As restrições no SQL Server são regras predefinidas que você pode aplicar em uma ou várias colunas. Essas restrições ajudam a manter a integridade, confiabilidade e precisão dos valores armazenados nessas colunas. Você pode criar restrições usando as instruções CREATE TABLE ou ALTER Table. Se você usar a instrução ALTER TABLE, o SQL Server verificará os dados da coluna existente antes de criar a restrição.
Se você inserir dados na coluna que atende aos critérios da regra de restrição, o SQL Server insere os dados com êxito. No entanto, se os dados violarem a restrição, a instrução de inserção será abortada com uma mensagem de erro.
Por exemplo, considere que você tem uma tabela [Employee] que armazena os dados dos funcionários da sua organização, incluindo seu salário. Existem algumas regras práticas quando se trata de valores na coluna de salário.
- A coluna não pode ter valores negativos, como -10.000 ou -15.000 USD.
- Você também deseja especificar o valor máximo do salário. Por exemplo, o salário máximo deve ser inferior a US$ 2.000.000.
Se você inserir um novo registro com uma restrição, o SQL Server validará o valor em relação às regras definidas.
Valor inserido:
Salário 80.000:Inserido com sucesso
Salário -50.000: Erro
Exploraremos as seguintes restrições no SQL Server neste artigo.
- NÃO NULO
- ÚNICO
- VERIFICAR
- CHAVE PRIMÁRIA
- CHAVE ESTRANGEIRA
- PADRÃO
restrição NÃO NULA
Por padrão, o SQL Server permite armazenar valores NULL em colunas. Esses valores NULL não representam dados válidos.
Por exemplo, todos os funcionários de uma organização devem ter um Emp ID, primeiro nome, sexo e endereço. Portanto, você pode especificar uma coluna com restrições NOT NULL para sempre garantir valores válidos.
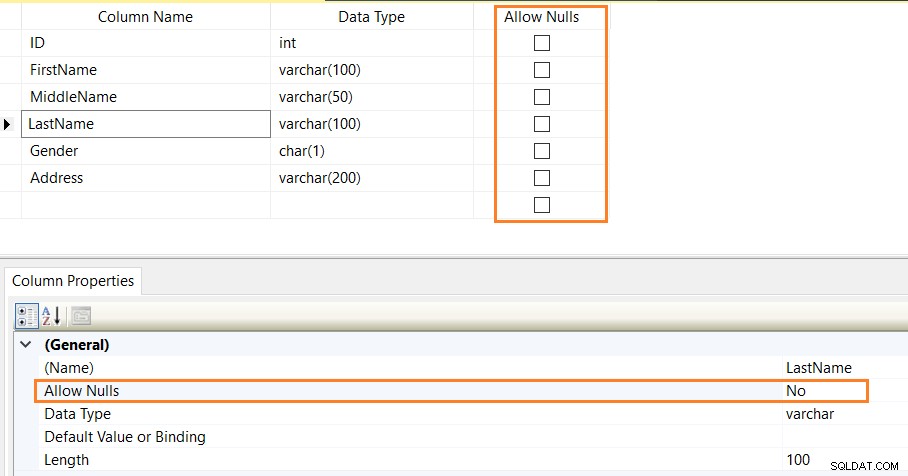
O script CREATE TABLE abaixo define restrições NOT NULL para as colunas [ID], [FirstName], [LastName], [Gender] e [Address].
CREATE TABLE Employees ( ID INT NOT NULL, [FirstName] Varchar(100) NOT NULL, [MiddleName] Varchar(50) NULL, [LastName] Varchar(100) NOT NULL, [Gender] char(1) NOT NULL, [Address] Varchar(200) NOT NULL )
Para validar o comportamento das restrições NOT NULL, usamos as seguintes instruções INSERT.
- Inserir valores para todas as colunas (NULL e NOT NULL) – Inserções bem-sucedidas
INSERT INTO Employees (ID,[FirstName],[MiddleName],[LastName],[gender],[Address]) VALUES(1,'Raj','','Gupta','M','India')
- Inserir valores para colunas com propriedade NOT NULL – Inserções bem-sucedidas
INSERT INTO Employees (ID,[FirstName],[LastName],[gender],[Address]) VALUES(2, 'Shyam','Agarwal','M','UK')
- Ignore a inserção de valores para a coluna [LastName] com restrições NOT NULL – Falha+
INSERT INTO Employees (ID,[FirstName],[gender],[Address]) VALUES(3,'Sneha','F','India')
A última instrução INSERT gerou o erro - Não é possível inserir valores NULL na coluna .

Esta tabela possui os seguintes valores inseridos na tabela [Employees].
Suponha que não exijamos valores NULL na coluna [MiddleName] conforme os requisitos de RH. Para isso, você pode usar a instrução ALTER TABLE.
ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Esta instrução ALTER TABLE falha devido aos valores existentes da coluna [MiddleName]. Para impor a restrição, você precisa eliminar esses valores NULL e, em seguida, executar a instrução ALTER.
UPDATE Employees SET [MiddleName]='' WHERE [MiddleName] IS NULL Go ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Você também pode validar as restrições NOT NULL usando o designer de tabela SSMS.
restrição ÚNICA
A restrição UNIQUE no SQL Server garante que você não tenha valores duplicados em uma única coluna ou combinação de colunas. Essas colunas devem fazer parte das restrições UNIQUE. O SQL Server cria automaticamente um índice quando as restrições UNIQUE são definidas. Você pode ter apenas um valor exclusivo na coluna (incluindo NULL).
Por exemplo, crie a [DemoTable] com a coluna [ID] com restrição UNIQUE.
CREATE TABLE DemoTable ( [ID] INT UNIQUE NOT NULL, [EmpName] VARCHAR(50) NOT NULL )
Em seguida, expanda a tabela no SSMS e você terá um índice exclusivo (não agrupado), conforme mostrado abaixo.
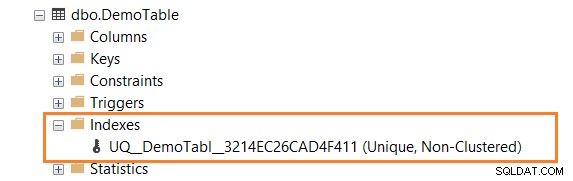
Clique com o botão direito do mouse no índice e gere seu script. Conforme mostrado abaixo, ele usa a palavra-chave ADD UNIQUE NONCLUSTERED para a restrição.

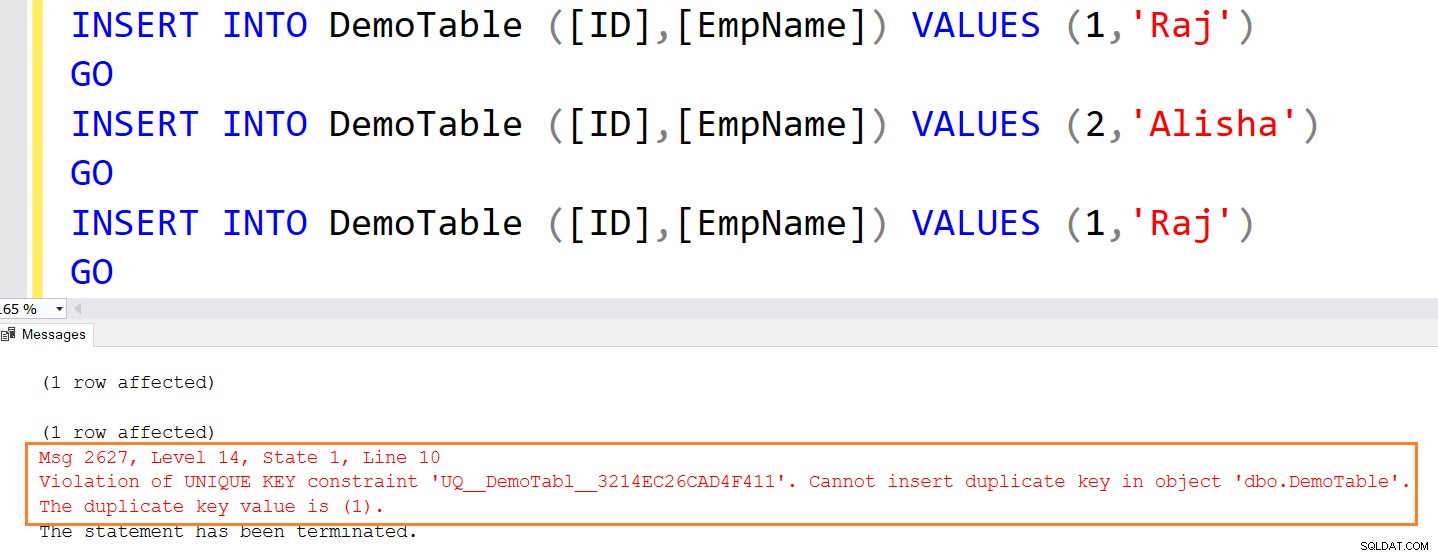
A instrução insert a seguir apresenta um erro porque tenta inserir valores duplicados.
INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (2,'Alisha') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO
VERIFICAR restrição
A restrição CHECK no SQL Server define um intervalo válido de valores que podem ser inseridos em colunas especificadas. Ele avalia cada valor inserido ou modificado e, se for satisfeito, a instrução SQL é concluída com sucesso.
O script SQL a seguir coloca uma restrição para a coluna [Age]. Seu valor deve ser superior a 18 anos.
CREATE TABLE DemoCheckConstraint ( ID INT PRIMARY KEY, [EmpName] VARCHAR(50) NULL, [Age] INT CHECK (Age>18) ) GO
Vamos inserir dois registros nesta tabela. A consulta insere o primeiro registro com sucesso.
INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (1,'Raj',20) Go INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (2,'Sohan',17) GO
A segunda instrução INSERT falha porque não atende à condição de restrição CHECK.
Outro caso de uso para a restrição CHECK é armazenar valores válidos de CEPs. No script abaixo, adicionamos uma nova coluna [ZipCode] e ela usa a restrição CHECK para validar os valores.
ALTER TABLE DemoCheckConstraint ADD zipcode int
GO
ALTER TABLE DemoCheckConstraint
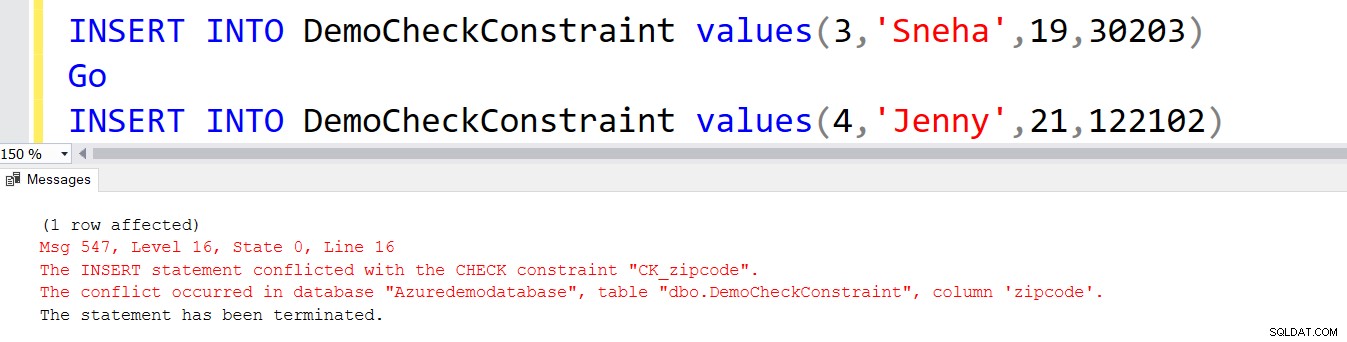
ADD CONSTRAINT CK_zipcode CHECK (zipcode LIKE REPLICATE ('[0-9]', 5)) Esta restrição CHECK não permite códigos postais inválidos. Por exemplo, a segunda instrução INSERT gera um erro.
INSERT INTO DemoCheckConstraint values(3,'Sneha',19,30203) Go INSERT INTO DemoCheckConstraint values(4,'Jenny',21,122102)
restrição de CHAVE PRIMÁRIA
A restrição PRIMARY KEY no SQL Server é uma escolha popular entre os profissionais de banco de dados para implementar valores exclusivos em uma tabela relacional. Ele combina restrições UNIQUE e NOT NULL. O SQL Server cria automaticamente um índice clusterizado assim que definimos uma restrição PRIMARY KEY. Você pode usar uma única coluna ou um conjunto de combinações para definir valores exclusivos em uma linha.
Seu objetivo principal é impor a integridade da tabela usando a entidade exclusiva ou o valor da coluna.
É semelhante à restrição UNIQUE com as seguintes diferenças.
| CHAVE PRIMÁRIA | CHAVE ÚNICA |
| Ele usa um identificador exclusivo para cada linha em uma tabela. | Ele define exclusivamente valores em uma coluna da tabela. |
| Você não pode inserir valores NULL na coluna PRIMARY KEY. | Ele pode aceitar um valor NULL na coluna de chave exclusiva. |
| Uma tabela pode ter apenas uma restrição PRIMARY KEY. | Você pode criar várias restrições UNIQUE KEY no SQL Server. |
| Por padrão, ele cria um índice clusterizado para as colunas PRIMARY KEY. | A UNIQUE KEY cria um índice não clusterizado para as colunas de chave primária. |
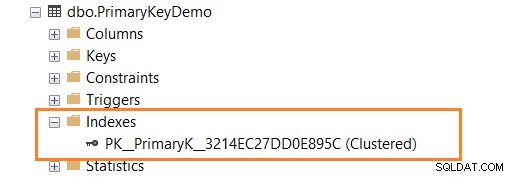
O script a seguir define a PRIMARY KEY na coluna ID.
CREATE TABLE PrimaryKeyDemo ( ID INT PRIMARY KEY, [Name] VARCHAR(100) NULL )
Conforme mostrado abaixo, você tem um índice de chave clusterizada após definir a PRIMARY KEY na coluna ID.
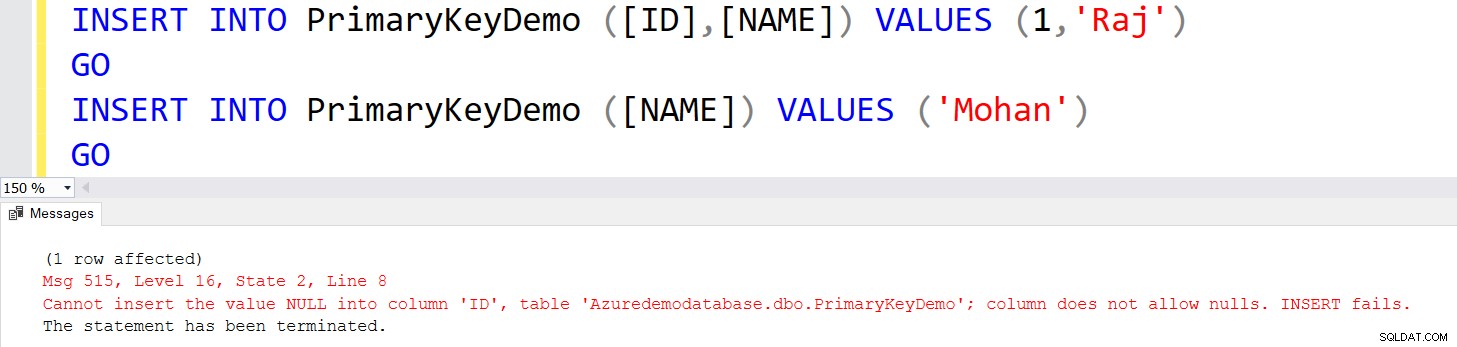
Vamos inserir os registros na tabela [PrimaryKeyDemo] com as seguintes instruções INSERT.
INSERT INTO PrimaryKeyDemo ([ID],[NAME]) VALUES (1,'Raj')
GO
INSERT INTO PrimaryKeyDemo ([NAME]) VALUES ('Mohan')
GO Você recebe um erro na segunda instrução INSERT porque ela tenta inserir o valor NULL.
Da mesma forma, se você tentar inserir valores duplicados, receberá a seguinte mensagem de erro.

restrição de CHAVE ESTRANGEIRA
A restrição FOREIGN KEY no SQL Server cria relacionamentos entre duas tabelas. Esse relacionamento é conhecido como relacionamento pai-filho. Ele impõe a integridade referencial no SQL Server.
A chave estrangeira da tabela filha deve ter uma entrada correspondente na coluna da chave primária pai. Você não pode inserir valores na tabela filha sem inseri-la primeiro na tabela pai. Da mesma forma, primeiro, precisamos remover o valor da tabela filho antes que ele possa ser removido da tabela pai.
Como não podemos ter valores duplicados na restrição PRIMARY KEY, ela também não permite duplicar ou NULL na tabela filha.
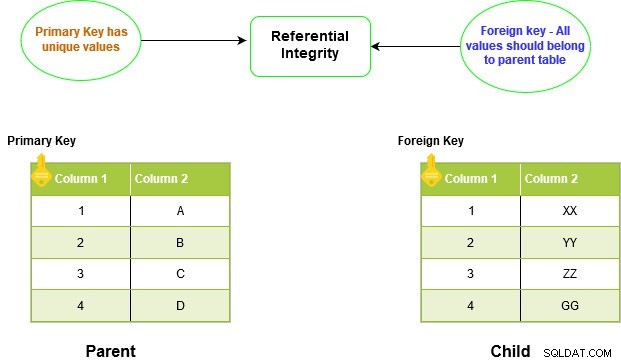
O script SQL a seguir cria uma tabela pai com uma chave primária e uma tabela filho com uma referência de chave primária e estrangeira para a coluna [EmpID] da tabela pai.
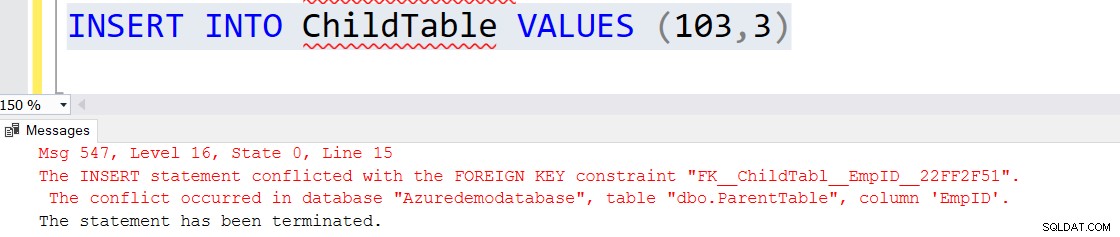
CREATE TABLE ParentTable ( [EmpID] INT PRIMARY KEY, [Name] VARCHAR(50) NULL ) GO CREATE TABLE ChildTable ( [ID] INT PRIMARY KEY, [EmpID] INT FOREIGN KEY REFERENCES ParentTable(EmpID) )
Insira registros em ambas as tabelas. Observe que o valor da chave estrangeira da tabela filho tem uma entrada na tabela pai.
INSERT INTO ParentTable VALUES (1,'Raj'),(2,'Komal') INSERT INTO ChildTable VALUES (101,1),(102,2)
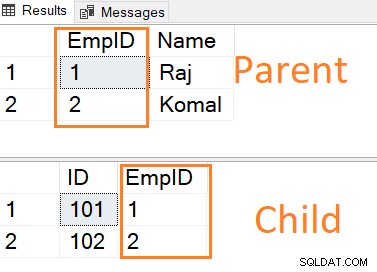
Se você tentar inserir um registro diretamente na tabela filho que não faça referência à chave primária da tabela pai, você receberá a seguinte mensagem de erro.
restrição DEFAULT
A restrição DEFAULT no SQL Server fornece o valor padrão para uma coluna. Se não especificarmos um valor na instrução INSERT para a coluna com a restrição DEFAULT, o SQL Server usará seu valor atribuído padrão. Por exemplo, suponha que uma tabela de pedidos tenha registros para todos os pedidos de clientes. Você pode usar a função GETDATE() para capturar a data do pedido sem especificar nenhum valor explícito.
CREATE TABLE Orders ( [OrderID] INT PRIMARY KEY, [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() ) GO
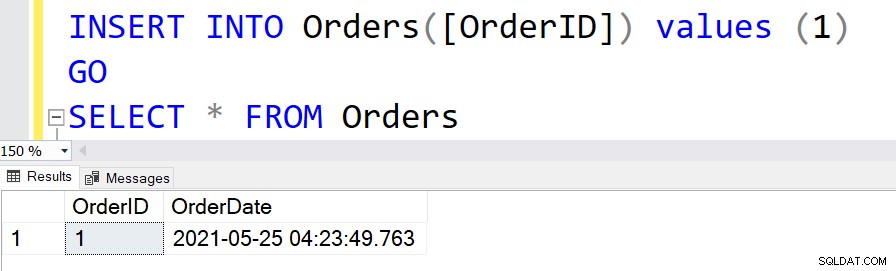
Para inserir os registros nesta tabela, podemos pular a atribuição de valores para a coluna [OrderDate].
INSERT INTO Orders([OrderID]) values (1) GO
SELECIONE * DE Pedidos
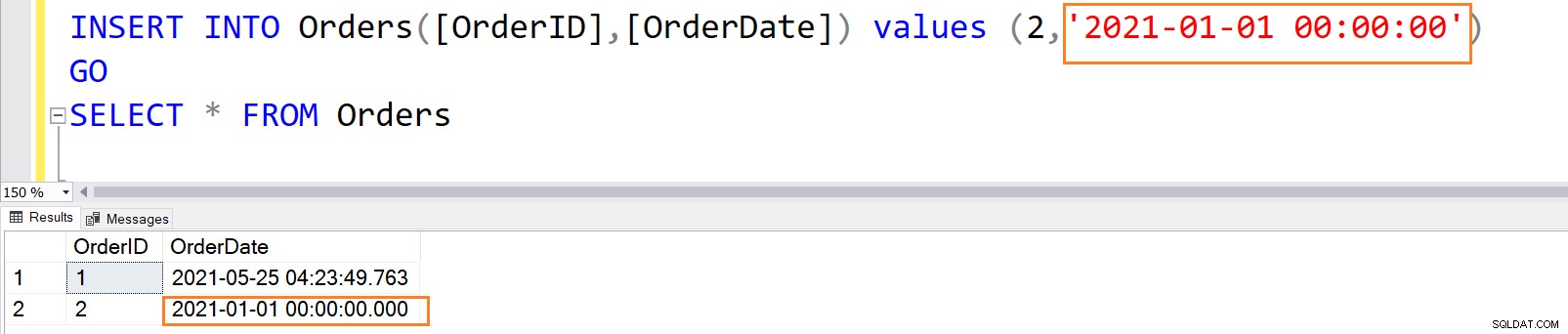
Depois que a coluna de restrição DEFAULT especifica um valor explícito, o SQL Server armazena esse valor explícito em vez do valor padrão.
Benefícios de restrição
As restrições no SQL Server podem ser benéficas nos seguintes casos:
- Como aplicar a lógica de negócios
- Como aplicar a integridade referencial
- Evitando o armazenamento de dados impróprios em tabelas do SQL Server
- Aplicando exclusividade para dados de coluna
- Melhorar o desempenho da consulta, pois o otimizador de consulta reconhece dados exclusivos e valida conjuntos de valores
- Evitando o armazenamento de valores NULL em tabelas SQL
- Escrevendo códigos para evitar NULL ao exibir dados no aplicativo