Um dos principais requisitos para qualquer banco de dados é alcançar a escalabilidade. Isso só pode ser alcançado se a contenção (bloqueio) for minimizada o máximo possível, se não for removida totalmente. Como leitura/gravação/atualização/exclusão são algumas das principais operações frequentes que ocorrem no banco de dados, portanto, é muito importante que essas operações ocorram simultaneamente sem serem bloqueadas. Para conseguir isso, a maioria dos principais bancos de dados emprega um modelo de simultaneidade chamado Controle de simultaneidade de várias versões, que reduz a contenção a um nível mínimo.
O que é MVCC
O controle de simultaneidade de várias versões (daqui em diante MVCC) é um algoritmo para fornecer controle de simultaneidade fino mantendo várias versões do mesmo objeto para que a operação READ e WRITE não entre em conflito. Aqui WRITE significa UPDATE e DELETE, pois o registro recém-INSERTADO será protegido de acordo com o nível de isolamento. Cada operação WRITE produz uma nova versão do objeto e cada operação de leitura simultânea lê uma versão diferente do objeto dependendo do nível de isolamento. Como ler e escrever, ambos operam em versões diferentes do mesmo objeto, portanto, nenhuma dessas operações é necessária para bloquear completamente e, portanto, ambas podem operar simultaneamente. O único caso em que a contenção ainda pode existir é quando duas transações simultâneas tentam ESCREVER o mesmo registro.
A maioria do banco de dados principal atual suporta MVCC. A intenção desse algoritmo é manter várias versões do mesmo objeto, de modo que a implementação do MVCC difere de banco de dados para banco de dados apenas em termos de como várias versões são criadas e mantidas. Assim, a operação do banco de dados correspondente e o armazenamento de dados mudam.
A abordagem mais reconhecida para implementar MVCC é a usada pelo PostgreSQL e Firebird/Interbase e outra é usada pelo InnoDB e Oracle. Nas seções subsequentes, discutiremos em detalhes como ele foi implementado no PostgreSQL e no InnoDB.
MVCC no PostgreSQL
Para suportar várias versões, o PostgreSQL mantém campos adicionais para cada objeto (Tupla na terminologia do PostgreSQL) conforme mencionado abaixo:
- xmin – ID da transação que inseriu ou atualizou a tupla. No caso de UPDATE, uma versão mais recente da tupla é atribuída com esse ID de transação.
- xmax – ID da transação que excluiu ou atualizou a tupla. No caso de UPDATE, uma versão atualmente existente da tupla recebe esse ID de transação. Em uma tupla recém-criada, o valor padrão desse campo é nulo.
O PostgreSQL armazena todos os dados em um armazenamento primário chamado HEAP (página de tamanho padrão de 8 KB). Toda a nova tupla recebe xmin como uma transação que a criou e uma tupla de versão mais antiga (que foi atualizada ou excluída) é atribuída com xmax. Há sempre um link da tupla da versão mais antiga para a nova versão. A tupla de versão mais antiga pode ser usada para recriar a tupla em caso de reversão e para ler uma versão mais antiga de uma tupla pela instrução READ, dependendo do nível de isolamento.
Considerando que existem duas tuplas, T1 (com valor 1) e T2 (com valor 2) para uma tabela, a criação de novas linhas pode ser demonstrada em 3 passos abaixo:
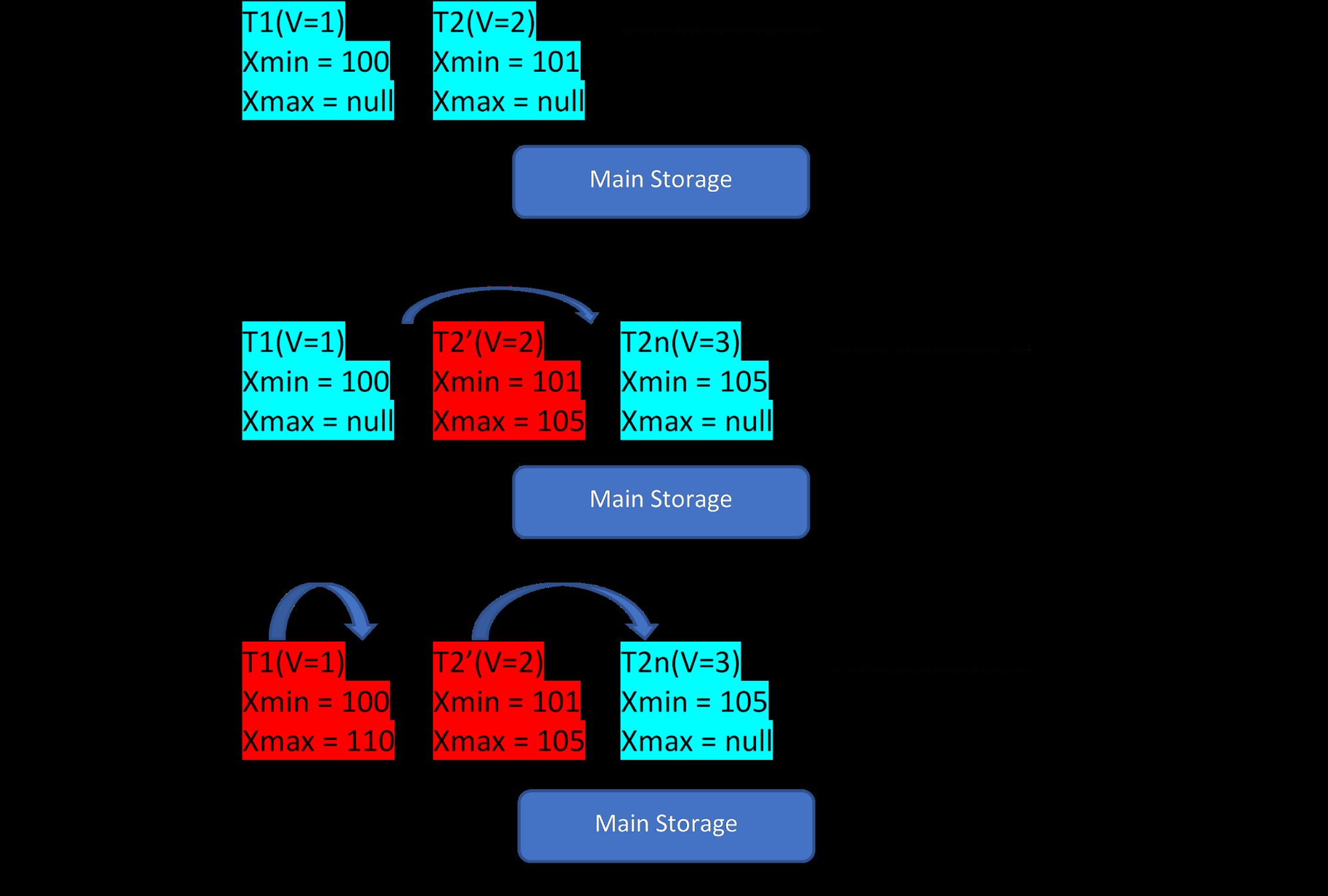 MVCC:Armazenamento de várias versões no PostgreSQL
MVCC:Armazenamento de várias versões no PostgreSQL Como visto na figura, inicialmente existem duas tuplas no banco de dados com valores 1 e 2.
Então, na segunda etapa, a linha T2 com valor 2 é atualizada com o valor 3. Neste ponto, uma nova versão é criada com o novo valor e ela é armazenada apenas como próxima à tupla existente na mesma área de armazenamento . Antes disso, a versão mais antiga é atribuída com xmax e aponta para a tupla da versão mais recente.
Da mesma forma, na terceira etapa, quando a linha T1 com valor 1 é excluída, a linha existente é virtualmente excluída (ou seja, apenas atribuiu xmax com a transação atual) no mesmo local. Nenhuma nova versão é criada para isso.
A seguir, vamos ver como cada operação cria várias versões e como o nível de isolamento da transação é mantido sem travamento com alguns exemplos reais. Em todos os exemplos abaixo, por padrão, o isolamento “READ COMMITTED” é usado.
INSERIR
Cada vez que um registro é inserido, ele cria uma nova tupla, que é adicionada a uma das páginas pertencentes à tabela correspondente.
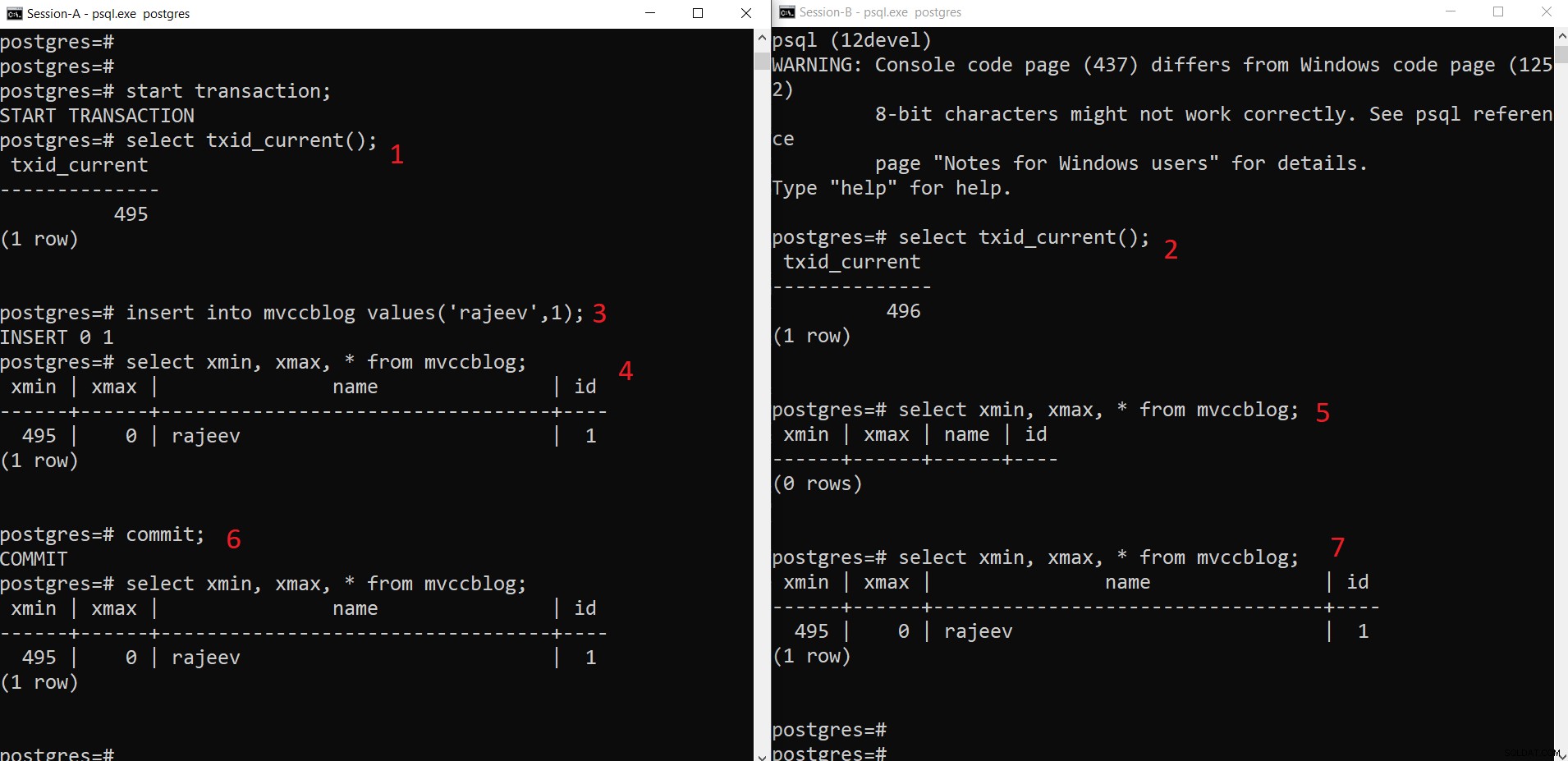 Operação INSERT simultânea do PostgreSQL
Operação INSERT simultânea do PostgreSQL Como podemos ver aqui passo a passo:
- A sessão-A inicia uma transação e obtém o ID de transação 495.
- A sessão-B inicia uma transação e obtém o ID de transação 496.
- Sessão-A insere uma nova tupla (é armazenada em HEAP)
- Agora, a nova tupla com xmin definido para o ID de transação atual 495 é adicionada.
- Mas o mesmo não é visível da Sessão-B, pois xmin (ou seja, 495) ainda não foi confirmado.
- Uma vez confirmado.
- Os dados ficam visíveis para ambas as sessões.
ATUALIZAÇÃO
PostgreSQL UPDATE não é uma atualização “IN-PLACE”, ou seja, não modifica o objeto existente com o novo valor necessário. Em vez disso, ele cria uma nova versão do objeto. Portanto, UPDATE envolve amplamente as etapas abaixo:
- Ele marca o objeto atual como excluído.
- Em seguida, adiciona uma nova versão do objeto.
- Redirecione a versão mais antiga do objeto para uma nova versão.
Portanto, mesmo que vários registros permaneçam os mesmos, o HEAP ocupa espaço como se mais um registro fosse inserido.
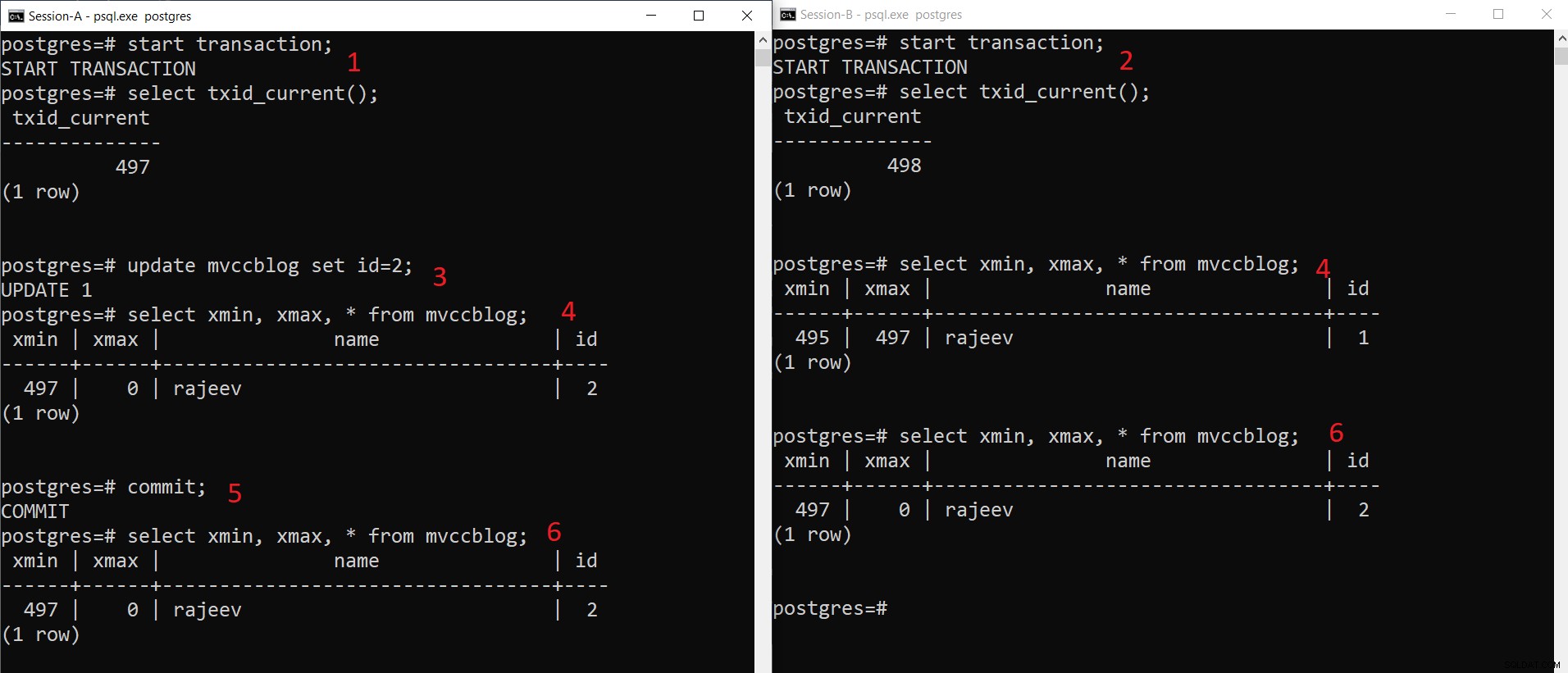 Operação INSERT simultânea do PostgreSQL
Operação INSERT simultânea do PostgreSQL Como podemos ver aqui passo a passo:
- A Sessão-A inicia uma transação e obtém o ID de transação 497.
- A sessão-B inicia uma transação e obtém o ID de transação 498.
- A Sessão A atualiza o registro existente.
- Aqui, a Sessão-A vê uma versão da tupla (tupla atualizada), enquanto a Sessão-B vê outra versão (tupla mais antiga, mas xmax definido como 497). Ambas as versões de tupla são armazenadas no armazenamento HEAP (até na mesma página, dependendo da disponibilidade de espaço)
- Depois que a Sessão-A confirma a transação, a tupla mais antiga expira quando xmax da tupla mais antiga é confirmada.
- Agora, ambas as sessões veem a mesma versão do registro.
EXCLUIR
Excluir é quase como a operação UPDATE, exceto que não precisa adicionar uma nova versão. Ele apenas marca o objeto atual como DELETED conforme explicado no caso UPDATE.
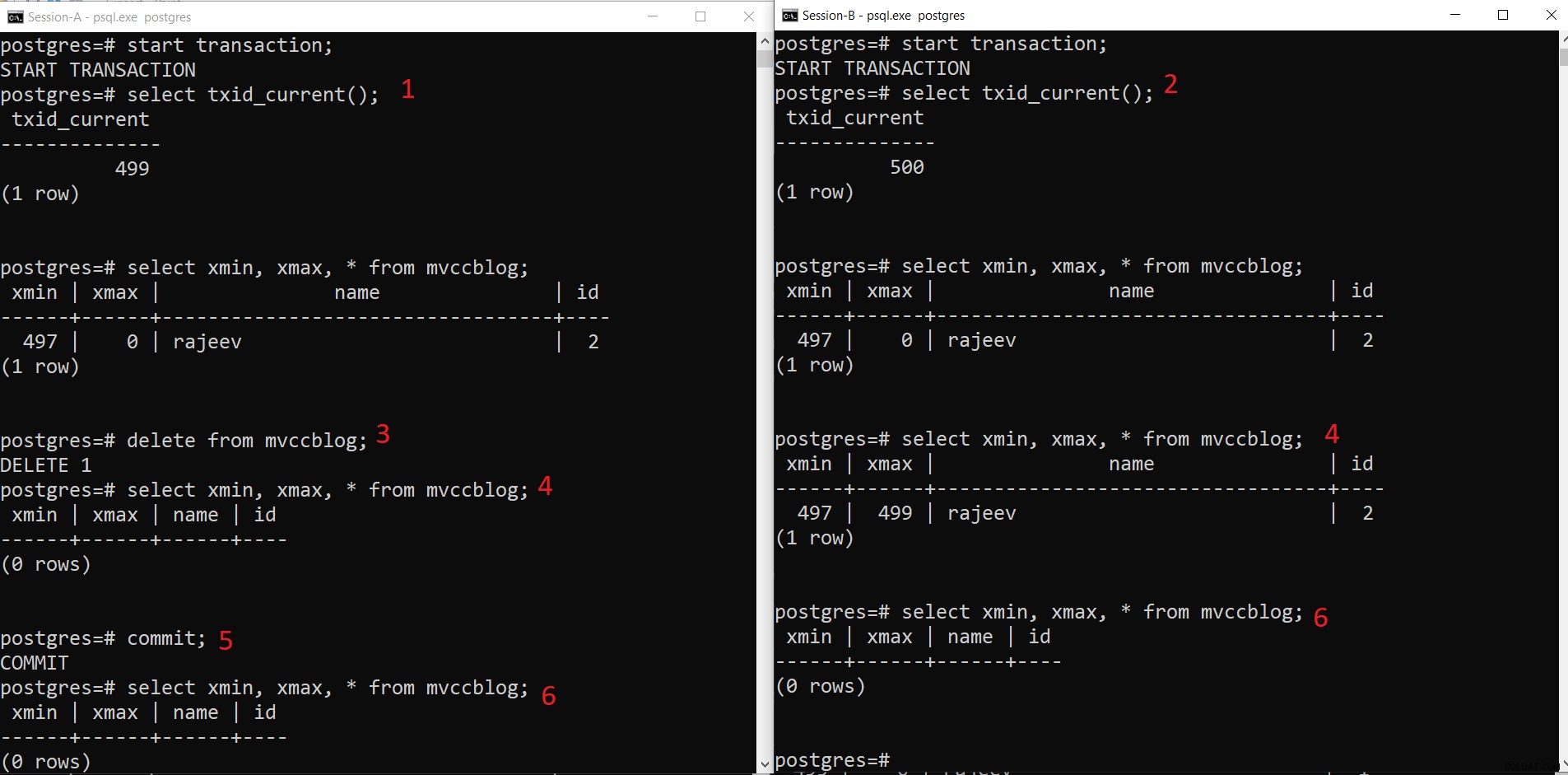 Operação DELETE simultânea do PostgreSQL
Operação DELETE simultânea do PostgreSQL - A Sessão-A inicia uma transação e obtém o ID de transação 499.
- A sessão-B inicia uma transação e obtém o ID de transação 500.
- Sessão-A exclui o registro existente.
- Aqui, a Sessão-A não vê nenhuma tupla como excluída da transação atual. Considerando que a Sessão-B vê uma versão mais antiga da tupla (com xmax como 499; a transação que excluiu este registro).
- Depois que a Sessão-A confirma a transação, a tupla mais antiga expira quando xmax da tupla mais antiga é confirmada.
- Agora, ambas as sessões não veem a tupla excluída.
Como podemos ver, nenhuma das operações remove diretamente a versão existente do objeto e, sempre que necessário, adiciona uma versão adicional do objeto.
Agora, vamos ver como a consulta SELECT é executada em uma tupla com várias versões:SELECT precisa ler todas as versões da tupla até encontrar a tupla apropriada de acordo com o nível de isolamento. Suponha que houvesse uma tupla T1, que foi atualizada e criou uma nova versão T1’ e que por sua vez criou T1’’ na atualização:
- A operação SELECT passará pelo armazenamento de heap para esta tabela e primeiro verificará T1. Se a transação T1 xmax for confirmada, ela será movida para a próxima versão dessa tupla.
- Suponha que agora a tupla T1' xmax também seja confirmada e, novamente, ela será movida para a próxima versão dessa tupla.
- Finalmente, ele encontra T1'' e vê que xmax não está confirmado (ou nulo) e T1'' xmin está visível para a transação atual de acordo com o nível de isolamento. Por fim, ele lerá a tupla T1''.
Como podemos ver, ele precisa percorrer todas as 3 versões da tupla para encontrar a tupla visível apropriada até que a tupla expirada seja excluída pelo coletor de lixo (VACUUM).
MVCC no InnoDB
Para oferecer suporte a várias versões, o InnoDB mantém campos adicionais para cada linha, conforme mencionado abaixo:
- DB_TRX_ID:ID da transação que inseriu ou atualizou a linha.
- DB_ROLL_PTR:também é chamado de ponteiro de rolagem e aponta para desfazer o registro de log gravado no segmento de reversão (mais sobre isso a seguir).
Assim como o PostgreSQL, o InnoDB também cria várias versões da linha como parte de toda a operação, mas o armazenamento da versão mais antiga é diferente.
No caso do InnoDB, a versão antiga da linha alterada é mantida em um espaço de tabela/armazenamento separado (chamado segmento de desfazer). Diferente do PostgreSQL, o InnoDB mantém apenas a versão mais recente das linhas na área de armazenamento principal e a versão mais antiga é mantida no segmento de desfazer. As versões de linha do segmento de desfazer são usadas para desfazer a operação em caso de reversão e para ler uma versão mais antiga de linhas pela instrução READ, dependendo do nível de isolamento.
Considerando que existem duas linhas, T1 (com valor 1) e T2 (com valor 2) para uma tabela, a criação de novas linhas pode ser demonstrada em 3 passos abaixo:
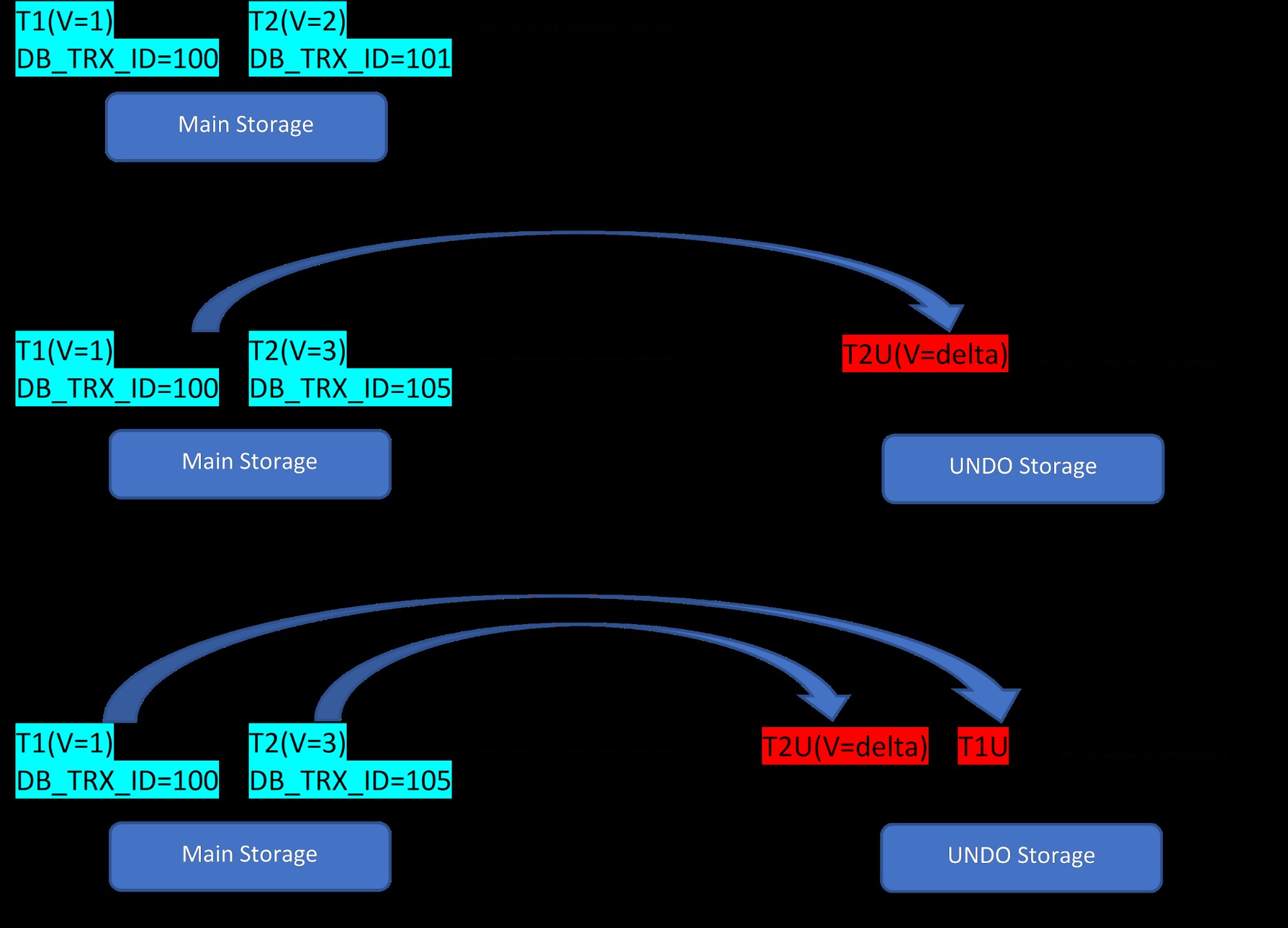 MVCC:Armazenamento de várias versões no InnoDB
MVCC:Armazenamento de várias versões no InnoDB Como visto na figura, inicialmente existem duas linhas no banco de dados com os valores 1 e 2.
Então, na segunda etapa, a linha T2 com valor 2 é atualizada com o valor 3. Neste ponto, uma nova versão é criada com o novo valor e substitui a versão anterior. Antes disso, a versão mais antiga é armazenada no segmento undo (observe que a versão do segmento UNDO tem apenas um valor delta). Além disso, observe que há um ponteiro da nova versão para a versão mais antiga no segmento de reversão. Ao contrário do PostgreSQL, a atualização do InnoDB é “IN-PLACE”.
Da mesma forma, na terceira etapa, quando a linha T1 com valor 1 é excluída, a linha existente é virtualmente excluída (ou seja, apenas marca um bit especial na linha) na área de armazenamento principal e uma nova versão correspondente a isso é adicionada em o segmento Desfazer. Novamente, há um ponteiro de rolagem do armazenamento principal para o segmento de desfazer.
Todas as operações se comportam da mesma forma que no caso do PostgreSQL quando vistas de fora. Apenas o armazenamento interno de várias versões difere.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
MVCC:PostgreSQL vs InnoDB
Agora, vamos analisar quais são as principais diferenças entre PostgreSQL e InnoDB em termos de implementação do MVCC:
-
Tamanho de uma versão mais antiga
O PostgreSQL apenas atualiza o xmax na versão mais antiga da tupla, então o tamanho da versão mais antiga permanece o mesmo do registro inserido correspondente. Isso significa que se você tiver 3 versões de uma tupla mais antiga, todas elas terão o mesmo tamanho (exceto a diferença no tamanho real dos dados, se houver, em cada atualização).
Já no caso do InnoDB, a versão do objeto armazenado no segmento Undo é normalmente menor que o registro inserido correspondente. Isso ocorre porque apenas os valores alterados (ou seja, diferenciais) são gravados no log UNDO.
-
Operação INSERIR
O InnoDB precisa escrever um registro adicional no segmento UNDO mesmo para INSERT enquanto o PostgreSQL cria uma nova versão apenas no caso de UPDATE.
-
Restaurando uma versão mais antiga em caso de reversão
O PostgreSQL não precisa de nada específico para restaurar uma versão mais antiga em caso de reversão. Lembre-se que a versão mais antiga tem xmax igual à transação que atualizou esta tupla. Portanto, até que esse id de transação seja confirmado, ele é considerado uma tupla viva para um instantâneo simultâneo. Uma vez que a transação é revertida, a transação correspondente será automaticamente considerada ativa para todas as transações, pois será uma transação abortada.
Considerando que, no caso do InnoDB, é explicitamente necessário reconstruir a versão mais antiga do objeto assim que a reversão ocorrer.
-
Recuperando espaço ocupado por uma versão mais antiga
No caso do PostgreSQL, o espaço ocupado por uma versão mais antiga pode ser considerado morto somente quando não houver um snapshot paralelo para ler esta versão. Uma vez que a versão mais antiga está morta, a operação VACUUM pode recuperar o espaço ocupado por eles. VACUUM pode ser acionado manualmente ou como uma tarefa em segundo plano, dependendo da configuração.
Os logs do InnoDB UNDO são divididos principalmente em INSERT UNDO e UPDATE UNDO. O primeiro é descartado assim que a transação correspondente é confirmada. O segundo precisa ser preservado até que seja paralelo a qualquer outro instantâneo. O InnoDB não possui operação VACUUM explícita, mas em uma linha semelhante, possui PURGE assíncrono para descartar logs UNDO que são executados como uma tarefa em segundo plano.
-
Impacto do vácuo atrasado
Conforme discutido em um ponto anterior, há um enorme impacto do vácuo atrasado no caso do PostgreSQL. Isso faz com que a tabela comece a inchar e aumente o espaço de armazenamento, mesmo que os registros sejam excluídos constantemente. Também pode chegar a um ponto em que VACUUM FULL precisa ser feito, o que é uma operação muito cara.
-
Verificação sequencial em caso de mesa inchada
A varredura sequencial do PostgreSQL deve percorrer todas as versões mais antigas de um objeto, mesmo que todas estejam mortas (até que sejam removidas usando vácuo). Este é o problema típico e mais falado no PostgreSQL. Lembre-se de que o PostgreSQL armazena todas as versões de uma tupla no mesmo armazenamento.
Considerando que, no caso do InnoDB, ele não precisa ler o registro Undo, a menos que seja necessário. Caso todos os registros de desfazer estejam mortos, será suficiente apenas ler todas as versões mais recentes dos objetos.
-
Índice
O PostgreSQL armazena o índice em um armazenamento separado que mantém um link para os dados reais no HEAP. Portanto, o PostgreSQL precisa atualizar a parte INDEX também, embora não tenha havido nenhuma alteração no INDEX. Embora mais tarde esse problema tenha sido corrigido implementando a atualização HOT (Heap Only Tuple), mas ainda tem a limitação de que, se uma nova tupla de heap não puder ser acomodada na mesma página, ela retornará ao UPDATE normal.
O InnoDB não tem esse problema, pois usa índice clusterizado.
Conclusão
O PostgreSQL MVCC tem poucas desvantagens, especialmente em termos de armazenamento inchado, se sua carga de trabalho tiver UPDATE/DELETE frequente. Portanto, se você decidir usar o PostgreSQL, deve ter muito cuidado para configurar o VACUUM com sabedoria.
A comunidade PostgreSQL também reconheceu isso como um problema importante e eles já começaram a trabalhar na abordagem MVCC baseada em UNDO (nome provisório como ZHEAP) e podemos ver o mesmo em uma versão futura.