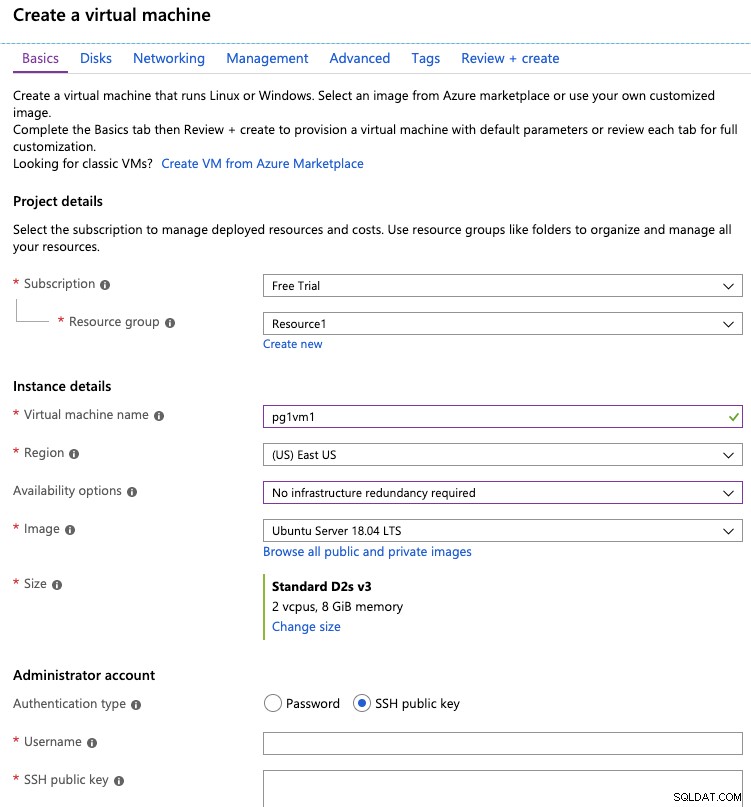
Na guia básica, você deve especificar a assinatura do Azure, Região, Disponibilidade opções, sistema operacional, tamanho do servidor, credenciais de acesso (nome de usuário/senha ou chave SSH) e regras de firewall de entrada.
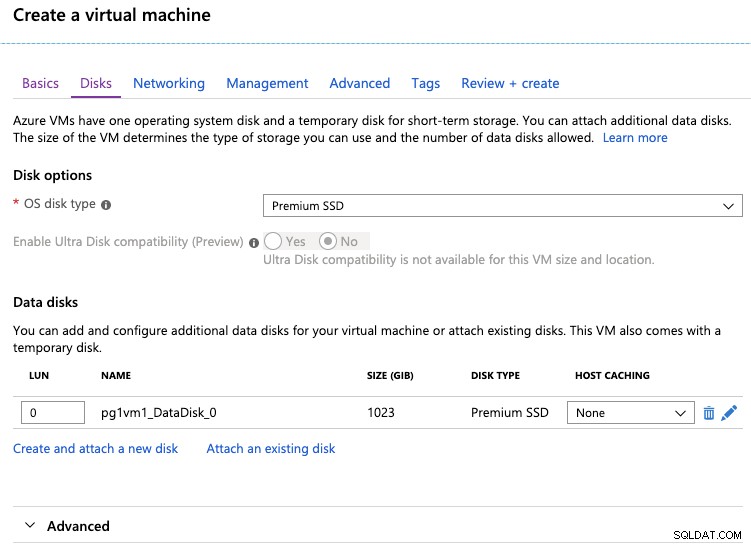
Na guia disco, você deve especificar o armazenamento (tipo e tamanho) para sua nova máquina virtual. O tipo de disco pode ser HDD padrão, SSD padrão ou SSD Premium. O último é recomendado para cargas de trabalho de alto IOPS.
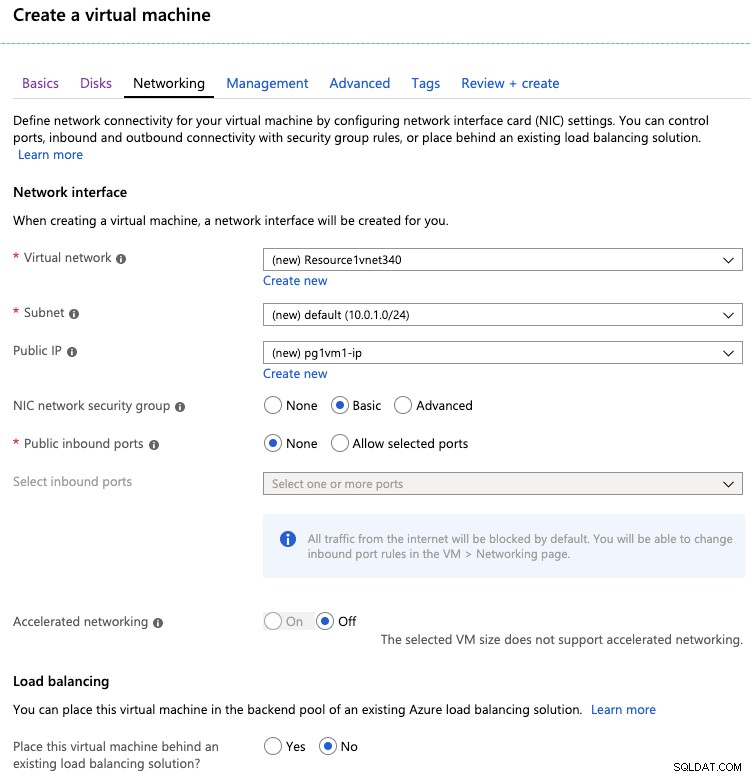
Na guia de rede, você pode especificar a rede virtual, o endereço IP público e as portas de entrada permitidas. Você também pode adicionar essa nova máquina virtual por trás de uma solução de balanceamento de carga do Azure existente.
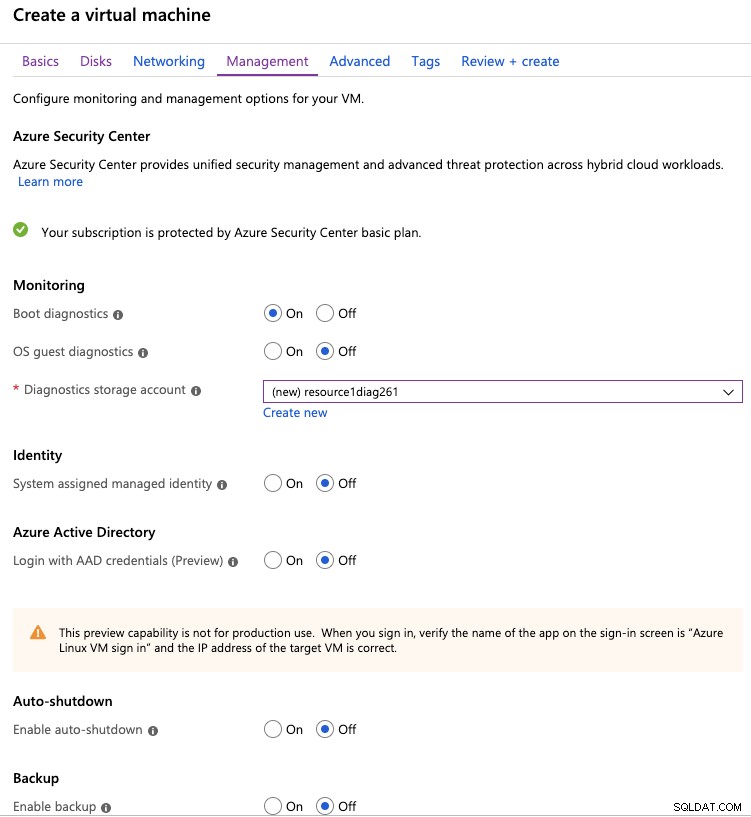
Na próxima aba, temos algumas opções de gerenciamento, como monitoramento e backups .
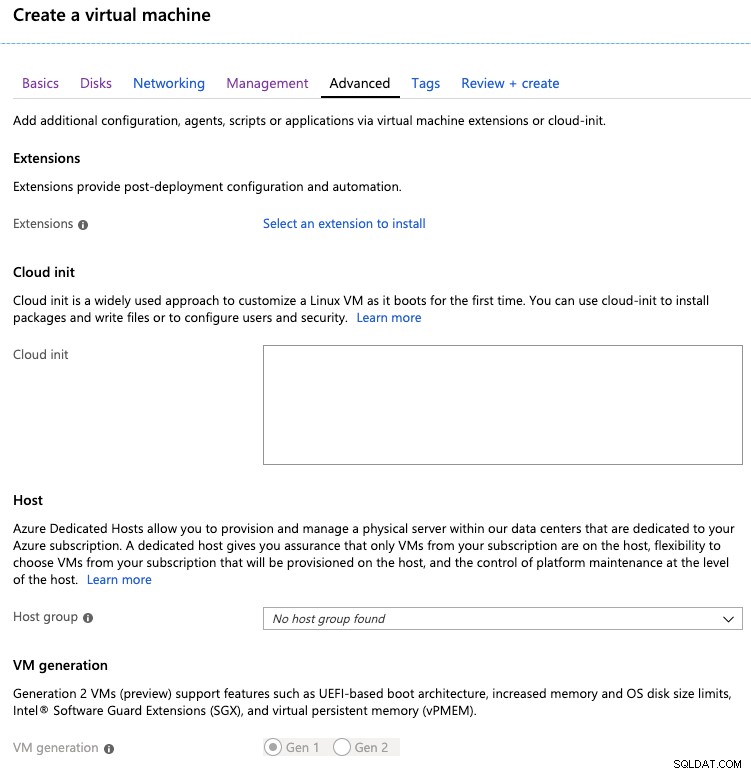
E finalmente, na guia avançada, podemos adicionar extensões, cloud- init ou grupos de hosts.
Após revisar a opção anterior e confirmá-la, você terá sua nova máquina virtual criada e acessível no Portal do Azure. Na seção Recurso -> Visão geral, você pode ver as informações de acesso à máquina virtual (Endereço IP público/privado).
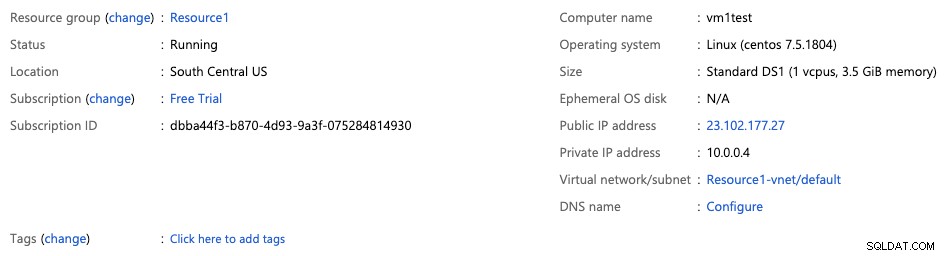
Agora, você pode acessá-lo via SSH e instalar o banco de dados PostgreSQL usando ClusterControl .
$ ssh 23.102.177.27
Last login: Mon Sep 23 21:33:27 2019
[example@sqldat.com ~]$Você pode verificar este link para ver as etapas para realizar a implantação do PostgreSQL com o ClusterControl.
Failover do PostgreSQL na Máquina Virtual do Azure
A recuperação de desastres é um recurso de Máquina Virtual na seção Operações que permite replicar seu ambiente em outra região do Azure. Para habilitá-lo, você precisa escolher a região de destino. Na guia avançada, você pode modificar os detalhes específicos do destino; como rede virtual, configurações de armazenamento e configurações de replicação.
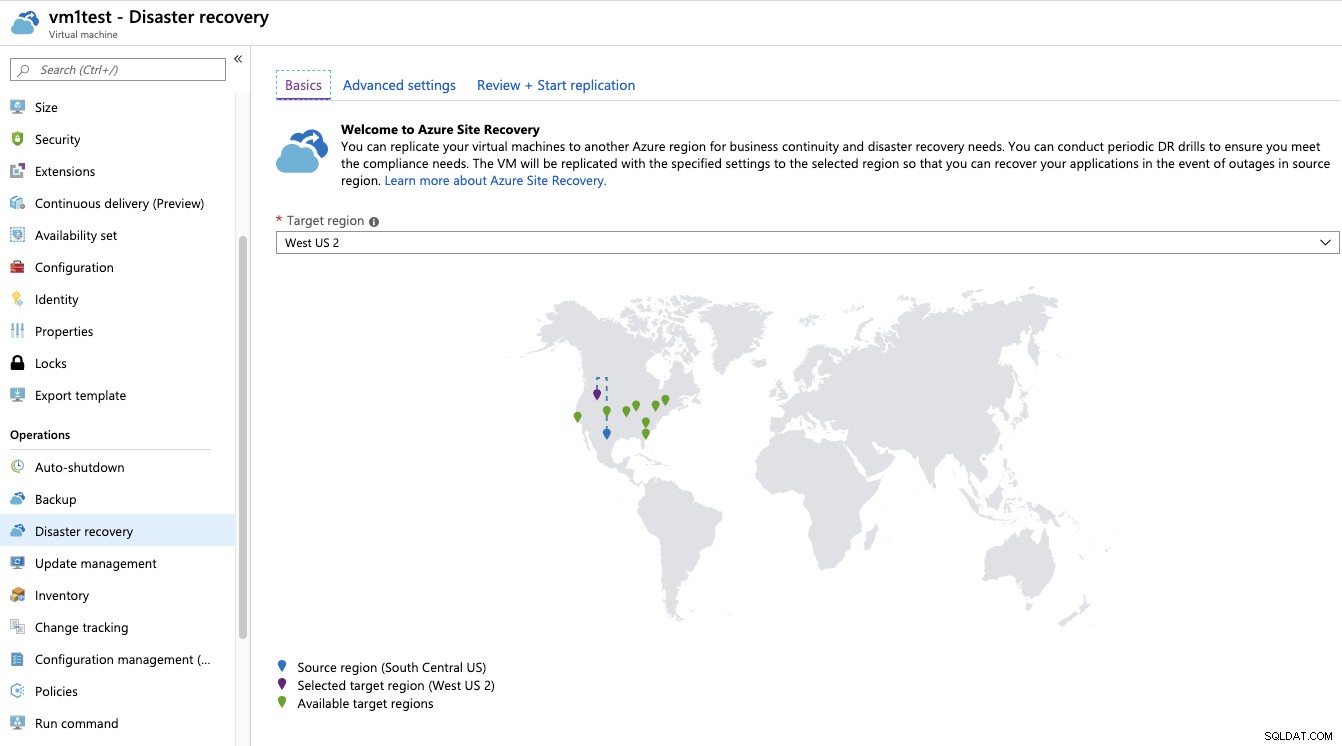
Quando a recuperação de desastres estiver habilitada, você poderá verificar o status de replicação, teste o processo de failover ou failover manualmente para ele.
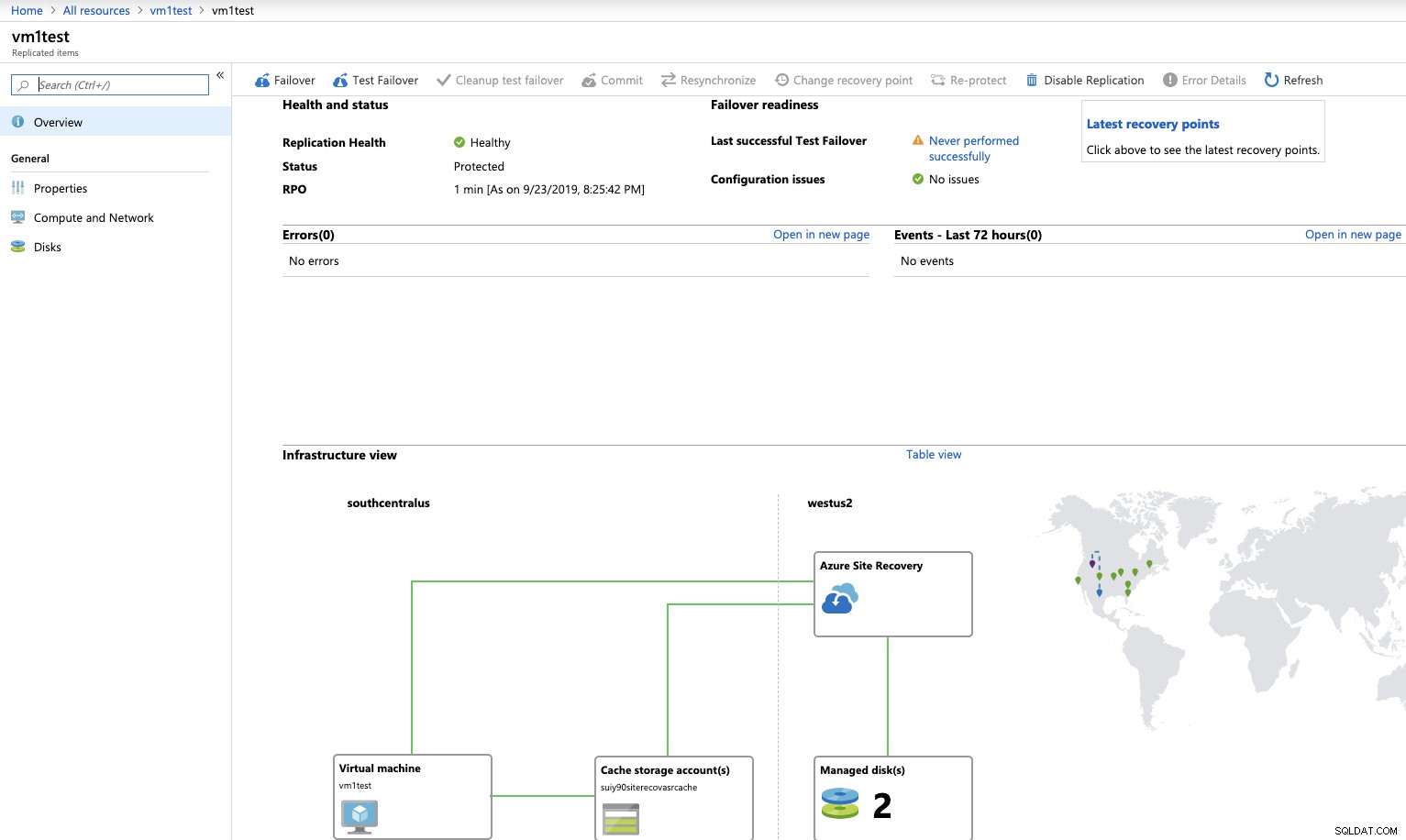
Ativar isso permite que você tenha uma opção de failover em caso de falha. Isso, no entanto, será um failover para todo o ambiente e não apenas para o serviço de banco de dados.
Um processo de failover do PostgreSQL aprimorado para Microsoft Azure
Como você tem acesso SSH, você pode melhorar esse processo de failover importando a máquina virtual (ou mesmo implantando o banco de dados PostgreSQL) com o ClusterControl.
Se você estiver gerenciando os nós do banco de dados com o ClusterControl (e se a opção “Auto Recovery” estiver ativada) no caso de falha do mestre, o ClusterControl promoverá o escravo mais avançado (se não estiver na lista negra ) para dominar, bem como notificá-lo sobre o problema. Ele também faz failover automático do restante dos escravos para replicar a partir do novo mestre.
Com o ClusterControl, você também implanta um ambiente misto com alguns nós na nuvem e outros no local. Você também pode adicionar balanceadores de carga à sua topologia para melhorar nosso ambiente de alta disponibilidade. Você pode encontrar mais informações sobre este tema aqui.
Conclusão
O Azure tem muitos recursos e produtos para oferecer uma solução de nível empresarial. Durante esses testes, no entanto, o principal problema que encontrei foi que o tempo de criação e failover era muito longo para a maioria das necessidades dos aplicativos.
Se você precisar de um failover e recuperação rápidos, melhore a disponibilidade do ambiente usando um balanceador de carga ou um sistema externo como o ClusterControl, para diminuir o tempo de inatividade. Para obter informações mais detalhadas sobre como executar o PostgreSQL no Microsoft Azure, você pode dar uma olhada em nosso blog de aprofundamento.