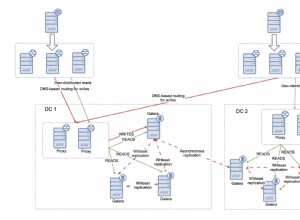
Nesta entrada do blog, falaremos sobre a replicação lógica no PostgreSQL:seus casos de uso, informações gerais sobre o status dessa tecnologia e um caso de uso especial em particular sobre como configurar um nó de assinante (réplica) do servidor primário para para funcionar como o servidor de banco de dados para o ambiente de teste e os desafios encontrados.
Introdução
A replicação lógica, introduzida oficialmente no PostgreSQL 10, é a mais recente tecnologia de replicação oferecida pela comunidade PostgreSQL. A replicação lógica é uma continuação do legado da replicação física com a qual compartilha muitas ideias e códigos. A replicação lógica funciona como a replicação física usando o WAL para registrar alterações lógicas independentemente da versão ou arquitetura específica. Para poder fornecer replicação lógica ao núcleo, a comunidade PostgreSQL percorreu um longo caminho.
Tipos de replicação e histórico de replicação do PostgreSQL
Os tipos de replicação em bancos de dados podem ser classificados da seguinte forma:
- Replicação física (binária)
- Nível do sistema operacional (replicação do vSphere)
- Nível do sistema de arquivos (DRBD)
- Nível do banco de dados (baseado em WAL)
- Replicação lógica (nível de banco de dados)
- Baseado em gatilho (DBMirror, Slony)
- Middleware (pgpool)
- baseado em WAL (pglogical, replicação lógica)
O roteiro que traz para a replicação lógica baseada em WAL de hoje foi:
- 2001:DBMirror (baseado em gatilho)
- 2004:Slony1 (baseado em gatilho), pgpool (middleware)
- 2005:PITR (baseado em WAL) introduzido no PostgreSQL 8.0
- 2006:espera a quente no PostgreSQL 8.2
- 2010:replicação de streaming físico, espera ativa no PostgreSQL 9.0
- 2011:replicação de streaming síncrona no PostgreSQL 9.1
- 2012:replicação de streaming em cascata no PostgreSQL 9.2
- 2013:trabalhadores em segundo plano no PostgreSQL 9.3
- 2014:API de decodificação lógica, slots de replicação. (Os fundamentos da Replicação Lógica) no PostgreSQL 9.4
- 2015:2ndQuadrant apresenta pglogical, o ancestral ou replicação lógica
- 2017:replicação lógica no núcleo do PostgreSQL 10!
Como podemos ver, muitas tecnologias colaboraram para tornar a Replicação Lógica uma realidade:arquivamento de WAL, esperas quentes/quentes, replicação física de WAL, trabalhadores em segundo plano, decodificação lógica. Supondo que o leitor esteja familiarizado com a maioria das noções de replicação física, falaremos sobre os componentes básicos da Replicação Lógica.
Conceitos básicos de replicação lógica do PostgreSQL
Algumas terminologias:
- Publicação: Um conjunto de alterações de um conjunto de tabelas definidas em um banco de dados específico em um servidor primário de replicação física. Uma publicação pode lidar com todos ou alguns de:INSERT, DELETE, UPDATE, TRUNCATE.
- Nó do editor: O servidor onde a publicação reside.
- Identidade da réplica: Uma maneira de identificar a linha no lado do assinante para UPDATEs e DELETEs.
- Assinatura: Uma conexão com um nó de editor e uma ou mais publicações nele. Uma assinatura usa um slot de replicação dedicado no editor para replicação. Slots de replicação adicionais podem ser usados para a etapa de sincronização inicial.
- Nó do assinante: O servidor onde reside a assinatura.
A replicação lógica segue um modelo de publicação/assinatura. Um ou mais assinantes podem assinar uma ou mais publicações em um nó publicador. Os assinantes podem republicar para permitir a replicação em cascata. A replicação lógica de uma tabela consiste em duas etapas:
- Tirar um instantâneo da tabela no editor e copiá-lo para o assinante
- Aplicando todas as alterações (desde o instantâneo) na mesma sequência
A replicação lógica é transacional e garante que a ordem das alterações aplicadas ao assinante permaneça a mesma do publicador. A replicação lógica dá muito mais liberdade do que a replicação física (binária), portanto, pode ser usada de várias maneiras:
- Banco de dados único ou replicação específica de tabela (sem necessidade de replicar todo o cluster)
- Configurar acionadores para o assinante para uma tarefa específica (como anonimização, que é um tópico muito importante após a entrada em vigor do GDPR)
- Fazer com que um nó de assinante colete dados de muitos nós de editor, permitindo assim o processamento analítico central
- Replicação entre diferentes versões/arquiteturas/plataformas (zero upgrades de tempo de inatividade)
- Usando o nó do assinante como servidor de banco de dados para um ambiente de teste/desenvolvimento. Por que queremos isso é porque testar com dados reais é o tipo de teste mais realista.
Ressalvas e Restrições
Há certas coisas que devemos ter em mente ao usar a replicação lógica, algumas delas podem influenciar algumas decisões de design, mas outras podem levar a incidentes críticos.
Restrições
- Apenas operações DML são suportadas. Sem DDL. O esquema deve ser definido antecipadamente
- As sequências não são replicadas
- Objetos grandes não são replicados
- Apenas tabelas base simples são suportadas (visualizações materializadas, tabelas raiz de partição, tabelas estrangeiras não são suportadas)
Advertências
O problema básico que mais cedo ou mais tarde teremos que enfrentar ao usar a Replicação Lógica são os conflitos no assinante. O assinante é um servidor de leitura/gravação normal que pode atuar como primário em uma configuração de replicação física ou até mesmo como publicador em uma configuração de replicação lógica em cascata. Enquanto as gravações nas tabelas inscritas forem executadas, pode haver conflitos . Um conflito surge quando os dados replicados violam uma restrição na tabela à qual são aplicados. Normalmente, a operação que causa isso é INSERT, DELETES ou UPDATES que não têm nenhum efeito devido a linhas ausentes não causarão conflito. Quando surge um conflito, a replicação é interrompida. O trabalhador lógico em segundo plano será reiniciado no intervalo especificado (wal_retrieve_retry_interval), no entanto, a replicação falhará novamente até que a causa do conflito seja resolvida. Esta é uma condição crítica que deve ser tratada imediatamente. Não fazer isso fará com que o slot de replicação fique preso em sua posição atual, o nó do editor começará a acumular WALs e inevitavelmente o nó do editor ficará sem espaço em disco . Um conflito é o motivo mais comum pelo qual a replicação pode parar, mas qualquer outra condição errônea terá o mesmo efeito:por exemplo, adicionamos uma nova coluna NOT NULL em uma tabela assinada, mas esquecemos de definir um valor padrão, ou adicionamos uma coluna em uma tabela publicada, mas esquecemos de defini-la na tabela assinada, ou cometemos um erro em seu tipo e os dois tipos não são compatível. Todos esses erros interromperão a replicação. Existem duas maneiras de resolver um conflito:
- Resolva o problema real
- Ignore a transação com falha chamando pg_replication_origin_advance
Solução B. como também mostrado aqui, pode ser perigoso e complicado, pois é basicamente um processo de tentativa e erro, e se alguém escolher o LSN atual no editor, ele poderá facilmente acabar com um sistema de replicação quebrado, pois pode haver operações entre o LSN problemático e o LSN atual que gostaríamos de manter. Portanto, a melhor maneira é realmente resolver o problema do lado do assinante. Por exemplo. se ocorrer uma violação de UNIQUE KEY, podemos atualizar os dados no assinante ou simplesmente excluir a linha. Em um ambiente de produção, tudo isso deve ser automatizado ou pelo menos semiautomatizado.
Configurando os nós do editor e do assinante
Para uma visão geral da replicação lógica na prática, leia este blog.
Os parâmetros relevantes para a replicação lógica são:
- Lado do editor
- wal_level>=“lógico”
- max_replication_slots>=#subscriptions + sincronização inicial da tabela
- max_wal_senders>=max_replication_slots + other_physical_standbys
- Lado do assinante
- max_replication_slots>=#subscriptions
- max_logical_replication_workers>=#subscriptions + sincronização inicial da tabela
- max_worker_processes>=max_logical_replication_workers + 1 + max_parallel_workers
Vamos nos concentrar nas considerações especiais que surgem de nosso propósito especial que precisamos de replicação lógica para alcançar:criar um cluster de banco de dados de teste para uso pelo departamento de teste . A publicação pode ser definida para todas as tabelas ou tabela por tabela. Sugiro a abordagem tabela por tabela, pois nos dá a máxima flexibilidade. As etapas gerais podem ser resumidas da seguinte forma:
- Execute um novo initdb no nó do assinante
- Descarregue o esquema do cluster do editor e copie para o nó do assinante
- Crie o esquema no assinante
- Decida quais tabelas você precisa e quais não precisa.
Em relação ao marcador acima, há duas razões pelas quais você pode não precisar que uma tabela seja replicada ou configurada para replicação:
- É uma tabela fictícia sem importância (e talvez você deva retirá-la da produção também)
- é uma tabela local para o ambiente de produção, o que significa que faz todo o sentido que a mesma tabela no ambiente de teste (assinante) tenha seus próprios dados
Todas as tabelas que participam da replicação lógica devem ter uma IDENTIDADE DE REPLICA. Esta é, por padrão, a PRIMARY KEY e, se não estiver disponível, uma chave UNIQUE pode ser definida. Próxima etapa para encontrar o status das tabelas em relação à REPLICA IDENTITY.
- Encontre as tabelas sem candidato óbvio para REPLICA IDENTITY
select table_schema||'.'||table_name from information_schema.tables where table_type='BASE TABLE' AND table_schema||'.'||table_name NOT IN (select table_schema||'.'||table_name from information_schema.table_constraints WHERE constraint_type in ('PRIMARY KEY','UNIQUE')) AND table_schema NOT IN ('information_schema','pg_catalog') ; - Encontre as tabelas sem PRIMARY KEY mas com um UNIQUE INDEX
select table_schema||'.'||table_name from information_schema.table_constraints WHERE constraint_type = 'UNIQUE' EXCEPT select table_schema||'.'||table_name from information_schema.table_constraints WHERE constraint_type = 'PRIMARY KEY'; - Percorra as listas acima e decida o que fazer com cada tabela
- Crie a publicação com as tabelas para as quais existe um PK
select 'CREATE PUBLICATION data_for_testdb_pub FOR TABLE ONLY ' || string_agg(qry.tblname,', ONLY ') FROM (select table_schema||'.'||quote_ident(table_name) as tblname from information_schema.tables where table_type='BASE TABLE' AND table_schema||'.'||table_name IN (select table_schema||'.'||table_name from information_schema.table_constraints WHERE constraint_type in ('PRIMARY KEY')) AND table_schema NOT IN( 'information_schema','pg_catalog') ORDER BY 1) as qry; \gexec - Em seguida, crie a assinatura no nó do assinante
O acima também copiará os dados.create subscription data_for_testdb_pub CONNECTION 'dbname=yourdb host=yourdbhost user=repmgr' PUBLICATION data_for_testdb_pub ; - Adicione as tabelas que você deseja que tenham um índice UNIQUE
Execute tanto em nós de editor quanto de assinante, por exemplo:
No editor:ALTER TABLE someschema.yourtable REPLICA IDENTITY USING INDEX yourindex_ukey;
No assinante:ALTER PUBLICATION data_for_testdb_pub ADD TABLE ONLY someschema.yourtable;ALTER SUBSCRIPTION data_for_testdb_pub REFRESH PUBLICATION WITH ( COPY_DATA ); - Neste ponto (sincronização), você deve sempre ficar de olho no log do PostgreSQL no nó do assinante. Você não quer nenhum erro ou qualquer coisa (timeout) que proíba a continuação da replicação lógica. SOLVE QUALQUER ERRO IMEDIATAMENTE , ou o editor continuará acumulando arquivos WAL em pg_wal e, eventualmente, ficará sem espaço. Então você tem que lidar com
- Todos os ERROS ou qualquer mensagem sobre o trabalhador lógico que resulte na saída
- Cuide também de
- wal_receiver_timeout
- wal_sender_timeout
Depois de resolver todos os problemas, você deve ter seu nó de assinante funcionando normalmente. Portanto, a próxima pergunta é como usar isso como um servidor de banco de dados de teste. Você terá que lidar com esses problemas/questões:
- Anonimização
- Chaves primárias e chaves exclusivas baseadas em violações de sequências
- Um conjunto geral de boas práticas
- Monitoramento
Anonimização
Em relação à anonimização de dados pessoais que é aplicada pelo GDPR na UE, você deve escrever SEMPRE alguns gatilhos que deixem em branco todos os campos referentes a endereços, contas bancárias, estado civil, números de telefone, e-mails, etc. Você deve consultar o responsável pela segurança de sua empresa sobre o que manter e o que deixar em branco. Os gatilhos devem ser definidos como ALWAYS, pois o operador lógico executa as instruções como REPLICA.
Chaves primárias com sequências
Em relação às sequências, claramente haverá um problema com essas chaves, a menos que seja tratado antes de iniciar qualquer teste. Considere este caso:
- Na tarde de sexta você faz alguns testes no banco de dados do assinante inserindo uma nova linha em alguma tabela. Isso terá como ID o próximo valor gerado pela sequência.
- Você vai para casa no fim de semana.
- Algum usuário de produção insere uma linha na mesma tabela no banco de dados do editor.
- A linha será replicada com base na REPLICA IDENTITY para o nó do assinante, mas falhará devido ao ERRO de violação de PK. O trabalhador lógico em segundo plano sairá e tentará novamente. Mas continuará falhando enquanto o problema persistir.
- A replicação ficará travada. O slot de replicação começará a acumular WALs.
- O editor fica sem espaço em disco.
- No fim de semana, você recebe um e-mail informando que seu nó principal entrou em PÂNICO!
Portanto, para resolver o problema de sequência, você pode adotar a seguinte abordagem:
select 'SELECT setval(''' || seqrelid::regclass||''','||CASE WHEN seqincrement <0 THEN -214748364 ELSE 214748364 END||');' from pg_sequence where seqtypid=20;
\gexecO que o acima faz é definir sequências para um valor grande o suficiente para que elas nunca se sobreponham em uma janela bastante grande no futuro, permitindo que você tenha um servidor de teste sem problemas.
Um conjunto de boas práticas
Você deve realmente dizer aos seus programadores para tornarem seus testes não persistentes. Portanto, qualquer teste após a conclusão deve deixar o banco de dados no mesmo estado em que estava antes do teste. Com inserções de IDs baseadas em sequência, isso não é um problema, vimos anteriormente uma solução. Mas com chaves ÚNICAS não sequenciais (por exemplo, compostas) isso pode ser um problema. Portanto, é melhor excluir esses dados de teste antes que alguma linha de produção com o mesmo valor atinja a tabela assinada.
Aqui também devemos adicionar lidar com alterações de esquema. Todas as alterações de esquema devem ser feitas também no assinante para não interromper o tráfego DML replicado.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Monitoramento
Você realmente deve investir em uma boa solução de monitoramento. Você deve monitorar para...
No assinante:
- TODAS as mensagens no log do assinante que são relevantes para a saída lógica do trabalhador. Instalar uma ferramenta como tail_n_mail pode realmente ajudar com isso. Uma configuração que funciona:
Assim que recebermos um alerta vindo do tail_n_mail, devemos resolver o problema imediatamente.INCLUDE: ERROR: .*publisher.* INCLUDE: ERROR: .*exited with exit.* INCLUDE: LOG: .*exited with exit.* INCLUDE: FATAL: INCLUDE: PANIC: - pg_stat_subscription. Pid não deve ser nulo. Além disso, o atraso deve ser pequeno.
Na editora:
- pg_stat_replication. Isso deve ter quantas linhas forem necessárias:uma para cada espera de replicação de streaming conectada (nós de assinante e outras esperas físicas incluídas).
- pg_replication_slots para o espaço do assinante. Isso deve estar ativo.
Geralmente, leva algum tempo até que você tenha seu servidor de banco de dados de teste ideal rodando sem problemas, mas depois de resolver todos eles, seus programadores agradecerão por tê-lo!